Creating and Using Context-Sensitive Linguistic Features in Text Mining Models Russell Albright, Janardhana Punuru, and Lane Surratt, SAS Institute Inc
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Quick-Start Workbook I
Quick -Start Introduction to Worldspan Reservations Workbook 2160 11/98 © 2000 Worldspan, L.P. All Rights Reserved. Worldspan, L.P. is primarily jointly owned by affiliates of Delta Air Lines, Northwest Airlines, and Trans World Airlines. Table of Contents Introducing Worldspan....................................................................................................... 1 What is Worldspan?........................................................................................................... 2 Introducing The Reservations Manager Screen.............................................................. 5 What Am I Looking At?................................................................................................ 5 More About Res Windows ........................................................................................... 7 Codes, Codes, and More Codes........................................................................................ 9 Airline Codes...............................................................................................................10 City and Airport Codes ...............................................................................................12 It All Begins with a PNR…..............................................................................................15 Let’s File the Information...........................................................................................17 When Can I Leave and How Much Will It Cost?...........................................................20 -

IATA CLEARING HOUSE PAGE 1 of 21 2021-09-08 14:22 EST Member List Report
IATA CLEARING HOUSE PAGE 1 OF 21 2021-09-08 14:22 EST Member List Report AGREEMENT : Standard PERIOD: P01 September 2021 MEMBER CODE MEMBER NAME ZONE STATUS CATEGORY XB-B72 "INTERAVIA" LIMITED LIABILITY COMPANY B Live Associate Member FV-195 "ROSSIYA AIRLINES" JSC D Live IATA Airline 2I-681 21 AIR LLC C Live ACH XD-A39 617436 BC LTD DBA FREIGHTLINK EXPRESS C Live ACH 4O-837 ABC AEROLINEAS S.A. DE C.V. B Suspended Non-IATA Airline M3-549 ABSA - AEROLINHAS BRASILEIRAS S.A. C Live ACH XB-B11 ACCELYA AMERICA B Live Associate Member XB-B81 ACCELYA FRANCE S.A.S D Live Associate Member XB-B05 ACCELYA MIDDLE EAST FZE B Live Associate Member XB-B40 ACCELYA SOLUTIONS AMERICAS INC B Live Associate Member XB-B52 ACCELYA SOLUTIONS INDIA LTD. D Live Associate Member XB-B28 ACCELYA SOLUTIONS UK LIMITED A Live Associate Member XB-B70 ACCELYA UK LIMITED A Live Associate Member XB-B86 ACCELYA WORLD, S.L.U D Live Associate Member 9B-450 ACCESRAIL AND PARTNER RAILWAYS D Live Associate Member XB-280 ACCOUNTING CENTRE OF CHINA AVIATION B Live Associate Member XB-M30 ACNA D Live Associate Member XB-B31 ADB SAFEGATE AIRPORT SYSTEMS UK LTD. A Live Associate Member JP-165 ADRIA AIRWAYS D.O.O. D Suspended Non-IATA Airline A3-390 AEGEAN AIRLINES S.A. D Live IATA Airline KH-687 AEKO KULA LLC C Live ACH EI-053 AER LINGUS LIMITED B Live IATA Airline XB-B74 AERCAP HOLDINGS NV B Live Associate Member 7T-144 AERO EXPRESS DEL ECUADOR - TRANS AM B Live Non-IATA Airline XB-B13 AERO INDUSTRIAL SALES COMPANY B Live Associate Member P5-845 AERO REPUBLICA S.A. -
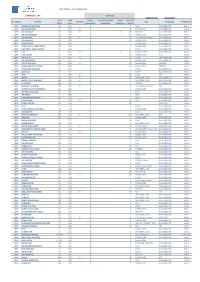
UPDATED ON: 18-03-2019 STATION AIRLINE IATA CODE AWB Prefix ON-LINE CARGO HANDLING FREIGHTER RAMP HANDLING RAMP LINEHAUL IMPORT
WFS CARGO - CUSTOMERS LIST DENMARK - CPH SERVICES UPDATED ON: 18-03-2019 IATA AWB CARGO FREIGHTER RAMP RAMP IMPORT STATION AIRLINE ON-LINE GSA TRUCKING TERMINAL CODE Prefix HANDLING HANDLING LINEHAUL EXPORT CPH AMERICAN AIRLINES AA 001 X E NAL WALLENBORN HAL 1 CPH DELTA AIRLINES DL 006 X X I/E PROACTIVE WALLENBORN HAL1 CPH AIR CANADA AC 014 X X X I/E HWF DK WALLENBORN HAL 1 CPH UNITED AIRLINES UA 016 X I/E NORDIC GSA WALLENBORN HAL1 CPH LUFTHANSA LH 020 X X I/E LUFTHANSA CARGO WALLENBORN HAL1 CPH US AIRWAYS US 037 X I/E NORDIC GSA WALLENBORN HAL1 CPH DRAGON AIR XH 043 X I NORDIC GSA WALLENBORN HAL1 CPH AEROLINEAS ARGENTINAS AR 044 X E CARGOCARE WALLENBORN HAL1 CPH LAN CHILE - LINEA AEREA LA 045 X E KALES WALLENBORN HAL1 CPH TAP TP 047 X X x I/E SCANPARTNER WALLENBORN HAL1 CPH AER LINGUS EI 053 X I/E NORDIC GSA N/A HAL1 CPH AIR France AF 057 X X I/E KL/AF KIM JOHANSEN HAL2 CPH AIR SEYCHELLES HM 061 X E NORDIC GSA WALLENBORN HAL1 CPH CZECH AIRLINES OK 064 X X I/E AviationPlus VARIOUS HAL1 CPH SAUDI AIRLINES CARGO SV 065 X I/E AviationPlus VARIOUS HAL1 CPH ETHIOPIAN AIRLINES ET 071 X E KALES WALLENBORN HAL1 CPH GULF AIR GF 072 X E KALES WALLENBORN HAL1 CPH KLM KL 074 X X I/E KL/AF JDR HAL2 CPH IBERIA IB 075 X X I/E UNIVERSAL GSA WALLENBORN HAL1 CPH MIDDLE EAST AIRLINES ME 076 X X E UNIVERSAL GSA WALLENBORN HAL1 CPH EGYPTAIR MS 077 X E HWF DK WALLENBORN HAL1 CPH BRUSSELS AIRLINES SN 020 X X I/E LUFTHANSA CARGO JDR HAL1 CPH SOUTH AFRICAN AIRWAYS SA 083 X E CARGOCARE WALLENBORN HAL1 CPH AIR NEW ZEALAND NZ 086 X E KALES WALLENBORN HAL1 CPH AIR -

February 8, 2006 CJSC Comtech-N
USER MANUAL: RESOURCE AND SALES MANAGEMENT PROCESSES IN SIRENA AUTOMATED SYSTEM Graphical Terminal February 8, 2006 CJSC Comtech-N © CJSC Comtech-N, 2005 Resource and Sales Management in Sirena AS February 8, 2006 CONTENTS 1 Introduction ......................................................................................... 9 2 Getting started ...................................................................................... 9 2.1 System logon. System messages ................................................................................. 9 2.2 Task list ...................................................................................................................... 10 2.3 Operator status (Me? request) ................................................................................ 11 Password change (NP request) .................................................................................. 12 3 Catalogs management ......................................................................... 12 3.1 Catalog handling techniques .................................................................................... 15 Catalog selection ........................................................................................................ 16 Catalog scrolling ........................................................................................................ 16 Quick search of catalog entry ..................................................................................... 16 Operations with cards ............................................................................................... -

Airplus Company Account: Airline Acceptance
AirPlus Company Account: Airline Acceptance IATA ICAO Country GDS ONLINE (Web) Comments Code Code Acceptance DBI Acceptance DBI Aegean Airlines A3 AEE GR a a a online acceptance: web & mobile Aer Arann RE REA IE a a Aer Lingus P.L.C. EI EIN IE a a a * Aeroflot Russian Intl. Airlines SU AFL RU a a a Aerogal 2K GLG EC a a Aeromar VW TAO MX a a a Aeroméxico AM AMX MX a a a Air Algérie AH DAH DZ a a Air Alps A6 LPV AT a a Air Astana KC KZR KZ a a Air Austral UU REU RE a a Air Baltic BT BTI LV a a Air Busan BX ABL KR a a Air Canada AC ACA CA a a a * Air Caraibes TX FWI FR a a a Air China CA CCA CN a a a a online acceptance in China only Air Corsica XK CCM FR a a Air Dolomiti EN DLA IT a a a Air Europa UX AEA ES a a Air France AF AFR FR a a a * Air Greenland GL GRL GL a a a Air India AI AIC IN a a Air Macau NX AMU MO a a Air Malta KM AMC MT a a a Air Mauritius MK MAU MU a a Air New Zealand NZ ANZ NZ a a a Air Niugini PX ANG PG a a a Air One AP ADH IT a a a Air Serbia JU ASL RS a a a Air Seychelles HM SEY SC a a Air Tahiti Nui VT VTA PF a a Air Vanuatu NF AVN VU a a Air Wisconsin ZW WSN US a a a Aircalin (Air Calédonie Intl.) SB ACI FR a a Air-Taxi Europe - TWG DE a a * AirTran Airways FL TRS US a a a * Alaska Airlines AS ASA US a a a Alitalia AZ AZA IT a a a * All Nippon Airways (ANA) NH ANA JP a a a American Airlines AA AAL US a a a * APG Airlines GP - FR a a a Arik Air W3 ARA NG a a Asiana Airlines OZ AAR KR a a a * Austrian Airlines OS AUA AT a a a a Avianca AV AVA CO a a Azul Linhas Aéreas Brasileiras AD AZU BR a a a Bahamasair UP BHS BS a a Bangkok Airways PG BKP TH a a Bearskin Airlines JV BLS US a a Beijing Capital Airlines JD CBJ CN a a Biman Bangladesh BG BBC BD a a BizCharters (BizAir Shuttle) - - US a a Blue Panorama BV BPA IT a a * Boliviana de Aviación OB BOV BO a a a British Airways BA BAW UK a a a a only one DBI field for online bookings available Brussels Airlines SN BEL BE a a a a Canadian North Inc. -

Airline Codes.Indd
AIRLINE CODES AND AWB PREFIX PREFIX IATA code AIRLINE PREFIX IATA code AIRLINE 044 AR Aerolineas Argentinas 173 HA Hawaiian Air Cargo 139 AM Aero Mexico 096 IR Iran Air 439 ZI Aigle Azur 131 JL Japan Airlines 657 BT Air Baltic 745 TB JetairFly 745 AB Air Berlin 589 9W Jet Airways 580 RU Air Bridge Cargo 074 KL KLM 159 CW Air Cargo Global 180 KE Korean Airlines 014 AC Air Canada 229 KU Kuwait Airways 427 TX Air Caraibes 045 LA Lan Chili 999 CA Air China International 148 LN Libyan Airlines 745 UX Air Europe 020 LH Lufthansa Cargo 057 AF Air France 232 MH Malaysian Airline 167 QM Air Malawi 129 MO Martinair 643 KM Air Malta 429 VL Med View Airlines 239 MK Air Mauritius 805 4X Mercury Air Cargo 086 NZ Air New Zealand 716 MG MNG Airlines Cargo 115 JU Air Serbia 519 NAB Niger Air Cargo 135 VT Air Tahiti 933 KZ Nippon Cargo Airlines 649 TS Air Transat 329 DY Norwegian Cargo 574 4W Allied Air 910 WY Oman Air 001 AA American Airlines 214 PR Pakistan International 810 M6 Amerijet International 624 PC Pegasus Airlines 988 OZ Asiana Airlines 079 PR Philippine Airlines 369 5Y Atlas Global 157 QR Qatar Airways 134 AV Avianca - Aerovias 672 BI Royal Runei Airlines 417 E6 Bringer Air Cargo 512 RJ Royal Jordanian 125 BA British Airways 117 SK Scandinavian Airlines 489 W8 Cargojet Airways 774 FM Shanghai Airlines 172 CV Cargolux Airlines 728 U3 Sky Gates 700 5C CAL 501 7L Silk Way West Airlines 160 CX Cathay Pacific Airways 618 SQ Singapore Airline Cargo 297 CI China Airlines 603 LX Srilankan Airlines 112 CK China Cargo Airlines 242 4E Stabo Air 781 MU -

Airlines Codes
Airlines codes Sorted by Airlines Sorted by Code Airline Code Airline Code Aces VX Deutsche Bahn AG 2A Action Airlines XQ Aerocondor Trans Aereos 2B Acvilla Air WZ Denim Air 2D ADA Air ZY Ireland Airways 2E Adria Airways JP Frontier Flying Service 2F Aea International Pte 7X Debonair Airways 2G AER Lingus Limited EI European Airlines 2H Aero Asia International E4 Air Burkina 2J Aero California JR Kitty Hawk Airlines Inc 2K Aero Continente N6 Karlog Air 2L Aero Costa Rica Acori ML Moldavian Airlines 2M Aero Lineas Sosa P4 Haiti Aviation 2N Aero Lloyd Flugreisen YP Air Philippines Corp 2P Aero Service 5R Millenium Air Corp 2Q Aero Services Executive W4 Island Express 2S Aero Zambia Z9 Canada Three Thousand 2T Aerocaribe QA Western Pacific Air 2U Aerocondor Trans Aereos 2B Amtrak 2V Aeroejecutivo SA de CV SX Pacific Midland Airlines 2W Aeroflot Russian SU Helenair Corporation Ltd 2Y Aeroleasing SA FP Changan Airlines 2Z Aeroline Gmbh 7E Mafira Air 3A Aerolineas Argentinas AR Avior 3B Aerolineas Dominicanas YU Corporate Express Airline 3C Aerolineas Internacional N2 Palair Macedonian Air 3D Aerolineas Paraguayas A8 Northwestern Air Lease 3E Aerolineas Santo Domingo EX Air Inuit Ltd 3H Aeromar Airlines VW Air Alliance 3J Aeromexico AM Tatonduk Flying Service 3K Aeromexpress QO Gulfstream International 3M Aeronautica de Cancun RE Air Urga 3N Aeroperlas WL Georgian Airlines 3P Aeroperu PL China Yunnan Airlines 3Q Aeropostal Alas VH Avia Air Nv 3R Aerorepublica P5 Shuswap Air 3S Aerosanta Airlines UJ Turan Air Airline Company 3T Aeroservicios -

International Civil Aviation Organization Asia and Pacific Office
INTERNATIONAL CIVIL AVIATION ORGANIZATION ASIA AND PACIFIC OFFICE REPORT OF THE TWELFTH MEETING OF THE APANPIRG ATS/AIS/SAR SUB-GROUP (ATS/AIS/SAR/SG/12) Bangkok, Thailand, 24 – 28 June 2002 The views expressed in this Report should be taken as those of the Sub-Group and not the Organization Approved by the Meeting And published by ICAO Asia and Pacific Office ATS/AIS/SAR/SG/12 Table of Contents TABLE OF CONTENTS Page Part I - History of the Meeting Introduction ..................................................................................................................................... i Attendance ...................................................................................................................................... i Officers and Secretariat ................................................................................................................... i Language and Documentation .......................................................................................................... i Opening of the Meeting .................................................................................................................... i Draft Conclusions, Draft Decisions and Decisions – Definitions..................................................... i List of Draft Conclusions, Draft Decisions and Decisions ..............................................................ii Part II – Report on Agenda Items Agenda Item 1 Adoption of Provisional Agenda.................................................................1-1 Agenda -

1.4. Coding and Decoding of Airlines 1.4.1. Coding Of
1.4. CODING AND DECODING OF AIRLINES 1.4.1. CODING OF AIRLINES In addition to the airlines' full names in alphabetical order the list below also contains: - Column 1: the airlines' prefix numbers (Cargo) - Column 2: the airlines' 2 character designators - Column 3: the airlines' 3 letter designators A Explanation of symbols: + IATA Member & IATA Associate Member * controlled duplication # Party to the IATA Standard Interline Traffic Agreement (see section 8.1.1.) © Cargo carrier only Full name of carrier 1 2 3 40-Mile Air, Ltd. Q5 MLA AAA - Air Alps Aviation A6 LPV AB Varmlandsflyg T9 ABX Air, Inc. © 832 GB Ada Air + 121 ZY ADE Adria Airways + # 165 JP ADR Aegean Airlines S.A. + # 390 A3 AEE Aer Arann Express (Comharbairt Gaillimh Teo) 809 RE REA Aeris SH AIS Aer Lingus Limited + # 053 EI EIN Aero Airlines A.S. 350 EE Aero Asia International Ltd. + # 532 E4 Aero Benin S.A. EM Aero California + 078 JR SER Aero-Charter 187 DW UCR Aero Continente 929 N6 ACQ Aero Continente Dominicana 9D Aero Express Del Ecuador - Trans AM © 144 7T Aero Honduras S.A. d/b/a/ Sol Air 4S Aero Lineas Sosa P4 Aero Lloyd Flugreisen GmbH & Co. YP AEF Aero Republica S.A. 845 P5 RPB Aero Zambia + # 509 Z9 Aero-Condor S.A. Q6 Aero Contractors Company of Nigeria Ltd. AJ NIG Aero-Service BF Aerocaribe 723 QA CBE Aerocaribbean S.A. 164 7L CRN Aerocontinente Chile S.A. C7 Aeroejecutivo S.A. de C.V. 456 SX AJO Aeroflot Russian Airlines + # 555 SU AFL Aeroflot-Don 733 D9 DNV Aerofreight Airlines JSC RS Aeroline GmbH 7E AWU Aerolineas Argentinas + # 044 AR ARG Aerolineas Centrales de Colombia (ACES) + 137 VX AES Aerolineas de Baleares AeBal 059 DF ABH Aerolineas Dominicanas S.A. -

The ANKER Report 64 (18 Jan 2021) (Pdf) Download
Issue 64 Monday 18 January 2021 www.anker-report.com Contents 2021 set to start badly in Europe but 1 2021 set to start badly in Europe but vaccines provide hope for second half of year. vaccines provide hope for second half 3 Ryanair set to further tighten grip on Italian market with new base in So what has happened in Europe since the last issue of The airlines saw a significant drop in flights compared with the Venice set to open in summer. ANKER Report in mid-December? Well, the UK and EU finally previous week. easyJet’s operations fell once more to less than managed to agree a Brexit trade deal after all, COVID vaccines 10% of their operations compared with a year ago, while British 4 Latest European route news; 63 new have started being administered across the region, the Dutch Airways and Vueling were both well below 20% of their flights routes from 28 airlines analysed. and Italian governments are in crisis, and the mutant strains of compared with early 2020. 8 Montenegro sees collapse of COVID identified in the UK, South Africa and Brazil have raised Only KLM, among major airlines, was operating at above 50% of national carrier which was significant health concerns, resulting in further travel last year’s flights, though mention should be made of Norway’s responsible for 25% of traffic in restrictions in many European countries. This included the UK domestic carrier Widerøe which has consistently operated at 2019; several carriers could be closure of all ‘air corridors’ last Friday. -

CHAMP Cargosystems Traxon Cargohub Airline Matrix
███ New carrier CHAMP Cargosystems 1 Partner network 2 Carrier that belongs to the Leisure Cargo Group Traxon cargoHUB Airline Matrix 3Additional charges may apply List is subject to change. Terms and conditions may apply according to partners and/or airlines service availability IATA IATA IATA AWB AWB AWB Airline Name 2-letter Airline Name 2-letter Airline Name 2-letter Prefix Prefix Prefix code code code A C N Aer Lingus Ltd. 053 EI China Cargo Airlines 112 CK Nasair Eritrea 2 745 XY Aeroflot Russian Airlines 555 SU China Eastern Airlines 781 MU Neos 2 745 NO AeroUnion (Aerotransporte de Carga Unión) 873 6R China Southern Cargo 784 CZ Niki 2 745 HG AHK Air Hongkong 1 160 LD Condor 2 745 DE Nippon Cargo Airlines 1 933 KZ Air Algerie 3 NEW! 124 AH Czech Airlines 064 OK Air Baltic 1 NEW! 657 BT O - R Air Berlin 2 745 AB D - F Orbest 2 745 6O Air Canada 014 AC Delta Air Lines 006 DL Philippine Airlines 3 NEW! 079 PR Air Canada Rouge 014 AC Dragonair 1 / 3 043 KA Polar Air Cargo 403 PO Air China Int. Cooperation 1 999 CA EL AL Israel Airlines 114 LY Qantas Airways 1 081 QF Air Europa 2 745 UX Emirates Sky Cargo 176 EK Qatar Airways 1 157 QR Air France 057 AF Etihad Crystal Cargo 1 607 EY Royal Air Maroc 147 AT Air India 3 NEW! 098 AI Ethiopian Cargo 071 ET Air Italy 2 745 I9 EVA Airways 1 695 BR S Air Malta 643 KM FedEx Express 3 NEW! 023 FX SAS Scandinavian Airlines 1 117 SK Air Mauritius 239 MK Finnair Cargo 105 AY Saudi Arabian Airlines 065 SV Air New Zealand 1 086 NZ Silkway Airlines 1 NEW! 463 ZP Air Tahiti Nui 244 TN G - J Silkway -

List of Assigned Manufacturer's Codes (MMM)
To Air Industry List Date March 4, 2020 From Scott L. Smith Reference 19-114/ABN-052 kpp [email protected] tel +1 443-221-8372 Subject List of Assigned Manufacturer’s Codes (MMM) Summary This list supersedes the previous edition issued as Ref: 18-136/ABN-051. Software Manufacturer’s codes (MMM) are defined by: ARINC Report 645: Common Terminology and Functions for Software Distribution and Loading. ARINC Report 665: Loadable Software Standards. The following MMM Code assignments have been added: Mfg Code Organization AJQ Air Peace Limited AUI Ukraine International Airlines BRU Belavia Belarusian Airlines CAW Comair Limited CAY Cayman Airways Ltd CDI Craft Designs, Inc. CND Corendon Dutch Airlines DAH Diehl Aviation Holding GmbH EAK Enter Air Sp. z o.o. EPA Donghai Airlines FEG FlyEgypt FLC Thales Avionics (USA) INI Initium Aerospace HEN Hensoldt Sensors GmbH ONT Ontic Engineering & Manufacturing UK Ltd. STG STG Aerospace Ltd TKS ThinKom Solutions TWB Tway Air co.ltd URL Ural Airlines UTR UTair JSC VTI Vistara SIA Airlines Ltd. Action Software developers and users are invited to review this document and direct changes or additions using the email address [email protected]. Please allow 90 days for your input to be included in the published list. This document is published information as defined by 15 CFR Section 734.7 of the Export Administration Regulations (EAR). As publicly available technology under 15 CFR 74.3(b)(3), it is not subject to the EAR and does not have an ECCN. It may be exported without an export license. 16701 Melford Blvd., Suite 120, Bowie, Maryland 20715 USA http://www.aviation-ia.com/activities/aeec List of Manufacturer’s Codes Introduction This is the current list of assigned Manufacturer’s Designator Codes.