An Overview of On- Premise File and Object Storage Access Protocols
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nasuni Cloud File Services™ the Modern, Cloud-Based Platform to Store, Protect, Synchronize, and Collaborate on Files Across All Locations at Scale
Data Sheet Data Sheet Nasuni Cloud File Services Nasuni Cloud File Services™ The modern, cloud-based platform to store, protect, synchronize, and collaborate on files across all locations at scale. Solution Overview What is Nasuni? Nasuni® Cloud File Services™ enables organizations to Nasuni Cloud File Services is a software-defined store, protect, synchronize and collaborate on files platform that leverages the low cost, scalability, and across all locations at scale. Licensed as stand-alone or durability of Amazon Simple Storage Service (Amazon bundled services, the Nasuni platform modernizes S3) and Nasuni’s cloud-based UniFS® global file system primary and archive file storage, file backup, and to transform file storage. disaster recovery, while offering advanced capabilities Just like device-based file systems were needed to for multi-site file synchronization. It is also the first make disk storage usable for storing files, Nasuni UniFS platform that automatically reduces costs as files age so overcomes obstacles inherent in Amazon S3 related to data never has to be migrated again. latency, file retrieval, and organization to make object With Nasuni, IT gains a more scalable, affordable, storage usable for storing files, with key features like: manageable, and highly available file infrastructure that • Fast access to files in any edge location. meets cloud-first objectives and eliminates tedious NAS • Legacy application support, without app rewrites. migrations and forklift upgrades. End users gain limitless capacity for group shares, project directories, and home • Familiar hierarchical folder structure for fast search. drives; LAN-speed access to files in any edge location; • Unified platform for primary and archive file storage and fast recovery of files to any point in time. -

Protocols: 0-9, A
Protocols: 0-9, A • 3COM-AMP3, on page 4 • 3COM-TSMUX, on page 5 • 3PC, on page 6 • 4CHAN, on page 7 • 58-CITY, on page 8 • 914C G, on page 9 • 9PFS, on page 10 • ABC-NEWS, on page 11 • ACAP, on page 12 • ACAS, on page 13 • ACCESSBUILDER, on page 14 • ACCESSNETWORK, on page 15 • ACCUWEATHER, on page 16 • ACP, on page 17 • ACR-NEMA, on page 18 • ACTIVE-DIRECTORY, on page 19 • ACTIVESYNC, on page 20 • ADCASH, on page 21 • ADDTHIS, on page 22 • ADOBE-CONNECT, on page 23 • ADWEEK, on page 24 • AED-512, on page 25 • AFPOVERTCP, on page 26 • AGENTX, on page 27 • AIRBNB, on page 28 • AIRPLAY, on page 29 • ALIWANGWANG, on page 30 • ALLRECIPES, on page 31 • ALPES, on page 32 • AMANDA, on page 33 • AMAZON, on page 34 • AMEBA, on page 35 • AMAZON-INSTANT-VIDEO, on page 36 Protocols: 0-9, A 1 Protocols: 0-9, A • AMAZON-WEB-SERVICES, on page 37 • AMERICAN-EXPRESS, on page 38 • AMINET, on page 39 • AN, on page 40 • ANCESTRY-COM, on page 41 • ANDROID-UPDATES, on page 42 • ANET, on page 43 • ANSANOTIFY, on page 44 • ANSATRADER, on page 45 • ANY-HOST-INTERNAL, on page 46 • AODV, on page 47 • AOL-MESSENGER, on page 48 • AOL-MESSENGER-AUDIO, on page 49 • AOL-MESSENGER-FT, on page 50 • AOL-MESSENGER-VIDEO, on page 51 • AOL-PROTOCOL, on page 52 • APC-POWERCHUTE, on page 53 • APERTUS-LDP, on page 54 • APPLEJUICE, on page 55 • APPLE-APP-STORE, on page 56 • APPLE-IOS-UPDATES, on page 57 • APPLE-REMOTE-DESKTOP, on page 58 • APPLE-SERVICES, on page 59 • APPLE-TV-UPDATES, on page 60 • APPLEQTC, on page 61 • APPLEQTCSRVR, on page 62 • APPLIX, on page 63 • ARCISDMS, -

Persistent 9P Sessions for Plan 9
Persistent 9P Sessions for Plan 9 Gorka Guardiola, [email protected] Russ Cox, [email protected] Eric Van Hensbergen, [email protected] ABSTRACT Traditionally, Plan 9 [5] runs mainly on local networks, where lost connections are rare. As a result, most programs, including the kernel, do not bother to plan for their file server connections to fail. These programs must be restarted when a connection does fail. If the kernel’s connection to the root file server fails, the machine must be rebooted. This approach suffices only because lost connections are rare. Across long distance networks, where connection failures are more common, it becomes woefully inadequate. To address this problem, we wrote a program called recover, which proxies a 9P session on behalf of a client and takes care of redialing the remote server and reestablishing con- nection state as necessary, hiding network failures from the client. This paper presents the design and implementation of recover, along with performance benchmarks on Plan 9 and on Linux. 1. Introduction Plan 9 is a distributed system developed at Bell Labs [5]. Resources in Plan 9 are presented as synthetic file systems served to clients via 9P, a simple file protocol. Unlike file protocols such as NFS, 9P is stateful: per-connection state such as which files are opened by which clients is maintained by servers. Maintaining per-connection state allows 9P to be used for resources with sophisticated access control poli- cies, such as exclusive-use lock files and chat session multiplexers. It also makes servers easier to imple- ment, since they can forget about file ids once a connection is lost. -

Nasuni for Business Continuity
+1.857.444.8500 Solution Brief nasuni.com [email protected] Nasuni for Business Continuity Summary of Nasuni Modern Cloud File Services Enables Remote Access to Critical Capabilities for Business File Assets and Remote Administration of File Infrastructure Continuity and Remote Work Anytime, Anywhere A key part of business continuity is main- Consolidation of Primary File Data in Remote File Access taining access to critical business con- Cloud Storage with Fast, Edge Access Anywhere, Anytime tent no matter what happens. Files are Highly resilient file storage is a funda- through standard drive the fastest-growing business content in mental building block for continuous file mappings or Web almost every industry. Providing remote file access. Nasuni stores the “gold copies” browser access, then, is a first step toward supporting of all file data in cloud object storage such Object Storage Dura- a “Work From Anywhere” model that can as Azure Blob, Amazon S3, or Google bility, Scalability, and sustain business operations through one-off Cloud Storage instead of legacy block Economics using Azure, hardware failures, local outages, regional storage. This approach leverages the AWS, and Google cloud office disasters, or global pandemics. superior durability, scalability, and availability storage of object storage to provision limitless file A remotely accessible file infrastructure sharing capacity, at substantially lower cost. Built-in Backup with that enables remote work must also be Better RPO/RTO with remotely manageable. IT departments Nasuni Edge Appliances – lightweight continuous file versioning must be able to provision new file storage virtual machines that cache copies of just to cloud storage capacity, create file shares, map drives, the frequently accessed files from cloud Rapid, Low-Cost DR recover data, and more without needing storage – can be deployed for as many that restores file shares skilled administrators “on the ground” in a offices as needed to give workers access in <15 minutes without datacenter or back office. -

Nasuni for Pharmaceuticals
+1.857.444.8500 Solution Brief nasuni.com [email protected] Nasuni for Pharmaceuticals Faster Collaboration Accelerate Research Collaboration with the Power of the Cloud between global research Now more than ever, pharmaceutical Nasuni Cloud File Storage for and manufacturing companies need to collaborate efficiently Pharmaceuticals locations across research and development centers, Major pharmaceutical companies have manufacturing facilities, and regulatory Unlimited Cloud solved their unstructured data storage, management centers. Critical research Storage On-Demand sharing, security, and protection challeng- and manufacturing processes generate in Microsoft Azure, AWS, es with Nasuni. terabytes of unstructured data that needs to IBM Cloud, Google be shared quickly — and protected securely. Immutable Storage in the Cloud Cloud or others elimi- Nasuni enables pharmaceutical com- nates on-premises NAS For IT, this requirement puts a tangible panies to consolidate all their file data in & file servers stress on traditionally siloed storage hard- cloud object storage (e.g. Microsoft Azure 50% Cost Savings ware and network bandwidth resources. Blob Storage, Amazon S3, Google Cloud when compared to Supporting unstructured data sharing Storage) instead of trapping it in silos of traditional NAS & backup forces IT to add storage capacity at an traditional, on-premises file servers or Net- solutions unpredictable rate, then bolt on expensive work-Attached Storage (NAS). Free from networking capabilities. Yet failing to keep physical device constraints, the combina- End-to-End Encryption up can impact both business and re- tion of Nasuni and cloud object storage secures research and search progress. Long delays waiting for offers limitless, scalable capacity at lower manufacturing data research files and manufacturing data to costs than on-premises storage. -

Virtfs—A Virtualization Aware File System Pass-Through
VirtFS—A virtualization aware File System pass-through Venkateswararao Jujjuri Eric Van Hensbergen Anthony Liguori IBM Linux Technology Center IBM Research Austin IBM Linux Technology Center [email protected] [email protected] [email protected] Badari Pulavarty IBM Linux Technology Center [email protected] Abstract operations into block device operations and then again into host file system operations. This paper describes the design and implementation of In addition to performance improvements over a tradi- a paravirtualized file system interface for Linux in the tional virtual block device, exposing guest file system KVM environment. Today’s solution of sharing host activity to the hypervisor provides greater insight to the files on the guest through generic network file systems hypervisor about the workload the guest is running. This like NFS and CIFS suffer from major performance and allows the hypervisor to make more intelligent decisions feature deficiencies as these protocols are not designed with respect to I/O caching and creates new opportuni- or optimized for virtualization. To address the needs of ties for hypervisor-based services like de-duplification. the virtualization paradigm, in this paper we are intro- ducing a new paravirtualized file system called VirtFS. In Section 2 of this paper, we explore more details about This new file system is currently under development and the motivating factors for paravirtualizing the file sys- is being built using QEMU, KVM, VirtIO technologies tem layer. In Section 3, we introduce the VirtFS design and 9P2000.L protocol. including an overview of the 9P protocol, which VirtFS is based on, along with a set of extensions introduced for greater Linux guest compatibility. -

Looking to the Future by JOHN BALDWIN
1 of 3 Looking to the Future BY JOHN BALDWIN FreeBSD’s 13.0 release delivers new features to users and refines the workflow for new contri- butions. FreeBSD contributors have been busy fixing bugs and adding new features since 12.0’s release in December of 2018. In addition, FreeBSD developers have refined their vision to focus on FreeBSD’s future users. An abbreviated list of some of the changes in 13.0 is given below. A more detailed list can be found in the release notes. Shifting Tools Not all of the changes in the FreeBSD Project over the last two years have taken the form of patches. Some of the largest changes have been made in the tools used to contribute to FreeBSD. The first major change is that FreeBSD has switched from Subversion to Git for storing source code, documentation, and ports. Git is widely used in the software industry and is more familiar to new contribu- tors than Subversion. Git’s distributed nature also more easily facilitates contributions from individuals who are Not all of the changes in the not committers. FreeBSD had been providing Git mir- rors of the Subversion repositories for several years, and FreeBSD Project over the last many developers had used Git to manage in-progress patches. The Git mirrors have now become the offi- two years have taken the form cial repositories and changes are now pushed directly of patches. to Git instead of Subversion. FreeBSD 13.0 is the first release whose sources are only available via Git rather than Subversion. -

Virtualization Best Practices
SUSE Linux Enterprise Server 15 SP1 Virtualization Best Practices SUSE Linux Enterprise Server 15 SP1 Publication Date: September 24, 2021 Contents 1 Virtualization Scenarios 2 2 Before You Apply Modifications 2 3 Recommendations 3 4 VM Host Server Configuration and Resource Allocation 3 5 VM Guest Images 25 6 VM Guest Configuration 36 7 VM Guest-Specific Configurations and Settings 42 8 Xen: Converting a Paravirtual (PV) Guest to a Fully Virtual (FV/HVM) Guest 45 9 External References 49 1 SLES 15 SP1 1 Virtualization Scenarios Virtualization oers a lot of capabilities to your environment. It can be used in multiple scenarios. To get more details about it, refer to the Book “Virtualization Guide” and in particular, to the following sections: Book “Virtualization Guide”, Chapter 1 “Virtualization Technology”, Section 1.2 “Virtualization Capabilities” Book “Virtualization Guide”, Chapter 1 “Virtualization Technology”, Section 1.3 “Virtualization Benefits” This best practice guide will provide advice for making the right choice in your environment. It will recommend or discourage the usage of options depending on your workload. Fixing conguration issues and performing tuning tasks will increase the performance of VM Guest's near to bare metal. 2 Before You Apply Modifications 2.1 Back Up First Changing the conguration of the VM Guest or the VM Host Server can lead to data loss or an unstable state. It is really important that you do backups of les, data, images, etc. before making any changes. Without backups you cannot restore the original state after a data loss or a misconguration. Do not perform tests or experiments on production systems. -

Egnyte + Alberici Case Study
+ Customer Success From the Office to the Project Site, How Alberici Uses Egnyte to Keep Teams in Sync Egnyte has opened new doors of possibilities where we didn’t have access out in the field previously. The VDC and BIM teams utilize Egnyte to sync huge files offline. They have been our largest proponents of Egnyte. — Ron Borror l Director, IT Infrastructure $2B + Annual Revenue Introduction Solving complex challenges on aggressive timelines is in the DNA of Alberici Corporation, a diversified construction company 17 that works in industrial and commercial markets globally. Regional Offices When longtime client General Motors Company called on Alberici for an urgent design-build request to transform an 100 86,000 square-foot warehouse into an emergency ventilator Average Number manufacturing facility during the COVID-19 pandemic, they of Projects answered the call. Within just two weeks, the transformed facility produced its first ventilator and, within a month, it was making 500 life-saving devices a day. AT A GLANCE Drawing on their more than 100-years of experience successfully completing complex projects like the largest hydroelectric plant on the Ohio River, automotive assembly plants for leading car manufacturers, and SSM Health Saint Louis University Hospital, Alberici was ready to act fast. Engineering News-Record recently ranked Alberici as the 31st- largest construction company in the United States with annual revenues of $2B. Nearly 80 percent of Alberici’s business is generated by repeat clients, a testament to their service and quality and the foundation for consistent growth. www.egnyte.com | © 2020 by Egnyte Inc. All rights reserved. -

ZFS: Love Your Data
ZFS: Love Your Data Neal H. Waleld LinuxCon Europe, 14 October 2014 ZFS Features I Security I End-to-End consistency via checksums I Self Healing I Copy on Write Transactions I Additional copies of important data I Snapshots and Clones I Simple, Incremental Remote Replication I Easier Administration I One shared pool rather than many statically-sized volumes I Performance Improvements I Hierarchical Storage Management (HSM) I Pooled Architecture =) shared IOPs I Developed for many-core systems I Scalable 128 I Pool Address Space: 2 bytes I O(1) operations I Fine-grained locks I On-disk data is protected by ECC I But, doesn't correct / catch all errors Silent Data Corruption I Data errors that are not caught by hard drive I = Read returns dierent data from what was written Silent Data Corruption I Data errors that are not caught by hard drive I = Read returns dierent data from what was written I On-disk data is protected by ECC I But, doesn't correct / catch all errors Uncorrectable Errors By Cory Doctorow, CC BY-SA 2.0 I Reported as BER (Bit Error Rate) I According to Data Sheets: 14 I Desktop: 1 corrupted bit per 10 (12 TB) 15 I Enterprise: 1 corrupted bit per 10 (120 TB) ∗ I Practice: 1 corrupted sector per 8 to 20 TB ∗Je Bonwick and Bill Moore, ZFS: The Last Word in File Systems, 2008 Types of Errors I Bit Rot I Phantom writes I Misdirected read / write 8 9 y I 1 per 10 to 10 IOs I = 1 error per 50 to 500 GB (assuming 512 byte IOs) I DMA Parity Errors By abdallahh, CC BY-SA 2.0 I Software / Firmware Bugs I Administration Errors yUlrich -
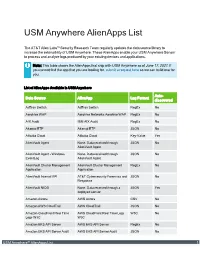
USM Anywhere Alienapps List
USM Anywhere AlienApps List The AT&T Alien Labs™ Security Research Team regularly updates the data source library to increase the extensibility of USM Anywhere. These AlienApps enable your USM Anywhere Sensor to process and analyze logs produced by your existing devices and applications. Note: This table shows the AlienApps that ship with USM Anywhere as of June 17, 2021. If you cannot find the app that you are looking for, submit a request here so we can build one for you. List of AlienApps Available in USM Anywhere Auto- Data Source AlienApp Log Format discovered AdTran Switch AdTran Switch RegEx No Aerohive WAP Aerohive Networks Aerohive WAP RegEx No AIX Audit IBM AIX Audit RegEx No Akamai ETP Akamai ETP JSON No Alibaba Cloud Alibaba Cloud Key-Value Yes AlienVault Agent None. Data received through JSON No AlienVault Agent AlienVault Agent - Windows None. Data received through JSON No EventLog AlienVault Agent AlienVault Cluster Management AlienVault Cluster Management RegEx No Application Application AlienVault Internal API AT&T Cybersecurity Forensics and JSON No Response AlienVault NIDS None. Data received through a JSON Yes deployed sensor Amazon Aurora AWS Aurora CSV No Amazon AWS CloudTrail AWS CloudTrail JSON No Amazon CloudFront Real Time AWS CloudFront Real Time Logs W3C No Logs W3C W3C Amazon EKS API Server AWS EKS API Server RegEx No Amazon EKS API Server Audit AWS EKS API Server Audit JSON No USM Anywhere™ AlienApps List 1 List of AlienApps Available in USM Anywhere (Continued) Auto- Data Source AlienApp Log Format discovered -

File Servers: Is It Time to Say Goodbye? Unstructured Data Is the Fastest-Growing Segment of Data in the Data Center
File Servers: Is It Time to Say Goodbye? Unstructured data is the fastest-growing segment of data in the data center. A significant portion of data within unstructured data is the data that users create though office productivity and other specialized applications. User data also often represents the bulk of the organization’s intellectual property. Traditionally, user data is stored on either file servers or network-attached storage (NAS) systems, which IT tries to locate solely at a primary data center. Initially, the problem that IT faced with storing unstructured data was keeping up with its growth, which leads to file server or NAS sprawl. Now the problem IT faces in storing file data is that users are no longer located in a single primary headquarters. The distribution of employees exacerbates file server sprawl. It also makes it almost impossible for collaboration on the data between locations. IT has tried various workarounds like routing everyone to a single server via a virtual private network (VPN), which leads to inconsistent connections and unacceptable performance. Users rebel and implement workarounds like consumer file sync and share, which puts corporate data at risk. Organizations are looking to the cloud for alternatives. Still, most cloud solutions are either attempts to harden file sync and share or are Cloud-only NAS implementations that don’t allow for cloud latency. Nasuni A File Services Platform Built for the Cloud Nasuni is a global file system that enables distributed organizations to work together as if they were all in a single office. It leverages the cloud as a primary storage point but integrates on-premises edge appliances, often running as virtual machines, to overcome cloud latency issues.