Preliminary Proposal to Encode Book Pahlavi in Unicode
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

China's Place in Philology: an Attempt to Show That the Languages of Europe and Asia Have a Common Origin
CHARLES WILLIAM WASON COLLECTION CHINA AND THE CHINESE THE GIFT Of CHARLES WILLIAM WASON CLASS OF IB76 1918 Cornell University Library P 201.E23 China's place in phiiologyian attempt toI iPii 3 1924 023 345 758 CHmi'S PLACE m PHILOLOGY. Cornell University Library The original of this book is in the Cornell University Library. There are no known copyright restrictions in the United States on the use of the text. http://www.archive.org/details/cu31924023345758 PLACE IN PHILOLOGY; AN ATTEMPT' TO SHOW THAT THE LANGUAGES OP EUROPE AND ASIA HAVE A COMMON OKIGIIS". BY JOSEPH EDKINS, B.A., of the London Missionary Society, Peking; Honorary Member of the Asiatic Societies of London and Shanghai, and of the Ethnological Society of France, LONDON: TRtJBNEE & CO., 8 aito 60, PATEENOSTER ROV. 1871. All rights reserved. ft WftSffVv PlOl "aitd the whole eaeth was op one langtta&e, and of ONE SPEECH."—Genesis xi. 1. "god hath made of one blood axl nations of men foe to dwell on all the face of the eaeth, and hath detee- MINED the ITMTIS BEFOEE APPOINTED, AND THE BOUNDS OP THEIS HABITATION." ^Acts Xvil. 26. *AW* & ju€V AiQionas fiereKlaOe tij\(J6* i6j/ras, AiOioiras, rol Si^^a SeSafarat effxarot av8p&Vf Ol fiiv ivffofievov Tireplovos, oi S' avdv-rof. Horn. Od. A. 22. TO THE DIRECTORS OF THE LONDON MISSIONAEY SOCIETY, IN EECOGNITION OP THE AID THEY HAVE RENDERED TO EELIGION AND USEFUL LEAENINO, BY THE RESEARCHES OP THEIR MISSIONARIES INTO THE LANGUAOES, PHILOSOPHY, CUSTOMS, AND RELIGIOUS BELIEFS, OP VARIOUS HEATHEN NATIONS, ESPECIALLY IN AFRICA, POLYNESIA, INDIA, AND CHINA, t THIS WORK IS RESPECTFULLY DEDICATED. -

Contents Origins Transliteration
Ayin , ע Ayin (also ayn or ain; transliterated ⟨ʿ⟩) is the sixteenth letter of the Semitic abjads, including Phoenician ʿayin , Hebrew ʿayin ← Samekh Ayin Pe → [where it is sixteenth in abjadi order only).[1) ع Aramaic ʿē , Syriac ʿē , and Arabic ʿayn Phoenician Hebrew Aramaic Syriac Arabic The letter represents or is used to represent a voiced pharyngeal fricative (/ʕ/) or a similarly articulated consonant. In some Semitic ع ע languages and dialects, the phonetic value of the letter has changed, or the phoneme has been lost altogether (thus, in Modern Hebrew it is reduced to a glottal stop or is omitted entirely). Phonemic ʕ The Phoenician letter is the origin of the Greek, Latin and Cyrillic letterO . representation Position in 16 alphabet Contents Numerical 70 value Origins (no numeric value in Transliteration Maltese) Unicode Alphabetic derivatives of the Arabic ʿayn Pronunciation Phoenician Hebrew Ayin Greek Latin Cyrillic Phonetic representation Ο O О Significance Character encodings References External links Origins The letter name is derived from Proto-Semitic *ʿayn- "eye", and the Phoenician letter had the shape of a circle or oval, clearly representing an eye, perhaps ultimately (via Proto-Sinaitic) derived from the ır͗ hieroglyph (Gardiner D4).[2] The Phoenician letter gave rise to theGreek Ο, Latin O, and Cyrillic О, all representing vowels. The sound represented by ayin is common to much of theAfroasiatic language family, such as in the Egyptian language, the Cushitic languages and the Semitic languages. Transliteration Depending on typography, this could look similar .( ﻋَ َﺮب In Semitic philology, there is a long-standing tradition of rendering Semitic ayin with Greek rough breathing the mark ̔〉 (e.g. -

Confrontation in Karabakh: on the Origin of the Albanian Arsacids Dynasty
Voice of the Publisher, 2021, 7, 32-43 https://www.scirp.org/journal/vp ISSN Online: 2380-7598 ISSN Print: 2380-7571 To Whom Belongs the Land? Confrontation in Karabakh: On the Origin of the Albanian Arsacids Dynasty Ramin Alizadeh1*, Tahmina Aslanova2, Ilia Brondz3# 1Azerbaijan National Academy of Sciences (ANAS), Baku, Azerbaijan 2Department of History of Azerbaijan, History Faculty, Baku State University (BSU), Baku, Azerbaijan 3Norwegian Drug Control and Drug Discovery Institute (NDCDDI) AS, Ski, Norway How to cite this paper: Alizadeh, R., As- Abstract lanova, T., & Brondz, I. (2021). To Whom Belongs the Land? Confrontation in Kara- The escalation of the Karabakh conflict during late 2020 and the resumption bakh: On the Origin of the Albanian Arsa- of the second Karabakh War—as a result of the provocative actions by the cids Dynasty. Voice of the Publisher, 7, Armenian government and its puppet regime, the so-called “Artsakh Repub- 32-43. lic”—have aroused the renewed interest of the scientific community in the https://doi.org/10.4236/vp.2021.71003 historical origins of the territory over which Azerbaijan and Armenia have Received: December 6, 2020 been fighting for many years. There is no consensus among scientific experts Accepted: March 9, 2021 on this conflict’s causes or even its course, and the factual details and their Published: March 12, 2021 interpretation remain under discussion. However, there are six resolutions by Copyright © 2021 by author(s) and the United Nations Security Council that recognize the disputed territories as Scientific Research Publishing Inc. Azerbaijan’s national territory. This paper presents the historical, linguistic, This work is licensed under the Creative and juridical facts that support the claim of Azerbaijan to these territories. -

Ancient Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

An Etymological Study of Mythical Lakes in Iranian "Bundahišn"
Advances in Language and Literary Studies ISSN: 2203-4714 Vol. 6 No. 6; December 2015 Australian International Academic Centre, Australia Flourishing Creativity & Literacy An Etymological Study of Mythical Lakes in Iranian Bundahišn Hossein Najari (Corresponding author) Shiraz University, Eram Square, Shiraz, Iran E-mail: [email protected] Zahra Mahjoub Shiraz University, Shiraz, Iran E-mail: [email protected] Doi:10.7575/aiac.alls.v.6n.6p.174 Received: 30/07/2015 URL: http://dx.doi.org/10.7575/aiac.alls.v.6n.6p.174 Accepted: 02/10/2015 Abstract One of the myth-making phenomena is lake, which has often a counterpart in reality. Regarding the possible limits of mythological lakes of Iranian Bundahišn, sometimes their place can be found in natural geography. Iranian Bundahišn, as one of the great works of Middle Persian (Pahlavi) language, contains a large number of mythological geography names. This paper focuses on the mythical lakes of Iranian Bundahišn. Some of the mythical lakes are nominally comparable to the present lakes, but are geographically located in different places. Yet, in the present research attempt is made to match the mythical lakes of Iranian Bundahišn with natural lakes. Furthermore, they are studied in the light of etymological and mythological principles. The study indicates that mythical lakes are often both located in south and along the "Frāxkard Sea" and sometimes they correspond with the natural geography, according to the existing mythological points and current characteristics of the lakes. Keywords: mythological geography, Bundahišn, lake, Iranian studies, Middle Persian 1. Introduction Discovering the geographical location of mythical places in our present-day world is one of the most noteworthy matters for mythologists. -

Iso/Iec Jtc1/Sc2/Wg2 N3241 L2/07-102
ISO/IEC JTC1/SC2/WG2 N3241 L2/07-102 2007-04-12 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Parthian, Inscriptional Pahlavi, and Psalter Pahlavi scripts in the BMP of the UCS Source: Michael Everson Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2007-04-12 The three scripts proposed here were used to write a number of Indo-European languages, chiefly Parthian, and Middle Persian. They are descended from the Imperial Aramaic script used in Iran during the during the Achaemenid period (549–330 BCE), the Seleucid period (330–210 BCE) and the early Parthian period (210 BCE–224 CE). By the second century CE the Parthian script had evolved, and was used as the official script during the first part of the Sassanian period (224–651 CE). The main sources of Parthian are the inscriptions from Nisa (near present Ashgabat, Turkmenistan) and from Hecatompolis, as well as from texts in Manichean script, and a number of Sasanian multilingual inscriptions. In Pars in what is now southern Iran however the Aramaic script evolved differently, into the Inscriptional Pahlavi script, which was used regularly as a momumental script until the fifth century CE. The Psalter Pahlavi script was used in Chinese Turkestan and is so named because of its used in a fragmentary manuscript of the Psalms of David. This script itself developed (or decayed) into the ambiguous Book Pahlavi script which was replaced by the Avestan reformed script. -

Indo-Europeans in the Ancient Yellow River Valley
SINO-PLATONIC PAPERS Number 311 April, 2021 Indo-Europeans in the Ancient Yellow River Valley by Shaun C. R. Ramsden Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino-Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out for peer review, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. We do, however, strongly recommend that prospective authors consult our style guidelines at www.sino-platonic.org/stylesheet.doc. -

Heritage of Scribes
HERITAGE OF SCRIBES The Relation of Rovas Scripts to Eurasian Writing Systems Written by GÁBOR HOSSZÚ Budapest 2013 Title: Heritage of Scribes The Relation of Rovas Scripts to Eurasian Writing Systems Written by: Dr. habil. Gábor Hosszú, Candidate of Sciences of the Hungarian Academy of Sciences Reviewers: Modeling: Prof. Ferenc Kovács, Doctor of the Hungarian Academy of Sciences Hungarian Dr. Erzsébet Zelliger, Candidate of Sciences of the Hungarian linguistics: Academy of Sciences Linguistic advice: György András Jeney Translation: Dr. habil. Gábor Hosszú and László Sípos Carolyn Yohn, translation editor Editing and cover Tamás Rumi and László Sípos page design: Foreword: Dr. István Erdélyi, Doctor of the Hungarian Academy of Sciences Edition Third, Revised and Extended Edition Publishing: Rovas Foundation, Hungary Sponsored by: Rovas Foundation and Affiliates, Hungary Printed: Budapest, Hungary Copyright © 2011, 2012, 2013 by Dr. habil. Gábor Hosszú and Rovas Foundation. All rights reserved. ISBN 978 963 88 4374 6 ROVAS FOUNDATION – HUNGARY ROVÁS ALAPÍTVÁNY – MAGYARORSZÁG gASroraGa m – NAvtIpal a sAvo r 2 To My Mother 1927 – 2010 3 Contents Foreword 7 Acknowledgements 9 1. Introduction 11 2. Abbre viations, glossary and sources 14 3. The family of the Rovash scripts 18 3.1. General description 18 3.2. Early Rovash scripts 27 3.2.1. The Proto-Rovash 27 3.2.2. The Early Steppe Rovash 34 3.3. The Rovash paleographical modeling 42 3.3.1. The Glyph Complexity Parameter 42 3.3.2. The glyph transformation modeling 43 3.3.3. Determining the genealogies of the graphemes 44 3.4. The Carpathian Basin Rovash 46 3.4.1. -

Preliminary Proposal to Encode the Book Pahlavi Script in the Unicode Standard
UTC Document Register L2/13-141R Preliminary proposal to encode the Book Pahlavi script in the Unicode Standard Roozbeh Pournader, Google Inc. July 24, 2013 1. Background This is a proposal to encode the Book Pahlavi script in the Unicode Standard. Book Pahlavi was last proposed in the “Preliminary proposal to encode the Book Pahlavi script in the BMP of the UCS” (L2/07-234 = JTC1/SC2/WG2 N3294). Here is a short summary of the major differences in the character repertoire between that document and this proposal: • Characters only proposed here: an alternate form of d and a second alternate form of l (see section 7), one atomic symbol and two atomic ligatures (section 8), combining dot below (sections 3 and 6); • Characters proposed in L2/07-234 but not proposed here: ABBREVIATION TAA (representable as a character sequence, section 9), three archigraphemes (ambiguity, implementability, and multiple representation concerns, section 5), combining three dots below (no evidence of usage found), KASHIDA (unified with TATWEEL, sections 9 and 10), numbers (more information needed, section 10). 2. Introduction Book Pahlavi was the most important script used in writing the Middle Persian language.1 It probably started to be commonly used near the end of the Sassanian era (sixth century CE), evolving from the non-cursive Inscriptional Pahlavi. While the term “Book Pahlavi” refers to the script mostly surviving in books, Book Pahlavi has also been used in inscriptions, coins, pottery, and seals. Together with the alphabetic and phonetic Avestan script, the Book Pahlavi abjad is of religious importance to the Zoroastrian community, as most of their surviving religious texts have been written in one or both of the scripts. -

(RSEP) Request October 16, 2017 Registry Operator INFIBEAM INCORPORATION LIMITED 9Th Floor
Registry Services Evaluation Policy (RSEP) Request October 16, 2017 Registry Operator INFIBEAM INCORPORATION LIMITED 9th Floor, A-Wing Gopal Palace, NehruNagar Ahmedabad, Gujarat 380015 Request Details Case Number: 00874461 This service request should be used to submit a Registry Services Evaluation Policy (RSEP) request. An RSEP is required to add, modify or remove Registry Services for a TLD. More information about the process is available at https://www.icann.org/resources/pages/rsep-2014- 02-19-en Complete the information requested below. All answers marked with a red asterisk are required. Click the Save button to save your work and click the Submit button to submit to ICANN. PROPOSED SERVICE 1. Name of Proposed Service Removal of IDN Languages for .OOO 2. Technical description of Proposed Service. If additional information needs to be considered, attach one PDF file Infibeam Incorporation Limited (“infibeam”) the Registry Operator for the .OOO TLD, intends to change its Registry Service Provider for the .OOO TLD to CentralNic Limited. Accordingly, Infibeam seeks to remove the following IDN languages from Exhibit A of the .OOO New gTLD Registry Agreement: - Armenian script - Avestan script - Azerbaijani language - Balinese script - Bamum script - Batak script - Belarusian language - Bengali script - Bopomofo script - Brahmi script - Buginese script - Buhid script - Bulgarian language - Canadian Aboriginal script - Carian script - Cham script - Cherokee script - Coptic script - Croatian language - Cuneiform script - Devanagari script -
Grammar Chapter 1.Pdf
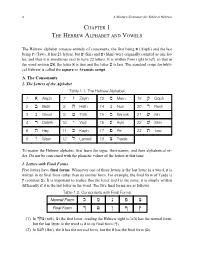
4 A Modern Grammar for Biblical Hebrew CHAPTER 1 THE HEBREW ALPHABET AND VOWELS Aleph) and the last) א The Hebrew alphabet consists entirely of consonants, the first being -Shin) were originally counted as one let) שׁ Sin) and) שׂ Taw). It has 23 letters, but) ת being ter, and thus it is sometimes said to have 22 letters. It is written from right to left, so that in -is last. The standard script for bibli שׁ is first and the letter א the letter ,אשׁ the word written cal Hebrew is called the square or Aramaic script. A. The Consonants 1. The Letters of the Alphabet Table 1.1. The Hebrew Alphabet Qoph ק Mem 19 מ Zayin 13 ז Aleph 7 א 1 Resh ר Nun 20 נ Heth 14 ח Beth 8 ב 2 Sin שׂ Samek 21 ס Teth 15 ט Gimel 9 ג 3 Shin שׁ Ayin 22 ע Yod 16 י Daleth 10 ד 4 Taw ת Pe 23 פ Kaph 17 כ Hey 11 ה 5 Tsade צ Lamed 18 ל Waw 12 ו 6 To master the Hebrew alphabet, first learn the signs, their names, and their alphabetical or- der. Do not be concerned with the phonetic values of the letters at this time. 2. Letters with Final Forms Five letters have final forms. Whenever one of these letters is the last letter in a word, it is written in its final form rather than its normal form. For example, the final form of Tsade is It is important to realize that the letter itself is the same; it is simply written .(צ contrast) ץ differently if it is the last letter in the word. -

Old Phrygian Inscriptions from Gordion: Toward A
OLD PHRYGIAN INSCRIPTIONSFROM GORDION: TOWARD A HISTORY OF THE PHRYGIAN ALPHABET1 (PLATES 67-74) JR HRYYSCarpenter's discussion in 1933 of the date of the Greektakeover of the Phoenician alphabet 2 stimulated a good deal of comment at the time, most of it attacking his late dating of the event.3 Some of the attacks were ill-founded and have been refuted.4 But with the passage of time Carpenter's modification of his original thesis, putting back the date of the takeover from the last quarter to the middle of the eighth century, has quietly gained wide acceptance.5 The excavations of Sir Leonard Woolley in 1936-37 at Al Mina by the mouth of the Orontes River have turned up evidence for a permanent Greek trading settle- ment of the eighth century before Christ, situated in a Semitic-speaking and a Semitic- writing land-a bilingual environment which Carpenter considered essential for the transmission of alphabetic writing from a Semitic- to a Greek-speakingpeople. Thus to Carpenter's date of ca. 750 B.C. there has been added a place which would seem to fulfill the conditions necessary for such a takeover, perhaps only one of a series of Greek settlements on the Levantine coast.6 The time, around 750 B.C., the required 1The fifty-one inscriptions presented here include eight which have appeared in Gordion preliminary reports. It is perhaps well (though repetitive) that all the Phrygian texts appear together in one place so that they may be conveniently available to those interested. A few brief Phrygian inscriptions which add little or nothing to the corpus are omitted here.