Design of a High Performance Volume Visualization System
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

(12) United States Patent (10) Patent No.: US 7,133,041 B2 Kaufman Et Al
US007133041B2 (12) United States Patent (10) Patent No.: US 7,133,041 B2 Kaufman et al. (45) Date of Patent: Nov. 7, 2006 (54) APPARATUS AND METHOD FOR VOLUME (56) References Cited PROCESSING AND RENDERING U.S. PATENT DOCUMENTS (75) Inventors: Arie E. Kaufman, Plainview, NY (US); 4,314,351 A 2f1982 Postel et al. Ingmar Bitter, Lake Grove, NY (US); 4,371,933 A 2, 1983 Bresenham et al. Frank Dachille, Amityville, NY (US); Kevin Kreeger, East Setauket, NY (Continued) (US); Baoquan Chen, Maple Grove, FOREIGN PATENT DOCUMENTS MN (US) EP O 216 156 A2 4f1987 (73) Assignee: The Research Foundation of State University of New York, Albany, NY (Continued) (US) OTHER PUBLICATIONS (*) Notice: Subject to any disclaimer, the term of this Knittel, G., TriangleCaster: extensions to 3D-texturing units for patent is extended or adjusted under 35 accelerated volume rendering, 1999, Proceedings of the ACM U.S.C. 154(b) by 742 days. SIGGRAPH/EUROGRAPHICS workshop on Graphics hardware, pp. 25-34.* (21) Appl. No.: 10/204,685 (Continued) PCT Fed: Feb. 26, 2001 (22) Primary Examiner Ulka Chauhan (86) PCT No.: PCT/USO1 (O6345 Assistant Examiner Said Broome (74) Attorney, Agent, or Firm Hoffmann & Baron, LLP S 371 (c)(1), (2), (4) Date: Jan. 9, 2003 (57) ABSTRACT (87) PCT Pub. No.: WOO1A63561 An apparatus and method for real-time Volume processing and universal three-dimensional rendering. The apparatus PCT Pub. Date: Aug. 30, 2001 includes a plurality of three-dimensional (3D) memory units; at least one pixel bus for providing global horizontal (65) Prior Publication Data communication; a plurality of rendering pipelines; at least one geometry bus; and a control unit. -

PACKET 22 BOOKSTORE, TEXTBOOK CHAPTER Reading Graphics
A.11 GRAPHICS CARDS, Historical Perspective (edited by J Wunderlich PhD in 2020) Graphics Pipeline Evolution 3D graphics pipeline hardware evolved from the large expensive systems of the early 1980s to small workstations and then to PC accelerators in the 1990s, to $X,000 graphics cards of the 2020’s During this period, three major transitions occurred: 1. Performance-leading graphics subsystems PRICE changed from $50,000 in 1980’s down to $200 in 1990’s, then up to $X,0000 in 2020’s. 2. PERFORMANCE increased from 50 million PIXELS PER SECOND in 1980’s to 1 billion pixels per second in 1990’’s and from 100,000 VERTICES PER SECOND to 10 million vertices per second in the 1990’s. In the 2020’s performance is measured more in FRAMES PER SECOND (FPS) 3. Hardware RENDERING evolved from WIREFRAME to FILLED POLYGONS, to FULL- SCENE TEXTURE MAPPING Fixed-Function Graphics Pipelines Throughout the early evolution, graphics hardware was configurable, but not programmable by the application developer. With each generation, incremental improvements were offered. But developers were growing more sophisticated and asking for more new features than could be reasonably offered as built-in fixed functions. The NVIDIA GeForce 3, described by Lindholm, et al. [2001], took the first step toward true general shader programmability. It exposed to the application developer what had been the private internal instruction set of the floating-point vertex engine. This coincided with the release of Microsoft’s DirectX 8 and OpenGL’s vertex shader extensions. Later GPUs, at the time of DirectX 9, extended general programmability and floating point capability to the pixel fragment stage, and made texture available at the vertex stage. -

3D Computer Graphics Compiled By: H
animation Charge-coupled device Charts on SO(3) chemistry chirality chromatic aberration chrominance Cinema 4D cinematography CinePaint Circle circumference ClanLib Class of the Titans clean room design Clifford algebra Clip Mapping Clipping (computer graphics) Clipping_(computer_graphics) Cocoa (API) CODE V collinear collision detection color color buffer comic book Comm. ACM Command & Conquer: Tiberian series Commutative operation Compact disc Comparison of Direct3D and OpenGL compiler Compiz complement (set theory) complex analysis complex number complex polygon Component Object Model composite pattern compositing Compression artifacts computationReverse computational Catmull-Clark fluid dynamics computational geometry subdivision Computational_geometry computed surface axial tomography Cel-shaded Computed tomography computer animation Computer Aided Design computerCg andprogramming video games Computer animation computer cluster computer display computer file computer game computer games computer generated image computer graphics Computer hardware Computer History Museum Computer keyboard Computer mouse computer program Computer programming computer science computer software computer storage Computer-aided design Computer-aided design#Capabilities computer-aided manufacturing computer-generated imagery concave cone (solid)language Cone tracing Conjugacy_class#Conjugacy_as_group_action Clipmap COLLADA consortium constraints Comparison Constructive solid geometry of continuous Direct3D function contrast ratioand conversion OpenGL between -

Visual Computing Systems CMU 15-769, Fall 2016 Lecture
Lecture 20: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems CMU 15-769, Fall 2016 Today ▪ Real-time 3D graphics workload metrics ▪ Scheduling the graphics pipeline on a modern GPU CMU 15-769, Fall 2016 Quick aside: tessellation CMU 15-769, Fall 2016 Triangle size (data from 2010) 30 20 10 Percentage of total triangles of total Percentage 0 [0-1] [1-5] [5-10] [10-20] [20-30] [30-40] [40-50] [50-60] [60-70] [70-80] [80-90] [90-100] [> 100] Triangle area (pixels) [source: NVIDIA] CMU 15-769, Fall 2016 Low geometric detail Credit: Pro Evolution Soccer 2010 CMU (Konami) 15-769, Fall 2016 Surface tessellation Approximating Subdivision Surfaces with Gregory Patches Procedurally generate Approximatingfne triangle mesh from coarse Subdivision mesh representation Surfaces with Gregory Patches for Hardwarefor Hardware Tessellation Tessellation CharlesCharles Loop Loop Scott SchaeferScott Schaefer TianyunTianyun Ni NiIgnacio Casta˜noIgnacio Casta˜no MicrosoftMicrosoft Research Research TexasTexas A&M A&M University University NVIDIANVIDIA NVIDIA NVIDIA Coarse geometry Post-Tessellation (fne) geometry [image credit:Figure Loop et al. 1: 2009]The first image (far left) illustrates an input control mesh; CMUregular 15-769, Fall 201 (gold)6 faces do not have an incident extraordinary vertex, irregularFigure quads 1: The (purple) first haveimage at (far least left) one extraordinary illustrates an ve inputrtex, and control triangular mesh; (green)regular faces (gold) are allowed. faces do The not second have an and incident third images extraordinary show vertex, theirregular parametric quads patches (purple) we generate. have at The least final one image extraordinary is of the same vertex, surface and with triangular a displacement (green) map faces applied. -

Opengl Performer™ Programmer's Guide
OpenGL Performer™ Programmer’s Guide 007-1680-060 CONTRIBUTORS Written by George Eckel and Ken Jones Edited by Rick Thompson and Susan Wilkening Illustrated by Chrystie Danzer and Chris Wengelski Production by Adrian Daley and Karen Jacobson Engineering contributions by Angus Dorbie, Tom Flynn, Yair Kurzion, Radomir Mech, Alexandre Naaman, Marcin Romaszewicz, Allan Schaffer, and Jenny Zhao COPYRIGHT © 1997, 2000 Silicon Graphics, Inc. All rights reserved; provided portions may be copyright in third parties, as indicated elsewhere herein. No permission is granted to copy, distribute, or create derivative works from the contents of this electronic documentation in any manner, in whole or in part, without the prior written permission of Silicon Graphics, Inc. LIMITED RIGHTS LEGEND The electronic (software) version of this document was developed at private expense; if acquired under an agreement with the USA government or any contractor thereto, it is acquired as "commercial computer software" subject to the provisions of its applicable license agreement, as specified in (a) 48 CFR 12.212 of the FAR; or, if acquired for Department of Defense units, (b) 48 CFR 227-7202 of the DoD FAR Supplement; or sections succeeding thereto. Contractor/manufacturer is Silicon Graphics, Inc., 1600 Amphitheatre Pkwy 2E, Mountain View, CA 94043-1351. TRADEMARKS AND ATTRIBUTIONS Silicon Graphics,IRIS, IRIS Indigo, IRIX, ImageVision Library, Indigo, Indy, InfiniteReality, Onyx, OpenGL, are registered trademarks, SGI, and CASEVision, Crimson, Elan Graphics, IRIS Geometry Pipeline, IRIS GL, IRIS Graphics Library, IRIS InSight, IRIS Inventor, Indigo Elan, Indigo2, InfiniteReality2, OpenGL Performer, Personal IRIS, POWER Series, Performance Co-Pilot, RealityEngine, RealityEngine2, SGI logo, and Showcase are trademarks of Silicon Graphics, Inc. -

Appendix C Graphics and Computing Gpus
C APPENDIX Graphics and Computing GPUs John Nickolls Imagination is more Director of Architecture important than NVIDIA knowledge. David Kirk Chief Scientist Albert Einstein On Science, 1930s NVIDIA C.1 Introduction C-3 C.2 GPU System Architectures C-7 C.3 Programming GPUs C-12 C.4 Multithreaded Multiprocessor Architecture C-24 C.5 Parallel Memory System C-36 C.6 Floating-point Arithmetic C-41 C.7 Real Stuff: The NVIDIA GeForce 8800 C-45 C.8 Real Stuff: Mapping Applications to GPUs C-54 C.9 Fallacies and Pitfalls C-70 C.10 Concluding Remarks C-74 C.11 Historical Perspective and Further Reading C-75 C.1 Introduction Th is appendix focuses on the GPU—the ubiquitous graphics processing unit graphics processing in every PC, laptop, desktop computer, and workstation. In its most basic form, unit (GPU) A processor the GPU generates 2D and 3D graphics, images, and video that enable window- optimized for 2D and 3D based operating systems, graphical user interfaces, video games, visual imaging graphics, video, visual computing, and display. applications, and video. Th e modern GPU that we describe here is a highly parallel, highly multithreaded multiprocessor optimized for visual computing. To provide visual computing real-time visual interaction with computed objects via graphics, images, and video, A mix of graphics the GPU has a unifi ed graphics and computing architecture that serves as both a processing and computing programmable graphics processor and a scalable parallel computing platform. PCs that lets you visually interact with computed and game consoles combine a GPU with a CPU to form heterogeneous systems. -

An Introductory Tour of Interactive Rendering by Eric Haines, [email protected]
An Introductory Tour of Interactive Rendering by Eric Haines, [email protected] [near-final draft, 9/23/05, for IEEE CG&A January/February 2006, p. 76-87] Abstract: The past decade has seen major improvements, in both speed and quality, in the area of interactive rendering. The focus of this article is on the evolution of the consumer-level personal graphics processor, since this is now the standard platform for most researchers developing new algorithms in the field. Instead of a survey approach covering all topics, this article covers the basics and then provides a tour of some parts the field. The goals are a firm understanding of what newer graphics processors provide and a sense of how different algorithms are developed in response to these capabilities. Keywords: graphics processors, GPU, interactive, real-time, shading, texturing In the past decade 3D graphics accelerators for personal computers have transformed from an expensive curiosity to a basic requirement. Along the way the traditional interactive rendering pipeline has undergone a major transformation, from a fixed- function architecture to a programmable stream processor. With faster speeds and new functionality have come new ways of thinking about how graphics hardware can be used for rendering and other tasks. While expanded capabilities have in some cases simply meant that old algorithms could now be run at interactive rates, the performance characteristics of the new hardware has also meant that novel approaches to traditional problems often yield superior results. The term “interactive rendering” can have a number of different meanings. Certainly the user interfaces for operating systems, photo manipulation capabilities of paint programs, and line and text display attributes of CAD drafting programs are all graphical in nature. -

Linzhi Working Papers Posts Against Progpow
Linzhi Semiconductors Linzhi Working Papers No 15 Posts against ProgPoW - 2019 May-Sep September 2019 Keywords: LWP15, ProgPoW, Resistance, Ethereum This publication is available on https://linzhi.io Telegram discussion https://t.me/LinzhiCorp All original rights for text and media are released into the public domain, attribution welcome. Rights of quoted or translated sources remain with their respective owners. 9/25/2019 Posts Against ProgPoW - 2019 May-Sep Posts Against ProgPoW - 2019 May-Sep This is a collection of Linzhi's debate contributions from May to September 2019, with contextual contributions by Tim Olson, OhGodAGirl (Kristy-Leigh Minehan) and others. The purpose of this collection is to document the authenticity and validity of Linzhi's contributions, and to serve as a focal point for further investigations into ProgPoW. The full threads on the Ethereum Magicians Forum are hard to parse because of repeated attempts to derail the conversation. We do not attempt to provide any documentation of the pro-ProgPoW arguments, and include such posts only where necessary to provide context. We add that we observed editing and deleting of pro-ProgPoW posts in social media, weeks or months after posts were made. We also suspect, without evidence other than eyebrow-raising continuity of some details, that several authors writing pro-ProgPoW posts under a variety of accounts are in fact all writing in a coordinated way. This collection merges posts from both threads chronologically. The collection ends with Linzhi's last contribution on September 6, 2019. Sources: EIP-ProgPoW: a Programmatic Proof-of-Work (2018-05-03) https://ethereum-magicians.org/t/progpow-audit-delay-issue/272 ProgPoW Audit Delay Issue (2019-05-23) https://ethereum-magicians.org/t/progpow-audit-delay-issue/3309 Linzhi Team, Shenzhen, September 25, 2019 Telegram: t.me/LinzhiCorp ifdefelse #1 January 16, 2019, 7:23am We propose an alternate proof-of-work algorithm tuned for commodity hardware in order to close the efficiency gap available to specialized ASICs. -

Visual Computing Systems Stanford CS348K, Spring 2020 Lecture
Lecture 14: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems Stanford CS348K, Spring 2020 Today ▪ Real-time 3D graphics workload metrics ▪ Scheduling the graphics pipeline on a modern GPU Stanford CS348K, Spring 2020 Quick Review Stanford CS348K, Spring 2020 Real-time graphics pipeline architecture Memory Buffers (system state) 3 1 Vertex Generation 4 Vertex data buffers 2 Vertices Vertex stream Vertex Processing Buffers, textures Vertex stream Primitive Generation Primitive stream Primitives Primitive Processing Buffers, textures Primitive stream Fragment Generation (Rasterization) Fragment stream Fragments Fragment Processing Buffers, textures Fragment stream Pixels Pixel Operations Output image buffer Stanford CS348K, Spring 2020 Programming the graphics pipeline ▪ Issue draw commands output image contents change Command Type Command State change Bind shaders, textures, uniforms Draw Draw using vertex buffer for object 1 State change Bind new uniforms Draw Draw using vertex buffer for object 2 State change Bind new shader Draw Draw using vertex buffer for object 3 State change Change depth test function State change Bind new shader Draw Draw using vertex buffer for object 4 Final rendered output should be consistent with the results of executing these commands in the order they are issued to the graphics pipeline. Stanford CS348K, Spring 2020 GPU: heterogeneous parallel processor SIMD SIMD SIMD SIMD Texture Texture Exec Exec Exec Exec Cache Cache Cache Cache Texture Texture SIMD SIMD SIMD SIMD Tessellate Tessellate Exec Exec -

April/May 1997
APRIL/MAY 1997 GAME DEVELOPER MAGAZINE GAME PLAN Chapter IV: A New Hope EDITOR IN CHIEF Alex Dunne [email protected] MANAGING EDITOR Tor D. Berg hen engaged in a With this issue we also kick off our [email protected] long-term project, it’s new design, which is more dynamic EDITORIAL ASSISTANT Chris Minnick cminnick@mfi.com helpful to stop what and visual than our old look. It’s also CONTRIBUTING EDITORS Larry O’Brien W you’re doing once in a more playful, which is certainly in [email protected] while and assess your progress. Are you keeping with the spirit of our creative Chris Hecker on schedule? Will you reach your community. I hope you’ll appreciate [email protected] goals? Perhaps more importantly, are the new aspects of the design, and we David Seiks [email protected] your goals still valid, or has the market- trust you’ll give us your feedback on Ben Sawyer place changed enough to warrant a what’s working and what isn’t. [email protected] change in your plans? This issue also marks the beginning ADVISORY BOARD Hal Barwood Here at Game Developer, we decided of a new program designed to promote Noah Falstein that it was time to do just such an the talents of game artists and anima- Susan Lee-Merrow assessment of the magazine. It’s been tors. Each issue will feature custom art- Mark Miller three years since a group of editors work by artists in the industry. You can Josh White (notably Alexander Antoniades — check out a short bio about the artist 6 thanks Sander!) dreamt up a magazine and the tools they used to create the COVER IMAGE Vector Graphics aimed at game programmers. -

Fakultet Za Informatiku I Menadžment
FAKULTET ZA INFORMATIKU I MENADŽMENT Dilara Kuscuoglu REKLAMA ZA AUTOMOBIL – Diplomski rad – 1 FAKULTET ZA INFORMATIKU I MENADŽMENT REKLAMA ZA AUTOMOBIL – Diplomski rad – Mentor: Student: Prof. dr Dragan Cvetković Dilara Kuscuoglu Broj indeksa: 160/2003 2 UNIVERZIET SINGIDUNUM FAKULTET ZA INFORMATIKU I MENADŽMENT Beograd, Danijelova 32 Kandidat: Dilara Kuscuoglu Broj indeksa: 160/2003 Smer: Grafički dizajn Tema: REKLAMA ZA AUTOMOBIL Zadatak: Napraviti reklamni spot za automobil. Objasniti proces modelovanja i proces izrade reklame. MENTOR: DEKAN: _____________________ _____________________ Prof. dr Dragan Cvetković Prof. dr Milan Milosavljević 3 SADRŽAJ: REZIME…………………………………………………………………………………7 UVOD.............................……………………………………………………...………8 RAČUNARSKA GRAFIKA……………………………………………..…………....9 3D RAČUNARSKA GRAFIKA....…………………………………….…………….10 ISTORIJA 3D RAČUNARSKE GRAFIKE…………………..…………………….11 BUDUĆNOST 3D GRAFIKE………………………………………..………………12 3D MODELOVANJE…………………………………………................................13 FIZIČKA SIMULACIJA.....................................................................................13 PROCES 3D MODELOVANJA.................................................................14 POLIGONO MODELOVANJE...........................................................................14 NURBS..............................................................................................................14 LAYOUT I ANIMACIJA.....................................................................................15 ORGANIZACIJA SCENE..................................................................................15 -
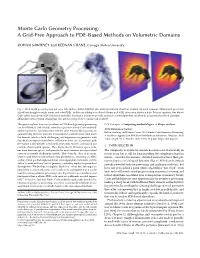
Monte Carlo Geometry Processing:A Grid-Free Approach to PDE-Based
Monte Carlo Geometry Processing: A Grid-Free Approach to PDE-Based Methods on Volumetric Domains ROHAN SAWHNEY and KEENAN CRANE, Carnegie Mellon University Fig. 1. Real-world geometry has not only rich surface detail (left) but also intricate internal structure (center). On such domains, FEM-based geometric algorithms struggle to mesh, setup, and solve PDEs—in this case taking more than 14 hours and 30GB of memory just for a basic Poisson equation. Our Monte Carlo solver uses about 1GB of memory and takes less than a minute to provide a preview (center right) that can then be progressively refined (far right). [Boundary mesh of Fijian strumigenys FJ13 used courtesy of the Economo Lab at OIST.] This paper explores how core problems in PDE-based geometry processing CCS Concepts: • Computing methodologies ! Shape analysis. can be efficiently and reliably solved via grid-free Monte Carlo methods. ACM Reference Format: Modern geometric algorithms often need to solve Poisson-like equations on Rohan Sawhney and Keenan Crane. 2020. Monte Carlo Geometry Processing: geometrically intricate domains. Conventional methods most often mesh A Grid-Free Approach to PDE-Based Methods on Volumetric Domains. ACM the domain, which is both challenging and expensive for geometry with Trans. Graph. 38, 4, Article 1 (July 2020), 18 pages. https://doi.org/XX fine details or imperfections (holes, self-intersections, etc.). In contrast, grid- free Monte Carlo methods avoid mesh generation entirely, and instead just evaluate closest point queries. They hence do not discretize space, time, 1 INTRODUCTION nor even function spaces, and provide the exact solution (in expectation) The complexity of geometric models has increased dramatically in even on extremely challenging models.