THE CS 1001 ENCHIRIDION1 Or, How to Use a Computer Real Good
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Free Email Software Download Best Free Email Client 2021
free email software download Best Free Email Client 2021. This article is all about best free email clients and how they can help you be more productive. We also talk about Clean Email, an easy-to-use email cleaner compatible with virtually all major email services. But before we go over the best email clients for 2021, we believe that we should first explain what advantages email clients have over web-based interfaces of various email services. Clean Email. Take control of your mailbox. What Is an Email Client and Why Should I Use One? If you’re like most people, you probably check your email at least once every day. And if you’re someone whose work involves communication with customers, clients, and coworkers, the chances are that you deal with emails all the time. Even though we spend so much time writing, forwarding, and managing emails, we hardly ever pause for a moment and think about how we could improve our emailing experience. We use clunky web interfaces that are not meant for professional use, we accept outdated applications as if alternatives didn’t exist, and we settle for the default email apps on our mobile devices even though app stores are full of excellent third-party email apps. Broadly speaking, an email client is a computer program used to access and manage a user’s email. But when we use the term email client in this article, we only mean those email clients that can be installed on a desktop computer or a mobile device—not web-based email clients that are hosted remotely and are accessible only from a web browser. -

Fortran Resources 1
Fortran Resources 1 Ian D Chivers Jane Sleightholme October 17, 2020 1The original basis for this document was Mike Metcalf’s Fortran Information File. The next input came from people on comp-fortran-90. Details of how to subscribe or browse this list can be found in this document. If you have any corrections, additions, suggestions etc to make please contact us and we will endeavor to include your comments in later versions. Thanks to all the people who have contributed. 2 Revision history The most recent version can be found at https://www.fortranplus.co.uk/fortran-information/ and the files section of the comp-fortran-90 list. https://www.jiscmail.ac.uk/cgi-bin/webadmin?A0=comp-fortran-90 • October 2020. Added an entry for Nvidia to the compiler section. Nvidia has integrated the PGI compiler suite into their NVIDIA HPC SDK product. Nvidia are also contributing to the LLVM Flang project. • September 2020. Added a computer arithmetic and IEEE formats section. • June 2020. Updated the compiler entry with details of standard conformance. • April 2020. Updated the Fortran Forum entry. Damian Rouson has taken over as editor. • April 2020. Added an entry for Hewlett Packard Enterprise in the compilers section • April 2020. Updated the compiler section to change the status of the Oracle compiler. • April 2020. Added an entry in the links section to the ACM publication Fortran Forum. • March 2020. Updated the Lorenzo entry in the history section. • December 2019. Updated the compiler section to add details of the latest re- lease (7.0) of the Nag compiler, which now supports coarrays and submodules. -
Geany Tutorial
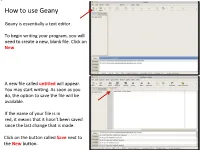
How to use Geany Geany is essentially a text editor. To begin writing your program, you will need to create a new, blank file. Click on New. A new file called untitled will appear. You may start writing. As soon as you do, the option to save the file will be available. If the name of your file is in red, it means that it hasn’t been saved since the last change that is made. Click on the button called Save next to the New button. Save the file in a directory you had previously created before you launched Geany and name it main.cpp. All of the files you will write and submit to will be named specifically main.cpp. Once the .cpp has been specified, Geany will turn on its color coding feature for the C++ template. Next, we will set up our environment and then write a simple program that will print something to the screen Feel free to supply your own name in this small program Before we do anything with it, we will need to configure some options to make your life easier in this class The vertical line to the right marks the ! boundary of your code. You will need to respect this limit in that any line of code you write must not cross this line and therefore be properly, manually broken down to the next line. Your code will be printed out for The line is not where it should be, however, and grading, and if your code crosses the we will now correct it line, it will cause line-wrapping and some points will be deducted. -
Fira Code: Monospaced Font with Programming Ligatures
Personal Open source Business Explore Pricing Blog Support This repository Sign in Sign up tonsky / FiraCode Watch 282 Star 9,014 Fork 255 Code Issues 74 Pull requests 1 Projects 0 Wiki Pulse Graphs Monospaced font with programming ligatures 145 commits 1 branch 15 releases 32 contributors OFL-1.1 master New pull request Find file Clone or download lf- committed with tonsky Add mintty to the ligatures-unsupported list (#284) Latest commit d7dbc2d 16 days ago distr Version 1.203 (added `__`, closes #120) a month ago showcases Version 1.203 (added `__`, closes #120) a month ago .gitignore - Removed `!!!` `???` `;;;` `&&&` `|||` `=~` (closes #167) `~~~` `%%%` 3 months ago FiraCode.glyphs Version 1.203 (added `__`, closes #120) a month ago LICENSE version 0.6 a year ago README.md Add mintty to the ligatures-unsupported list (#284) 16 days ago gen_calt.clj Removed `/**` `**/` and disabled ligatures for `/*/` `*/*` sequences … 2 months ago release.sh removed Retina weight from webfonts 3 months ago README.md Fira Code: monospaced font with programming ligatures Problem Programmers use a lot of symbols, often encoded with several characters. For the human brain, sequences like -> , <= or := are single logical tokens, even if they take two or three characters on the screen. Your eye spends a non-zero amount of energy to scan, parse and join multiple characters into a single logical one. Ideally, all programming languages should be designed with full-fledged Unicode symbols for operators, but that’s not the case yet. Solution Download v1.203 · How to install · News & updates Fira Code is an extension of the Fira Mono font containing a set of ligatures for common programming multi-character combinations. -

10 Keyboard/Keypad Page (0X07) This Section Is the Usagepage for Key Codes to Be Used in Implementing a USB Keyboard
54 Universal Serial Bus HID Usage Tables 10 Keyboard/Keypad Page (0x07) This section is the UsagePage for key codes to be used in implementing a USB keyboard. A Boot Keyboard (84-, 101- or 104-key) should at a minimum support all associated usage codes as indicated in the “Boot” column below. The usage type of all key codes is Selectors (Sel), except for the modifier keys Keyboard Left Control (0x224) to Keyboard Right GUI (0x231) which are Dynamic Flags (DV). Note A general note on Usages and languages: Due to the variation of keyboards from language to language, it is not feasible to specify exact key mappings for every language. Where this list is not specific for a key function in a language, the closest equivalent key position should be used, so that a keyboard may be modified for a different language by simply printing different keycaps. One example is the Y key on a North American keyboard. In Germany this is typically Z. Rather than changing the keyboard firmware to put the Z Usage into that place in the descriptor list, the vendor should use the Y Usage on both the North American and German keyboards. This continues to be the existing practice in the industry, in order to minimize the number of changes to the electronics to accommodate other languages. Table 12: Keyboard/Keypad Page Ref: Typical AT-101 Usage ID Usage ID Usage Name Position PC- MacUNI Boot (Dec) (Hex) AT X 0 00 Reserved (no event indicated)9 N/A 4/101/104 1 01 Keyboard ErrorRollOver9 N/A 4/101/104 2 02 Keyboard POSTFail9 N/A 4/101/104 3 03 Keyboard ErrorUndefined9 -

Metadefender Core V4.12.2
MetaDefender Core v4.12.2 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

The Glib/GTK+ Development Platform
The GLib/GTK+ Development Platform A Getting Started Guide Version 0.8 Sébastien Wilmet March 29, 2019 Contents 1 Introduction 3 1.1 License . 3 1.2 Financial Support . 3 1.3 Todo List for this Book and a Quick 2019 Update . 4 1.4 What is GLib and GTK+? . 4 1.5 The GNOME Desktop . 5 1.6 Prerequisites . 6 1.7 Why and When Using the C Language? . 7 1.7.1 Separate the Backend from the Frontend . 7 1.7.2 Other Aspects to Keep in Mind . 8 1.8 Learning Path . 9 1.9 The Development Environment . 10 1.10 Acknowledgments . 10 I GLib, the Core Library 11 2 GLib, the Core Library 12 2.1 Basics . 13 2.1.1 Type Definitions . 13 2.1.2 Frequently Used Macros . 13 2.1.3 Debugging Macros . 14 2.1.4 Memory . 16 2.1.5 String Handling . 18 2.2 Data Structures . 20 2.2.1 Lists . 20 2.2.2 Trees . 24 2.2.3 Hash Tables . 29 2.3 The Main Event Loop . 31 2.4 Other Features . 33 II Object-Oriented Programming in C 35 3 Semi-Object-Oriented Programming in C 37 3.1 Header Example . 37 3.1.1 Project Namespace . 37 3.1.2 Class Namespace . 39 3.1.3 Lowercase, Uppercase or CamelCase? . 39 3.1.4 Include Guard . 39 3.1.5 C++ Support . 39 1 3.1.6 #include . 39 3.1.7 Type Definition . 40 3.1.8 Object Constructor . 40 3.1.9 Object Destructor . -

The Linux Users' Guide
The Linux Users' Guide Copyright c 1993, 1994, 1996 Larry Greenfield All you need to know to start using Linux, a free Unix clone. This manual covers the basic Unix commands, as well as the more specific Linux ones. This manual is intended for the beginning Unix user, although it may be useful for more experienced users for reference purposes. i UNIX is a trademark of X/Open MS-DOS and Microsoft Windows are trademarks of Microsoft Corporation OS/2 and Operating System/2 are trademarks of IBM X Window System is a trademark of X Consortium, Inc. Motif is a trademark of the Open Software Foundation Linux is not a trademark, and has no connection to UNIX, Unix System Labratories, or to X/Open. Please bring all unacknowledged trademarks to the attention of the author. Copyright c Larry Greenfield 427 Harrison Avenue Highland Park, NJ 08904 [email protected] Permission is granted to make and distribute verbatim copes of this manual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the conditions for verbatim copying, provided also that the sections that reprint \The GNU General Public License", \The GNU Library General Public License", and other clearly marked sections held under seperate copyright are reproduced under the conditions given within them, and provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another language under the conditions for modified versions. -

Softwindows™ 95 for UNIX User's Guide (Version 5 of Softwindows
SoftWindows™ 95 for UNIX User’s Guide (Version 5 of SoftWindows 95) Document Number 007-3113-007 CONTRIBUTORS Edited by Karin Borda and Douglas B. O’Morain Production by Carlos Miqueo © 1998, Silicon Graphics, Inc.— All Rights Reserved The contents of this document may not be copied or duplicated in any form, in whole or in part, without the prior written permission of Silicon Graphics, Inc. RESTRICTED RIGHTS LEGEND Use, duplication, or disclosure of the technical data contained in this document by the Government is subject to restrictions as set forth in subdivision (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013 and/or in similar or successor clauses in the FAR, or in the DOD or NASA FAR Supplement. Unpublished rights reserved under the Copyright Laws of the United States. Contractor/manufacturer is Silicon Graphics, Inc., 2011 N. Shoreline Blvd., Mountain View, CA 94043-1389. TurboStart and SoftNode are registered trademarks of Insignia Solutions. SoftWindows is a trademark used under license. Silicon Graphics, the Silicon Graphics logo and IRIX are registered trademarks, and Indy, O2, and IRIS InSight are trademarks of Silicon Graphics, Inc. R5000 and R10000 are registered trademarks of MIPS Technologies, Inc. Apple and Macintosh are registered trademarks of Apple Computer, Inc. DEC is a trademark of Digital Equipment Corporation. WinPost is a trademark of Eastern Mountain Software. FLEXlm is a trademark of Globetrotter Software Inc. IBM is a registered trademark and IBM PC and IBM PC/AT are trademarks of International Business Machines Corp. Intel and Pentium are registered trademarks of Intel Corporation. -

GSI Local Guide
UNIX Primer GSI Local Guide GSI Computing Center Version 2.0 This is draft version !!! Preface: More than one year ago, we published our ®rst version of the Unix primer, which has been used in the meantime by many people at GSI and even in the outside HEP community. Nowadays, as more and more physicists have access to a Unix computer either via a X-terminal or use their own workstation, and as the installed computing power has increased by a large factor, we have revised the ®rst version of our Unix primer. We tried to re¯ect the changes in the installedhardware, like the installationof the 11 machine AIX cluster, and the installationof new software products, as the batch system for job submission, new backup and restore products and the graphics system IDL. Almost all chapters have been revised, and some have undergone substantial changes like the introduction, the section about experimental data and tape handling and the chapter about the editors, where more editors are described in detail. Although many topics are still missing or could be improved, we decided to publishthe second edition of the Unix primer now in order to give a guide to the rapidly increasing Unix user community at GSI. As for the ®rst edition, many people again have contributed to this document: Wolfgang Ahner, Eliete Bertulani, Michael Dahlinger, Matthias Feyerabend, Ingo Giese, Horst GÈoringer, Eva Hocks, Peter Malzacher, Udo Meyer, Kerstin Schiebel, Kay Winkler and Heiko Weber. Preface for Version 1.0: In early summer 1991 the GSI Computing Center started a Unix Pilot Project investigating the hardware and software possibilities of centrally operated unix workstation systems. -

Summary Keyboard Mapping
Technical Bulletin Product: RUMBA OFFICE 2.0 RUMBA for UNIX RUMBA for the VAX Version #: See above Host: UNIX, VAX Summary If you find that one or more of the keys you press in RUMBA for the VAX or RUMBA for UNIX doesn't produce the effect you expect, it may be that there is a mismatch between how the keyboard is mapped in RUMBA software and how the keys are mapped on the host. By remapping the characters that a key sends, RUMBA software can emulate most keyboards and be made to work with almost any application. When a key is pressed one of two things can happen. If the key defines a "local function," RUMBA software performs that function and nothing is sent to the host. One local function is the F2 or PrintScreen key. This function does not require host interaction. RUMBA software simply copies the information from the screen to the printer. If the key does not define a local function then RUMBA will send either a single character or a string of characters to the host. This document describes how to change the character or string of characters sent by RUMBA software when a key is pressed. It also covers some basic ways to determine what the host or application expects. To effectively fix key mapping problems, you will need to talk with your system administrator and possibly with the vendor of the host application you are using. Keyboard Mapping Host applications are written for a specific host keyboard. In the case of DEC and UNIX applications, this keyboard is usually a VT keyboard. -

Latex in Twenty Four Hours
Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide A Short Presentation on Dilip Datta Department of Mechanical Engineering, Tezpur University, Assam, India E-mail: [email protected] / datta [email protected] URL: www.tezu.ernet.in/dmech/people/ddatta.htm Dilip Datta A Short Presentation on LATEX in 24 Hours (1/76) Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide Presentation plan • Introduction to LATEX Dilip Datta A Short Presentation on LATEX in 24 Hours (2/76) Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide Presentation plan • Introduction to LATEX • Fonts selection Dilip Datta A Short Presentation on LATEX in 24 Hours (2/76) Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide Presentation plan • Introduction to LATEX • Fonts selection • Texts formatting Dilip Datta A Short Presentation on LATEX in 24 Hours (2/76) Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide Presentation plan • Introduction to LATEX • Fonts selection • Texts formatting • Listing items Dilip Datta A Short Presentation on LATEX in 24 Hours (2/76) Plan Introduction Fonts Format Listing Tabbing Table Figure Equation Bibliography Article Thesis Slide Presentation plan • Introduction to LATEX • Fonts selection • Texts formatting • Listing items • Tabbing items Dilip Datta A Short Presentation on LATEX