Exploring the Ecosystem of Referrer-Anonymizing Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In-Depth Evaluation of Redirect Tracking and Link Usage
Proceedings on Privacy Enhancing Technologies ; 2020 (4):394–413 Martin Koop*, Erik Tews, and Stefan Katzenbeisser In-Depth Evaluation of Redirect Tracking and Link Usage Abstract: In today’s web, information gathering on 1 Introduction users’ online behavior takes a major role. Advertisers use different tracking techniques that invade users’ privacy It is common practice to use different tracking tech- by collecting data on their browsing activities and inter- niques on websites. This covers the web advertisement ests. To preventing this threat, various privacy tools are infrastructure like banners, so-called web beacons1 or available that try to block third-party elements. How- social media buttons to gather data on the users’ on- ever, there exist various tracking techniques that are line behavior as well as privacy sensible information not covered by those tools, such as redirect link track- [52, 69, 73]. Among others, those include information on ing. Here, tracking is hidden in ordinary website links the user’s real name, address, gender, shopping-behavior pointing to further content. By clicking those links, or or location [4, 19]. Connecting this data with informa- by automatic URL redirects, the user is being redirected tion gathered from search queries, mobile devices [17] through a chain of potential tracking servers not visible or content published in online social networks [5, 79] al- to the user. In this scenario, the tracker collects valuable lows revealing further privacy sensitive information [62]. data about the content, topic, or user interests of the This includes personal interests, problems or desires of website. Additionally, the tracker sets not only third- users, political or religious views, as well as the finan- party but also first-party tracking cookies which are far cial status. -

IBM Cognos Analytics - Reporting Version 11.1
IBM Cognos Analytics - Reporting Version 11.1 User Guide IBM © Product Information This document applies to IBM Cognos Analytics version 11.1.0 and may also apply to subsequent releases. Copyright Licensed Materials - Property of IBM © Copyright IBM Corp. 2005, 2021. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. IBM, the IBM logo and ibm.com are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at " Copyright and trademark information " at www.ibm.com/legal/copytrade.shtml. The following terms are trademarks or registered trademarks of other companies: • Adobe, the Adobe logo, PostScript, and the PostScript logo are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States, and/or other countries. • Microsoft, Windows, Windows NT, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both. • Intel, Intel logo, Intel Inside, Intel Inside logo, Intel Centrino, Intel Centrino logo, Celeron, Intel Xeon, Intel SpeedStep, Itanium, and Pentium are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. • Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both. • UNIX is a registered trademark of The Open Group in the United States and other countries. • Java and all Java-based trademarks and logos are trademarks or registered trademarks of Oracle and/or its affiliates. -

Download Forecheck Guide
Forecheck Content 1 Welcome & Introduction 5 2 Overview: What Forecheck Can Do 6 3 First Steps 7 4 Projects and Analyses 9 5 Scheduler and Queue 12 6 Important Details 13 6.1 La..n..g..u..a..g..e..s.,. .C...h..a..r.a..c..t.e..r. .S..e..t.s.. .a..n..d.. .U..n..i.c..o..d..e....................................................................... 13 6.2 Ch..o..o..s..i.n..g.. .t.h..e.. .c.o..r..r.e..c..t. .F..o..n..t............................................................................................. 14 6.3 St.o..r.a..g..e.. .L..o..c..a..t.i.o..n.. .o..f. .D..a..t.a................................................................................................ 15 6.4 Fo..r.e..c..h..e..c..k. .U...s.e..r.-.A...g..e..n..t. .a..n..d.. .W...e..b.. .A..n..a..l.y..s.i.s.. .T..o..o..l.s............................................................. 15 6.5 Er.r.o..r.. .H..a..n..d..l.i.n..g................................................................................................................ 17 6.6 Ro..b..o..t.s...t.x..t.,. .n..o..i.n..d..e..x..,. .n..o..f.o..l.l.o..w......................................................................................... 18 6.7 Co..m...p..l.e..t.e.. .A..n..a..l.y..s..i.s. .o..f. .l.a..r.g..e.. .W....e..b..s.i.t.e..s............................................................................. 20 6.8 Fi.n..d..i.n..g.. .a..l.l. .p..a..g..e..s. .o..f. .a.. .W....e..b..s.i.t.e....................................................................................... 21 6.9 Go..o..g..l.e.. .A...n..a..l.y.t.i.c..s. -

Lxmldoc-4.5.0.Pdf
lxml 2020-01-29 Contents Contents 2 I lxml 14 1 lxml 15 Introduction................................................. 15 Documentation............................................... 15 Download.................................................. 16 Mailing list................................................. 17 Bug tracker................................................. 17 License................................................... 17 Old Versions................................................. 17 2 Why lxml? 18 Motto.................................................... 18 Aims..................................................... 18 3 Installing lxml 20 Where to get it................................................ 20 Requirements................................................ 20 Installation................................................. 21 MS Windows............................................. 21 Linux................................................. 21 MacOS-X............................................... 21 Building lxml from dev sources....................................... 22 Using lxml with python-libxml2...................................... 22 Source builds on MS Windows....................................... 22 Source builds on MacOS-X......................................... 22 4 Benchmarks and Speed 23 General notes................................................ 23 How to read the timings........................................... 24 Parsing and Serialising........................................... 24 The ElementTree -

CSE 190 M (Web Programming), Spring 2008 University of Washington
Extra Slides, week 2 CSE 190 M (Web Programming), Spring 2008 University of Washington Reading: Chapter 2, sections 2.4 - 2.6 Except where otherwise noted, the contents of this presentation are © Copyright 2008 Marty Stepp and Jessica Miller and are licensed under the Creative Commons Attribution 2.5 License. Additional XHTML Tags for adding metadata and icons to a page Web page metadata: <meta> information about your page (for a browser, search engine, etc.) <meta name="description" content="Authors' web site for Building Java Programs." /> <meta name="keywords" content="java, textbook" /> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> placed in the head of your XHTML page meta tags often have both the name and content attributes some meta tags use the http-equiv attribute instead of name meta element to aid browser / web server <meta http-equiv="Content-Type" content=" type of document (character encoding)" /> <meta http-equiv="refresh" content=" how often to refresh the page (seconds)" /> </head> using the Content-Type gets rid of the W3C "tentatively valid" warning <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> the meta refresh tag can also redirect from one page to another: <meta http-equiv="refresh" content="5;url=http://www.bjp.com " /> why would we want to do this? (example ) meta element to describe the page <head> <meta name="author" content=" web page's author " /> <meta name="revised" content=" web page version and/or last modification date " /> <meta name="generator" -

Essbase Logs
Oracle® Enterprise Performance Management System Installation and Configuration Troubleshooting Guide Release 11.1.2.1 Updated: August 2012 EPM System Installation and Configuration Troubleshooting Guide, 11.1.2.1 Copyright © 2007, 2012, Oracle and/or its affiliates. All rights reserved. Authors: EPM Information Development Team Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS: Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). -

CSE 190 M: HTML Page 1
CSE 190 M: HTML Page 1 Lecture Notes 2: Hypertext Markup Language (HTML) CSE 190 M (Web Programming), Spring 2007 University of Washington Reading: Sebesta Ch. 2 sections 2.1 - 2.4.5, 2.4.7 - 2.4.9, 2.5 -2.6.1,2.7 -2.7.2 Hypertext Markup Language (HTML ) describes the content and structure of information on a web page not the same as the presentation (appearance on screen) surrounds text content with opening and closing tags each tag's name is called an element syntax: <element > content </element > example: <p>This is a paragraph</p> most whitespace is insignificant in HTML (it gets ignored or collapsed into a single space) More about HTML tags some tags can contain additional information called attributes syntax: <element attribute =" value " attribute =" value "> content </element > example: <a href="page2.html">Next page</a> some tags don't contain content; can be opened and closed in one tag syntax: <element attribute =" value " attribute =" value " /> example: <img src="bunny.jpg" alt="A bunny" /> example: <hr /> file://localhost/C:/Documents%20and%20Settings/stepp/My%20Documents/cse190m/07sp/... 05/03/2007 12:57:29 PM CSE 190 M: HTML Page 2 Structure of an HTML page <html> <head> information about the page </head> <body> page contents </body> </html> a header describes the page and a body contains the page's contents an HTML page is saved into a file ending with extension .html Example page XHTML a newer version of HTML, standardized in 2000 uses a markup format called XML (XML + HTML = XHTML) though the browser will accept some malformed HTML, we'll write "strict" XHTML that complies to the official web standards why use XHTML and web standards? more rigid and structured language more interoperable across different web browsers more likely that our pages will display correctly in the future can be interchanged with other XML data: SVG (graphics), MathML , MusicML , etc. -

(ACM) Style Guide, WCAG 2.0 Level A
Association of Computing Machinery (ACM) Style Guide, WCAG 2.0 Level A ACM 12/19/16 TABLE OF CONTENTS Overview ............................................................................................................................................................... 4 Media Types .......................................................................................................................................................... 4 Images ............................................................................................................................................................... 4 Best Practice: Provide Alternative Text for Images ..................................................................................... 4 Best Practice: Ensure complex images provide sufficient descriptions ....................................................... 5 Best Practice: Ensure CSS background images that convey meaning have textual and visible equivalents ...................................................................................................................................................................... 5 Color and Contrast ............................................................................................................................................ 6 Best Practice: Ensure color is not the sole means of communicating information or indicating error messages ..................................................................................................................................................... -

SC Tech Summary
SC tech summary Failure of Success Criterion F65 1.1.1 due to omitting the alt attribute on img elements, area elements, and input elements of type image Using label elements to associate text labels with form H44 controls." category Using the title attribute to identify form controls when H65 the label element cannot be used Using alt attributes on images used as submit buttons" H36 category ARIA6 Using aria-label to provide labels for objects H37 Using alt attributes on img elements 1.1.1 Failure of Success Criterion F30 1.1.1 and 1.2.1 due to using text alternatives that are not alternatives Combining adjacent image and text links for the same H2 resource H35 Providing text alternatives on applet elements H53 Using the body of the object element" category Providing text alternatives for the area elements of image H24 maps" category Providing link text that describes the purpose of a link for H30 anchor elements H45 Using longdesc H46 Using noembed with embed Using null alt text and no title attribute on img elements H67 for images that AT should ignore H96 Using the track element to provide audio descriptions Providing an alternative for time-based media for audio- G158 only content Providing an alternative for time-based media for video- G195 1.2.1 only content Providing audio that describes the important video G166 content and describing it as such Failure of Success Criterion F30 1.1.1 and 1.2.1 due to using text alternatives that are not alternatives 1.2.2 H95 Using the track element to provide captions 1.2.3 H53 Using the body -

Package 'Htmlutils'
Package ‘HTMLUtils’ February 19, 2015 Type Package Title Facilitates Automated HTML Report Creation Version 0.1.7 Date 2015-01-17 Depends R2HTML Suggests Author ``Markus Loecher, Berlin School of Eco- nomics and Law (BSEL)'' <[email protected]> Maintainer ``Markus Loecher, Berlin School of Eco- nomics and Law (BSEL)'' <[email protected]> Description Facilitates automated HTML report creation, in particular framed HTML pages and dynamically sortable tables. License GPL LazyLoad yes Repository CRAN Date/Publication 2015-01-17 16:21:32 NeedsCompilation no R topics documented: HTMLUtils-package . .2 BasicHTML . .2 FramedHTML . .6 HTMLhref . 12 HTMLsortedTable . 13 InstallJSC . 14 makePathName . 14 myHTMLInitFile . 15 MyReportBegin . 16 MyReportEnd . 17 Index 18 1 2 BasicHTML HTMLUtils-package Facilitates Automated HTML Report Creation Description Facilitates automated HTML report creation, in particular framed HTML pages and dynamically sortable tables. Details Package: HTMLUtils Type: Package Title: Facilitates Automated HTML Report Creation Version: 0.1.7 Date: 2015-01-17 Depends: R2HTML Suggests: Author: "Markus Loecher, Berlin School of Economics and Law (BSEL)" <[email protected]> Maintainer: "Markus Loecher, Berlin School of Economics and Law (BSEL)" <[email protected]> License: GPL LazyLoad: yes Packaged: 2012-05-17 21:56:35 UTC; mloecher Repository: CRAN Date/Publication: 2012-05-18 05:59:13 Author(s) "Markus Loecher, Berlin School of Economics and Law (BSEL)" <[email protected]> BasicHTML creates a basic HTML page displaying plots and annota Description Creates a basic HTML page displaying plots and annotations that can easily be navigated. The plots can be created either ’on the fly’ by passing the appropriate commands or beforehand in which case just the filenames need to be passed. -

CSC 443: Web Programming Basic HTML
1 CSC 443: Web Programming Haidar Harmanani Department of Computer Science and Mathematics Lebanese American University Byblos, 1401 2010 Lebanon CSC443: Web Programming 2 Basic HTML Haidar Harmanani Department of Computer Science and Mathematics Lebanese American University Byblos, 1401 2010 Lebanon CSC443: Web Programming Hypertext Markup Language (HTML) 3 ¨ Describes the content and structure of information on a web page ¨ Not the same as the presentation (appearance on screen) ¨ Surrounds text content with opening and closing tags ¨ Each tag's name is called an element ¤ syntax: <element> content </element> ¤ example: <p>This is a paragraph</p> CSC443: Web Programming XHTML 4 ¨ Uses a markup format called XML ¨ XML + HTML = XHTML ¨ Standardized in 2000 ¨ A strict XHTML page uses some different syntax and tags than HTML CSC443: Web Programming Structure of XHTML page 5 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> information about the page </head> <body> page contents </body> </html> HTML ¨ HTML is saved with extension .html ¨ Basic structure: tags that enclose content, i.e., elements ¨ Header describes the page ¨ Body contains the page’s contents CSC443: Web Programming Page Title <title> 6 … <head> <title> HARRY POTTER AND THE DEATHLY HALLOWS - PART 2 </title> </head> … HTML ¨ Placed within the head of the page ¨ Displayed in web browser’s title mark and when bookmarking the page CSC443: Web Programming Paragraph <p> 7 … <body> <p> Harry Potter and the Deathly Hallows, the last book in the series, begins directly after the events of the sixth book. -
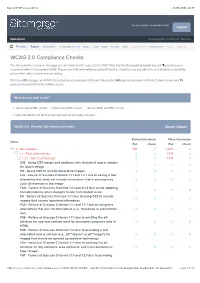
Web and PDF Accessibility 24/05/2016, 20:35
Web and PDF Accessibility 24/05/2016, 20:35 You are logged in as Lawrence Shaw Logout Dashboard Knowledge Base Need Help? Overview Priorities Report Inventory Accessibility: 1.0 | 2.0 Brand Code Email Function SEO Trademarks / IP Performance Privacy Spelling WCAG 2.0 Compliance Checks The Accessibility checks on this page are determined with respect to the W3C Web Content Accessibility Guidelines 2.0 published as a recommendation in December 2008. Please note that automated accessibility testing should be used as part of a co-ordinated accessibility policy which also includes manual testing. We found 0% of pages and PDF files tested passed automated Priority 1 (A) checks, 95% passed automated Priority 2 (AA) checks, and 1% passed automated Priority 3 (AAA) checks. What do you wish to see? Show only HTML checks Show only PDF checks Show HTML and PDF checks Also list WCAG 2.0 techniques that must be manually checked WCAG 2.0 - Priority 1 (A) checks and results Expand | Collapse Failure techniques Other techniques Name Fail Check Fail Check 1 - Perceivable 136 0 1,825 0 1.1 - Text Alternatives 0 0 1,714 0 1.1.1 - Non-text Content 0 0 1,714 0 C18 - Using CSS margin and padding rules instead of spacer images 0 0 0 0 forfor layoutlayout designdesign C9 - Using CSS to include decorative images 0 0 0 0 F13 - Failure of Success Criterion 1.1.1 and 1.4.1 due to having a text alternative that does not includeinclude informationinformation thatthat isis conveyedconveyed byby 0 0 0 0 color differences in the image F20 - Failure of Success Criterion