Quantitative and Functional Analysis Pipeline for Label-Free Metaproteomics Data and Its Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Doctoral Dissertation Template
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE METAGENOMIC INSIGHTS INTO MICROBIAL COMMUNITY RESPONSES TO LONG-TERM ELEVATED CO2 A DISSERTATION SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY By QICHAO TU Norman, Oklahoma 2014 METAGENOMIC INSIGHTS INTO MICROBIAL COMMUNITY RESPONSES TO LONG-TERM ELEVATED CO2 A DISSERTATION APPROVED FOR THE DEPARTMENT OF MICROBIOLOGY AND PLANT BIOLOGY BY ______________________________ Dr. Jizhong Zhou, Chair ______________________________ Dr. Meijun Zhu ______________________________ Dr. Fengxia (Felicia) Qi ______________________________ Dr. Michael McInerney ______________________________ Dr. Bradley Stevenson © Copyright by QICHAO TU 2014 All Rights Reserved. Acknowledgements At this special moment approaching the last stage for this degree, I would like to express my gratitude to all the people who encouraged me and helped me out through the past years. Dr. Jizhong Zhou, my advisor, is no doubt the most influential and helpful person in pursuing my academic goals. In addition to continuous financial support for the past six years, he is the person who led me into the field of environmental microbiology, from a background of bioinformatics and plant molecular biology. I really appreciated the vast training I received from the many interesting projects I got involved in, without which I would hardly develop my broad experienced background from pure culture microbial genomics to complex metagenomics. Dr. Zhili He, who played a role as my second advisor, is also the person I would like to thank most. Without his help, I could be still struggling working on those manuscripts lying in my hard drive. I definitely learned a lot from him in organizing massed results into logical scientific work—skills that will benefit me for life. -

Renal Cell Neoplasms Contain Shared Tumor Type–Specific Copy Number Variations
The American Journal of Pathology, Vol. 180, No. 6, June 2012 Copyright © 2012 American Society for Investigative Pathology. Published by Elsevier Inc. All rights reserved. http://dx.doi.org/10.1016/j.ajpath.2012.01.044 Tumorigenesis and Neoplastic Progression Renal Cell Neoplasms Contain Shared Tumor Type–Specific Copy Number Variations John M. Krill-Burger,* Maureen A. Lyons,*† The annual incidence of renal cell carcinoma (RCC) has Lori A. Kelly,*† Christin M. Sciulli,*† increased steadily in the United States for the past three Patricia Petrosko,*† Uma R. Chandran,†‡ decades, with approximately 58,000 new cases diag- 1,2 Michael D. Kubal,§ Sheldon I. Bastacky,*† nosed in 2010, representing 3% of all malignancies. Anil V. Parwani,*†‡ Rajiv Dhir,*†‡ and Treatment of RCC is complicated by the fact that it is not a single disease but composes multiple tumor types with William A. LaFramboise*†‡ different morphological characteristics, clinical courses, From the Departments of Pathology* and Biomedical and outcomes (ie, clear-cell carcinoma, 82% of RCC ‡ Informatics, University of Pittsburgh, Pittsburgh, Pennsylvania; cases; type 1 or 2 papillary tumors, 11% of RCC cases; † the University of Pittsburgh Cancer Institute, Pittsburgh, chromophobe tumors, 5% of RCC cases; and collecting § Pennsylvania; and Life Technologies, Carlsbad, California duct carcinoma, approximately 1% of RCC cases).2,3 Benign renal neoplasms are subdivided into papillary adenoma, renal oncocytoma, and metanephric ade- Copy number variant (CNV) analysis was performed on noma.2,3 Treatment of RCC often involves surgical resec- renal cell carcinoma (RCC) specimens (chromophobe, tion of a large renal tissue component or removal of the clear cell, oncocytoma, papillary type 1, and papillary entire affected kidney because of the relatively large size of type 2) using high-resolution arrays (1.85 million renal tumors on discovery and the availability of a life-sus- probes). -

Salivary Alpha Amylase (AMY1C) (NM 001008219) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RG215827 Salivary alpha amylase (AMY1C) (NM_001008219) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: Salivary alpha amylase (AMY1C) (NM_001008219) Human Tagged ORF Clone Tag: TurboGFP Symbol: AMY1C Synonyms: AMY1 Vector: pCMV6-AC-GFP (PS100010) E. coli Selection: Ampicillin (100 ug/mL) Cell Selection: Neomycin This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 5 Salivary alpha amylase (AMY1C) (NM_001008219) Human Tagged ORF Clone – RG215827 ORF Nucleotide >RG215827 representing NM_001008219 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGAAGCTCTTTTGGTTGCTTTTCACCATTGGGTTCTGCTGGGCTCAGTATTCCTCAAATACACAACAAG GACGAACATCTATTGTTCATCTGTTTGAATGGCGATGGGTTGATATTGCTCTTGAATGTGAGCGATATTT AGCTCCCAAGGGATTTGGAGGGGTTCAGGTCTCTCCACCAAATGAAAATGTTGCCATTCACAACCCTTTC AGACCTTGGTGGGAAAGATACCAACCAGTTAGCTATAAATTATGCACAAGATCTGGAAATGAAGATGAAT TTAGAAACATGGTGACTAGATGCAACAATGTTGGGGTTCGTATTTATGTGGATGCTGTAATTAATCATAT GTGTGGTAATGCTGTGAGTGCAGGAACAAGCAGTACCTGTGGAAGTTACTTCAACCCTGGAAGTAGGGAC TTTCCAGCAGTCCCATATTCTGGATGGGATTTTAATGATGGTAAATGTAAAACTGGAAGTGGAGATATCG AGAACTATAATGATGCTACTCAGGTCAGAGATTGTCGTCTGTCTGGTCTTCTCGATCTTGCACTGGGGAA -

Shotgun Metagenomics of 361 Elderly Women Reveals Gut Microbiome
bioRxiv preprint doi: https://doi.org/10.1101/679985; this version posted June 23, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Shotgun Metagenomics of 361 elderly women reveals gut microbiome change in bone mass loss Qi Wang1,2,3,4, *, Hui Zhao1,2,3,4, *, Qiang Sun2,5, *, Xiaoping Li3,4, *, Juanjuan Chen3,4, Zhefeng Wang6, Yanmei Ju2,3,4, Zhuye Jie3,4, Ruijin Guo3,4,7,8, Yuhu Liang2, Xiaohuan Sun3,4, Haotian Zheng3,4, Tao Zhang3,4, Liang Xiao3,4, Xun Xu3,4, Huanming Yang3,9, Songlin Peng6, †, Huijue Jia3,4,7,8, †. 1. School of Future Technology, University of Chinese Academy of Sciences, Beijing, 101408, China. 2. BGI Education Center, University of Chinese Academy of Sciences, Shenzhen 518083, China; 3. BGI-Shenzhen, Shenzhen 518083, China; 4. China National Genebank, Shenzhen 518120, China; 5. Department of Statistical Sciences, University of Toronto, Toronto, Canada; 6. Department of Spine Surgery, Shenzhen People's Hospital, Ji Nan University Second College of Medicine, 518020, Shenzhen, China. 7. Macau University of Science and Technology, Taipa, Macau 999078, China; 8. Shenzhen Key Laboratory of Human Commensal Microorganisms and Health Research, BGI-Shenzhen, Shenzhen 518083, China; 9. James D. Watson Institute of Genome Sciences, 310058 Hangzhou, China; * These authors have contributed equally to this study †Corresponding authors: S.P., [email protected]; H.J., [email protected]; bioRxiv preprint doi: https://doi.org/10.1101/679985; this version posted June 23, 2019. -

Chuanxiong Rhizoma Compound on HIF-VEGF Pathway and Cerebral Ischemia-Reperfusion Injury’S Biological Network Based on Systematic Pharmacology
ORIGINAL RESEARCH published: 25 June 2021 doi: 10.3389/fphar.2021.601846 Exploring the Regulatory Mechanism of Hedysarum Multijugum Maxim.-Chuanxiong Rhizoma Compound on HIF-VEGF Pathway and Cerebral Ischemia-Reperfusion Injury’s Biological Network Based on Systematic Pharmacology Kailin Yang 1†, Liuting Zeng 1†, Anqi Ge 2†, Yi Chen 1†, Shanshan Wang 1†, Xiaofei Zhu 1,3† and Jinwen Ge 1,4* Edited by: 1 Takashi Sato, Key Laboratory of Hunan Province for Integrated Traditional Chinese and Western Medicine on Prevention and Treatment of 2 Tokyo University of Pharmacy and Life Cardio-Cerebral Diseases, Hunan University of Chinese Medicine, Changsha, China, Galactophore Department, The First 3 Sciences, Japan Hospital of Hunan University of Chinese Medicine, Changsha, China, School of Graduate, Central South University, Changsha, China, 4Shaoyang University, Shaoyang, China Reviewed by: Hui Zhao, Capital Medical University, China Background: Clinical research found that Hedysarum Multijugum Maxim.-Chuanxiong Maria Luisa Del Moral, fi University of Jaén, Spain Rhizoma Compound (HCC) has de nite curative effect on cerebral ischemic diseases, *Correspondence: such as ischemic stroke and cerebral ischemia-reperfusion injury (CIR). However, its Jinwen Ge mechanism for treating cerebral ischemia is still not fully explained. [email protected] †These authors share first authorship Methods: The traditional Chinese medicine related database were utilized to obtain the components of HCC. The Pharmmapper were used to predict HCC’s potential targets. Specialty section: The CIR genes were obtained from Genecards and OMIM and the protein-protein This article was submitted to interaction (PPI) data of HCC’s targets and IS genes were obtained from String Ethnopharmacology, a section of the journal database. -

Early Growth Response 1 Regulates Hematopoietic Support and Proliferation in Human Primary Bone Marrow Stromal Cells
Hematopoiesis SUPPLEMENTARY APPENDIX Early growth response 1 regulates hematopoietic support and proliferation in human primary bone marrow stromal cells Hongzhe Li, 1,2 Hooi-Ching Lim, 1,2 Dimitra Zacharaki, 1,2 Xiaojie Xian, 2,3 Keane J.G. Kenswil, 4 Sandro Bräunig, 1,2 Marc H.G.P. Raaijmakers, 4 Niels-Bjarne Woods, 2,3 Jenny Hansson, 1,2 and Stefan Scheding 1,2,5 1Division of Molecular Hematology, Department of Laboratory Medicine, Lund University, Lund, Sweden; 2Lund Stem Cell Center, Depart - ment of Laboratory Medicine, Lund University, Lund, Sweden; 3Division of Molecular Medicine and Gene Therapy, Department of Labora - tory Medicine, Lund University, Lund, Sweden; 4Department of Hematology, Erasmus MC Cancer Institute, Rotterdam, the Netherlands and 5Department of Hematology, Skåne University Hospital Lund, Skåne, Sweden ©2020 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol. 2019.216648 Received: January 14, 2019. Accepted: July 19, 2019. Pre-published: August 1, 2019. Correspondence: STEFAN SCHEDING - [email protected] Li et al.: Supplemental data 1. Supplemental Materials and Methods BM-MNC isolation Bone marrow mononuclear cells (BM-MNC) from BM aspiration samples were isolated by density gradient centrifugation (LSM 1077 Lymphocyte, PAA, Pasching, Austria) either with or without prior incubation with RosetteSep Human Mesenchymal Stem Cell Enrichment Cocktail (STEMCELL Technologies, Vancouver, Canada) for lineage depletion (CD3, CD14, CD19, CD38, CD66b, glycophorin A). BM-MNCs from fetal long bones and adult hip bones were isolated as reported previously 1 by gently crushing bones (femora, tibiae, fibulae, humeri, radii and ulna) in PBS+0.5% FCS subsequent passing of the cell suspension through a 40-µm filter. -

The Genome-Wide Landscape of Copy Number Variations in the MUSGEN Study Provides Evidence for a Founder Effect in the Isolated Finnish Population
European Journal of Human Genetics (2013) 21, 1411–1416 & 2013 Macmillan Publishers Limited All rights reserved 1018-4813/13 www.nature.com/ejhg ARTICLE The genome-wide landscape of copy number variations in the MUSGEN study provides evidence for a founder effect in the isolated Finnish population Chakravarthi Kanduri1, Liisa Ukkola-Vuoti1, Jaana Oikkonen1, Gemma Buck2, Christine Blancher2, Pirre Raijas3, Kai Karma4, Harri La¨hdesma¨ki5 and Irma Ja¨rvela¨*,1 Here we characterized the genome-wide architecture of copy number variations (CNVs) in 286 healthy, unrelated Finnish individuals belonging to the MUSGEN study, where molecular background underlying musical aptitude and related traits are studied. By using Illumina HumanOmniExpress-12v.1.0 beadchip, we identified 5493 CNVs that were spread across 467 different cytogenetic regions, spanning a total size of 287.83 Mb (B9.6% of the human genome). Merging the overlapping CNVs across samples resulted in 999 discrete copy number variable regions (CNVRs), of which B6.9% were putatively novel. The average number of CNVs per person was 20, whereas the average size of CNV per locus was 52.39 kb. Large CNVs (41 Mb) were present in 4% of the samples. The proportion of homozygous deletions in this data set (B12.4%) seemed to be higher when compared with three other populations. Interestingly, several CNVRs were significantly enriched in this sample set, whereas several others were totally depleted. For example, a CNVR at chr2p22.1 intersecting GALM was more common in this population (P ¼ 3.3706 Â 10 À44) than in African and other European populations. The enriched CNVRs, however, showed no significant association with music-related phenotypes. -

AMY1A ELISA Kit (Human) (OKEH01050)
AMY1A ELISA Kit (Human) (OKEH01050) Instructions for Use For the quantitative measurement of AMY1A in biological fluids. This product is intended for research use only. v{Version} AMY1A ELISA Kit (Human) (OKEH01050) v1.0 Table of Contents 1. Background ................................................................................................................................. 3 2. Assay Summary .......................................................................................................................... 4 3. Storage and Stability ................................................................................................................... 4 4. Kit Components ........................................................................................................................... 4 5. Precautions.................................................................................................................................. 5 6. Required Materials Not Supplied ................................................................................................ 5 7. Technical Application Tips .......................................................................................................... 5 8. Reagent Preparation ................................................................................................................... 6 9. Sample Preparation Guidelines .................................................................................................. 7 10. Assay Procedure ........................................................................................................................ -

Innate and Adaptive Immunity Interact to Quench Microbiome Flagellar Motility in the Gut
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Cell Host & Microbe Article Innate and Adaptive Immunity Interact to Quench Microbiome Flagellar Motility in the Gut Tyler C. Cullender,1,2 Benoit Chassaing,3 Anders Janzon,1,2 Krithika Kumar,1,2 Catherine E. Muller,4 Jeffrey J. Werner,5,7 Largus T. Angenent,5 M. Elizabeth Bell,1,2 Anthony G. Hay,1 Daniel A. Peterson,6 Jens Walter,4 Matam Vijay-Kumar,3,8 Andrew T. Gewirtz,3 and Ruth E. Ley1,2,* 1Department of Microbiology, Cornell University, Ithaca, NY 14853, USA 2Department of Molecular Biology and Genetics, Cornell University, Ithaca, NY 14853, USA 3Center for Inflammation, Immunity and Infection, Georgia State University, Atlanta, GA 30303, USA 4Department of Food Science and Technology, University of Nebraska, Lincoln, NE 68583, USA 5Department of Biological and Environmental Engineering, Cornell University, Ithaca, NY 14853, USA 6Department of Pathology, Johns Hopkins University, Baltimore, MD 21287, USA 7Present address: Department of Chemistry, SUNY Cortland, Cortland, NY 13045, USA 8Present address: Department of Nutritional Sciences, The Pennsylvania State University, University Park, PA 16802, USA *Correspondence: [email protected] http://dx.doi.org/10.1016/j.chom.2013.10.009 SUMMARY IgA’s role in barrier defense is generally assumed to be immune exclusion, in which the IgA binds microbial surface antigens and Gut mucosal barrier breakdown and inflammation promotes the agglutination of microbial cells and their entrap- have been associated with high levels of flagellin, ment in mucus and physical clearance (Hooper and Macpher- the principal bacterial flagellar protein. -

The Human Gut Firmicute Roseburia Intestinalis Is a Primary Degrader of Dietary - Mannans
Downloaded from orbit.dtu.dk on: Oct 04, 2021 The human gut Firmicute Roseburia intestinalis is a primary degrader of dietary - mannans La Rosa, Sabina Leanti; Leth, Maria Louise; Michalak, Leszek; Hansen, Morten Ejby; Pudlo, Nicholas A.; Glowacki, Robert; Pereira, Gabriel; Workman, Christopher T.; Arntzen, Magnus; Pope, Phillip B. Total number of authors: 13 Published in: Nature Communications Link to article, DOI: 10.1038/s41467-019-08812-y Publication date: 2019 Document Version Publisher's PDF, also known as Version of record Link back to DTU Orbit Citation (APA): La Rosa, S. L., Leth, M. L., Michalak, L., Hansen, M. E., Pudlo, N. A., Glowacki, R., Pereira, G., Workman, C. T., Arntzen, M., Pope, P. B., Martens, E. C., Hachem, M. A., & Westereng, B. (2019). The human gut Firmicute Roseburia intestinalis is a primary degrader of dietary -mannans. Nature Communications, 10(1), [905]. https://doi.org/10.1038/s41467-019-08812-y General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. Users may download and print one copy of any publication from the public portal for the purpose of private study or research. You may not further distribute the material or use it for any profit-making activity or commercial gain You may freely distribute the URL identifying the publication in the public portal If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. -

(12) Patent Application Publication (10) Pub. No.: US 2001/0034023 A1 Stanton, JR
US 2001.0034O23A1. (19) United States (12) Patent Application Publication (10) Pub. No.: US 2001/0034023 A1 Stanton, JR. et al. (43) Pub. Date: Oct. 25, 2001 (54) GENE SEQUENCE VARIATIONS WITH Related U.S. Application Data UTILITY IN DETERMINING THE (63) Continuation-in-part of application No. 09/710,467, TREATMENT OF DISEASE, INGENES filed on Nov. 8, 2000, which is a continuation-in-part RELATING TO DRUG PROCESSING of application No. 09/696,482, filed on Oct. 24, 2000. Non-provisional of provisional application No. 60/131,334, filed on Apr. 26, 1999. Non-provisional (76) Inventors: Vincent P. Stanton JR., Belmont, MA of provisional application No. 60/139,440, filed on (US); Martin Zillmann, Shrewsbury, Jun. 15, 1999. MA (US) (30) Foreign Application Priority Data Correspondence Address: Jan. 20, 2000 (WO)........................... PCT/USOO/O1392 EDWARD O. KRUESSER BROBECK PHLEGER & HARRISON Publication Classification 12390 EL CAMINO REAL (51) Int. Cl. ............................. C12O 1/68; G06F 19/00 SAN DIEGO, CA 92130 (US) (52) U.S. Cl. ................................................... 435/6; 702/20 (57) ABSTRACT (21) Appl. No.: 09/733,000 Methods for identifying and utilizing variances in genes relating to efficacy and Safety of medical therapy and other aspects of medical therapy are described, including methods (22) Filed: Dec. 7, 2000 for Selecting an effective treatment. US 2001/0034023 A1 Oct. 25, 2001 GENE SEQUENCE WARIATIONS WITH UTILITY 0005 For some drugs, over 90% of the measurable IN DETERMINING THE TREATMENT OF interSubject variation in Selected pharmacokinetic param DISEASE, INGENES RELATING TO DRUG eters has been shown to be heritable. For a limited number PROCESSING of drugs, DNA sequence variances have been identified in Specific genes that are involved in drug action or metabo RELATED APPLICATIONS lism, and these variances have been shown to account for the 0001. -
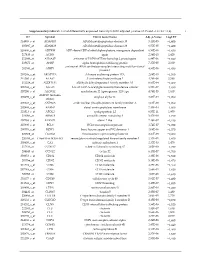
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at