Pipeline for the Identification and Classification of Ion Channels in Parasitic Flatworms Bahiyah Nor1†, Neil D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Single-Particle Cryo-EM of the Ryanodine Receptor Channel in an Aqueous Environment
Single-particle cryo-EM of the ryanodine receptor channel Eur J Transl Myol - Basic Appl Myol 2015; 25 (1): 35-48 Single-particle cryo-EM of the ryanodine receptor channel in an aqueous environment Mariah R. Baker, Guizhen Fan and Irina I. Serysheva Department of Biochemistry and Molecular Biology, The University of Texas Medical School at Houston, 6431 Fannin Street, Houston, TX 77030, USA Abstract Ryanodine receptors (RyRs) are tetrameric ligand-gated Ca2+ release channels that are responsible for the increase of cytosolic Ca2+ concentration leading to muscle contraction. Our current understanding of RyR channel gating and regulation is greatly limited due to the lack of a high-resolution structure of the channel protein. The enormous size and unwieldy shape of Ca2+ release channels make X-ray or NMR methods difficult to apply for high-resolution structural analysis of the full-length functional channel. Single-particle electron cryo- microscopy (cryo-EM) is one of the only effective techniques for the study of such a large integral membrane protein and its molecular interactions. Despite recent developments in cryo- EM technologies and break-through single-particle cryo-EM studies of ion channels, cryospecimen preparation, particularly the presence of detergent in the buffer, remains the main impediment to obtaining atomic-resolution structures of ion channels and a multitude of other integral membrane protein complexes. In this review we will discuss properties of several detergents that have been successfully utilized in cryo-EM studies of ion channels and the emergence of the detergent alternative amphipol to stabilize ion channels for structure- function characterization. Future structural studies of challenging specimen like ion channels are likely to be facilitated by cryo-EM amenable detergents or alternative surfactants. -

Helminth Infection-Induced Carcinogenesis: Spectrometric Insights from The
bioRxiv preprint doi: https://doi.org/10.1101/606772; this version posted April 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 PLoS NTD 2 3 Helminth infection-induced carcinogenesis: spectrometric insights from the 4 liver flukes, Opisthorchis and Fasciola 5 6 Maria João Gouveia1,2,3, Maria Y. Pakharukova4,5, Banchob Sripa6, Gabriel Rinaldi7,♯, Paul J. 7 Brindley7, Viatcheslav A. Mordvinov4, Fátima Gärtner2,3,8, José M. C. da Costa1,9, Nuno 8 Vale2,3,8,10* 9 10 1 Center for the Study of Animal Science, CECA-ICETA, University of Porto, Praça Gomes Teixeira, 11 Apartado 55142, 4051-401 Porto, Portugal 12 2 i3S, Instituto de Investigação e Inovação em Saúde, University of Porto, Rua Alfredo Allen, 208, 4200- 13 135 Porto, Portugal 14 3 Department of Molecular Pathology and Immunology, Institute of Biomedical Sciences Abel Salazar 15 (ICBAS), University of Porto, Rua de Jorge Viterbo Ferreira 228, 4050-313 Porto, Portugal 16 4 Laboratory of Molecular Mechanisms of Pathological Processes, Institute of Cytology and Genetics, 17 Siberian Branch of the Russian Academy of Science, 10 Lavrentiev Avenue, 630090 Novosibirsk, Russia 18 5 Department of Natural Sciences, Novosibirsk State University, 2 Pirogov Street, 630090 Novosibirsk, 19 Russia 20 6 Department of Pathology, and Tropical Diseases Research Laboratory, Faculty of Medicine, Khon Kaen 21 University, Khon Kaen, 40002, Thailand 22 7 Department of Microbiology, Immunology & Tropical Medicine, and Research Center for Neglected 23 Diseases of Poverty, School of Medicine & Health Sciences, George Washington University, Washington, 24 D.C., 20037, USA 1 bioRxiv preprint doi: https://doi.org/10.1101/606772; this version posted April 11, 2019. -

Review and Meta-Analysis of the Environmental Biology and Potential Invasiveness of a Poorly-Studied Cyprinid, the Ide Leuciscus Idus
REVIEWS IN FISHERIES SCIENCE & AQUACULTURE https://doi.org/10.1080/23308249.2020.1822280 REVIEW Review and Meta-Analysis of the Environmental Biology and Potential Invasiveness of a Poorly-Studied Cyprinid, the Ide Leuciscus idus Mehis Rohtlaa,b, Lorenzo Vilizzic, Vladimır Kovacd, David Almeidae, Bernice Brewsterf, J. Robert Brittong, Łukasz Głowackic, Michael J. Godardh,i, Ruth Kirkf, Sarah Nienhuisj, Karin H. Olssonh,k, Jan Simonsenl, Michał E. Skora m, Saulius Stakenas_ n, Ali Serhan Tarkanc,o, Nildeniz Topo, Hugo Verreyckenp, Grzegorz ZieRbac, and Gordon H. Coppc,h,q aEstonian Marine Institute, University of Tartu, Tartu, Estonia; bInstitute of Marine Research, Austevoll Research Station, Storebø, Norway; cDepartment of Ecology and Vertebrate Zoology, Faculty of Biology and Environmental Protection, University of Lodz, Łod z, Poland; dDepartment of Ecology, Faculty of Natural Sciences, Comenius University, Bratislava, Slovakia; eDepartment of Basic Medical Sciences, USP-CEU University, Madrid, Spain; fMolecular Parasitology Laboratory, School of Life Sciences, Pharmacy and Chemistry, Kingston University, Kingston-upon-Thames, Surrey, UK; gDepartment of Life and Environmental Sciences, Bournemouth University, Dorset, UK; hCentre for Environment, Fisheries & Aquaculture Science, Lowestoft, Suffolk, UK; iAECOM, Kitchener, Ontario, Canada; jOntario Ministry of Natural Resources and Forestry, Peterborough, Ontario, Canada; kDepartment of Zoology, Tel Aviv University and Inter-University Institute for Marine Sciences in Eilat, Tel Aviv, -

Minding the Calcium Store: Ryanodine Receptor Activation As a Convergent Mechanism of PCB Toxicity
Pharmacology & Therapeutics 125 (2010) 260–285 Contents lists available at ScienceDirect Pharmacology & Therapeutics journal homepage: www.elsevier.com/locate/pharmthera Associate Editor: Carey Pope Minding the calcium store: Ryanodine receptor activation as a convergent mechanism of PCB toxicity Isaac N. Pessah ⁎, Gennady Cherednichenko, Pamela J. Lein Department of Molecular Biosciences, School of Veterinary Medicine, University of California, Davis, CA 95616, USA article info abstract Keywords: Chronic low-level polychlorinated biphenyl (PCB) exposures remain a significant public health concern since Ryanodine receptor (RyR) results from epidemiological studies indicate that PCB burden is associated with immune system Calcium-induced calcium release dysfunction, cardiovascular disease, and impairment of the developing nervous system. Of these various Calcium regulation adverse health effects, developmental neurotoxicity has emerged as a particularly vulnerable endpoint in Polychlorinated biphenyls PCB toxicity. Arguably the most pervasive biological effects of PCBs could be mediated by their ability to alter Triclosan fi 2+ Bastadins the spatial and temporal delity of Ca signals through one or more receptor-mediated processes. This Polybrominated diphenylethers review will focus on our current knowledge of the structure and function of ryanodine receptors (RyRs) in Developmental neurotoxicity muscle and nerve cells and how PCBs and related non-coplanar structures alter these functions. The Activity dependent plasticity molecular and cellular mechanisms by which non-coplanar PCBs and related structures alter local and global Ca2+ signaling properties and the possible short and long-term consequences of these perturbations on neurodevelopment and neurodegeneration are reviewed. © 2009 Elsevier Inc. All rights reserved. Contents 1. Introduction ............................................... 260 2. Ryanodine receptor macromolecular complexes: significance to polychlorinated biphenyl-mediated Ca2+ dysregulation . -

Comparative Genomic Analysis of Integral Membrane Transport Proteins in Ciliates
UC San Diego UC San Diego Previously Published Works Title Comparative genomic analysis of integral membrane transport proteins in ciliates. Permalink https://escholarship.org/uc/item/3g98s19z Journal The Journal of eukaryotic microbiology, 62(2) ISSN 1066-5234 Authors Kumar, Ujjwal Saier, Milton H Publication Date 2015-03-01 DOI 10.1111/jeu.12156 Peer reviewed eScholarship.org Powered by the California Digital Library University of California The Journal of Published by the International Society of Eukaryotic Microbiology Protistologists Journal of Eukaryotic Microbiology ISSN 1066-5234 ORIGINAL ARTICLE Comparative Genomic Analysis of Integral Membrane Transport Proteins in Ciliates Ujjwal Kumar & Milton H. Saier Jr Division of Biological Sciences, University of California at San Diego, La Jolla, California Keywords ABSTRACT Channels; evolution; genome analyses; secondary carriers. Integral membrane transport proteins homologous to those found in the Transporter Classification Database (TCDB; www.tcdb.org) were identified and Correspondence bioinformatically characterized by transporter class, family, and substrate speci- M. H. Saier Jr, Division of Biological ficity in three ciliates, Paramecium tetraurelia (Para), Tetrahymena thermophila Sciences, University of California at San (Tetra), and Ichthyophthirius multifiliis (Ich). In these three organisms, 1,326 of Diego, La Jolla, CA 92093-0116, USA 39,600 proteins (3.4%), 1,017 of 24,800 proteins (4.2%), and 504 out of 8,100 Telephone number: +858-534-4084; proteins (6.2%) integral membrane transport proteins were identified, respec- FAX number: +858-534-7108; tively. Thus, an inverse relationship was observed between the % transporters e-mail: [email protected] identified and the number of total proteins per genome reported. -

The Trematode Parasites of Marine Mammals
THE TREMATODE PARASITES OF MARINE MAMMALS By Emmett W. Pkice Parasitologist, Zoological Division, Bureau of Animal Industry United States Department of Agriculture The internal parasites of marine mammals have not been exten- sively studied, although a fairly large number of species have been described. In attempting to identify the trematodes from mammals of the orders Cetacea, Pinnipedia, and Sirenia, as represented by specimens in the United States National Museum helminthological collection, it was necessary to review the greater part of the litera- ture dealing with this group of parasitic worms. In view of the fact that there is not in existence a single comprehensive paper on the trematodes of these mammals, and that many of the descrip- tions of species have appeared in publications having more or less limited circulation, the writer has undertaken to assemble descriptions of all trematodes reported from these hosts, with the hope that such a paper may serve a useful purpose in aiding other workers in de- termining specimens at their disposal. In addition to compiling the descriptions of species not available to the writer, two new species, one of which represents a new genus, have been described. Specimens representing 10 of the previously described species have been studied and emendations or additions have been made to the existing descriptions; in a few instances the species have been completely reclescribed. Three species, Distoinwni pallassil Poirier, D. vaUdwim von Lin- stow, and D. am/pidlacewni Buttel-Reepen, have been omitted from this paper despite the fact that they have been reported from ceta- ceans. These species belong in the family Hemiuridae, and since all species of this family are parasites of fishes, the writer feels that their reported occurrence in mammals may be regarded as either errors of some sort or cases of accidental parasitism in which fishes have been eaten by mammals and the fish parasites found in the mammal post-mortem. -
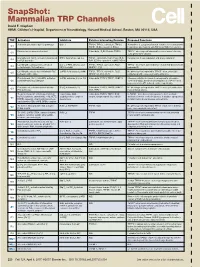
Snapshot: Mammalian TRP Channels David E
SnapShot: Mammalian TRP Channels David E. Clapham HHMI, Children’s Hospital, Department of Neurobiology, Harvard Medical School, Boston, MA 02115, USA TRP Activators Inhibitors Putative Interacting Proteins Proposed Functions Activation potentiated by PLC pathways Gd, La TRPC4, TRPC5, calmodulin, TRPC3, Homodimer is a purported stretch-sensitive ion channel; form C1 TRPP1, IP3Rs, caveolin-1, PMCA heteromeric ion channels with TRPC4 or TRPC5 in neurons -/- Pheromone receptor mechanism? Calmodulin, IP3R3, Enkurin, TRPC6 TRPC2 mice respond abnormally to urine-based olfactory C2 cues; pheromone sensing 2+ Diacylglycerol, [Ca ]I, activation potentiated BTP2, flufenamate, Gd, La TRPC1, calmodulin, PLCβ, PLCγ, IP3R, Potential role in vasoregulation and airway regulation C3 by PLC pathways RyR, SERCA, caveolin-1, αSNAP, NCX1 La (100 µM), calmidazolium, activation [Ca2+] , 2-APB, niflumic acid, TRPC1, TRPC5, calmodulin, PLCβ, TRPC4-/- mice have abnormalities in endothelial-based vessel C4 i potentiated by PLC pathways DIDS, La (mM) NHERF1, IP3R permeability La (100 µM), activation potentiated by PLC 2-APB, flufenamate, La (mM) TRPC1, TRPC4, calmodulin, PLCβ, No phenotype yet reported in TRPC5-/- mice; potentially C5 pathways, nitric oxide NHERF1/2, ZO-1, IP3R regulates growth cones and neurite extension 2+ Diacylglycerol, [Ca ]I, 20-HETE, activation 2-APB, amiloride, Cd, La, Gd Calmodulin, TRPC3, TRPC7, FKBP12 Missense mutation in human focal segmental glomerulo- C6 potentiated by PLC pathways sclerosis (FSGS); abnormal vasoregulation in TRPC6-/- -

Ca Signaling in Cardiac Fibroblasts and Fibrosis-Associated Heart
Journal of Cardiovascular Development and Disease Review Ca2+ Signaling in Cardiac Fibroblasts and Fibrosis-Associated Heart Diseases Jianlin Feng 1, Maria K. Armillei 1, Albert S. Yu 1, Bruce T. Liang 1, Loren W. Runnels 2,* and Lixia Yue 1,* 1 Calhoun Cardiology Center, Department of Cell Biology, University of Connecticut Health Center, Farmington, CT 06030, USA; [email protected] (J.F.); [email protected] (M.K.A.); [email protected] (A.S.Y.); [email protected] (B.T.L.) 2 Department of Pharmacology, Rutgers, Robert Wood Johnson Medical School, Piscataway, NJ 08854, USA * Correspondence: [email protected] (L.W.R.); [email protected] (L.Y.) Received: 11 August 2019; Accepted: 18 September 2019; Published: 23 September 2019 Abstract: Cardiac fibrosis is the excessive deposition of extracellular matrix proteins by cardiac fibroblasts and myofibroblasts, and is a hallmark feature of most heart diseases, including arrhythmia, hypertrophy, and heart failure. This maladaptive process occurs in response to a variety of stimuli, including myocardial injury, inflammation, and mechanical overload. There are multiple signaling pathways and various cell types that influence the fibrogenesis cascade. Fibroblasts and myofibroblasts are central effectors. Although it is clear that Ca2+ signaling plays a vital role in this pathological process, what contributes to Ca2+ signaling in fibroblasts and myofibroblasts is still not wholly understood, chiefly because of the large and diverse number of receptors, transporters, and ion channels that influence intracellular Ca2+ signaling. Intracellular Ca2+ signals are generated by Ca2+ release from intracellular Ca2+ stores and by Ca2+ entry through a multitude of Ca2+-permeable ion channels in the plasma membrane. -

Endemicity of Opisthorchis Viverrini Liver Flukes, Vietnam, 2011–2012
LETTERS Endemicity of for species identification of Opisthor- A total of 4 fish species were in- chis fluke metacercariae 7( ). fected with O. viverrini metacercariae Opisthorchis Fish were collected from Tuy (online Technical Appendix Table 1, viverrini Liver Hoa City and from the districts of Hoa wwwnc.cdc.gov/EID/article/20/1/13- Flukes, Vietnam, Xuan Dong, Tuy An, and Song Hinh; 0168-Techapp1.pdf). Metacercariae these 3 districts are areas of large prevalence was highest (28.1%) 2011–2012 aquaculture production of freshwater among crucian carp (Carasius aura- To the Editor: Fishborne zoo- fish. Fresh fish from ponds, rice fields, tus). Specific identification was con- notic trematodes are highly prevalent rivers, and swamps were purchased at firmed by morphologic appearance of in many Asian communities (1,2). Al- local markets from April 2011 through adult worms recovered from hamsters though presence of the liver flukeClo - March 2012. The fish sellers provided (Figure) and PCR and sequence anal- norchis sinensis is well documented information about the source of the ysis of the partial metacercarial CO1 in Vietnam (3), evidence of the pres- fish (e.g., type of water body). Fish gene, amplified by CO1-OV-Hap- ence of the more common liver fluke were transported live with mechani- F&R primers (7). Infected fish origi- of Southeast Asia, Opisthorchis viver- cal aeration to the Research Institute nated predominantly from so-called rini, is only circumstantial. Surveys of for Aquaculture No. 3 in Nha Trang, wild water (i.e., swamps, rice fields, human fecal samples have frequently where they were examined for meta- rivers). -

Updated Molecular Phylogenetic Data for Opisthorchis Spp
Dao et al. Parasites & Vectors (2017) 10:575 DOI 10.1186/s13071-017-2514-9 RESEARCH Open Access Updated molecular phylogenetic data for Opisthorchis spp. (Trematoda: Opisthorchioidea) from ducks in Vietnam Thanh Thi Ha Dao1,2,3, Thanh Thi Giang Nguyen1,2, Sarah Gabriël4, Khanh Linh Bui5, Pierre Dorny2,3* and Thanh Hoa Le6 Abstract Background: An opisthorchiid liver fluke was recently reported from ducks (Anas platyrhynchos) in Binh Dinh Province of Central Vietnam, and referred to as “Opisthorchis viverrini-like”. This species uses common cyprinoid fishes as second intermediate hosts as does Opisthorchis viverrini, with which it is sympatric in this province. In this study, we refer to the liver fluke from ducks as “Opisthorchis sp. BD2013”, and provide new sequence data from the mitochondrial (mt) genome and the nuclear ribosomal transcription unit. A phylogenetic analysis was conducted to clarify the basal taxonomic position of this species from ducks within the genus Opisthorchis (Digenea: Opisthorchiidae). Methods: Adults and eggs of liver flukes were collected from ducks, metacercariae from fishes (Puntius brevis, Rasbora aurotaenia, Esomus metallicus) and cercariae from snails (Bithynia funiculata) in different localities in Binh Dinh Province. From four developmental life stage samples (adults, eggs, metacercariae and cercariae), the complete cytochrome b (cob), nicotinamide dehydrogenase subunit 1 (nad1) and cytochrome c oxidase subunit 1 (cox1) genes, and near-complete 18S and partial 28S ribosomal DNA (rDNA) sequences were obtained by PCR-coupled sequencing. The alignments of nucleotide sequences of concatenated cob + nad1+cox1, and of concatenated 18S + 28S were separately subjected to phylogenetic analyses. Homologous sequences from other trematode species were included in each alignment. -

Studies on the Trematode Parasites of Ducks In
STUDIES ON THE TREMATODE PARASITES OF DUCKS IN MICHIGAN WITH SPECIAL REFERENCE TO THE MALLARD BY W. CARL GOWER A THESIS Presented to the Graduate School of Michigan State College of Agriculture and Applied Science in Partial Fulfillment of Requirements for the Degree of Doctor of Philosophy Department of Bacteriology, Hygiene, and Parasitology and Department of Zoology East Lansing, Michigan 1937 ProQuest Number: 10008314 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest. ProQuest 10008314 Published by ProQuest LLC (2016). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 •Foreword and Acknowledgments This study was at first intended to be an intensive study of the species of Prosthogonimu3 occurring in south ern Michigan. Soon after beginning, however, it became apparent that, perhaps, a more important contribution might be made at this time through a survey of the trematodes found in ducks in Michigan. The obvious need for, and the excellent opportunity afforded at the W. K. Kellogg Bird Sanctuary for such a study, were instrumental in the change. Too, although Prosthogonimus is highly pathogenic in chickens, certain other trematodes seemed to be of more importance in ducks. -

Environmental Conservation Online System
U.S. Fish and Wildlife Service Southeast Region Inventory and Monitoring Branch FY2015 NRPC Final Report Documenting freshwater snail and trematode parasite diversity in the Wheeler Refuge Complex: baseline inventories and implications for animal health. Lori Tolley-Jordan Prepared by: Lori Tolley-Jordan Project ID: Grant Agreement Award# F15AP00921 1 Report Date: April, 2017 U.S. Fish and Wildlife Service Southeast Region Inventory and Monitoring Branch FY2015 NRPC Final Report Title: Documenting freshwater snail and trematode parasite diversity in the Wheeler Refuge Complex: baseline inventories and implications for animal health. Principal Investigator: Lori Tolley-Jordan, Jacksonville State University, Jacksonville, AL. ______________________________________________________________________________ ABSTRACT The Wheeler National Wildlife Refuge (NWR) Complex includes: Wheeler, Sauta Cave, Fern Cave, Mountain Longleaf, Cahaba, and Watercress Darter Refuges that provide freshwater habitat for many rare, endangered, endemic, or migratory species of animals. To date, no systematic, baseline surveys of freshwater snails have been conducted in these refuges. Documenting the diversity of freshwater snails in this complex is important as many snails are the primary intermediate hosts of flatworm parasites (Trematoda: Digenea), whose infection in subsequent aquatic and terrestrial vertebrates may lead to their impaired health. In Fall 2015 and Summer 2016, snails were collected from a variety of aquatic habitats at all Refuges, except at Mountain Longleaf and Cahaba Refuges. All collected snails were transported live to the lab where they were identified to species and dissected to determine parasite presence. Trematode parasites infecting snails in the refuges were identified to the lowest taxonomic level by sequencing the DNA barcoding gene, 18s rDNA. Gene sequences from Refuge parasites were matched with published sequences of identified trematodes accessioned in the NCBI GenBank database.