Architetture a Confronto
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD's Llano Fusion
AMD’S “LLANO” FUSION APU Denis Foley, Maurice Steinman, Alex Branover, Greg Smaus, Antonio Asaro, Swamy Punyamurtula, Ljubisa Bajic Hot Chips 23, 19th August 2011 TODAY’S TOPICS . APU Architecture and floorplan . CPU Core Features . Graphics Features . Unified Video decoder Features . Display and I/O Capabilities . Power Gating . Turbo Core . Performance 2 | LLANO HOT CHIPS | August 19th, 2011 ARCHITECTURE AND FLOORPLAN A-SERIES ARCHITECTURE • Up to 4 Stars-32nm x86 Cores • 1MB L2 cache/core • Integrated Northbridge • 2 Chan of DDR3-1866 memory • 24 Lanes of PCIe® Gen2 • x4 UMI (Unified Media Interface) • x4 GPP (General Purpose Ports) • x16 Graphics expansion or display • 2 x4 Lanes dedicated display • 2 Head Display Controller • UVD (Unified Video Decoder) • 400 AMD Radeon™ Compute Units • GMC (Graphics Memory Controller) • FCL (Fusion Control Link) • RMB (AMD Radeon™ Memory Bus) • 227mm2, 32nm SOI • 1.45BN transistors 4 | LLANO HOT CHIPS | August 19th, 2011 INTERNAL BUS . Fusion Control Link (FCL) – 128b (each direction) path for IO access to memory – Variable clock based on throughput (LCLK) – GPU access to coherent memory space – CPU access to dedicated GPU framebuffer . AMD Radeon™ Memory Bus (RMB) – 256b (each direction) for each channel for GMC access to memory – Runs on Northbridge clock (NCLK) – Provides full bandwidth path for Graphics access to system memory – DRAM friendly stream of reads and write – Bypasses coherency mechanism 5 | LLANO HOT CHIPS | August 19th, 2011 Dual-channel DDR3 Unified Video DDR3 UVD Decoder NB CPU CPU Graphics SIMD Integrated Integrated GPU, Display Northbridge Array Controller I/O Controllers L2 Display L2 I/OMultimedia Controllers L2 PCI Express I/O - 24 lanes, optional 1 MB L2 cache L2 I/O per core digital display interfaces CPU CPU Digital display interfaces 4 Stars-32nm PCIe CPU cores PPL Display PCIe PCIe Display 6 | LLANO HOT CHIPS | August 19th, 2011 CPU, GPU, UVD AND IO FEATURES STARS-32nm CPU CORE FEATURES . -

Passmark Intel Vs AMD CPU Benchmarks - High End
PassMark Intel vs AMD CPU Benchmarks - High End http://www.cpubenchmark.net/high_end_cpus.html Shopping cart | Search Home Software Hardware Benchmarks Services Store Support Forums About Us Home » CPU Benchmarks » High End CPU's CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone CPU Benchmarks Over 600,000 CPUs Benchmarked High End CPU's - Intel vs AMD How does your CPU compare? This chart comparing high end CPU's is made using thousands of PerformanceTest benchmark Add your CPU to our benchmark results and is updated daily. These are the high end AMD and Intel CPUs are typically those chart with PerformanceTest V8 found in newer computers. The chart below compares the performance of Intel Xeon CPUs, Intel Core i7 CPUs, AMD Phenom II CPUs and AMD Opterons with multiple cores. Intel processors vs ---- Select A Page ---- AMD chips - find out which CPU's performance is best for your new gaming rig or server! CPU Mark | Price Performance (Click to select desired chart) PassMark - CPU Mark High End CPUs - Updated 26th of August 2013 Price (USD) Intel Xeon E5-2687W @ 3.10GHz 14,564 $1,929.99 Intel Xeon E5-2690 @ 2.90GHz 14,511 $1,920.99 Intel Xeon E5-2680 @ 2.70GHz 13,949 $1,725.99 Intel Xeon E5-2689 @ 2.60GHz 13,444 NA Intel Xeon E5-2670 @ 2.60GHz 13,312 $1,509.00 Intel Core i7-3970X @ 3.50GHz 12,873 $1,006.99 Intel Core i7-3960X @ 3.30GHz 12,749 $965.99 Intel Xeon E5-1660 @ 3.30GHz 12,457 $1,086.99 Intel Xeon E5-2665 @ 2.40GHz 12,453 $1,499.99 Intel Core i7-3930K @ 3.20GHz 12,086 $567.27 Intel Xeon -

Motherboard Gigabyte Ga-A75n-Usb3
Socket AM3+ - AMD 990FX - GA-990FXA-UD5 (rev. 1.x) Socket AM3+ Pagina 1/3 GA- Model 990FXA- Motherboard UD5 PCB 1.x Since L2 L3Core System vendor CPU Model Frequency Process Stepping Wattage BIOS Name Cache Cache Bus(MT/s) Version AMD FX-8150 3600MHz 1MBx8 8MB Bulldozer 32nm B2 125W 5200 F5 AMD FX-8120 3100MHz 1MBx8 8MB Bulldozer 32nm B2 125W 5200 F5 AMD FX-8120 3100MHz 1MBx8 8MB Bulldozer 32nm B2 95W 5200 F5 AMD FX-8100 2800MHz 1MBx8 8MB Bulldozer 32nm B2 95W 5200 F5 AMD FX-6100 3300MHz 1MBx6 8MB Bulldozer 32nm B2 95W 5200 F5 AMD FX-4100 3600MHz 1MBx4 8MB Bulldozer 32nm B2 95W 5200 F5 Socket AM3 GA- Model 990FXA- Motherboard UD5 PCB 1.x Since L2 L3Core System vendor CPU Model Frequency Process Stepping Wattage BIOS Name Cache Cache Bus(MT/s) Version AMD Phenom II X6 1100T 3300MHz 512KBx6 6MB Thuban 45nm E0 125W 4000 F2 AMD Phenom II X6 1090T 3200MHz 512KBx6 6MB Thuban 45nm E0 125W 4000 F2 AMD Phenom II X6 1075T 3000MHz 512KBx6 6MB Thuban 45nm E0 125W 4000 F2 AMD Phenom II X6 1065T 2900MHz 512KBx6 6MB Thuban 45nm E0 95W 4000 F2 AMD Phenom II X6 1055T 2800MHz 512KBx6 6MB Thuban 45nm E0 125W 4000 F2 AMD Phenom II X6 1055T 2800MHz 512KBx6 6MB Thuban 45nm E0 95W 4000 F2 AMD Phenom II X6 1045T 2700MHz 512KBx6 6MB Thuban 45nm E0 95W 4000 F2 AMD Phenom II X6 1035T 2600MHz 512KBx6 6MB Thuban 45nm E0 95W 4000 F2 AMD Phenom II X4 980 3700MHz 512KBx4 6MB Deneb 45nm C3 125W 4000 F6 AMD Phenom II X4 975 3600MHz 512KBx4 6MB Deneb 45nm C3 125W 4000 F2 AMD Phenom II X4 970 3500MHz 512KBx4 6MB Deneb 45nm C3 125W 4000 F2 AMD Phenom II X4 965 3400MHz 512KBx4 -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

TA790GXB3 Motherboard TA790GXB3 Specifcation
TA790GXB3 Motherboard • Supported Socket AM3 processors AMD Phenom II X4 / Phenom II X3 / Athlon II processor • AMD 125W processor support • AMD 790GX Chipset with ATI Radeon HD 3300 Graphics • Dual-Channel DDR3 -1600(OC)/1333/1066/800 • ATI Hybrid Graphics Support • Integrated DVI interface with HDCP Support 1080P HD Video Experience • AMD OverDrive Utility Support • Optional DVI to HDMI adapter • AMD OverDrive™ with ACC feature (Advanced Clock Calibration) supported TA790GXB3 Specifcation CPU SUPPORT AMD Phenom™ II X4 Processor AMD Phenom™ II X3 Processor AMD Phenom™ II X2 Processor AMD Athlon™ II X4 Processor AMD Athlon™ II X3 Processor AMD Athlon™ II X2 Processor Maximum CPU TDP (Thermal Design Power) : 125Watt HT BIOSTARSupport HT 5.2G MEMORY Support Dual Channel DDR3 800/1066/1333/1600(OC) MHz 4 x DDR3 DIMM Memory Slot Max. Supports up to 16GB Memory INTEGRATED VIDEO ATI Radeon™ HD3300 Graphics , Max. Memory Share Up to 512 MB Support ATI Hybrid Crossfire STORAGE 6 x SATA II Connector 1 x IDE Connector Support SATA RAID: 0,1,5,10 LAN Realtek RTL8111DL - 10/100/1000 Controller AUDIO CODEC Realtek ALC662 6-Channel HD Audio USB 4 x USB 2.0 Port 3 x USB 2.0 Header EXPANSION SLOT 1 x PCI-E 2.0 x16 Slot 2 x PCI-E 2.0 x1 Slot 3 x PCI Slot REAR I/O 1 x PS/2 Mouse 1 x PS/2 Keyboard 4 x USB 2.0 Port 1 x DVI Connector 1 x VGA Port 1 x LAN Port 3 x Audio Jacks INTERNAL I/O 3 x USB 2.0 Header 6 x SATA II Connector (3Gb/s ) 1 x IDE Connector 1 x Floppy Connector 1 x Front Audio Header 1 x Front Panel Header 1 x CD-IN Header 1 x S/PDIF-Out Header -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors. -
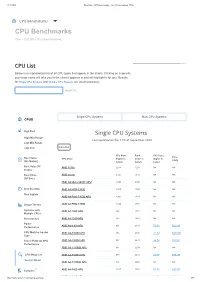
CPU Benchmarks - List of Benchmarked Cpus
11.09.2020 PassMark - CPU Benchmarks - List of Benchmarked CPUs CPU Benchmarks CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Find CPU Single CPU Systems Multi CPU Systems CPUS High End Single CPU Systems High Mid Range Last updated on the 11th of September 2020 Low Mid Range Low End Column CPU Mark Rank CPU Value Price Best Value CPU Name (higher is (lower is (higher is (USD) (On Market) better) better) better) Best Value XY AMD 3015e 2,678 1285 NA NA Scatter Best Value AMD 3020e 2,721 1272 NA NA (All time) AMD A4 Micro-6400T APU 1,004 2126 NA NA New Desktop AMD A4 PRO-3340B 1,519 1790 NA NA New Laptop AMD A4 PRO-7300B APU 1,421 1839 NA NA Single Thread AMD A4 PRO-7350B 1,024 2108 NA NA Systems with AMD A4-1200 APU 445 2572 NA NA Multiple CPUs Overclocked AMD A4-1250 APU 432 2583 NA NA Power AMD A4-3300 APU 994 2131 76.50 $12.99 Performance CPU Mark by Socket AMD A4-3300M APU 665 2394 22.19 $29.99* Type Cross-Platform CPU AMD A4-3305M APU 807 2273 38.78 $20.81 Performance AMD A4-3310MX APU 844 2239 NA NA CPU Mega List AMD A4-3320M APU 877 2212 23.77 $36.90 Search Model AMD A4-3330MX APU 816 2265 NA NA 0 1,067 2078 Compare AMD A4-3400 APU 53.35 $20.00 https://www.cpubenchmark.net/cpu_list.php AMD A4 3420 APU 8 01 $12 9 * 1/87 11.09.2020 PassMark - CPU Benchmarks - List -

Take a Way: Exploring the Security Implications of AMD's Cache Way
Take A Way: Exploring the Security Implications of AMD’s Cache Way Predictors Moritz Lipp Vedad Hadžić Michael Schwarz Graz University of Technology Graz University of Technology Graz University of Technology Arthur Perais Clémentine Maurice Daniel Gruss Unaffiliated Univ Rennes, CNRS, IRISA Graz University of Technology ABSTRACT 1 INTRODUCTION To optimize the energy consumption and performance of their With caches, out-of-order execution, speculative execution, or si- CPUs, AMD introduced a way predictor for the L1-data (L1D) cache multaneous multithreading (SMT), modern processors are equipped to predict in which cache way a certain address is located. Conse- with numerous features optimizing the system’s throughput and quently, only this way is accessed, significantly reducing the power power consumption. Despite their performance benefits, these op- consumption of the processor. timizations are often not designed with a central focus on security In this paper, we are the first to exploit the cache way predic- properties. Hence, microarchitectural attacks have exploited these tor. We reverse-engineered AMD’s L1D cache way predictor in optimizations to undermine the system’s security. microarchitectures from 2011 to 2019, resulting in two new attack Cache attacks on cryptographic algorithms were the first mi- techniques. With Collide+Probe, an attacker can monitor a vic- croarchitectural attacks [12, 42, 59]. Osvik et al. [58] showed that tim’s memory accesses without knowledge of physical addresses an attacker can observe the cache state at the granularity of a cache or shared memory when time-sharing a logical core. With Load+ set using Prime+Probe. Yarom et al. [82] proposed Flush+Reload, Reload, we exploit the way predictor to obtain highly-accurate a technique that can observe victim activity at a cache-line granu- memory-access traces of victims on the same physical core. -

Beyond the Ordinary
Beyond the ordinary HP Recommends Windows® 7. HP Compaq 6005 Pro Business PC Designed to Packed with high performance features, Easy to deploy and manage the HP Compaq 6005 Pro Business PC is Streamline business processes while deliver energy efficient and well equipped to go lowering IT costs and operating uncompromised beyond meeting your daily business expenses with DASH and other demands. Enabled for manageability with manageability features that allow for results with energy DASH 1.1, you can also choose the more efficient planning, deployment, efficiency features productivity and security features that best and transition of your PCs. You get suit your everyday needs with a PC access to a suite of client management and high-end designed to exceed your expectations. tools, 12+ month product lifecycle, and global SKUs to meet your world-wide capabilities Designed to deliver needs. Enhance your capabilities with the latest AMD Business Class technology: Simplified serviceability comes in the processors and chipset that provide form of tool-less hood removal, drive exceptional performance while operating bays and slots as well as internal quick as efficiently as possible. Integrated ATI release latches, green pull tabs, and Radeon 4200 graphics with ATI Avivo™ color coordinated cables and and DirectX 10.1 provide a stunning connectors. visual experience. Dual monitor capability Security that’s right for you also comes standard for easier mutli- Help your investments be more secure tasking. with the embedded TPM 1.2 security chip Use less, save more that helps provide enhanced data Improve your bottom line with energy protection and limits system access efficient features like an optional 89% through hardware-based encryption. -
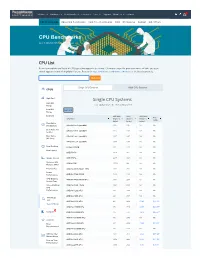
CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android Ios / Iphone
Software Hardware Benchmarks Services Store Support About Us Forums 0 CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Find CPU Single CPU Systems Multi CPU Systems CPUS High End Single CPU Systems High Mid Range Last updated on the 28th of May 2021 Low Mid Column Range Low End CPU Mark Rank CPU Value Price CPU Name (higher is (lower is (higher is (USD) better) better) better) Best Value (On Market) AArch64 rev 0 (aarch64) 2,335 1605 NA NA Best Value XY AArch64 rev 1 (aarch64) 2,325 1606 NA NA Scatter Best Value AArch64 rev 2 (aarch64) 1,937 1807 NA NA (All time) AArch64 rev 4 (aarch64) 1,676 1968 NA NA New Desktop AC8257V/WAB 693 2730 NA NA New Laptop AMD 3015e 2,678 1472 NA NA Single Thread AMD 3020e 2,637 1481 NA NA Systems with AMD 4700S 17,756 222 NA NA Multiple CPUs Overclocked AMD A4 Micro-6400T APU 1,004 2445 NA NA Power Performance AMD A4 PRO-3340B 1,706 1938 NA NA CPU Mark by AMD A4 PRO-7300B APU 1,481 2097 NA NA Socket Type Cross-Platform AMD A4 PRO-7350B 1,024 2428 NA NA CPU Performance AMD A4-1200 APU 445 2969 NA NA AMD A4-1250 APU 428 2987 NA NA CPU Mega List AMD A4-3300 APU 961 2494 53.40 $18.00* Search Model AMD A4-3300M APU 686 2740 22.86 $29.99* 0 Compare AMD -

Passmark - CPU Benchmarks - List of Benchmarked Cpus
PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Mark Rank CPU Name CPU Benchmarks (higher is better) (lower is better) CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Find CPU Single CPU Systems Multi CPU Systems Single CPU Systems Last updated on the 11th of June 2021 Column CPU Mark Rank CPU Value Price CPU Name (higher is better) (lower is better) (higher is better) (USD) AMD EPYC 7763 87,767 1 NA NA AMD Ryzen Threadripper PRO 3995WX 86,096 2 15.69 $5,486.99 AMD EPYC 7713 85,887 3 NA NA AMD Ryzen Threadripper 3990X 81,290 4 13.30 $6,110.99 AMD EPYC 7643 77,101 5 NA NA AMD EPYC 7702 71,686 6 8.43 $8,499.00 AMD Ryzen Threadripper 3970X 64,139 7 26.28 $2,440.51 AMD EPYC 7742 64,071 8 8.01 $7,995.94* AMD Ryzen Threadripper PRO 3975WX 61,259 9 22.70 $2,698.99 AMD EPYC 7702P 60,273 10 12.96 $4,650.00* AMD EPYC 7443P 58,896 11 44.05 $1,337.00* AMD EPYC 7R32 58,556 12 NA NA AMD EPYC 7542 56,809 13 13.53 $4,198.95* AMD Ryzen Threadripper 3960X 55,004 14 39.29 $1,399.99 1 z 112 11.06.2021, 11:17 PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Mark Rank CPU Value Price CPU Name (higher is better) (lower is better) (higher is better) (USD) CPU Mark Rank CPU Name CPU Benchmarks (higher -

SKU: 740GMAT-A-E Features
WWW.ZOTAC.COM SKU: 740GMAT-A-E Embrace the ultimate visual experience with the ZOTAC 740G platform featuring proven ATI Radeon™ graphics processing for lifelike photos, smooth video playback and an immersive computing experience. An integrated ATI Radeon™ 2100 graphics processor enables the ZOTAC 740G to deliver stunning clarity for all computing needs from web browsing to gaming. The ZOTAC 740G is the perfect platform for everyday computing with plenty of performance for modern day tasks when paired with single, dual or quad-core AMD Phenom™ II, Athlon™ II or Sempron processors. Plenty of features are packed into a micro-ATX form factor with the ZOTAC 740G -- including dual- channel DDR3 memory support, SATA 3.0 Gb/s with RAID 0 and 1 support, and high-definition 6-channel audio -- for an affordable platform that delivers plenty of performance and expansion capabilities. Specifications Features • AMD 740G chipset • ATI Radeon™ 2100 • Socket AM3 • ATI Avivo™ Technology • AMD HyperTransport™ technology • Microsoft® DirectX® 9 • Microsoft® Windows 7/Vista® ready • OpenGL® 2.0 Processor support • AMD Phenom II • AMD Athlon II • AMD Sempron • Up to 95-watt TDP Storage support • 4 SATA 3.0Gb/s • 1 IDE Memory support • DDR3-1066/1333 • 2 x 240 pin DDR3 DIMM slots • Up to 4GB ram Connectors • 12 USB ports (4 on back panel, 8 via header) • 1 HD Audio Port (5.1-channel) Expansion • 1 Serial port header • 1 x PCI Express x16 • 1 Front panel audio header • 2 x PCI Express x1 • 2 Fan headers • 1 x PCI Dimensions • Micro-ATX form factor Display outputs • Height: 9.6in - 244mm • Width: 6.97in – 177mm • DVI-D (HDCP) • VGA Rear port layout Size comparison Mini-ITX MicroATX ATX Inside the box • 2 SATA cables • 1 I/O back plate © 2010 ZOTAC International (MCO) Limited ZOTAC International (MCO) Limited does not warrant the accuracy, completeness or reliability of information, materials and other items contained on this website or server.