Mapping Crop Field Probabilities Using Hyper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Districts of Ethiopia
Region District or Woredas Zone Remarks Afar Region Argobba Special Woreda -- Independent district/woredas Afar Region Afambo Zone 1 (Awsi Rasu) Afar Region Asayita Zone 1 (Awsi Rasu) Afar Region Chifra Zone 1 (Awsi Rasu) Afar Region Dubti Zone 1 (Awsi Rasu) Afar Region Elidar Zone 1 (Awsi Rasu) Afar Region Kori Zone 1 (Awsi Rasu) Afar Region Mille Zone 1 (Awsi Rasu) Afar Region Abala Zone 2 (Kilbet Rasu) Afar Region Afdera Zone 2 (Kilbet Rasu) Afar Region Berhale Zone 2 (Kilbet Rasu) Afar Region Dallol Zone 2 (Kilbet Rasu) Afar Region Erebti Zone 2 (Kilbet Rasu) Afar Region Koneba Zone 2 (Kilbet Rasu) Afar Region Megale Zone 2 (Kilbet Rasu) Afar Region Amibara Zone 3 (Gabi Rasu) Afar Region Awash Fentale Zone 3 (Gabi Rasu) Afar Region Bure Mudaytu Zone 3 (Gabi Rasu) Afar Region Dulecha Zone 3 (Gabi Rasu) Afar Region Gewane Zone 3 (Gabi Rasu) Afar Region Aura Zone 4 (Fantena Rasu) Afar Region Ewa Zone 4 (Fantena Rasu) Afar Region Gulina Zone 4 (Fantena Rasu) Afar Region Teru Zone 4 (Fantena Rasu) Afar Region Yalo Zone 4 (Fantena Rasu) Afar Region Dalifage (formerly known as Artuma) Zone 5 (Hari Rasu) Afar Region Dewe Zone 5 (Hari Rasu) Afar Region Hadele Ele (formerly known as Fursi) Zone 5 (Hari Rasu) Afar Region Simurobi Gele'alo Zone 5 (Hari Rasu) Afar Region Telalak Zone 5 (Hari Rasu) Amhara Region Achefer -- Defunct district/woredas Amhara Region Angolalla Terana Asagirt -- Defunct district/woredas Amhara Region Artuma Fursina Jile -- Defunct district/woredas Amhara Region Banja -- Defunct district/woredas Amhara Region Belessa -- -
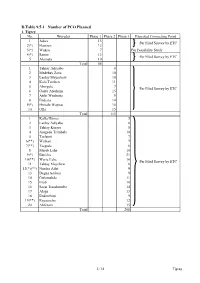
D.Table 9.5-1 Number of PCO Planned 1
D.Table 9.5-1 Number of PCO Planned 1. Tigrey No. Woredas Phase 1 Phase 2 Phase 3 Expected Connecting Point 1 Adwa 13 Per Filed Survey by ETC 2(*) Hawzen 12 3(*) Wukro 7 Per Feasibility Study 4(*) Samre 13 Per Filed Survey by ETC 5 Alamata 10 Total 55 1 Tahtay Adiyabo 8 2 Medebay Zana 10 3 Laelay Mayechew 10 4 Kola Temben 11 5 Abergele 7 Per Filed Survey by ETC 6 Ganta Afeshum 15 7 Atsbi Wenberta 9 8 Enderta 14 9(*) Hintalo Wajirat 16 10 Ofla 15 Total 115 1 Kafta Humer 5 2 Laelay Adiyabo 8 3 Tahtay Koraro 8 4 Asegede Tsimbela 10 5 Tselemti 7 6(**) Welkait 7 7(**) Tsegede 6 8 Mereb Lehe 10 9(*) Enticho 21 10(**) Werie Lehe 16 Per Filed Survey by ETC 11 Tahtay Maychew 8 12(*)(**) Naeder Adet 9 13 Degua temben 9 14 Gulomahda 11 15 Erob 10 16 Saesi Tsaedaemba 14 17 Alage 13 18 Endmehoni 9 19(**) Rayaazebo 12 20 Ahferom 15 Total 208 1/14 Tigrey D.Table 9.5-1 Number of PCO Planned 2. Affar No. Woredas Phase 1 Phase 2 Phase 3 Expected Connecting Point 1 Ayisaita 3 2 Dubti 5 Per Filed Survey by ETC 3 Chifra 2 Total 10 1(*) Mile 1 2(*) Elidar 1 3 Koneba 4 4 Berahle 4 Per Filed Survey by ETC 5 Amibara 5 6 Gewane 1 7 Ewa 1 8 Dewele 1 Total 18 1 Ere Bti 1 2 Abala 2 3 Megale 1 4 Dalul 4 5 Afdera 1 6 Awash Fentale 3 7 Dulecha 1 8 Bure Mudaytu 1 Per Filed Survey by ETC 9 Arboba Special Woreda 1 10 Aura 1 11 Teru 1 12 Yalo 1 13 Gulina 1 14 Telalak 1 15 Simurobi 1 Total 21 2/14 Affar D.Table 9.5-1 Number of PCO Planned 3. -

Epidemiological Status and Vector Identification of Bovine Trypanosomosis in Lalo-Kile District of Kellem Wollega Zone, Western Ethiopia
Central Journal of Veterinary Medicine and Research Bringing Excellence in Open Access Research Article *Corresponding author Abebe Olani, Department of Parasitology, National Animal health Diagnosis and Investigation Centre, Epidemiological Status and Sebeta, Ethiopia, Tel: 251-913176665; Email: Submitted: 26 January 2016 Vector Identification of Bovine Accepted: 26 April 2016 Published: 28 April 2016 Trypanosomosis in Lalo-Kile ISSN: 2378-931X Copyright District of Kellem Wollega Zone, © 2016 Olani et al. OPEN ACCESS Western Ethiopia Keywords • Bovine 1 2 Abebe Olani * and Dagim Bekele • Trypanosomosis 1Department of Parasitology, National Animal Health Diagnostic and Investigation Center, • Buffy coat Ethiopia • Lalo-Kile and tsetse flies 2Livestock development and Fisheries, Lalo-Kile distrct, Kellem Wollega zone, Ethiopia Abstract Across-sectional study was conducted from Nov, 2013 to May, 2014 to assess the prevalence of bovine trypanosomosis and apparent density of tsetse flies in seven peasant associations of Lalo-Kile district of Kellem wollega zone, Western Ethiopia. The overall 7.78% prevalence of bovine trypanosomosis was recorded from 836 blood sample collected from selected animals using Buffy coat method. Trypanosoma congolense was the dominant species 36 (55.38%), while the low infection was mixed infection of Trypanosoma Congolense and trypanosome vivax 2 (3.07%). The highest prevalence 36(17.64%) of the disease was recorded in Merfo peasant association while the lowset 1(0.7%) was recorded in Kutala-Lube association. The mean packed cell volume (PCV) was 21.95% and 24.47% in parasitamic and aparasitemic animals, respectively. There were statistically significant difference (P<0.05) in prevalence of the disease between sexes and higher prevalence rate 26(9.42%) and 48(8.75%) in poor body condition scores and with > 3 years ages, respectively. -

Local History of Ethiopia : Ga Necu
Local History of Ethiopia Ga Necu - Ghomasha © Bernhard Lindahl (2008) Ga.., see also Ge.. ga (A) near to, close to; (Gurage) time; GDF51 Ga Necu, see Gallachu gaa (O) enough, sufficient; ga-a (O) 1. grown-up /male/; 2. share HDL23 Gaa (Ga'a) 0917'/3845' 2559 m 09/38 [AA Gz] gaad (O) spy out; gaadh (Som) arrive, reach, almost succeed JDJ83 Gaad 09/41 [WO] at the railway 25 km north of Dire Dawa. JDE12 Gaan 0817'/4338' 1210 m 08/43 [Gz] gaaro: geare (T) roar, thunder HFF91 Gaaro (Gaar) (mountain) 1425'/3930' 2589/2905 m 14/39 [WO Gu Gz] HET78 Gaashi (Ga'ashi) (with church Iyesus) 1320'/3910' 13/39 [Gz] -- Gaba (ethnic group west of Gidole), see Dullay ?? Gaba (Geba) (river) ../.. [20] JDJ91 Gaba (Gabba) 0616'/4238' 327/355 m 06/42 [Gz WO] gaba, gabaa (O) 1. market, market goers; 2. thorn-like barley stalk or shoot; gaba (A,T) thorny shrub, Zizyphus spina-christi; arbi (O) Wednesday or Friday, depending on region HDA15 Gaba Arbi 0818'/3518' 1531 m 08/35 [Gz] GDM02 Gaba Gandura (Gheba Giandura) 09/34 [Gz] 0908'/3434' 1410 m HED14 Gaba Gheorghis (Ghaba Gh.), see HED04 Sede Giyorgis JCJ48 Gaba Gurali 0645'/4221' 581 m, cf Gurale 06/42 [Gz] ?? Gaba Sambato, in Wellega ../.. [x] gababa, gabaabaa (O) short, low; gababdu (O) shortly; gabaa ba-u (O) go to the market HER82 Gababu (mountain) 1327'/3645' 952 m, cf Gebabu 13/36 [WO Gz] JCK94 Gabadilli 0710'/4253' 776 m 07/42 [Gz] JCL62 Gabagaba 0655'/4338' 711 m, cf Geba Geba 06/43 [WO Gz] GDM51 Gabagola, see Katugola gabal (Som) portion, piece, part, province; gabbal (Som) spot, circular mark; gebel (T) python JDE60 Gabal Garis (area), cf Gebel 08/43 [WO] -- Gabala, a probably nomad tribe known since the 1300s; gebela (T) shed, porch, verandah; -- Gabila (Afar?) tribe HFF66 Gabala (waterhole), written Gabal in early sources 14/39 [WO] JEJ56 Gabalti, see Debalti, cf Asa Gabalti gaban (Som) small, young; gabbaan (Som) livestock giving little milk; gabanaa (O) one's personal affairs HDC03 Gabana (Gabano) (mountain) 0808'/3653' 2097 m, 08/36 [WO Gz] see under Seka, cf Kabana, Kabena HCP. -

Food Supply Prospect Based on Different Types of Scenarios in 2005
EWS Food Supply Prospect Based on Different Types of EARLY WARNING SYSTEM Scenarios in 2005 REPORT Disaster Prevention and Preparedness Commission September 2004 TABLE OF CONTENTS TABLE OF CONTENTS PAGE List of Glossary of Local Names and Acronyms 3 Executive Summary 4 Introduction 9 Part One: Food Security Prospects in Crop Dependent Areas 1.1 Tigray Region 10 1.2 Amhara Region 12 1.3 Oromiya Region 15 1.4 Southern Nations, Nationalities and Peoples Region (SNNPR) 17 1.5 Dire Dawa 20 1.6 Harar 22 Part Two: Food Security Prospects in Pastoral and Agro-pastoral Areas 2.1 Afar Region 24 2.2 Somali Region 28 2.3 Borena Zones (Oromiya Region) 32 2.4 Low lands of Bale Zone (Oromiya Region) 34 2.5 South Omo Zone, (SNNPR) 36 Tables: Table1: - Needy Population and Food Requirement under Different Scenarios by Regions 8 Table 2: - Needy and Food Requirement Under Different Scenarios for Tigray Region 11 Table 3: - Needy and Food Requirement Under Different Scenarios for Amahra Region 14 Table 4: - Needy and Food Requirment Under Different Scenarios for Oromiya Region 16 Table 5: - Needy and Food Requirement Under Different Scenarios for SNNPR Region 19 Table 6: - Needy and Food Requirement Under Different Scenarios for Dire Dewa 21 Table 7: - Needy and Food Requirement Under Different Scenarios for Harari Region 23 Table 8: - Needy and Food Requirement Under Different Scenarios for Afar Region 27 Table 9: - Needy and Food Requirement Under Different Scenarios for Somali Region 31 Table 10: - Needy and Food Requirement Under Different Scenarios -

Ethiopian Roads Authority
FEDERAL DEMOCRATIC REPUBLIC OF ETHIOPIA MINISTRY OF WORKS & URBAN DEVELOPMENT ETHIOPIAN ROADS AUTHORITY Ethiopia Road Sector Development Stage IV Project (APL4) In Support of Govt.'s RSDP (P106872) Re-Disclosure of Executive Summary of Environmental Impact Assessment Reports For 1. Mekenajo–Dembi Dolo Road Upgrading Project 2. Welkite–Hosaina Road Upgrading Project 3. Ankober–Awasharba Road Construction Project 12 March 2009 Addis Ababa xiii Table of Contents TABLE OF CONTENTS .............................................................................................. XIV PART I – MEKENAJO-DEMBI DOLO LINK ROAD PROJECT ................................................................. 1 PART II – WELKITE-HOSAINA LINK ROAD PROJECT ......................................................................... 12 PART III – ANKOBER-AWASHARBA LINK ROAD PROJECT ............................................................... 24 xiv Part I – Mekenajo-Dembi Dolo Link Road Project xv E.1 Introduction Mekenajo - Dembidolo Road project is located in the West Wollega Zone of the Oromia Regional State. The proposed road route traverses eight woredas of the zone namely: Ayira Guliso, Gawo Dale, Gimbi, Hawa Walel, Lalo Assabi , Seyo, Dale Sedi and Yubdo woredas, and it connects town centers and several villages of those woredas. The project route map is shown in Fig 1.1. The project is among the road project works planned by the Ethiopian Roads Authority (ERA) for the transport sector development. The Ethiopian Road Authority has secured fund from IDA for the implementation of the project. ERA commissioned SPANS Consultants in association with Beza- Consultants to undertake review of the feasibility study, review of the Environmental Impact Assessment (EIA), review of the detailed engineering design and tender document preparation of the Mekenajo – Dembidolo Road project. The Environmental Impact Assessment review has been conducted in accordance with the requirements of the Terms of Reference (TOR). -

Prevalence of Bacterial Wilt of Ginger (Z
International Journal of Research Studies in Agricultural Sciences (IJRSAS) Volume 1, Issue 6, 2015, PP 14-22 ISSN 2454–6224 www.arcjournals.org Prevalence of Bacterial Wilt of Ginger (Z. Officinale) Caused by Ralstonia Solansearum (Smith) in Ethiopia Habetewold kifelew1, Bekelle Kassa2, Kasahun Sadessa3, Tariku Hunduma3 1Tepi National Spice Research Center, Tepi, SNNPRS, Ethiopia 2Holetta Agricultural Research Center 3Ambo Plant Protection Research Center [email protected], [email protected] Abstract: Ginger is one of the most important spices, largely for small scale farmer in Ethiopia. In many production areas of Ethiopia up to 85% of the farmers and 35% of the total arable land were allotted for ginger production. However, this potential spices crop wiped out by a sudden outbreak of bacterial wilt epidemics in 2011 and 2012. A survey was conducted on the status of ginger bacterial wilt incidence in major growing areas of Ethiopia and laboratory work was done to identify the causal agent of ginger wilt. The diseases were found distributed in all ginger growing areas and the loss were estimated up to 100%. During 2012 survey season the wilt incidence percentage was recorded maximum (93.5) in Sheka zone followed by Benchmaji zone (91.6) and Majang zone (65.7) while the lowest wilt incidence was recorded in gamogofa zone (10.7). During 2014 survey season wilt incidence percentage was recorded maximum (98.9) in Benchmaji zone followed by Majang zone (98.8) and Sheka zone (97.4) while the lowest wilt incidence was recorded in Keffa zone (78.4). The syptomology and pathogenicity test confirmed the bacteria were R. -

4.2.1.1. Knowledge of Contraceptive Methods 42 4.2.1.2
I Lists of tables III Lists of Figures V ACRONYMS VI Acknowledgment VII Evaluators VIII Executive summary IX I. INTRODUCTION 1 1.1. Background 1 1.2. Context of RH/FP in Oromia Region 4 1.3. Program Description 6 1.3.1. Objective of the Project 6 1. General Objective: 6 2. Specific Objectives of ODA program: 6 1.3.2. Program Components 7 1.4. Justification of the Evaluation 9 1.5. Stakeholder Analysis 9 II. OBJECTIVE OF THE EVALUATION 11 2.1 General Objective 11 2.2. Specific objectives of the evaluation 11 2.3 Evaluation Questions 11 III. EVALUATION METHODOLOGY 15 3.1. Study area and Period 15 3.2 Evaluation Design and Data collection Methods 15 3.3. Sample size and sampling technique 16 3.4. Data management and analysis Limitations of the study 18 3.5. Ethical considerations 19 IV. RESULTS AND DISCUSSIONS 21 4.1. Degree of Program Implementation 21 4.1.2. Level of stakeholders’ involvement 22 4.1.4. Supervisory Support 24 4.1.5. Capacity Building Activities 24 4.1.6. Role of CBRHAs and their acceptance by the community 26 4.1.7. Information, Education, and Communication (IEC) 29 Evaluation of Reproductive Health/Family Planning Project Of Oromia Development Association (ODA) II 4.1.7.2. Provisions of Information and Education 30 4.1.7.3. Exposure to Family Planning messages 31 4.1.7.4. Organize/Supporting in and out-of-school youth clubs 32 4.1.8. Provisions of Contraceptives 33 4.1.8.1. Amount of contraceptive methods and Couple-year protection (CYP) generated 33 4.1.8.2. -

Demography and Health Aynalem Adugna Www
OROMIYA Demography and Health Aynalem Adugna December 2017 www.EthioDemographyAndHealth.Org ooo and A 2 OROMIYA Suggested citation: OROMIYA: Demography and Health Aynalem Adugna November 2017 www.EthioDemographyAndHealth.Org With 353,690 square kilometers of land area (32% of the country), Oromiya represents the largest regional State [1]. Its population was estimated at 28,067,000 in mid July 2008 [2]; the largest population size of any region (35.4% of the country’s total population). The Oromo represent the majority ethnic group in Oromiya (85%), and in the country at large. Nearly 4 million are residents of urban areas with an urbanization rate of 13.8% - slightly below the national average. The percentage proportion of the Oromo has been estimated variously at 30% to 40% of the country’s total but the mid-way estimate above seems closer to the real proportion. Administratively, Oromiya is divided into 17 zones, 245 Weredas, and 36 town administrations with 6500 kebele subdivisions (see map below). There is an apparent unanimity among authors, that the Oromo had not been part of present-day Ethiopia’s settled landscape prior to the 1550s. In the absence of scientific research and accurate historical accounting of their beginnings, the Oromo have often been described as “migrants” who arrived in Ethiopia proper from its southern-most reaches in mid-16th century, and settled amicably among all groups whose lands they had “appropriated”. Other labels used in place of migration include invasion, plunder, onslaught, conquest, etc. The source below also described them as aliens, and characterized their historical role as destructive: “Oromo, settled in far southern Ethiopia, were an egalitarian pastoral people divided into a number of competing segments or groups but sharing a type of age-set system of social organization called the gada system, which was ideally suited for warfare. -
Project Period: Year Z0W-2A07
West Wellega Zone Oromia Regional State FEDERAL DEMOCRATIC REPUBLIC OF ETHIOPIA Project Period: Year Z0W-2A07 For Action., Submitted to To: African Program for onchocerciasis Control TCCIT (APOC) faurlrJu.:r,9 COOf ! CSD CLV Btrr toP blo Revised July 2003 fior lt*fiorrnut{orr SECTION 1: BACKGROUND INFORMATION 1. INFORMATION ON THE PROJECT AREA FOR CDTI....................... I l.l. Geographical and administrative areas...... I Topography, | ? CIimare, Access ') 1.3 OnchocerciasisEndemicityLevels 8 1.4 CommunityStructure 9 2. PAST AND CURRENT STATUS OII CDTI IN PROJECT AREA .ll SECTION 2: PROJECT EXECUTION OUTLINE II 3. DESCRIPTION OF PROPOSED CDTI ll 3.1. Outline PIan and Timing ... lr 3.2.HealthEducationandCommunityInteractionandParticipation................ ri 3.3. Local Operational Research ......... l(r SUPPLY, IMPORTATION, STORAGE, INVENTORY AND DELIVERY MECTIzANTABLETs.............................. OF 5. SUPERVISION,MONITORINGANDEVALUATION......... r8 during : I -Supervision Evaluation t8 5.2. Monitoring CDTI 19 2t SUSTAINABILITY OF THE CDTI AFTER THE WITHDRAWAL OF EXTERNAL FUNDING .............. 2I g Integration of GDTI into other community pHC I Based of Systems .......... .. 23 6.2. Cost Recovery System during CDTI . ......._...... 25 6.3. .Other Issues 26 6'4' Methods of Measuring the progress Towards sustainabirity. ... 27 7. CROSS BORDER CONSIDERATIONS 28 8. SPECIAL RISK ISSUES 28 S ECT I ON 3 ADM I N ISTRATI O N/F INAN C IAL 9. ADMINISTRATION 'tg 9.1. Organisational Structure for CDTI 29 9.2. FinancialAdministration 3t 9.3. -

Prevalence of Bovine Trypanosomosis and Apparent Density of Tsetse Flies in Sayonole District Western Oromia, Ethiopia
ary Scien in ce r te & e T V e f c h o Journal of Veterinary Science & n n l o o a a l l n n o o r r g g u u Kassaye, J Veterinar Sci Technol 2015, 6:5 y y o o J J Technology DOI: 10.4172/2157-7579.1000254 ISSN: 2157-7579 Research Article Open Access Prevalence of Bovine Trypanosomosis and Apparent Density of Tsetse Flies in Sayonole District Western Oromia, Ethiopia Bedaso Kebede Kassaye* Veterinary Drug and Animal Feed Administration and Control Authority, Ministry of Agriculture, Addis Ababa, Ethiopia *Corresponding author: Bedaso Kebede Kassaye, Veterinary Drug and Animal Feed Administration and Control Authority, Ministry of Agriculture, Addis Ababa, Ethiopia, Tel: 0913136824; E-mail: [email protected] Rec date: Jul 21, 2015; Acc date: Aug 18, 2015; Pub date: Aug 20, 2015 Copyright: © 2015 Kassaye. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Abstract A cross-sectional study was carried out from January up to March 2013 to determine the prevalence of bovine Trypanosomosis and apparent density of the tsetse flies and other biting flies in Sayonole district. The methods employed during the study were deploying trap for the collection of tsetse flies and buffy coat technique for parasitological study. About 43 traps were deployed for 48 hr for collection of tsetse fly. Among five species of tsetse flies commonly found in Ethiopia four of them G.m.submorsitans, G.pallidepes, G.f.fuscipes and G.tachinoides were captured in the study area. -

Food Supply Prospect Based on Different Types of Scenarios in 2005
EWS Food Supply Prospect Based on Different Types of EARLY WARNING SYSTEM Scenarios in 2005 REPORT Disaster Prevention and Preparedness Commission September 2004 TABLE OF CONTENTS TABLE OF CONTENTS PAGE List of Glossary of Local Names and Acronyms 3 Executive Summary 4 Introduction 9 Part One: Food Security Prospects in Crop Dependent Areas 1.1 Tigray Region 10 1.2 Amhara Region 12 1.3 Oromiya Region 15 1.4 Southern Nations, Nationalities and Peoples Region (SNNPR) 17 1.5 Dire Dawa 20 1.6 Harar 22 Part Two: Food Security Prospects in Pastoral and Agro-pastoral Areas 2.1 Afar Region 24 2.2 Somali Region 28 2.3 Borena Zones (Oromiya Region) 32 2.4 Low lands of Bale Zone (Oromiya Region) 34 2.5 South Omo Zone, (SNNPR) 36 Tables: Table1: - Needy Population and Food Requirement under Different Scenarios by Regions 8 Table 2: - Needy and Food Requirement Under Different Scenarios for Tigray Region 11 Table 3: - Needy and Food Requirement Under Different Scenarios for Amahra Region 14 Table 4: - Needy and Food Requirment Under Different Scenarios for Oromiya Region 16 Table 5: - Needy and Food Requirement Under Different Scenarios for SNNPR Region 19 Table 6: - Needy and Food Requirement Under Different Scenarios for Dire Dewa 21 Table 7: - Needy and Food Requirement Under Different Scenarios for Harari Region 23 Table 8: - Needy and Food Requirement Under Different Scenarios for Afar Region 27 Table 9: - Needy and Food Requirement Under Different Scenarios for Somali Region 31 Table 10: - Needy and Food Requirement Under Different Scenarios