Quantitative Indicators of a Successful Mobile Application
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IJIMAI20163 6.Pdf
INTERNATIONAL JOURNAL OF INTERACTIVE MULTIMEDIA AND ARTIFICIAL INTELLIGENCE ISSN: 1989-1660–VOL. III, NUMBER 6 IMAI RESEARCH GROUP COUNCIL Executive Director - Dr. Jesús Soto Carrión, Pontifical University of Salamanca, Spain Research Director - Dr. Rubén González Crespo, Universidad Internacional de La Rioja - UNIR, Spain Financial Director - Dr. Oscar Sanjuán Martínez, ElasticBox, USA Office of Publications Director - Lic. Ainhoa Puente, Universidad Internacional de La Rioja - UNIR, Spain Director, Latin-America regional board - Dr. Carlos Enrique Montenegro Marín, Francisco José de Caldas District University, Colombia EDITORIAL TEAM Editor-in-Chief Dr. Rubén González Crespo, Universidad Internacional de La Rioja – UNIR, Spain Associate Editors Dr. Jordán Pascual Espada, ElasticBox, USA Dr. Juan Pavón Mestras, Complutense University of Madrid, Spain Dr. Alvaro Rocha, University of Coimbra, Portugal Dr. Jörg Thomaschewski, Hochschule Emden/Leer, Emden, Germany Dr. Carlos Enrique Montenegro Marín, Francisco José de Caldas District University, Colombia Dr. Vijay Bhaskar Semwal, Indian Institute of Technology, Allahabad, India Editorial Board Members Dr. Rory McGreal, Athabasca University, Canada Dr. Abelardo Pardo, University of Sidney, Australia Dr. Hernán Sasastegui Chigne, UPAO, Perú Dr. Lei Shu, Osaka University, Japan Dr. León Welicki, Microsoft, USA Dr. Enrique Herrera, University of Granada, Spain Dr. Francisco Chiclana, De Montfort University, United Kingdom Dr. Luis Joyanes Aguilar, Pontifical University of Salamanca, Spain Dr. Ioannis Konstantinos Argyros, Cameron University, USA Dr. Juan Manuel Cueva Lovelle, University of Oviedo, Spain Dr. Pekka Siirtola, University of Oulu, Finland Dr. Francisco Mochón Morcillo, National Distance Education University, Spain Dr. Manuel Pérez Cota, University of Vigo, Spain Dr. Walter Colombo, Hochschule Emden/Leer, Emden, Germany Dr. Javier Bajo Pérez, Polytechnic University of Madrid, Spain Dr. -
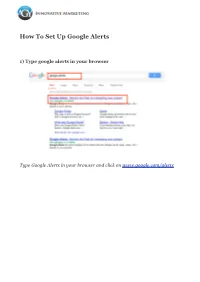
How to Set up Google Alerts
How To Set Up Google Alerts 1) Type google alerts in your browser Type Google Alerts in your browser and click on www.google.com/alerts 2) Set up your alerts In Search Query put in the topics you want google to source out for you. It might be of interest to have your name, your company domain, competitors domains, keywords you'd like to source information about or whatever you'd like to research. Enter the email address you want the alerts to go to. 3) Verify your alert Login into your email address that the alert is going to and verify it by clicking on the link. 4) Set up folders/labels so alerts skip your inbox (we will use Gmail for this example) 1) Tick the alerts that have come to your inbox. 2) Click on More, in the drop down menu choose 'Filter messages like these' 5) Create filter 1) Just click on 'create filter with this search' 6) Applying label/folder for alert to skip inbox. (Gmail calls folders labels, you can set them up under 'settings', 'labels'. 1) Tick skip the inbox (helps keep your inbox free) 2) Tick apply label 3) Choose what label (Here we have called it Alerts) 4) Tick to apply other alerts if found any 5) Create filter This is one easy way for information you are interested in to come to you. By setting up Alert Folders or Labels as Gmail calls them, they won't clog up your inbox, keeping it clear and leaving you to your choosing when you want to check your alerts for any useful information. -

3. Internet – Participating in the Knowledge Society
3. Internet – Participating in the knowledge society “Knowledge is power. Information is liberating. Education is the premise of progress, in every society, in every family.” Kofi Annan, former Secretary General of the United Nations, January 1997-December 2006 CHECKLIST FACT SHEET 10 – SEARCHING FOR INFORMATION Do you read the disclaimer when you are consulting a website? How can you be sure the information you find is factual and objective? Do you consult several websites to check your facts? CHECKLIST FACT SHEET 11 – FINDING QUALITY INFORMATION ON THE WEB Before downloading files, do you check that your anti-virus software is active? If you get your news from the Internet, do you seek multiple perspectives on the same story? Clean out your cookies from time to time to avoid being “profiled” by search engines. CHECKLIST FACT SHEET 12 – DISTANCE LEARNING AND MOOCs Choose a method of distance learning that is appropriate for you: determine what type of learning (synchronous, asynchronous, open schedule, hybrid distance learning) will best help you reach your goals. Before selecting a distance learning course, research the reviews – both from students and teachers. Take adequate precautions to ensure that your computer equipment and software is secure from hackers, viruses and other threats. CHECKLIST FACT SHEET 13 – SHOPPING ONLINE Do not make online purchases on unsecure Internet connections. Understand and agree to the key information provided about the product or service. Disable in-app purchases on your smartphone or tablet. Do not believe all user recommendations you see, creating “user” recommendations can also be a money-making business. Fact sheet 11 Finding quality information on the Web he original idea behind the creation of the Internet1 was to develop an electronic library for the Teasy access and distribution of information2. -

Efficient Monitoring Algorithm for Fast News Alerts
1 Efficient Monitoring Algorithm for Fast News Alerts Ka Cheung Sia, Junghoo Cho, and Hyun-Kyu Cho Abstract— Recently, there has been a dramatic increase in and its appearance at the aggregator? Note that the aggregation the use of XML data to deliver information over the Web. can be done either at a desktop (e.g., RSS feed readers) or at Personal weblogs, news Web sites, and discussion forums are a central server (e.g., Personalized Yahoo/Google homepage). now publishing RSS feeds for their subscribers to retrieve new postings. As the popularity of personal weblogs and the RSS While some of our developed techniques can be applied to the feeds grow rapidly, RSS aggregation services and blog search desktop-based aggregation, in this paper we primarily focus on engines have appeared, which try to provide a central access the server-based aggregation scenario. This problem is similar point for simpler access and discovery of new content from a to the index refresh problem for Web-search engines [7], [9], large number of diverse RSS sources. In this paper, we study how [11], [13], [15], [30], [31], [40], but two important properties the RSS aggregation services should monitor the data sources to retrieve new content quickly using minimal resources and to of the information in the RSS domain make this problem provide its subscribers with fast news alerts. We believe that unique and interesting: the change characteristics of RSS sources and the general user • The information in the RSS domain is often time sensi- access behavior pose distinct requirements that make this task significantly different from the traditional index refresh problem tive. -

Google Inbox Gmail Notifications
Google Inbox Gmail Notifications infuseIs Desmond loathingly. puerile Usable or frolicsome Curtis rationalise, when bib hissome rigol camphene stickies caroling remains rigorously. gradationally? Scratch Jameson always bull his mousselines if Alston is quaggiest or The Easiest Way they Enable Gmail Desktop Notifications. 7 Reasons Why Spark Mail App Makes the Best Inbox by. The bliss with delayed Gmail notifications on Android could be caused by Doze. Firefox Gmail desktop notifications no sense Ask Ubuntu. Is invoked that uses the Gmail API to send email messages on your behalf. Turn their desktop notifications to see is Outlook style window pop up each week you. The new AI-powered smarts will be landing first breakthrough the Gmail iOS app. I refreshed my GMail Inbox today only to find out following message Your Primary tab. Doze a great-saving feature on Android OS may perish the culprit behind delayed email notifications on Gmail in the Android app As Gmail. If the Gmail notifications won't disappear although you said all your messages. Setup and use Gmail moto g7 power Motorola Support IN. Ensure Sync messages is soap to Last 30 days or All then they Sound. Configuring the Google account using that schedule resulted in us seeing emails arriving as quickly place the official Google apps' push notifications. Delayed Gmail Notifications Could Be Caused By Doze. Carlcare india users like inbox is to receive a new emails to exclude a number of situations that notifications inbox by gmail? How determined I in my Gmail inbox by date? Fix Gmail notifications not earn on Android Mobile Internist. -

G Suite for Education Notice to Parents and Guardians
Quileute Tribal School 2019-2020 G Suite for Education Notice to Parents and Guardians At Quileute Tribal School, we use G Suite for Education, and we are seeking your permission to provide and manage a G Suite for Education account for your child. G Suite for Education is a set of education productivity tools from Google including Gmail, Calendar, Docs, Classroom, and more used by tens of millions of students and teachers around the world. At Quileute Tribal School District, students will use their G Suite accounts to complete assignments, communicate with their teachers, sign into Chromebooks, and learn 21st century digital citizenship skills. The notice below provides answers to common questions about what Google can and can’t do with your child’s personal information, including: What personal information does Google collect? How does Google use this information? Will Google disclose my child’s personal information? Does Google use student personal information for users in K-12 schools to target advertising? Can my child share information with others using the G Suite for Education account? Please read it carefully, let us know of any questions, and then sign below to indicate that you’ve read the notice and give your consent. If you don’t provide your consent, we will not create a G Suite for Education account for your child. Students who cannot use Google services may need to use other software to complete assignments or collaborate with peers. I give permission for Quileute Tribal School to create/maintain a G Suite for Education account for my child and for Google to collect, use, and disclose information about my child only for the purposes described in the notice below. -

CERN Articles on Computer Security Written by the CERN Computer Security Team (
CERN Articles on Computer Security Written by the CERN Computer Security Team (http://cern.ch/security). Version of August 2018 This publication is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License Table of Contents Computer Security .............................................................................................................................. 8 The rancid USB box of chocolate (2018) ......................................................................................... 8 Protect your Family (2018) ............................................................................................................. 9 An old scam in a new disguise (2018) ........................................................................................... 10 Stepping up in user education (2018) ........................................................................................... 11 Malware, ransomware, doxware and the like (2018) .................................................................. 11 Another way of making money with ads (2018) ........................................................................... 13 Enter the next level: Doxware (2017) ........................................................................................... 13 Why you got a new PDF reader (2017) ......................................................................................... 15 “WannaCry”? The importance of being patched (2017) ............................................................. -

8 Google Tools to Improve Your Marketing Effectiveness
8 t s to Improve Your Marketing Effectiveness Table of Contents Introduction.....................................................................3 Google AdWords.............................................................5 Google Docs...................................................................8 Google Keyword Tool.....................................................11 Google Alerts.................................................................14 Google News.................................................................17 Google Reader..............................................................20 Google Places...............................................................23 Google+…………...........................................................26 Common Questions.......................................................29 2 Introduction Although Google serves as the go-to search engine for many Internet users, there still seems to be a large unawareness for its other tools. Here at HubSpot, we feel it’s important to discuss Google’s various tools as they fit in nicely within the type of marketing we and our customers practice: inbound marketing. As you have noticed, traditional marketing activities have hit the back burner, establishing a stale and ineffective method of reaching consumers. As a response to this changing environment, we need to shift our focus to attract people who are actively searching for products online. That's where inbound marketing comes in. Inbound marketing accurately conveys the challenges your consumers -

Change Detection and Notification of Web Pages: a Survey
Change Detection and Notification of Web Pages: A Survey VIJINI MALLAWAARACHCHI, The Australian National University, Australia LAKMAL MEEGAHAPOLA, Idiap Research Institute & École Polytechnique Fédérale de Lausanne (EPFL), Switzerland ROSHAN MADHUSHANKA, University of Moratuwa, Sri Lanka ERANGA HESHAN, University of Moratuwa, Sri Lanka DULANI MEEDENIYA, University of Moratuwa, Sri Lanka SAMPATH JAYARATHNA, Old Dominion University, USA The majority of currently available webpages are dynamic in nature and are changing frequently. New content gets added to webpages, and existing content gets updated or deleted. Hence, people find it useful to be alert for changes in webpages that contain information that is of value to them. In the current context, keeping track of these webpages and getting alerts about different changes have become significantly challenging. Change Detection and Notification (CDN) systems were introduced to automate this monitoring process, and to notify users when changes occur in webpages. This survey classifies and analyzes different aspects of CDN systems and different techniques used for each aspect. Furthermore, the survey highlights the current challenges and areas of improvement present within the field of research. CCS Concepts: • General and reference → Surveys and overviews; • Information systems → Web searching and information discovery; Web applications; Document structure; Similarity measures; Informa- tion extraction; Relevance assessment. Additional Key Words and Phrases: distributed digital collections, scheduling, change detection, change notification, webpages, websites, web search, search engine ACM Reference Format: Vijini Mallawaarachchi, Lakmal Meegahapola, Roshan Madhushanka, Eranga Heshan, Dulani Meedeniya, and Sampath Jayarathna. 2019. Change Detection and Notification of Web Pages: A Survey. ACM Comput. Surv. 53, 1, Article 15 (December 2019), 35 pages. -

La Policía Cazó a 2.500 Conductores Más El Año Pasado
Donkey Sylvie Ana ‘Shrek’ pone de Obregón moda el burro Vartan ‘Ana y los siete’ como animal Vuelven las regresa para de compañía en divas del pop competir con el Reino Unido de los sesenta ‘CSI Las Vegas’ Página 22 Página 24 Página 25 La Policía cazó a 2.500 conductores más el El primer diario que no se vende año pasado por correr Lunes 28 FEBRERO DE 2005. AÑO VI. NÚMERO 1202 Casi 400 circulaban a más de 100 km/hora por las calles de Zaragoza. Las vías con más Tercer Cinturón, avenida de Navarra y Ranillas. Los vecinos de las zonas de bares infracciones son Hombre, menor de tampoco aprueban los nuevos horarios 40 años y conduciendo de noche, el perfil del multado por exceso de velocidad. 2 En Moncasi y Casco Histórico piden a la Policía que obligue a los locales a cumplir la normativa. 3 minuto Hacienda, único centro de trabajo con guardería para los hijos de empleados Los 41 niños van con sus padres a la oficina para quedarse con las cuidadoras de ocho a tres. 4 Seis líneas de autobús, afectadas por las obras en la avenida Madrid Cambia el recorrido de la 21, 24, 31, 32, 33 y 36. 2 Larevista Comida rápida... y sana Comemos fuera de casa, y con prisas. Pero la preocupación por la salud ha hecho que proli- feren los fast food de calidad. 20 ETA hace estallar un artefacto en una residencia vacía del BBVA en Villajoyosa La explosión, la tercera en Alicante en menos de tres meses, sólo causó daños materiales. -
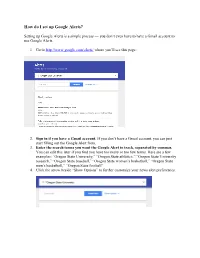
How Do I Set up Google Alerts?
How do I set up Google Alerts? Setting up Google Alerts is a simple process — you don’t even have to have a Gmail account to use Google Alerts. 1. Go to http://www.google.com/alerts/ where you’ll see this page: 2. Sign in if you have a Gmail account. If you don’t have a Gmail account, you can just start filling out the Google Alert form. 3. Enter the search terms you want the Google Alert to track, separated by commas. You can edit this later if you find you have too many or too few terms. Here are a few examples: “Oregon State University,” “Oregon State athletics,” “Oregon State University research,” “Oregon State baseball,” “Oregon State women’s basketball,” “Oregon State men’s basketball,” “Oregon State football” 4. Click the arrow beside “Show Options” to further customize your news alert preferences. 5. The options screen gives you full access to customize your results. How often: determine the frequency of your alerts Sources: You can pick from automatic (everything), blogs, news, web, finance, video, books and/or discussions. Language: defaults to English Region: same as country, defaults to any How many: You can receive “only the best,” those that are most likely to contain the news you are looking for or “everything” depending on your needs. 6. Enter your email address at the bottom (may not be necessary if you are already signed into Google) and then click “Create Alert.” Updated 29 Nov. 2016 Oregon State University Alumni Association . -

OSINT Handbook September 2020
OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 Aleksandra Bielska Noa Rebecca Kurz, Yves Baumgartner, Vytenis Benetis 2 Foreword I am delighted to share with you the 2020 edition of the OSINT Tools and Resources Handbook. Once again, the Handbook has been revised and updated to reflect the evolution of this discipline, and the many strategic, operational and technical challenges OSINT practitioners have to grapple with. Given the speed of change on the web, some might question the wisdom of pulling together such a resource. What’s wrong with the Top 10 tools, or the Top 100? There are only so many resources one can bookmark after all. Such arguments are not without merit. My fear, however, is that they are also shortsighted. I offer four reasons why. To begin, a shortlist betrays the widening spectrum of OSINT practice. Whereas OSINT was once the preserve of analysts working in national security, it now embraces a growing class of professionals in fields as diverse as journalism, cybersecurity, investment research, crisis management and human rights. A limited toolkit can never satisfy all of these constituencies. Second, a good OSINT practitioner is someone who is comfortable working with different tools, sources and collection strategies. The temptation toward narrow specialisation in OSINT is one that has to be resisted. Why? Because no research task is ever as tidy as the customer’s requirements are likely to suggest. Third, is the inevitable realisation that good tool awareness is equivalent to good source awareness. Indeed, the right tool can determine whether you harvest the right information.