Deep Learning for Image-Based Large-Flowered Chrysanthemum
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Establishment of a Global Network for the in Situ Conservation of Crop Wild Relatives: Status and Needs
THEMATIC BACKGROUND STUDY Establishment of a Global Network for the In Situ Conservation of Crop Wild Relatives: Status and Needs Nigel Maxted and Shelagh Kell BACKGROUND STUDY PAPER NO. 39 October 2009 COMMISSION ON GENETIC RESOURCES FOR FOOD AND AGRICULTURE ESTABLISHMENT OF A GLOBAL NETWORK FOR THE IN SITU CONSERVATION OF CROP WILD RELATIVES: STATUS AND NEEDS by *By Nigel Maxted and Shelagh Kell The content of this document is entirely the responsibility of the authors, and does not .necessarily represent the views of the FAO, or its Members 2 * School of Biosciences, University of Birmingham. Disclaimer The content of this document is entirely the responsibility of the authors, and does not necessarily represent the views of the Food and Agriculture Organization of the United Nations (FAO), or its Members. The designations employed and the presentation of material do not imply the expression of any opinion whatsoever on the part of FAO concerning legal or development status of any country, territory, city or area or of its authorities or concerning the delimitation of its frontiers or boundaries. The mention of specific companies or products of manufacturers, whether or not these have been patented, does not imply that these have been endorsed by FAO in preference to others of a similar nature that are not mentioned. CONTENTS SUMMARY 6 ACKNOWLEDGEMENTS 7 PART 1: INTRODUCTION 8 1.1 Background and scope 8 1.2 The global and local importance of crop wild relatives 10 1.3 Definition of a crop wild relative 12 1.4 Global numbers of crop -

50 Years of the International Code of Nomenclature for Cultivated Plants: Future Prospects for the Code
50 Years of the International Code of Nomenclature for Cultivated Plants: Future Prospects for the Code P. Trehane 2 Pye Corner Wimborne Dorset, BH21 1UL United Kingdom Keywords: culton, cultivar-group, history, International Association for Cultivated Plant Taxonomy, linguistics, plant breeders’ rights, trademarks Abstract The first edition of the International Code of Nomenclature for Cultivated Plants was published in June 1953 by the Royal Horticultural Society as a preprint from the Report of the Thirteenth International Horticultural Congress held in London, September 1952, and has undergone a total of six editions, the last being in 1995. This presentation sets the scene for discussions on nomenclature issues which form one of purposes of this Symposium by reviewing past editions of the Code and illustrating a few of the problems confronting the formulation of a new edition. The need for international co-operation between statutory and non-statutory bodies in the various acts of nomenclature and taxonomy is highlighted. INTRODUCTION As the speaker following will describe (McNeill, these proceedings), before the advent of the International Code of Nomenclature for Cultivated Plants (Stearn, 1953a) otherwise known as the Cultivated Plant Code or ICNCP, the formal rules for naming cultivated plants was largely governed through the International Rules of Botanical Nomenclature through its various editions up until the Stockholm Code of 1952. In that Code a proposed set of rules for governing names of cultivated plants was presented in its Appendix III. In introducing that Appendix, it was stated that the regulations would not become official until formally accepted by the 13th International Horticultural Congress to be held in London in late 1952. -

Cultonomy of Aster +
Acta Bot. Need. 45(2), June 1996, p. 173-181 Cultonomy of Aster L. W.L.A. Hetterscheidi* and R.G. van den Berg+ *Vaste Keurings Commissie, Linnaeuslaan 2a, 1431 JV Aalsmeer, The Netherlands; and tDepartment ofPlant Taxonomy, Wageningen Agricultural University, PO Box 8010, 6700 ED Wageningen, The Netherlands SUMMARY Recent increase in commercial breeding in the genus Aster of cultivars particularly suitable for the cut-flower industry calls for a reassessment of the systematics of cultivated asters. A system of three is here of the cultivar-groups proposed to encompass most diversity of cultivars based on typical user criteria: the Dumosus Group, the Universum Group and the Novi-belgii Group. The applicability of numerical character analysis for cultonomic classification is outlined. The flexibility of open (‘cultonomic’) classifications for culta is demonstrated. It is shown that this system of cultivar-groups serves stability much better in the application of names to Aster cultivars than the continued use of Latin binomials. The use of the culton concept and its consequences for classifying Aster cultivars is outlined. Key-words: Aster, cluster analysis, cultivar-group, culton, cultonomy, taxonomy. INTRODUCTION Species and cultivars of the genus Aster L. have long been in cultivation, especially as garden plants. A relatively small number of all cultivated species has been used in breeding programmes, e.g. A. alpinus L., A. amellus L., A. cordifolius L., A. dumosus L., A. laevis L., A. lanceolatus Willd., A. lateriflorus (L.) Britton, A. novae-angliae L., tradescantii A. novi-belgii L. and A. L. Interspecific hybridization has led to an array of cultivars suitable for the garden, for the cut-flower industry, or for both. -

Botanical Classification and Nomenclature an Introduction —
Botanical classification and nomenclature an introduction — Marc S.M. Sosef Jérôme Degreef Henry Engledow Pierre Meerts Botanical classification and nomenclature an introduction — Marc S.M. Sosef Jérôme Degreef Henry Engledow Pierre Meerts by Marc S.M. Sosef1, Jérôme Degreef1,2, Henry Engledow1 & Pierre Meerts3 1 Meise Botanic Garden, Nieuwelaan 38, B-1860 Meise, Belgium 2 Service Général de l’Enseignement supérieur et de la Recherche scientifique, Fédération Wallonie-Bruxelles, Rue A. Lavallée 1, B-1080 Brussels, Belgium 3 Herbarium et bibliothèque de botanique africaine, Université Libre de Bruxelles, Av. F.D. Roosevelt 50, CP 265, B-1050 Brussels, Belgium Copyright © 2020 Meise Botanic Garden, Nieuwelaan 38, 1860 Meise, Belgium. Printed in Belgium by Gewadrupo, Arendonk. This publication is published and distributed in Open Access under the Creative Commons Attribution 4.0 International license (CC-BY 4.0), which permits use, distribution, and reproduction in any medium, provided the original work is properly cited. A PDF file of this publication can be ordered, free of charge (send an email to [email protected]), or downloaded from the webshop of Meise Botanic Garden at http://shopbotanicgarden.weezbe.com. DOI: 10.5281/zenodo.3706707 CIP Royal Library Albert I, Brussels Botanical classification and nomenclature, an introduction. Marc S.M. Sosef, Jérôme Degreef, Henry Engledow & Pierre Meerts - Meise, Meise Botanic Garden, 2020. - 72 p.; ill.; 22 x 15 cm. ISBN 9789492663207 Subject: Botany D/2020/0325/002 Content Introduction . 5 1. The history of classification . 9 1.1 Theophrastus to the Middle Ages . 11 1.2 Renaissance, Pre-Linnean period . 13 1.3 Linnaeus and the Linnaeans . -

Oh-Rock") Cutlivar Registration Project Authors May Reuse with Attribution All Text but No Images in This File for the Purposes of Promoting New Cultivars
Copyright 2016. Laurence C. Hatch. All Rights Reserved. Please visit www.cultivar.org for more information on the OROC ("oh-rock") cutlivar registration project Authors may reuse with attribution all text but no images in this file for the purposes of promoting new cultivars. ' Please read OROC terms at cultivar.org before attempting use of this material. We have endeavored to produce as accurate and useful descriptions as possible based on all available information on these new and often very rare cultivars. This registry is never finished so if you know more (and can document it) please contact us at [email protected] with OROC in your subject line. Where no descriptions are placed please rely on the under URL link to view the originator's or a major vendor's description. By current plans, Book V or VI will be an additional woody plant register with new additions, updated data, and other features. Book III will be Genera N to Z. Your data submissions today will make those free books happen. Thank you in advance. Before I ramble on...OROC is not pronounced like a popular, light weight, hotel lobby vacuum cleaner but as "Oh-rock" something like the snazzy and garish lime green or orange IROC Chevy Camero you or your dad may have had in high school. If you're a Millennial...Google IROC before your phone catches fire. Hope that helps. We hope to rock. We wish we could delay publication until every last detail of every cultivar was nailed down, vouchered, taxonomically perfect, sealed in plexiglass domes for all time, DNA fingerprinted, placed in foirty-six reference LEED Gold certified Green collections, and otherwise documented to near perfection. -

UF Savanna Cultivar Group—Eight Colors of Heat-Tolerant Lisianthus
HORTSCIENCE 41(3):850–854. 2006. edge, ‘Savanna Blue Frost’ and ‘Savanna Pink Frost’ fl ower colors are not available in other UF Savanna Cultivar Group—Eight commercial pot type lisianthus. Colors of Heat-tolerant Lisianthus for Origin ‘UF Savanna Blue’ is an F1 hybrid result- Potted Plants ing from crossing inbred lines UF03-1240 and UF00-770A (Fig. 2). UF03-1240 was chosen Brent K. Harbaugh and Zhanao Deng for its large pink fl owers, intermediate plant University of Florida, Institute of Food and Agricultural Sciences, Environmental height, sturdy branches and heat-tolerance. Horticulture Department, Gulf Coast Research and Education Center, 14625 UF00-770A was selected for its bright blue CR 672, Wimauma, FL 33598 fl owers and semi-dwarf height. UF03-1240 was the F7 selection of a cross Additional index words. high temperature, rosette, potted fl owering plants, Eustoma between UF96-404 and a selection of ‘Mariachi grandifl orum, Gentianaceae, plant breeding Double Pink’. A plant with large pink single fl owers was selected in the F2 and inbred seven generations selecting for shorter plants and A lisianthus [Eustoma grandifl orum (Raf.) is represented with eight colors including blue, heat-tolerance. UF96-404 was a semi-dwarf Shinners; Gentianaceae Juss.] breeding pro- pink, white, silver, blue rim, pink rim, blue selection of UF95-321 (Harbaugh and Scott, gram was initiated in 1985 at the University frost, and pink frost (Fig. 1). To our knowl- 1999) chosen for its bright pink fl owers and of Florida’s Gulf Coast Research and Educa- tion Center, Bradenton. The emphasis was on development of pot or bedding plant types with heat-tolerance and and basal branching pot and bedding plant types. -

Brassica Rapa Cultivar Rcbr Showing Growth Stages at Various Times from Seeding Until 28 Days
Chapter 1 Rapid-Cycling Brassicas (RCB's) in Hands-on Teaching of Plant Biology Paul H. Williams Department of Plant Pathology Russell Laboratories University of Wisconsin-Madison Madison, WI 53706 Paul H. Williams received his B.S.A. degree in Plant Science from the University of British Columbia in 1959, and his Ph.D. in Plant Pathology/Botany from the University of Wisconsin-Madison in 1962. He is currently Professor of Plant Pathology at the University of Wisconsin-Madison. Williams is the Principal Investigator of the NSF funded Wisconsin Fast Plants Instructional materials Development Program. His research interests include the development of multiple resistance (MDR) screening technology, genetics of and breeding for MDR in Brassica and Raphanus, and the development and distribution of rapid-cycling stocks of crucifers, including Brassica, Raphanus, and Arabidopsis through the Crucifer Genetics Cooperative. 1 Educational Uses of the Rapid-cycling Brassicas INTRODUCTION The development of rapid-cycling brassicas (RCB's) as model organisms for research and education is profoundly influencing the quality of science education at all levels by bringing dynamic living materials into the classroom. Most biology courses lack convenient living materials; many use animals predominantly. General and advanced courses in biology, botany, science education and applied plant sciences usually lack suitable living plant material that would permit students to explore plant growth and development, physiology, reproduction, genetics, evolution and ecology. These speedy relatives of mustard are particularly amenable to classroom settings because they show remarkably rapid development (Figure 1), they flower in 13 to 18 days, they are small, and they can reproduce at high densities (up to 2500 plants per square meter) under fluorescent lighting in a classroom. -

Plant Nomenclature and Taxonomy an Horticultural and Agronomic Perspective
3913 P-01 7/22/02 4:25 PM Page 1 1 Plant Nomenclature and Taxonomy An Horticultural and Agronomic Perspective David M. Spooner* Ronald G. van den Berg U.S. Department of Agriculture Biosystematics Group Agricultural Research Service Department of Plant Sciences Vegetable Crops Research Unit Wageningen University Department of Horticulture PO Box 8010 University of Wisconsin 6700 ED Wageningen 1575 Linden Drive The Netherlands Madison Wisconsin 53706-1590 Willem A. Brandenburg Plant Research International Wilbert L. A. Hetterscheid PO Box 16 VKC/NDS 6700 AA, Wageningen Linnaeuslaan 2a The Netherlands 1431 JV Aalsmeer The Netherlands I. INTRODUCTION A. Taxonomy and Systematics B. Wild and Cultivated Plants II. SPECIES CONCEPTS IN WILD PLANTS A. Morphological Species Concepts B. Interbreeding Species Concepts C. Ecological Species Concepts D. Cladistic Species Concepts E. Eclectic Species Concepts F. Nominalistic Species Concepts *The authors thank Paul Berry, Philip Cantino, Vicki Funk, Charles Heiser, Jules Janick, Thomas Lammers, and Jeffrey Strachan for review of parts or all of our paper. Horticultural Reviews, Volume 28, Edited by Jules Janick ISBN 0-471-21542-2 © 2003 John Wiley & Sons, Inc. 1 3913 P-01 7/22/02 4:25 PM Page 2 2 D. SPOONER, W. HETTERSCHEID, R. VAN DEN BERG, AND W. BRANDENBURG III. CLASSIFICATION PHILOSOPHIES IN WILD AND CULTIVATED PLANTS A. Wild Plants B. Cultivated Plants IV. BRIEF HISTORY OF NOMENCLATURE AND CODES V. FUNDAMENTAL DIFFERENCES IN THE CLASSIFICATION AND NOMENCLATURE OF CULTIVATED AND WILD PLANTS A. Ambiguity of the Term Variety B. Culton Versus Taxon C. Open Versus Closed Classifications VI. A COMPARISON OF THE ICBN AND ICNCP A. -

Apple Cultivars Bred in Holovousy. Part 2 – Fruit Characteristics and Their Storage Potential
Vol. 40, 2013, No. 2: 52–57 Hort. Sci. (Prague) Apple cultivars bred in Holovousy. Part 2 – Fruit characteristics and their storage potential J. Blažek, J. Křelinová, M. Šecová Research and Breeding Institute of Pomology Holovousy Ltd., Holovousy, Czech Republic Abstract Blažek J., Křelinová J., Šecová M., 2012. Apple cultivars bred in Holovousy. Part 2 – Fruit characteristics and their storage potential. Hort. Sci. (Prague), 40: 52–57. In continuation of a previous study concerning tree performance and yield characteristics of 20 Holovousy-bred apple cultivars, their fruit characteristics and storage potential were evaluated during 2006–2011 in comparison to commercial standards (Golden Delicious and Jonagold). Fruits of Meteor cv. had the longest storage potential, exceeding six months. It was followed in this respect by cvs Rubimeg, Zuzana, Rucla and Angold that were better than both standards. Mean fruit sizes of cvs Meteor, Angold, Mivibe, Nabella and Zuzana were larger than the standards. Fruits of cultivar Rubin- step were evaluated as the most attractive. In this respect also Rubimeg, Meteor and Rucla were remarkable. Regarding total taste Rucla cv. was the clear winner, followed by cvs Meteor, Rubinstep, Rubimeg and Angold. Regarding total fruit quality cvs Meteor, Rucla and Rubinstep were better than standards. Besides these cultivars, Angold, Fragrance, Julia and Selena were evaluated on the level comparable to standards. Keywords: time of consumption; fruit size; fruit appearance; fruit taste; total fruit quality This paper is focused on the evaluation of fruit MATERIAL AND METHOds quality of apple cultivars bred in Holovousy, as a continuation of a previous study concerning their This study took place in Holovousy during vigour and yield performance. -

International Code of Nomenclature for Cultivated Plants
INTERNATIONAL CODE OF NOMENCLATURE FOR CULTIVATED PLANTS (ICNCP or Cultivated Plant Code) incorporating the Rules and Recommendations for naming plants in cultivation Ninth Edition Adopted by the International Union of Biological Sciences International Commission for the Nomenclature of Cultivated Plants Prepared and edited by C.D. Brickell (Commission Chairman), C. Alexander, J.J. Cubey, J.C. David, M.H.A. Hoffman, A.C. Leslie, V. Malécot, Xiaobai Jin, members of the Editorial Committee June, 2016 ISSN 1813-9205 ISBN 978-94-6261-116-0, Scripta Horticulturae Number 18 Published by ISHS, June 2016 Executive Director of ISHS: Ir. J. Van Assche ISHS Secretariat, PO Box 500, 3001 Leuven 1, Belgium Printed by Drukkerij Station Drukwerk, PO Box 3099, 2220 CB Katwijk aan Zee, The Netherlands © 2016 by the International Society for Horticultural Science (ISHS). All rights reserved. No part of this book may be reproduced and/or published in any form or by any means, electronic or mechanical, including photocopying, microfilm and recording, or by any information storage and retrieval system, without written permission from the publishers. Photograph on the front cover: Lettuce trial 2003. Credit: RHS / Jacquie Gray. Contents CONTENTS Foreword v Membership of the IUBS International Commission for the Nomenclature of Cultivated vii Plants Preface ix Comparison between the 2009 Code and this edition xii New provisions xv Important dates in this Code xvi Previous editions of this Code xvii PREAMBLE 1 DIVISION I: PRINCIPLES 3 DIVISION II: RULES AND -
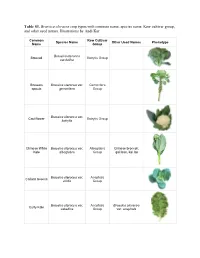
Table S1. Brassica Oleracea Crop Types with Common Name, Species Name, Kew Cultivar Group, and Other Used Names
Table S1. Brassica oleracea crop types with common name, species name, Kew cultivar group, and other used names. Illustrations by Andi Kur. Common Kew Cultivar Species Name Other Used Names Phenotype Name Group Brassica oleracea Broccoli Botrytis Group var.italica Brussels Brassica oleracea var. Gemmifera spouts gemmifera Group Brassica oleracea var. Cauliflower Botrytis Group botrytis Chinese White Brassica oleracea var. Alboglabra Chinese broccoli, Kale alboglabra Group gai laan, kai lan Brassica oleracea var. Acephala Collard Greens viridis Group Brassica oleracea var. Acephala Brassica oleracea Curly Kale sabellica Group var. acephala Jersey Cabbage, Cow cabbage, Giant Jersey Brassica oleracea var. Acephala Walking stick kale, Kale longata Group Couve Galega, Portuguese tree kale Brassica oleracea var. Gongylodes Kohlrabi gongylodes Group Brassica oleracea var. Acephala Lacinato kale palmifolia Group Marrow Brassica oleracea var. Acephala Brassica oleracea Cabbage medullosa Group var. acephala Ornamental Brassica oleracea var. Acephala cabbage acephala Group Brassica oleracea var. Acephala Brassica oleracea Perpetual Kale ramosa Group var. acephala Brassica oleracea var. Red Cabbage Capitata Group capitata f. rubra Brassica oleracea var. Romanesco Botrytis Group botrytis Savoy Brassica oleracea var. Capitata Group Cabbage capitata f. sabauda Tronchuda Brassica oleracea var. Tronchuda Portuguese cabbage, Kale costata Group seakale cabbage Brassica oleracea var. White Cabbage Capitata Group capitata f. alba Table S2. Sample information -

Variation in Pawpaw (Asimina Triloba L. Dunal) Productivity and Fruit Quality Among Cultivars and Orchards in Ohio
Variation in Pawpaw (Asimina triloba L. Dunal) Productivity and Fruit Quality Among Cultivars and Orchards in Ohio THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Sarah E. Francino Graduate Program in Environment & Natural Resources The Ohio State University 2019 Master's Examination Committee: Professor G. Matt Davies, Advisor Professor Joseph Scheerens Professor Shoshanah Inwood Brad Bergefurd Copyrighted by Sarah E. Francino 2019 Abstract Natural environmental gradients affect crop productivity; while the same is true for genetic and agronomic factors these can be controlled by the grower. Growers have to choose cultivars, rootstocks, and agronomic inputs that account for environmental factors to gain consistent yields and high-quality produce. For many emerging fruit crops, such as pawpaw (Asimina triloba L. Dunal), factors controlling yield and quality still need to be properly understood. The pawpaw is a fruit tree native to the Eastern United States and has a rapidly growing market. How environmental gradients, cultivars, and agronomic inputs influence the yield and quality of a pawpaw fruit harvest has not been studied extensively. This study’s aim was to investigate the relationship between environmental factors and cultivar identity in terms of fruit yield and quality. Eight commercial and semi-commercial orchards across the State of Ohio had flower counts and fruit counts performed on them for 24 cultivars. Fruits were counted by four size classes based on their length and width to estimate the yield. Allometric relationships between fruit size, total mass, and pulp mass were investigated to predict the total pulp and fruit masses for each tree by cultivar.