Micro Adaptivity in Vectorwise
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Monetdb/X100: Hyper-Pipelining Query Execution
MonetDB/X100: Hyper-Pipelining Query Execution Peter Boncz, Marcin Zukowski, Niels Nes CWI Kruislaan 413 Amsterdam, The Netherlands fP.Boncz,M.Zukowski,[email protected] Abstract One would expect that query-intensive database workloads such as decision support, OLAP, data- Database systems tend to achieve only mining, but also multimedia retrieval, all of which re- low IPC (instructions-per-cycle) efficiency on quire many independent calculations, should provide modern CPUs in compute-intensive applica- modern CPUs the opportunity to get near optimal IPC tion areas like decision support, OLAP and (instructions-per-cycle) efficiencies. multimedia retrieval. This paper starts with However, research has shown that database systems an in-depth investigation to the reason why tend to achieve low IPC efficiency on modern CPUs in this happens, focusing on the TPC-H bench- these application areas [6, 3]. We question whether mark. Our analysis of various relational sys- it should really be that way. Going beyond the (im- tems and MonetDB leads us to a new set of portant) topic of cache-conscious query processing, we guidelines for designing a query processor. investigate in detail how relational database systems The second part of the paper describes the interact with modern super-scalar CPUs in query- architecture of our new X100 query engine intensive workloads, in particular the TPC-H decision for the MonetDB system that follows these support benchmark. guidelines. On the surface, it resembles a The main conclusion we draw from this investiga- classical Volcano-style engine, but the cru- tion is that the architecture employed by most DBMSs cial difference to base all execution on the inhibits compilers from using their most performance- concept of vector processing makes it highly critical optimization techniques, resulting in low CPU CPU efficient. -
Voodoo - a Vector Algebra for Portable Database Performance on Modern Hardware
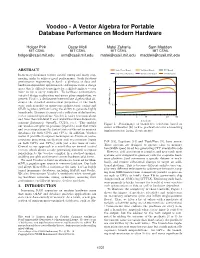
Voodoo - A Vector Algebra for Portable Database Performance on Modern Hardware Holger Pirk Oscar Moll Matei Zaharia Sam Madden MIT CSAIL MIT CSAIL MIT CSAIL MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT Single Thread Branch Multithread Branch GPU Branch In-memory databases require careful tuning and many engi- Single Thread No Branch Multithread No Branch GPU No Branch neering tricks to achieve good performance. Such database performance engineering is hard: a plethora of data and 10 hardware-dependent optimization techniques form a design space that is difficult to navigate for a skilled engineer { even more so for a query compiler. To facilitate performance- 1 oriented design exploration and query plan compilation, we present Voodoo, a declarative intermediate algebra that ab- stracts the detailed architectural properties of the hard- ware, such as multi- or many-core architectures, caches and Absolute time in s 0.1 SIMD registers, without losing the ability to generate highly tuned code. Because it consists of a collection of declarative, vector-oriented operations, Voodoo is easier to reason about 1 5 10 50 100 and tune than low-level C and related hardware-focused ex- Selectivity tensions (Intrinsics, OpenCL, CUDA, etc.). This enables Figure 1: Performance of branch-free selections based on our Voodoo compiler to produce (OpenCL) code that rivals cursor arithmetics [28] (a.k.a. predication) over a branching and even outperforms the fastest state-of-the-art in memory implementation (using if statements) databases for both GPUs and CPUs. In addition, Voodoo makes it possible to express techniques as diverse as cache- conscious processing, predication and vectorization (again PeR [18], Legobase [14] and TupleWare [9], have arisen. -

A Survey on Parallel Database Systems from a Storage Perspective: Rows Versus Columns
A Survey on Parallel Database Systems from a Storage Perspective: Rows versus Columns Carlos Ordonez1 ? and Ladjel Bellatreche2 1 University of Houston, USA 2 LIAS/ISAE-ENSMA, France Abstract. Big data requirements have revolutionized database technol- ogy, bringing many innovative and revamped DBMSs to process transac- tional (OLTP) or demanding query workloads (cubes, exploration, pre- processing). Parallel and main memory processing have become impor- tant features to exploit new hardware and cope with data volume. With such landscape in mind, we present a survey comparing modern row and columnar DBMSs, contrasting their ability to write data (storage mecha- nisms, transaction processing, batch loading, enforcing ACID) and their ability to read data (query processing, physical operators, sequential vs parallel). We provide a unifying view of alternative storage mecha- nisms, database algorithms and query optimizations used across diverse DBMSs. We contrast the architecture and processing of a parallel DBMS with an HPC system. We cover the full spectrum of subsystems going from storage to query processing. We consider parallel processing and the impact of much larger RAM, which brings back main-memory databases. We then discuss important parallel aspects including speedup, sequential bottlenecks, data redistribution, high speed networks, main memory pro- cessing with larger RAM and fault-tolerance at query processing time. We outline an agenda for future research. 1 Introduction Parallel processing is central in big data due to large data volume and the need to process data faster. Parallel DBMSs [15, 13] and the Hadoop eco-system [30] are currently two competing technologies to analyze big data, both based on au- tomatic data-based parallelism on a shared-nothing architecture. -

Actian Zen Database Product Family Zero DBA, Embeddable Database for Data-Driven Edge Intelligence Applications
Actian Zen Database Product Family Zero DBA, embeddable database for data-driven Edge intelligence applications Actian Zen database product family Zen offers NoSQL access for data-intensive Key Benefits is a single, secure, scalable Edge data application performance and local Zero DBA, developer-configurable management portfolio that meets the analytics support that leverages all popular NoSQL and SQL needs of on-premise, cloud, mobile and IoT programming languages (C/C++/C#, application developers. Actian Zen provides Java, Python, Perl, PHP, etc.), providing Embed or bundle with your persistent local and distributed data the perfect combination of speed and business-critical applications across intelligent applications deployed flexibility. Developers can choose among Support multiple data tables and in enterprise, branch, and remote field several methods of direct access to data files each up to 64TB environments, including mobile devices without going through a relational layer. Cross platform and version data and IoT. Develop and deploy on Intel or ARM Zen databases also offer SQL access for portability follows your application running Windows 10, Windows 2016 and reporting, query, and local transactions. This Simple upgrades 2019 Servers, Linux, macOS and iOS, Android, enables fast read and quick insert, update, Raspbian Linux distributions, Windows IoT and delete performance alongside full ACID Backward compatibility Core and Windows Nano Servers, supporting response on writes and ANSI SQL queries. JSON, BLOB, and Time-series the -

AWS Marketplace Getting Started
AWS Marketplace Getting Started Actian Vector VAWS-51-GS-14 Copyright © 2018 Actian Corporation. All Rights Reserved. This Documentation is for the end user’s informational purposes only and may be subject to change or withdrawal by Actian Corporation (“Actian”) at any time. This Documentation is the proprietary information of Actian and is protected by the copyright laws of the United States and international treaties. The software is furnished under a license agreement and may be used or copied only in accordance with the terms of that agreement. No part of this Documentation may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or for any purpose without the express written permission of Actian. To the extent permitted by applicable law, ACTIAN PROVIDES THIS DOCUMENTATION “AS IS” WITHOUT WARRANTY OF ANY KIND, AND ACTIAN DISCLAIMS ALL WARRANTIES AND CONDITIONS, WHETHER EXPRESS OR IMPLIED OR STATUTORY, INCLUDING WITHOUT LIMITATION, ANY IMPLIED WARRANTY OF MERCHANTABILITY, OF FITNESS FOR A PARTICULAR PURPOSE, OR OF NON-INFRINGEMENT OF THIRD PARTY RIGHTS. IN NO EVENT WILL ACTIAN BE LIABLE TO THE END USER OR ANY THIRD PARTY FOR ANY LOSS OR DAMAGE, DIRECT OR INDIRECT, FROM THE USE OF THIS DOCUMENTATION, INCLUDING WITHOUT LIMITATION, LOST PROFITS, BUSINESS INTERRUPTION, GOODWILL, OR LOST DATA, EVEN IF ACTIAN IS EXPRESSLY ADVISED OF SUCH LOSS OR DAMAGE. The manufacturer of this Documentation is Actian Corporation. For government users, the Documentation is delivered with “Restricted Rights” as set forth in 48 C.F.R. Section 12.212, 48 C.F.R. -

VECTORWISE Simply FAST
VECTORWISE Simply FAST A technical whitepaper TABLE OF CONTENTS: Introduction .................................................................................................................... 1 Uniquely fast – Exploiting the CPU ................................................................................ 2 Exploiting Single Instruction, Multiple Data (SIMD) .................................................. 2 Utilizing CPU cache as execution memory ............................................................... 3 Other CPU performance features ............................................................................. 3 Leveraging industry best practices ................................................................................ 4 Optimizing large data scans ...................................................................................... 4 Column-based storage .............................................................................................. 4 VectorWise’s hybrid column store ........................................................................ 5 Positional Delta Trees (PDTs) .............................................................................. 5 Data compression ..................................................................................................... 6 VectorWise’s innovative use of data compression ............................................... 7 Storage indexes ........................................................................................................ 7 Parallel -

With Strato, Esgyn Sends Hybrid Data Workloads to the Cloud
451 RESEARCH REPRINT REPORT REPRINT With Strato, Esgyn sends hybrid data workloads to the cloud JAMES CURTIS 01 NOV 2018 Esgyn is an emerging player in the hybrid processing space that sells a SQL-based query engine based on the Apache Trafodion project. Now the company is introducing a managed cloud service to handle hybrid workloads as it looks to spur US adoption. THIS REPORT, LICENSED TO ESGYN, DEVELOPED AND AS PROVIDED BY 451 RESEARCH, LLC, WAS PUBLISHED AS PART OF OUR SYNDICATED MARKET INSIGHT SUBSCRIPTION SERVICE. IT SHALL BE OWNED IN ITS ENTIRETY BY 451 RESEARCH, LLC. THIS REPORT IS SOLELY INTENDED FOR USE BY THE RECIPIENT AND MAY NOT BE REPRODUCED OR RE-POSTED, IN WHOLE OR IN PART, BY THE RE- CIPIENT WITHOUT EXPRESS PERMISSION FROM 451 RESEARCH. ©2018 451 Research, LLC | WWW.451RESEARCH.COM 451 RESEARCH REPRINT Establishing itself as an up-and-coming player in the hybrid processing space, Esgyn has rolled out an updated version of its EsgynDB database, which is based on Apache Trafodion. The company is also making an active push into the cloud with a managed cloud service called Esgyn Strato, which is ex- pected to be generally available in November on AWS and Azure. THE 451 TAKE With hybrid workloads on the rise, Esgyn is in a good position to ride the current wave. The startup’s core technology of Apache Trafodion hearkens back nearly 30 years to technology developed at Tan- dem and later refined at Hewlett-Packard. As such, the company’s core technology rests on a solid foundation with a proven history. -

Actian Zen Core Database for Android Zero DBA, Embeddable DB for Edge Apps and Smart Devices
Actian Zen Core Database for Android Zero DBA, embeddable DB for edge apps and smart devices Key Benefits Actian Zen Core database for Android focuses squarely on the needs of Edge and IoT application developers, providing persistent local and distributed data across intelligent Zero DBA, developer-configurable applications embedded in smart devices. Develop using the Android SDK and other 3rd party tools and deploy on any standard or embedded platform running Android. Actian Zen Core SQL and NoSQL database for Android supports zero ETL data sharing to any Actian Zen family server or Embed in local apps client database. Data portability across platforms and Zen Core database for Android is a NoSQL, zero DBA, embeddable, nano-footprint (2MB versions minimum) edge database for SIs, ISVs, and OEMs that need to embed a data management platform in their Android apps, from smart phones to PoS terminals to industrial IoT. With direct Supports peer-to-peer and client-server data access via APIs, self-tuning, reporting, data portability, exceptional reliability, and compatibility, IoT and Edge developers can deliver apps at scale across a Wide range of platforms. Supported Platforms Zero Database Administration Set it and forget it. Edge computing in the World of consumer device and industrial IoT apps Android 5 or higher means no DBA. Zen Edge database is built for non-IT environments, removing need for consultants or DBA supervision. Whether you elect to never touch your app or continually Android Things 1.0 or higher patch and redeploy it, Zen Core database for Android Won’t break your app under any Android SDK 25 or higher circumstances. -

The Ingres Next Initiative Enabling the Cloud, Mobile, and Web Journeys for Our Actian X and Ingres Database Customers
The Ingres NeXt Initiative Enabling the Cloud, Mobile, and Web Journeys for our Actian X and Ingres Database Customers Any organization that has leveraged technology to help run their business Benefits knows that the costs associated with on-going maintenance and support for Accelerate Cost Savings legacy systems can often take the upwards of 50% of the budget. Analysts and • Seize near-term cost IT vendors tend to see these on-going investments as sub-optimum, but for reductions across your IT and mission critical systems that have served their organizations well for decades business operations and tight budgets, , the risk to operations and business continuity make • Leverage existing IT replacing these tried and tested mission critical systems impractical. In many investments and data sources cases, these essential systems contain thousands of hours of custom developed business logic investment. • Avoid new CAPEX cycles when Products such as Actian Ingres and, more recently Actian X Relational retiring legacy systems Database Management Systems (RDBMS), have proven Actian’s commitment to helping our customers maximize their existing investments without having Optimize Risk Mitigation to sacrifice modern functionality. Ultimately, this balance in preservation and • Preserve investments in existing business logic while innovation with Ingres has taken us to three areas of development and taking advantage of modern deployment: continuation of heritage UNIX variants on their associated capabilities hardware, current Linux and Windows for on-premise and virtualized environments and most importantly, enabling migration to the public cloud. • Same database across all platforms Based on a recent survey of our Actian X and Ingres customer base, we are seeing a growing desire to move database workloads to the Cloud. -

Hannes Mühleisen
Large-Scale Statistics with MonetDB and R Hannes Mühleisen DAMDID 2015, 2015-10-13 About Me • Postdoc at CWI Database architectures since 2012 • Amsterdam is nice. We have open positions. • Special interest in data management for statistical analysis • Various research & software projects in this space 2 Outline • Column Store / MonetDB Introduction • Connecting R and MonetDB • Advanced Topics • “R as a Query Language” • “Capturing The Laws of Data Nature” 3 Column Stores / MonetDB Introduction 4 Postgres, Oracle, DB2, etc.: Conceptional class speed flux NX 1 3 Constitution 1 8 Galaxy 1 3 Defiant 1 6 Intrepid 1 1 Physical (on Disk) NX 1 3 Constitution 1 8 Galaxy 1 3 Defiant 1 6 Intrepid 1 1 5 Column Store: class speed flux Compression! NX 1 3 Constitution 1 8 Galaxy 1 3 Defiant 1 6 Intrepid 1 1 NX Constitution Galaxy Defiant Intrepid 1 1 1 1 1 3 8 3 6 1 6 What is MonetDB? • Strict columnar architecture OLAP RDBMS (SQL) • Started by Martin Kersten and Peter Boncz ~1994 • Free & Open Open source, active development ongoing • www.monetdb.org Peter A. Boncz, Martin L. Kersten, and Stefan Manegold. 2008. Breaking the memory wall in MonetDB. Communications of the ACM 51, 12 (December 2008), 77-85. DOI=10.1145/1409360.1409380 7 MonetDB today • Expanded C code • MAL “DB assembly” & optimisers • SQL to MAL compiler • Memory-Mapped files • Automatic indexing 8 Some MAL • Optimisers run on MAL code • Efficient Column-at-a-time implementations EXPLAIN SELECT * FROM mtcars; | X_2 := sql.mvc(); | | X_3:bat[:oid,:oid] := sql.tid(X_2,"sys","mtcars"); | | X_6:bat[:oid,:dbl] -

LDBC Introduction and Status Update
8th Technical User Community meeting - LDBC Peter Boncz [email protected] ldbcouncil.org LDBC Organization (non-profit) “sponsors” + non-profit members (FORTH, STI2) & personal members + Task Forces, volunteers developing benchmarks + TUC: Technical User Community (8 workshops, ~40 graph and RDF user case studies, 18 vendor presentations) What does a benchmark consist of? • Four main elements: – data & schema: defines the structure of the data – workloads: defines the set of operations to perform – performance metrics: used to measure (quantitatively) the performance of the systems – execution & auditing rules: defined to assure that the results from different executions of the benchmark are valid and comparable • Software as Open Source (GitHub) – data generator, query drivers, validation tools, ... Audience • For developers facing graph processing tasks – recognizable scenario to compare merits of different products and technologies • For vendors of graph database technology – checklist of features and performance characteristics • For researchers, both industrial and academic – challenges in multiple choke-point areas such as graph query optimization and (distributed) graph analysis SPB scope • The scenario involves a media/ publisher organization that maintains semantic metadata about its Journalistic assets (articles, photos, videos, papers, books, etc), also called Creative Works • The Semantic Publishing Benchmark simulates: – Consumption of RDF metadata (Creative Works) – Updates of RDF metadata, related to Annotations • Aims to be -

Magic Quadrant for Data Integration Tools
20/08/2019 Gartner Reprint Licensed for Distribution Magic Quadrant for Data Integration Tools Published 1 August 2019 - ID G00369547 - 92 min read By Analysts Ehtisham Zaidi, Eric Thoo, Nick Heudecker The data integration tool market is resurging as new requirements for hybrid/intercloud integration, active metadata and augmented data management force a rethink of existing practices. This assessment of 16 vendors will help data and analytics leaders make the best choice for their organization. Strategic Planning Assumptions By 2021, more than 80% of organizations will use more than one data delivery style to execute their data integration use cases. By 2022, organizations utilizing active metadata to dynamically connect, optimize and automate data integration processes will reduce time to data delivery by 30%. By 2022, manual data integration tasks (including recognition of performance and optimization issues across multiple environments) will be reduced by 45% through the addition of ML and automated service-level management. By 2023, improved location-agnostic semantics in data integration tools will reduce design, deployment and administrative costs by 40%. Market Definition/Description The discipline of data integration comprises the architectural techniques, practices and tools that ingest, transform, combine and provision data across the spectrum of data types. This integration takes place in the enterprise and beyond — across partners as well as third-party data sources and use cases — to meet the data consumption requirements of all applications and business processes. This is inclusive of any technology that supports data integration requirements regardless of current market nomenclature (e.g., data ingestion, data transformation, data replication, messaging, data synchronization, data virtualization, stream data integration and many more).