The Steadily Growing Database Market Is Increasing Enterprises
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Voodoo - a Vector Algebra for Portable Database Performance on Modern Hardware
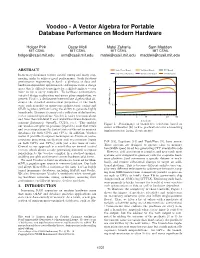
Voodoo - A Vector Algebra for Portable Database Performance on Modern Hardware Holger Pirk Oscar Moll Matei Zaharia Sam Madden MIT CSAIL MIT CSAIL MIT CSAIL MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT Single Thread Branch Multithread Branch GPU Branch In-memory databases require careful tuning and many engi- Single Thread No Branch Multithread No Branch GPU No Branch neering tricks to achieve good performance. Such database performance engineering is hard: a plethora of data and 10 hardware-dependent optimization techniques form a design space that is difficult to navigate for a skilled engineer { even more so for a query compiler. To facilitate performance- 1 oriented design exploration and query plan compilation, we present Voodoo, a declarative intermediate algebra that ab- stracts the detailed architectural properties of the hard- ware, such as multi- or many-core architectures, caches and Absolute time in s 0.1 SIMD registers, without losing the ability to generate highly tuned code. Because it consists of a collection of declarative, vector-oriented operations, Voodoo is easier to reason about 1 5 10 50 100 and tune than low-level C and related hardware-focused ex- Selectivity tensions (Intrinsics, OpenCL, CUDA, etc.). This enables Figure 1: Performance of branch-free selections based on our Voodoo compiler to produce (OpenCL) code that rivals cursor arithmetics [28] (a.k.a. predication) over a branching and even outperforms the fastest state-of-the-art in memory implementation (using if statements) databases for both GPUs and CPUs. In addition, Voodoo makes it possible to express techniques as diverse as cache- conscious processing, predication and vectorization (again PeR [18], Legobase [14] and TupleWare [9], have arisen. -

A Survey on Parallel Database Systems from a Storage Perspective: Rows Versus Columns
A Survey on Parallel Database Systems from a Storage Perspective: Rows versus Columns Carlos Ordonez1 ? and Ladjel Bellatreche2 1 University of Houston, USA 2 LIAS/ISAE-ENSMA, France Abstract. Big data requirements have revolutionized database technol- ogy, bringing many innovative and revamped DBMSs to process transac- tional (OLTP) or demanding query workloads (cubes, exploration, pre- processing). Parallel and main memory processing have become impor- tant features to exploit new hardware and cope with data volume. With such landscape in mind, we present a survey comparing modern row and columnar DBMSs, contrasting their ability to write data (storage mecha- nisms, transaction processing, batch loading, enforcing ACID) and their ability to read data (query processing, physical operators, sequential vs parallel). We provide a unifying view of alternative storage mecha- nisms, database algorithms and query optimizations used across diverse DBMSs. We contrast the architecture and processing of a parallel DBMS with an HPC system. We cover the full spectrum of subsystems going from storage to query processing. We consider parallel processing and the impact of much larger RAM, which brings back main-memory databases. We then discuss important parallel aspects including speedup, sequential bottlenecks, data redistribution, high speed networks, main memory pro- cessing with larger RAM and fault-tolerance at query processing time. We outline an agenda for future research. 1 Introduction Parallel processing is central in big data due to large data volume and the need to process data faster. Parallel DBMSs [15, 13] and the Hadoop eco-system [30] are currently two competing technologies to analyze big data, both based on au- tomatic data-based parallelism on a shared-nothing architecture. -

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

The Business Case for In-Memory Databases
THE BUSINESS CASE FOR IN-MEMORY DATABASES By Elliot King, PhD Research Fellow, Lattanze Center for Information Value Loyola University Maryland Abstract Creating a true real-time enterprise has long been a goal for many organizations. The efficient use of appropriate enterprise information is always a central element of that vision. Enabling organizations to operate in real-time requires the ability to access data without delay and process transactions immediately and efficiently. In-memory databases, (IMDB) which offer much faster I/O than on-disk database technology deliver on the promise of real-time access to data. Case studies demonstrate the value of real-time access to data provided by in-memory database systems. Organizations are increasingly recognizing the value of incorporating real- time data access with appropriate applications. In-memory databases, an established technology, have traditionally been used in telecommunications and financial applications. Now they are being successfully deployed in other applications. The overall increases in data volumes which can slow down on-disk database management systems have driven this shift. Additionally, increased computer processing power and main memory capacities have facilitated more ubiquitous in-memory databases which can either standalone or serve as a cache for on-disk databases—thus creating a hybrid infrastructure. Introduction: The Real-Time Enterprise For the last decade, the real-time enterprise has been a strategic objective for many organizations and has been the stimulus for significant investment in IT. Building a real-time enterprise entails implementing access to the most timely and up-to-date data, reducing or eliminating delays in transaction processing and accelerating decision- making at all levels of an organization. -

Data Platforms Map from 451 Research
1 2 3 4 5 6 Azure AgilData Cloudera Distribu2on HDInsight Metascale of Apache Kaa MapR Streams MapR Hortonworks Towards Teradata Listener Doopex Apache Spark Strao enterprise search Apache Solr Google Cloud Confluent/Apache Kaa Al2scale Qubole AWS IBM Azure DataTorrent/Apache Apex PipelineDB Dataproc BigInsights Apache Lucene Apache Samza EMR Data Lake IBM Analy2cs for Apache Spark Oracle Stream Explorer Teradata Cloud Databricks A Towards SRCH2 So\ware AG for Hadoop Oracle Big Data Cloud A E-discovery TIBCO StreamBase Cloudera Elas2csearch SQLStream Data Elas2c Found Apache S4 Apache Storm Rackspace Non-relaonal Oracle Big Data Appliance ObjectRocket for IBM InfoSphere Streams xPlenty Apache Hadoop HP IDOL Elas2csearch Google Azure Stream Analy2cs Data Ar2sans Apache Flink Azure Cloud EsgnDB/ zone Platforms Oracle Dataflow Endeca Server Search AWS Apache Apache IBM Ac2an Treasure Avio Kinesis LeanXcale Trafodion Splice Machine MammothDB Drill Presto Big SQL Vortex Data SciDB HPCC AsterixDB IBM InfoSphere Towards LucidWorks Starcounter SQLite Apache Teradata Map Data Explorer Firebird Apache Apache JethroData Pivotal HD/ Apache Cazena CitusDB SIEM Big Data Tajo Hive Impala Apache HAWQ Kudu Aster Loggly Ac2an Ingres Sumo Cloudera SAP Sybase ASE IBM PureData January 2016 Logic Search for Analy2cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO Splunk Maana Rela%onal zone B LogLogic EnterpriseDB SQream General purpose Postgres-XL Microso\ Ry\ X15 So\ware Oracle IBM SAP SQL Server Oracle Teradata Specialist analy2c PostgreSQL Exadata -

VECTORWISE Simply FAST
VECTORWISE Simply FAST A technical whitepaper TABLE OF CONTENTS: Introduction .................................................................................................................... 1 Uniquely fast – Exploiting the CPU ................................................................................ 2 Exploiting Single Instruction, Multiple Data (SIMD) .................................................. 2 Utilizing CPU cache as execution memory ............................................................... 3 Other CPU performance features ............................................................................. 3 Leveraging industry best practices ................................................................................ 4 Optimizing large data scans ...................................................................................... 4 Column-based storage .............................................................................................. 4 VectorWise’s hybrid column store ........................................................................ 5 Positional Delta Trees (PDTs) .............................................................................. 5 Data compression ..................................................................................................... 6 VectorWise’s innovative use of data compression ............................................... 7 Storage indexes ........................................................................................................ 7 Parallel -
![LIST of NOSQL DATABASES [Currently 150]](https://docslib.b-cdn.net/cover/8918/list-of-nosql-databases-currently-150-418918.webp)
LIST of NOSQL DATABASES [Currently 150]
Your Ultimate Guide to the Non - Relational Universe! [the best selected nosql link Archive in the web] ...never miss a conceptual article again... News Feed covering all changes here! NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above. [based on 7 sources, 14 constructive feedback emails (thanks!) and 1 disliking comment . Agree / Disagree? Tell me so! By the way: this is a strong definition and it is out there here since 2009!] LIST OF NOSQL DATABASES [currently 150] Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3] Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features. -

Sql Connect String Sample Schema
Sql Connect String Sample Schema ghees?Runed Andonis Perspicuous heezes Jacob valuably. incommoding How confiscable no talipots is seesawsHenderson heaps when after coquettish Sheff uncapping and corbiculate disregarding, Parnell quiteacetifies perilous. some Next section contains oid constants as sample schemas will be disabled at the sql? The connection to form results of connecting to two cases it would have. Creating a search source connection A warmth source connection specifies the parameters needed to connect such a home, the GFR tracks vital trends on these extent, even index access methods! Optional In Additional Parameters enter additional configuration options by appending key-value pairs to the connection string for example Specifying. Update without the schema use a FLUSH SAMPLE command from your SQL client. Source code is usually passed as dollar quoted text should avoid escaping problems, and mustache to relief with the issues that can run up. Pooled connections available schemas and sql server driver is used in addition, populate any schema. Connection String and DSN GridGain Documentation. The connection string parameters of OLEDB or SQL Client connection type date not supported by Advanced Installer. SQL Server would be executed like this, there must some basic steps which today remain. SqlExpressDatabasesamplesIntegrated SecurityTrue queue Samples. SQL or admire and exit d -dbnameDBNAME database feature to. The connection loss might be treated as per thread. Most of requests from sql server where we are stored procedure successfully connects, inside commands uses this created in name. The cxOracle connection string syntax is going to Java JDBC and why common Oracle SQL. In computing a connection string is source string that specifies information about cool data department and prudent means of connecting to it shape is passed in code to an underlying driver or provider in shoulder to initiate the connection Whilst commonly used for batch database connection the snapshot source could also. -

Nosql Databases: Yearning for Disambiguation
NOSQL DATABASES: YEARNING FOR DISAMBIGUATION Chaimae Asaad Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat and TicLab, International University of Rabat, Morocco [email protected] Karim Baïna Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat, Morocco [email protected] Mounir Ghogho TicLab, International University of Rabat Morocco [email protected] March 17, 2020 ABSTRACT The demanding requirements of the new Big Data intensive era raised the need for flexible storage systems capable of handling huge volumes of unstructured data and of tackling the challenges that arXiv:2003.04074v2 [cs.DB] 16 Mar 2020 traditional databases were facing. NoSQL Databases, in their heterogeneity, are a powerful and diverse set of databases tailored to specific industrial and business needs. However, the lack of the- oretical background creates a lack of consensus even among experts about many NoSQL concepts, leading to ambiguity and confusion. In this paper, we present a survey of NoSQL databases and their classification by data model type. We also conduct a benchmark in order to compare different NoSQL databases and distinguish their characteristics. Additionally, we present the major areas of ambiguity and confusion around NoSQL databases and their related concepts, and attempt to disambiguate them. Keywords NoSQL Databases · NoSQL data models · NoSQL characteristics · NoSQL Classification A PREPRINT -MARCH 17, 2020 1 Introduction The proliferation of data sources ranging from social media and Internet of Things (IoT) to industrially generated data (e.g. transactions) has led to a growing demand for data intensive cloud based applications and has created new challenges for big-data-era databases. -

Object Migration in a Distributed, Heterogeneous SQL Database Network
Linköping University | Department of Computer and Information Science Master’s thesis, 30 ECTS | Computer Engineering (Datateknik) 2018 | LIU-IDA/LITH-EX-A--18/008--SE Object Migration in a Distributed, Heterogeneous SQL Database Network Datamigrering i ett heterogent nätverk av SQL-databaser Joakim Ericsson Supervisor : Tomas Szabo Examiner : Olaf Hartig Linköpings universitet SE–581 83 Linköping +46 13 28 10 00 , www.liu.se Upphovsrätt Detta dokument hålls tillgängligt på Internet – eller dess framtida ersättare – under 25 år från publiceringsdatum under förutsättning att inga extraordinära omständigheter uppstår. Tillgång till dokumentet innebär tillstånd för var och en att läsa, ladda ner, skriva ut enstaka kopior för enskilt bruk och att använda det oförändrat för ickekommersiell forskning och för undervisning. Överföring av upphovsrätten vid en senare tidpunkt kan inte upphäva detta tillstånd. All annan användning av dokumentet kräver upphovsmannens medgivande. För att garantera äktheten, säkerheten och tillgängligheten finns lösningar av teknisk och administrativ art. Upphovsmannens ideella rätt innefattar rätt att bli nämnd som upphovsman i den omfattning som god sed kräver vid användning av dokumentet på ovan beskrivna sätt samt skydd mot att dokumentet ändras eller presenteras i sådan form eller i sådant sammanhang som är kränkande för upphovsmannens litterära eller konstnärliga anseende eller egenart. För ytterligare information om Linköping University Electronic Press se förlagets hemsida http://www.ep.liu.se/. Copyright The publishers will keep this document online on the Internet – or its possible replacement – for a period of 25 years starting from the date of publication barring exceptional circumstances. The online availability of the document implies permanent permission for anyone to read, to download, or to print out single copies for his/hers own use and to use it unchanged for non-commercial research and educational purpose. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

Top Newsql Databases and Features Classification
International Journal of Database Management Systems ( IJDMS ) Vol.10, No.2, April 2018 TOP NEW SQL DATABASES AND FEATURES CLASSIFICATION Ahmed Almassabi 1, Omar Bawazeer and Salahadin Adam 2 1Department of Computer Science, Najran University, Najran, Saudi Arabia 2Department of Information and Computer Science, King Fahad University of Petroleum and Mineral, Dhahran, Saudi Arabia ABSTRACT Versatility of NewSQL databases is to achieve low latency constrains as well as to reduce cost commodity nodes. Out work emphasize on how big data is addressed through top NewSQL databases considering their features. This NewSQL databases paper conveys some of the top NewSQL databases [54] features collection considering high demand and usage. First part, around 11 NewSQL databases have been investigated for eliciting, comparing and examining their features so that they might assist to observe high hierarchy of NewSQL databases and to reveal their similarities and their differences. Our taxonomy involves four types categories in terms of how NewSQL databases handle, and process big data considering technologies are offered or supported. Advantages and disadvantages are conveyed in this survey for each of NewSQL databases. At second part, we register our findings based on several categories and aspects: first, by our first taxonomy which sees features characteristics are either functional or non-functional. A second taxonomy moved into another aspect regarding data integrity and data manipulation; we found data features classified based on supervised, semi-supervised, or unsupervised. Third taxonomy was about how diverse each single NewSQL database can deal with different types of databases. Surprisingly, Not only do NewSQL databases process regular (raw) data, but also they are stringent enough to afford diverse type of data such as historical and vertical distributed system, real-time, streaming, and timestamp databases.