Download PDF Van Tekst
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Postbus 60 2501 CB Den Haag 06
Postbus 60 06 - 16 27 04 35 IBAN: NL51ABNA0491044100 KvK: 58053174 2501 CB Den Haag www.prinsjesfestival.nl BTW nummer: 852851972B01 ANBI: 852851972 Prinsjesfestival 2016 | beeldverslag Prinsjesfestival viert het feest van de democratie. Na een korte aanloop omlijst- te Prinsjesfestival van donderdag 15 tot en met dinsdag 20 september 2016 voor de vierde maal Prinsjesdag. Prinsjesfestival is een moderne traditie die in Den Haag een betekenisvol programma biedt vol feestelijke en inhoudelijke activiteiten. Ditmaal was de provincie Zeeland strategisch partner van dit festi- val voor stad en land. Het centrale thema van Prinsjesfestival 2016 was: Democr@tie: tussen Facebook en Wetboek Over democratie en de digitale revolutie Dit beeldverslag bevat een deel van de activiteiten onder de vlag van Prinsjes- festival. Zie achterin voor het volledig overzicht van het programma, de samen- stelling van diverse gremia, een greep uit de pers, de tekst waarmee Prinsjes- dichter Franca Treur Prinsjesfestival 2016 opende, het menu voor PrinsjesDiner 2016 van Prinsjeskok Eric van Bochove. Eerste en laatste pagina beeldverslag: voor- en achterkant Festivalkrant Prinsjesfestival 2016. Postbus 60 06 - 16 27 04 35 IBAN: NL51ABNA0491044100 KvK: 58053174 2501 CB Den Haag www.prinsjesfestival.nl BTW nummer: 852851972B01 ANBI: 852851972 VRIJDAG 09.09.2016 | 20.00 | Nacht van de dictatuur ProDemos | ProDemos, Gevangenpoort. Postbus 60 06 - 16 27 04 35 IBAN: NL51ABNA0491044100 KvK: 58053174 2501 CB Den Haag www.prinsjesfestival.nl BTW nummer: 852851972B01 ANBI: 852851972 ZATERDAG 10.09.2016 (Dag van de democratie in Nederland, open monumentendag) | 10.00 – 16.30 | PrinsjesFototentoonstelling 2016 | Noenzaal Eerste Kamer | in samenwerking met Eerste Kamer der Staten-Generaal, Rabobank Nederland. -

Waar Flaneren Tot Kunst Verheven Is
Waar flaneren tot kunst verheven is De rol van citybranding bij de herbestemming van Strijp S BART A.M. DE ZWART Marco Polo: “Niemand weet beter dan jij, wijze Kublai, dat je nooit een stad mag verwarren met de woorden die haar beschrijven. En toch is er een verband tussen het een en het ander. Als ik je Olivia beschrijf, een stad rijk aan producten en inkomsten, dan heb ik, om je een idee te geven van haar welvaart, geen ander middel ter beschikking dan te praten over filigraanpaleizen met kussens vol franjes op de vensterbanken van de biforen; achter het hekwerk van een patio besproeien de waterstralen van een draaiende fontein een gazon waar een witte pauw op staat te pronken. Maar uit deze woorden begrijp jij meteen hoe Olivia gehuld is in een smerige roetwolk die zich vasthecht aan de muren van de huizen; dat in het gedrang op straat voetgangers verpletterd worden tegen de muren door manoeuvrerende vrachtwagens. Als ik je moet vertellen over de bedrijvigheid van haar inwoners, praat ik over naar leer geurende werkplaatsen van zadelmakers, over vrouwen die met elkaar kletsen onder het knopen van raffia tapijten, over hangende kanalen waarvan de watervallen molenschoepen in beweging zetten: maar het beeld dat deze woorden oproepen in jouw verlichte bewustzijn is het gebaar waarmee het staal tegen de tanden van de frees gehouden wordt, herhaald door duizenden handen, duizenden malen, op de voor de ploegendienst vastgestelde tijden. Als ik je moet uitleggen hoe de geest van Olivia streeft naar een vrij leven en naar een uiterst verfijnde beschaving, zal ik je vertellen van dames die ’s nachts zingend in verlichte kano’s varen tussen de oevers van een groene vijver; maar dat is slechts om je eraan te herinneren dat er in de buitenwijken waar iedere avond mannen en vrouwen uit boten stappen als rijen slaapwandelaars, altijd wel iemand is die in het donker in lachen uitbarst, die zich te buiten gaat aan grappen en sarcastische opmerkingen. -

European Parliament 2014-2019
European Parliament 2014-2019 Committee on Civil Liberties, Justice and Home Affairs LIBE_PV(2017)1106_1 MINUTES Meeting of 6 November 2017, 15.00-18.30 BRUSSELS The meeting opened at 15.03 on Monday, 6 November 2017, with Claude Moraes (Chair) in the chair. 1. Adoption of agenda LIBE_OJ (2017)1106_1 The agenda was adopted. 2. Chair's announcements The Chair announced that interpretation in Maltese, Croatian and Gaelic was not available for this meeting. Endorsement of Coordinators' recommendations (Rule 205) Further to Rule 205 of the Rules of Procedure the Chair submitted the following Coordinators' recommendation for approval: Endorsement of Coordinators’ feedback note of 23 October 2017 – Pursuant to Rule 208(3) of the Rules of Procedure the Greens/EFA, S&D and GUE/NGL, have requested a roll-call vote on the Coordinators' decision not to organise a mission to Hungary (point 2.4 of the agenda of the Coordinator's meeting of 23 October). This vote has been taken under point 6 of the agenda. – LIBE Calendar of Committee meetings for the year 2018 The Committee endorsed the LIBE Calendar of Committee meetings for the year 2018. – Delegated and Implementing Acts The Chair announced that on 26 October 2017, the European Parliament received a "Draft Commission Implementing Decision on the adoption of the work programme for 2018 and on the financing of the Rights, Equality and Citizenship Programme". The basic act being PV\1139046EN.docx PE613.404v01–00 EN United in diversity EN Regulation (EU) No 1381/2013 of the European Parliament and of the Council of 17 December 2013 establishing a Rights, Equality and Citizenship Programme for the period 2014 to 2020. -
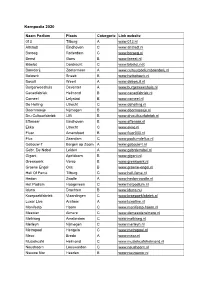
Kernpodia 2020
Kernpodia 2020 Naam Podium Plaats Catergorie Link website 013 Tilburg A www.013.nl Altstadt Eindhoven C www.altstadt.nl Baroeg Rotterdam C www.baroeg.nl Beest Goes B www.tbeest.nl Bibelot Dordrecht C www.bibelot.net Boerderij Zoetermeer A www.cultuurpodiumboerderij.nl Bolwerk Sneek B www.hetbolwerk.nl Bosuil Weert A www.debosuil.nl Burgerweeshuis Deventer A www.burgerweeshuis.nl Cacaofabriek Helmond B www.cacaofabriek.nl Corneel Lelystad B www.corneel.nl De Helling Utrecht C www.dehelling.nl Doornroosje Nijmegen B www.doornroosje.nl Dru Cultuurfabriek Ulft B www.drucultuurfabriek.nl Effenaar Eindhoven B www.effenaar.nl Ekko Utrecht C www.ekko.nl Fluor Amersfoort B www.fluor033.nl Flux Zaandam C www.podiumdeflux.nl Gebouw-T Bergen op Zoom A www.gebouw-t.nl Gebr. De Nobel Leiden A www.gebrdenobel.nl Gigant Apeldoorn B www.gigant.nl Grenswerk Venlo B www.grenswerk.nl Groene Engel Oss B www.groene-engel.nl Hall Of Fame Tilburg C www.hall-fame.nl Hedon Zwolle A www.hedon-zwolle.nl Het Podium Hoogeveen C www.hetpodium.nl Iduna Drachten B www.iduna.nu Kroepoekfabriek Vlaardingen C www.kroepoekfabriek.nl Luxor Live Arnhem A www.luxorlive.nl Manifesto Hoorn C www.manifesto-hoorn.nl Meester Almere C www.demeesteralmere.nl Melkweg Amsterdam C www.melkweg.nl Merleyn Nijmegen C www.merleyn.nl Metropool Hengelo C www.metropool.nl Mezz Breda A www.mezz.nl Muziekcafé Helmond C www.muziekcafehelmond.nl Neushoorn Leeuwarden C www.neushoorn.nl Nieuwe Nor Heerlen B www.nieuwenor.nl Nirwana Lierop C www.nirwana.nl OCCII Amsterdam C www.occii.org P3 Purmerend -

Podia Van De Zeroes: Van 013 Tot Tivolivredenburg De Nieuwbouwgolf Van De Jaren Nul in Beeld
Podia van de Zeroes: van 013 tot TivoliVredenburg De nieuwbouwgolf van de jaren nul in beeld Ingmar Griffioen 14 februari 2014 Zoom De Waerdse Tempel in Heerhugowaard De Zeroes was het tijdperk waarin de drang tot vernieuwing, professionalisering en schaalvergroting in het zalencircuit vorm kreeg in een stoet aan nieuwbouw poppodia. Van Haarlem tot Eindhoven en van Purmerend tot Bergen Op Zoom verrezen nieuwe zalen, vaak ingericht als multifunctionele culturele centra. De nieuwbouwgolf begon grofweg met de opening van 013, Tilburg in 1998 en je zou de opening van TivoliVredenburg (juni) en Doornroosje (oktober) als slotstuk van die dadendrang kunnen zien. 3voor12 kijkt naar de verwachtingen en angsten uit de Zeroes en hoe de vlag er anno 2014 bij hangt. MEGALOMAAN OF GROEISTUIPEN? Najaar 2005 openden twee grote nieuwe zalen in Brabant (Effenaar) en Noord-Holland (Patronaat), twee jaar later zat de nieuwbouwgolf zo'n beetje op haar hoogtepunt. 3voor12 noteerde begin 2007: "Op dit moment zijn meer dan vijftien steden bezig met de her- of nieuwbouw van een poppodium. Bij meer dan tien gaat het om complexen die meer dan duizend bezoekers kunnen huisvesten, vaak verdeeld over meerdere zalen." In dezelfde maand vroeg de Volkskrant zich af wie al die blinkende poptempels toch ging vullen? Internationale boekers constateerden op 3voor12 een tekort aan bands die genoeg publiek trekken. De vraag was kortom: "Verplettert het Nederlandse podiumcircuit zichzelf met megalomane ambities, of beleven we de groeistuipen van een professionaliserende sector?" Zoom Paard van Troje grote zaal na de verbouwing © Nico Laan SLEUTELWOORDEN SCHAALVERGROTING EN PROFESSIONALISERING Belangenvereniging VNPF (Vereniging Nederlandse Poppodia en -Festivals) heeft de stand van zaken in 2008 gevat in Het Grote Poppodium Onderzoek. -

Onderzoek Stemgedrag
Colofon Auteur: Iris van Hulsenbeek Begeleider: Anna Domingo Amsterdam, april 2011 Instituut voor Publiek en Politiek (onderdeel van het Huis voor democratie en rechtsstaat) Prinsengracht 915 1017 KD Amsterdam 020-521 76 00 [email protected] www.publiek-politiek.nl 2 Inleiding 3 H.1. Werking van het Europees Parlement 5 H.2. Partijcohesie 8 H.3. Convergentie tussen de partijen 13 H.4. Beleidsonderwerpen 17 Conclusie 22 Bijlage 1 24 Bronvermelding 25 3 Inleiding Het eerste jaar van de zevende zitting van het Europees Parlement is afgerond. Een mooi moment om terug te blikken en conclusies te trekken. In juni 2009 vonden de verkiezingen voor het Europees Parlement plaats en werden 25 Nederlandse Europarlementariërs gekozen om de komende vijf jaar plaats te nemen in het Parlement. Het Instituut voor Publiek en Politiek (IPP)1 beschikt over data van de hoofdelijke stemmingen van de Nederlandse parlementsleden en hierdoor ligt de mogelijkheid vrij om deze gegevens te analyseren. Door deze informatie te interpreteren kan er onderzoek gedaan worden naar het stemgedrag van de Nederlandse parlementariërs. In 2009 is namens het IPP al onderzoek gedaan naar het stemgedrag van de Nederlandse Europarlementariërs in de periode oktober 2007 tot en met september 2008. Belangrijke conclusies van dat onderzoek waren: • Het stemgedrag van Europarlementariërs is vooral te verklaren vanuit een links/rechts ideologie en niet vanuit nationale belangen. In slechts 9,5% van de gevallen stemmen alle Nederlandse Europarlementariërs hetzelfde. • Het gemeenschappelijk stemgedrag binnen de delegaties ligt veel hoger. De cohesie binnen de verschillende politieke partijen ligt tussen de 0,94 en 0,99, waarbij 1 maximale cohesie is. -

Jean-Claude Juncker President of the European Commission Brussels Cc
Jean-Claude Juncker President of the European Commission Brussels cc: Frans Timmermans, First Vice-President, European Commission Maroš Šefčovič, Vice-President, European Commission Violeta Bulc, European Commissioner for Transport 9 June 2015 Dear President Juncker, We are writing to express our concern on hearing that the Commission has withdrawn plans to propose an EU-wide strategic target for reducing serious road traffic injuries, set to be announced later this week. This long-planned initiative, reconfirmed in a Commission press release as recently as 24 March, has already been strongly supported by member states and the European Parliament. An announcement at the meeting of Transport Ministers in June was expected but we understand on good authority that those plans have now been dropped. You have said that the European Commission is to be “serious about being big on big things”. Serious road injuries are undoubtedly a very big thing, with at least 200,000 people suffering life-changing consequences resulting from traffic collisions last year alone. The timing of this decision is unfortunate as, according to analysis by ETSC, serious road injuries increased by 3% last year. Furthermore, over recent years, declines in serious road injuries have not matched the reductions in road deaths. Moreover, there is a strong economic case to act. Estimates undertaken by ETSC show that, if all serious injuries recorded in 2010 could have been prevented, the benefits to society would have been more than 50 billion Euros in that year. The role of road safety targets in the current progress in reducing road deaths is known to be effective, as is confirmed both by the OECD (“Towards zero: achieving ambitious road safety targets and the safe system approach”, 2008) and scientists (Elvik, “Quantified road safety targets: a useful tool for policy making”, Accident analysis and prevention, 1993). -

NERG 1958 Deel 23 Nr. 02
Tijdschrift van het Nederlands Radiogenootschap DEEL 23 No. 2 1958 De overdracht van omroepprogramma’s via het interlokale telefoonnet door D. van den Berg *) Voordracht gehouden voor het Nederlands Radiogenootschap op 25-4-'57. Summary* For the programme transmission over the Netherlands wire-broadcasting network much use is made of trunk cables. The author describes the various types of programme circuits and the additional repeaters and branching amplifiers. Furthermore he explains what networks are required for the afore-said transmission, what demands they have to meet, and how the networks are maintained. 1. Internationale aanbevelingen voor muziektransmissie. Het telefoonnet en met name het moderne telecommunicatienet leent er zich uitermate goed voor om muziekprogramma's over te brengen, of ruimer geformuleerd: programma's die aan de telefoonfrequentieband van 300-3400 Hz niet voldoende hebben, kunnen op zeer behoorlijke wijze langs kabelverbindingen worden overgebracht. De Union Internationale des Télécommunications (U.I.T.) die als één van zijn onderdelen heeft het Comité Consultatif Inter national Téléfonique (CCIF) dat onlangs zijn naam een iets ge wijzigde vorm heeft gegeven waarbij de telecommunicatie als zodanig wordt genoemd, (CCITT) heeft indertijd een aanbeve ling uitgegeven, welke in zekere zin curieus is en aan de andere kant voldoende aanknoping geeft om het onderwerp te intro duceren. *) Centrale Directie PTT 38 D. van den Berg De aanhef van deze aanbeveling is aardig genoeg om volledig weer te geven: „Le Comité -

Complete Dissertation.Pdf
VU Research Portal Framing the hijab Lettinga, D.N. 2011 document version Publisher's PDF, also known as Version of record Link to publication in VU Research Portal citation for published version (APA) Lettinga, D. N. (2011). Framing the hijab: The governance of intersecting religious, ethnic and gender differences in France, the Netherlands and Germany. VU University Amsterdam. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal ? Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. E-mail address: [email protected] Download date: 26. Sep. 2021 Framing the hijab The governance of intersecting religious, ethnic and gender differences in France, the Netherlands and Germany 1 Thesis committee : Prof.dr. Han Entzinger Prof.dr. Birgit Sauer Prof.dr. Thijl Sunier Prof.dr. Mieke Verloo Dr. Chia Longman Dr. Marcel Maussen ISBN: 978-90-5335-424-7 Printed by: Ridderprint Offsetdrukkerij BV, Ridderkerk Lay out cover page: Dennis Schuivens © D. -

EN EN WORKING DOCUMENT No 9
European Parliament 2014-2019 Committee of Inquiry into Emission Measurements in the Automotive Sector 30.11.2016 WORKING DOCUMENT No 9 on the inquiry into emission measurements in the automotive sector – Appendix B: The committee of inquiry Committee of Inquiry into Emission Measurements in the Automotive Sector Rapporteurs: Jens Gieseke, Gerben-Jan Gerbrandy DT\1109945EN.docx PE594.079v01-00 EN United in diversity EN Appendix B. The committee of inquiry Chair: Ms Kathleen VAN BREMPT (S&D, BE) Bureau: Mr Ivo BELET, 1st Vice-President (EPP, BE) Mr Mark DEMESMAEKER, 2nd Vice-President (ECR, BE) Ms Kateřina KONEČNÁ, 3rd Vice-President (GUE/NGL, CZ) Ms Karima DELLI, 4th Vice-President (Greens/EFA, FR) Coordinators: Mr Krišjānis KARIŅŠ (EPP, LV) Mr Jens GIESEKE (EPP, DE) – Vice-Coordinator Mr Seb DANCE (S&D, UK) Mr Hans-Olaf HENKEL (ECR, DE) Mr Fredrick FEDERLEY (ALDE, SE) Ms Merja KYLLÖNEN (GUE/NGL, FI) Mr Bas EICKHOUT (Greens/EFA, NL) Ms Eleonora EVI (EFDD, IT) Mr Marcus PRETZELL (ENF, DE) – from 17.5.2016 Mr Georg MAYER (ENF, AT) – until 17.5.2016 Rapporteurs: Mr Jens GIESEKE (EPP, DE) – from 24.11.2016 Mr Pablo ZALBA BIDEGAIN (EPP, ES) – until 24.11.2016 Mr Gerben-Jan GERBRANDY (ALDE, NL) Shadow Rapporteurs: Ms Christine REVAULT D’ALLONNES BONNEFOY (S&D, FR) Mr Hans-Olaf HENKEL (ECR, DE) Mr Neoklis SYLIKIOTIS (GUE/NGL, CY) Mr Bas EICKHOUT (Greens/EFA, NL) – for the final report Mr Claude TURMES (Greens/EFA, LU) – for the interim report Ms Eleonora EVI (EFDD, IT) Mr Marcus PRETZELL (ENF, DE) Other Members: Mr Nikos ANDROULAKIS (S&D, EL) -

Brussels, March 4 , 2015 SUBJECT: the Case of Raif Badawi and Other Prisoners of Conscience in Saudi Arabia Madam High Repre
Brussels, March 4th, 2015 SUBJECT: The case of Raif Badawi and other prisoners of conscience in Saudi Arabia Madam High Representative, We are again writing to you regarding the case of Raif Badawi, Saudi prisoner of conscience, currently held in detention by the Saudi authorities, after having been convicted by the Criminal Court of Jeddah. We remain deeply concerned about the possible developments in his case. We have been informed by multiple sources that Mr. Badawi may be subjected again in the near future to a new trial, this time for apostasy, and that he faces, if found guilty by the Criminal Court, the risk of being convicted to the death penalty. We, therefore, urge you to employ all your best efforts to call on the authorities of the Kingdom of Saudi Arabia for the release of Raif Badawi, his lawyer Walled Abulkhair who is also imprisoned and of all other prisoners of conscience. Raif Badawi’s alleged crime was to use his freedom of expression, which is an international human right that Saudi Arabia is bound to respect. We understand that Saudi Arabia is deemed an important partner to the European Union, both individually and in the context of EU’s relationship with the Gulf Cooperation Council. Nevertheless, we strongly believe that engagement with third countries must be based on the upholding of international law, namely, international human rights law, and Saudi Arabia is no exception to that. The moment has come, especially now with a new Saudi leadership, for the EU to send a clear message to the Saudi authorities demanding that it respects, protects and fulfills international human rights, releases all prisoners of conscience and revokes all institutionalized practices that actively infringe fundamental freedoms in the Kingdom. -

7424/11 Lb 1 DQPG COUNCIL of the EUROPEAN UNION Brussels
COUNCIL OF Brussels, 31 March 2011 THE EUROPEAN UNION 7424/11 CRS/CRP 12 SUMMARY RECORD Subject : 2355th meeting of the PERMANENT REPRESENTATIVES COMMITTEE held in Brussels on 9 and 11 March 2011 7424/11 lb 1 DQPG FR/EN SUMMARY Page 1. Adoption of the provisional agenda and items "I"..................................................................... 7 Coreper Part 1 I 2. Reply to written questions put to the Council by Members of the European Parliament (a) n° E-8512/10 put by Raül Romeva i Rueda "Political prisoners in Burma" (b) n° E-9448/10 put by Liam Aylward "The Kimberley Process and conflict diamonds" (c) n° E-10274/10 put by Baroness Sarah Ludford, Simon Busuttil, Marisa Matias and Christel Schaldemose "Achieving a unified EU position with a view to the UN Summit on Non- Communicable Diseases" (d) n° E-10827/10 put by Marina Yannakoudakis "CIA rendition and secret detention programmes" (e) n° E-10972/10 put by Barry Madlener and Daniël van der Stoep "Jihadi website on Netherlands servers" (f) n° E-11062/10 put by Silvia-Adriana Ţicău "Council measures to promote the free movement of workers between Member States" (g) n° E-11145/10 put by Franz Obermayr "European Raw Materials Strategy: rare raw materials" (h) n° E-11251/10 put by Martin Ehrenhauser "Mutual legal assistance agreement between the EU and Japan" (i) n° E-11253/10 put by Martin Ehrenhauser "Cameras on Council premises" (j) n° E-11276/10 put by Wim van de Camp "Exchanges of information about sex offenders" (k) n° E-000045/11 put by Vilija Blinkevičiūtė "Health services