Mardia's Skewness and Kurtosis for Assessing Normality Assumption In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Use of Proc Iml to Calculate L-Moments for the Univariate Distributional Shape Parameters Skewness and Kurtosis
Statistics 573 USE OF PROC IML TO CALCULATE L-MOMENTS FOR THE UNIVARIATE DISTRIBUTIONAL SHAPE PARAMETERS SKEWNESS AND KURTOSIS Michael A. Walega Berlex Laboratories, Wayne, New Jersey Introduction Exploratory data analysis statistics, such as those Gaussian. Bickel (1988) and Van Oer Laan and generated by the sp,ge procedure PROC Verdooren (1987) discuss the concept of robustness UNIVARIATE (1990), are useful tools to characterize and how it pertains to the assumption of normality. the underlying distribution of data prior to more rigorous statistical analyses. Assessment of the As discussed by Glass et al. (1972), incorrect distributional shape of data is usually accomplished conclusions may be reached when the normality by careful examination of the values of the third and assumption is not valid, especially when one-tail tests fourth central moments, skewness and kurtosis. are employed or the sample size or significance level However, when the sample size is small or the are very small. Hopkins and Weeks (1990) also underlying distribution is non-normal, the information discuss the effects of highly non-normal data on obtained from the sample skewness and kurtosis can hypothesis testing of variances. Thus, it is apparent be misleading. that examination of the skewness (departure from symmetry) and kurtosis (deviation from a normal One alternative to the central moment shape statistics curve) is an important component of exploratory data is the use of linear combinations of order statistics (L analyses. moments) to examine the distributional shape characteristics of data. L-moments have several Various methods to estimate skewness and kurtosis theoretical advantages over the central moment have been proposed (MacGillivray and Salanela, shape statistics: Characterization of a wider range of 1988). -
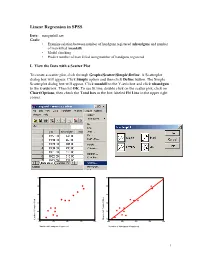
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

A Skew Extension of the T-Distribution, with Applications
J. R. Statist. Soc. B (2003) 65, Part 1, pp. 159–174 A skew extension of the t-distribution, with applications M. C. Jones The Open University, Milton Keynes, UK and M. J. Faddy University of Birmingham, UK [Received March 2000. Final revision July 2002] Summary. A tractable skew t-distribution on the real line is proposed.This includes as a special case the symmetric t-distribution, and otherwise provides skew extensions thereof.The distribu- tion is potentially useful both for modelling data and in robustness studies. Properties of the new distribution are presented. Likelihood inference for the parameters of this skew t-distribution is developed. Application is made to two data modelling examples. Keywords: Beta distribution; Likelihood inference; Robustness; Skewness; Student’s t-distribution 1. Introduction Student’s t-distribution occurs frequently in statistics. Its usual derivation and use is as the sam- pling distribution of certain test statistics under normality, but increasingly the t-distribution is being used in both frequentist and Bayesian statistics as a heavy-tailed alternative to the nor- mal distribution when robustness to possible outliers is a concern. See Lange et al. (1989) and Gelman et al. (1995) and references therein. It will often be useful to consider a further alternative to the normal or t-distribution which is both heavy tailed and skew. To this end, we propose a family of distributions which includes the symmetric t-distributions as special cases, and also includes extensions of the t-distribution, still taking values on the whole real line, with non-zero skewness. Let a>0 and b>0be parameters. -

1 One Parameter Exponential Families
1 One parameter exponential families The world of exponential families bridges the gap between the Gaussian family and general dis- tributions. Many properties of Gaussians carry through to exponential families in a fairly precise sense. • In the Gaussian world, there exact small sample distributional results (i.e. t, F , χ2). • In the exponential family world, there are approximate distributional results (i.e. deviance tests). • In the general setting, we can only appeal to asymptotics. A one-parameter exponential family, F is a one-parameter family of distributions of the form Pη(dx) = exp (η · t(x) − Λ(η)) P0(dx) for some probability measure P0. The parameter η is called the natural or canonical parameter and the function Λ is called the cumulant generating function, and is simply the normalization needed to make dPη fη(x) = (x) = exp (η · t(x) − Λ(η)) dP0 a proper probability density. The random variable t(X) is the sufficient statistic of the exponential family. Note that P0 does not have to be a distribution on R, but these are of course the simplest examples. 1.0.1 A first example: Gaussian with linear sufficient statistic Consider the standard normal distribution Z e−z2=2 P0(A) = p dz A 2π and let t(x) = x. Then, the exponential family is eη·x−x2=2 Pη(dx) / p 2π and we see that Λ(η) = η2=2: eta= np.linspace(-2,2,101) CGF= eta**2/2. plt.plot(eta, CGF) A= plt.gca() A.set_xlabel(r'$\eta$', size=20) A.set_ylabel(r'$\Lambda(\eta)$', size=20) f= plt.gcf() 1 Thus, the exponential family in this setting is the collection F = fN(η; 1) : η 2 Rg : d 1.0.2 Normal with quadratic sufficient statistic on R d As a second example, take P0 = N(0;Id×d), i.e. -

On the Meaning and Use of Kurtosis
Psychological Methods Copyright 1997 by the American Psychological Association, Inc. 1997, Vol. 2, No. 3,292-307 1082-989X/97/$3.00 On the Meaning and Use of Kurtosis Lawrence T. DeCarlo Fordham University For symmetric unimodal distributions, positive kurtosis indicates heavy tails and peakedness relative to the normal distribution, whereas negative kurtosis indicates light tails and flatness. Many textbooks, however, describe or illustrate kurtosis incompletely or incorrectly. In this article, kurtosis is illustrated with well-known distributions, and aspects of its interpretation and misinterpretation are discussed. The role of kurtosis in testing univariate and multivariate normality; as a measure of departures from normality; in issues of robustness, outliers, and bimodality; in generalized tests and estimators, as well as limitations of and alternatives to the kurtosis measure [32, are discussed. It is typically noted in introductory statistics standard deviation. The normal distribution has a kur- courses that distributions can be characterized in tosis of 3, and 132 - 3 is often used so that the refer- terms of central tendency, variability, and shape. With ence normal distribution has a kurtosis of zero (132 - respect to shape, virtually every textbook defines and 3 is sometimes denoted as Y2)- A sample counterpart illustrates skewness. On the other hand, another as- to 132 can be obtained by replacing the population pect of shape, which is kurtosis, is either not discussed moments with the sample moments, which gives or, worse yet, is often described or illustrated incor- rectly. Kurtosis is also frequently not reported in re- ~(X i -- S)4/n search articles, in spite of the fact that virtually every b2 (•(X i - ~')2/n)2' statistical package provides a measure of kurtosis. -

Simple Linear Regression with Least Square Estimation: an Overview
Aditya N More et al, / (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 7 (6) , 2016, 2394-2396 Simple Linear Regression with Least Square Estimation: An Overview Aditya N More#1, Puneet S Kohli*2, Kshitija H Kulkarni#3 #1-2Information Technology Department,#3 Electronics and Communication Department College of Engineering Pune Shivajinagar, Pune – 411005, Maharashtra, India Abstract— Linear Regression involves modelling a relationship amongst dependent and independent variables in the form of a (2.1) linear equation. Least Square Estimation is a method to determine the constants in a Linear model in the most accurate way without much complexity of solving. Metrics where such as Coefficient of Determination and Mean Square Error is the ith value of the sample data point determine how good the estimation is. Statistical Packages is the ith value of y on the predicted regression such as R and Microsoft Excel have built in tools to perform Least Square Estimation over a given data set. line The above equation can be geometrically depicted by Keywords— Linear Regression, Machine Learning, Least Squares Estimation, R programming figure 2.1. If we draw a square at each point whose length is equal to the absolute difference between the sample data point and the predicted value as shown, each of the square would then represent the residual error in placing the I. INTRODUCTION regression line. The aim of the least square method would Linear Regression involves establishing linear be to place the regression line so as to minimize the sum of relationships between dependent and independent variables. -

Univariate and Multivariate Skewness and Kurtosis 1
Running head: UNIVARIATE AND MULTIVARIATE SKEWNESS AND KURTOSIS 1 Univariate and Multivariate Skewness and Kurtosis for Measuring Nonnormality: Prevalence, Influence and Estimation Meghan K. Cain, Zhiyong Zhang, and Ke-Hai Yuan University of Notre Dame Author Note This research is supported by a grant from the U.S. Department of Education (R305D140037). However, the contents of the paper do not necessarily represent the policy of the Department of Education, and you should not assume endorsement by the Federal Government. Correspondence concerning this article can be addressed to Meghan Cain ([email protected]), Ke-Hai Yuan ([email protected]), or Zhiyong Zhang ([email protected]), Department of Psychology, University of Notre Dame, 118 Haggar Hall, Notre Dame, IN 46556. UNIVARIATE AND MULTIVARIATE SKEWNESS AND KURTOSIS 2 Abstract Nonnormality of univariate data has been extensively examined previously (Blanca et al., 2013; Micceri, 1989). However, less is known of the potential nonnormality of multivariate data although multivariate analysis is commonly used in psychological and educational research. Using univariate and multivariate skewness and kurtosis as measures of nonnormality, this study examined 1,567 univariate distriubtions and 254 multivariate distributions collected from authors of articles published in Psychological Science and the American Education Research Journal. We found that 74% of univariate distributions and 68% multivariate distributions deviated from normal distributions. In a simulation study using typical values of skewness and kurtosis that we collected, we found that the resulting type I error rates were 17% in a t-test and 30% in a factor analysis under some conditions. Hence, we argue that it is time to routinely report skewness and kurtosis along with other summary statistics such as means and variances. -

A Family of Skew-Normal Distributions for Modeling Proportions and Rates with Zeros/Ones Excess
S S symmetry Article A Family of Skew-Normal Distributions for Modeling Proportions and Rates with Zeros/Ones Excess Guillermo Martínez-Flórez 1, Víctor Leiva 2,* , Emilio Gómez-Déniz 3 and Carolina Marchant 4 1 Departamento de Matemáticas y Estadística, Facultad de Ciencias Básicas, Universidad de Córdoba, Montería 14014, Colombia; [email protected] 2 Escuela de Ingeniería Industrial, Pontificia Universidad Católica de Valparaíso, 2362807 Valparaíso, Chile 3 Facultad de Economía, Empresa y Turismo, Universidad de Las Palmas de Gran Canaria and TIDES Institute, 35001 Canarias, Spain; [email protected] 4 Facultad de Ciencias Básicas, Universidad Católica del Maule, 3466706 Talca, Chile; [email protected] * Correspondence: [email protected] or [email protected] Received: 30 June 2020; Accepted: 19 August 2020; Published: 1 September 2020 Abstract: In this paper, we consider skew-normal distributions for constructing new a distribution which allows us to model proportions and rates with zero/one inflation as an alternative to the inflated beta distributions. The new distribution is a mixture between a Bernoulli distribution for explaining the zero/one excess and a censored skew-normal distribution for the continuous variable. The maximum likelihood method is used for parameter estimation. Observed and expected Fisher information matrices are derived to conduct likelihood-based inference in this new type skew-normal distribution. Given the flexibility of the new distributions, we are able to show, in real data scenarios, the good performance of our proposal. Keywords: beta distribution; centered skew-normal distribution; maximum-likelihood methods; Monte Carlo simulations; proportions; R software; rates; zero/one inflated data 1. -

Tests Based on Skewness and Kurtosis for Multivariate Normality
Communications for Statistical Applications and Methods DOI: http://dx.doi.org/10.5351/CSAM.2015.22.4.361 2015, Vol. 22, No. 4, 361–375 Print ISSN 2287-7843 / Online ISSN 2383-4757 Tests Based on Skewness and Kurtosis for Multivariate Normality Namhyun Kim1;a aDepartment of Science, Hongik University, Korea Abstract A measure of skewness and kurtosis is proposed to test multivariate normality. It is based on an empirical standardization using the scaled residuals of the observations. First, we consider the statistics that take the skewness or the kurtosis for each coordinate of the scaled residuals. The null distributions of the statistics converge very slowly to the asymptotic distributions; therefore, we apply a transformation of the skewness or the kurtosis to univariate normality for each coordinate. Size and power are investigated through simulation; consequently, the null distributions of the statistics from the transformed ones are quite well approximated to asymptotic distributions. A simulation study also shows that the combined statistics of skewness and kurtosis have moderate sensitivity of all alternatives under study, and they might be candidates for an omnibus test. Keywords: Goodness of fit tests, multivariate normality, skewness, kurtosis, scaled residuals, empirical standardization, power comparison 1. Introduction Classical multivariate analysis techniques require the assumption of multivariate normality; conse- quently, there are numerous test procedures to assess the assumption in the literature. For a gen- eral review, some references are Henze (2002), Henze and Zirkler (1990), Srivastava and Mudholkar (2003), and Thode (2002, Ch.9). For comparative studies in power, we refer to Farrell et al. (2007), Horswell and Looney (1992), Mecklin and Mundfrom (2005), and Romeu and Ozturk (1993). -

Generalized Linear Models
Generalized Linear Models Advanced Methods for Data Analysis (36-402/36-608) Spring 2014 1 Generalized linear models 1.1 Introduction: two regressions • So far we've seen two canonical settings for regression. Let X 2 Rp be a vector of predictors. In linear regression, we observe Y 2 R, and assume a linear model: T E(Y jX) = β X; for some coefficients β 2 Rp. In logistic regression, we observe Y 2 f0; 1g, and we assume a logistic model (Y = 1jX) log P = βT X: 1 − P(Y = 1jX) • What's the similarity here? Note that in the logistic regression setting, P(Y = 1jX) = E(Y jX). Therefore, in both settings, we are assuming that a transformation of the conditional expec- tation E(Y jX) is a linear function of X, i.e., T g E(Y jX) = β X; for some function g. In linear regression, this transformation was the identity transformation g(u) = u; in logistic regression, it was the logit transformation g(u) = log(u=(1 − u)) • Different transformations might be appropriate for different types of data. E.g., the identity transformation g(u) = u is not really appropriate for logistic regression (why?), and the logit transformation g(u) = log(u=(1 − u)) not appropriate for linear regression (why?), but each is appropriate in their own intended domain • For a third data type, it is entirely possible that transformation neither is really appropriate. What to do then? We think of another transformation g that is in fact appropriate, and this is the basic idea behind a generalized linear model 1.2 Generalized linear models • Given predictors X 2 Rp and an outcome Y , a generalized linear model is defined by three components: a random component, that specifies a distribution for Y jX; a systematic compo- nent, that relates a parameter η to the predictors X; and a link function, that connects the random and systematic components • The random component specifies a distribution for the outcome variable (conditional on X). -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed. -

Approximating the Distribution of the Product of Two Normally Distributed Random Variables
S S symmetry Article Approximating the Distribution of the Product of Two Normally Distributed Random Variables Antonio Seijas-Macías 1,2 , Amílcar Oliveira 2,3 , Teresa A. Oliveira 2,3 and Víctor Leiva 4,* 1 Departamento de Economía, Universidade da Coruña, 15071 A Coruña, Spain; [email protected] 2 CEAUL, Faculdade de Ciências, Universidade de Lisboa, 1649-014 Lisboa, Portugal; [email protected] (A.O.); [email protected] (T.A.O.) 3 Departamento de Ciências e Tecnologia, Universidade Aberta, 1269-001 Lisboa, Portugal 4 Escuela de Ingeniería Industrial, Pontificia Universidad Católica de Valparaíso, Valparaíso 2362807, Chile * Correspondence: [email protected] or [email protected] Received: 21 June 2020; Accepted: 18 July 2020; Published: 22 July 2020 Abstract: The distribution of the product of two normally distributed random variables has been an open problem from the early years in the XXth century. First approaches tried to determinate the mathematical and statistical properties of the distribution of such a product using different types of functions. Recently, an improvement in computational techniques has performed new approaches for calculating related integrals by using numerical integration. Another approach is to adopt any other distribution to approximate the probability density function of this product. The skew-normal distribution is a generalization of the normal distribution which considers skewness making it flexible. In this work, we approximate the distribution of the product of two normally distributed random variables using a type of skew-normal distribution. The influence of the parameters of the two normal distributions on the approximation is explored. When one of the normally distributed variables has an inverse coefficient of variation greater than one, our approximation performs better than when both normally distributed variables have inverse coefficients of variation less than one.