ATM 562: Numerical Methods and Modeling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Pressure Gradient Force Examples of Pressure Gradient Hurricane Andrew, 1992 Extratropical Cyclone
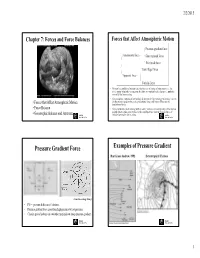
4/29/2011 Chapter 7: Forces and Force Balances Forces that Affect Atmospheric Motion Pressure gradient force Fundamental force - Gravitational force FitiFrictiona lfl force Centrifugal force Apparent force - Coriolis force • Newton’s second law of motion states that the rate of change of momentum (i.e., the acceleration) of an object , as measured relative relative to coordinates fixed in space, equals the sum of all the forces acting. • For atmospheric motions of meteorological interest, the forces that are of primary concern are the pressure gradient force, the gravitational force, and friction. These are the • Forces that Affect Atmospheric Motion fundamental forces. • Force Balance • For a coordinate system rotating with the earth, Newton’s second law may still be applied provided that certain apparent forces, the centrifugal force and the Coriolis force, are • Geostrophic Balance and Jetstream ESS124 included among the forces acting. ESS124 Prof. Jin-Jin-YiYi Yu Prof. Jin-Jin-YiYi Yu Pressure Gradient Force Examples of Pressure Gradient Hurricane Andrew, 1992 Extratropical Cyclone (from Meteorology Today) • PG = (pressure difference) / distance • Pressure gradient force goes from high pressure to low pressure. • Closely spaced isobars on a weather map indicate steep pressure gradient. ESS124 ESS124 Prof. Jin-Jin-YiYi Yu Prof. Jin-Jin-YiYi Yu 1 4/29/2011 Gravitational Force Pressure Gradients • • Pressure Gradients – The pressure gradient force initiates movement of atmospheric mass, widfind, from areas o fhihf higher to areas o flf -

Chapter 5. Meridional Structure of the Atmosphere 1
Chapter 5. Meridional structure of the atmosphere 1. Radiative imbalance 2. Temperature • See how the radiative imbalance shapes T 2. Temperature: potential temperature 2. Temperature: equivalent potential temperature 3. Humidity: specific humidity 3. Humidity: saturated specific humidity 3. Humidity: saturated specific humidity Last time • Saturated adiabatic lapse rate • Equivalent potential temperature • Convection • Meridional structure of temperature • Meridional structure of humidity Today’s topic • Geopotential height • Wind 4. Pressure / geopotential height • From a hydrostatic balance and perfect gas law, @z RT = @p − gp ps T dp z(p)=R g p Zp • z(p) is called geopotential height. • If we assume that T and g does not vary a lot with p, geopotential height is higher when T increases. 4. Pressure / geopotential height • If we assume that g and T do not vary a lot with p, RT z(p)= (ln p ln p) g s − • z increases as p decreases. • Higher T increases geopotential height. 4. Pressure / geopotential height • Geopotential height is lower at the low pressure system. • Or the high pressure system corresponds to the high geopotential height. • T tends to be low in the region of low geopotential height. 4. Pressure / geopotential height The mean height of the 500 mbar surface in January , 2003 4. Pressure / geopotential height • We can discuss about the slope of the geopotential height if we know the temperature. R z z = (T T )(lnp ln p) warm − cold g warm − cold s − • We can also discuss about the thickness of an atmospheric layer if we know the temperature. RT z z = (ln p ln p ) p1 − p2 g 2 − 1 4. -

Heat Advection Processes Leading to El Niño Events As
1 2 Title: 3 Heat advection processes leading to El Niño events as depicted by an ensemble of ocean 4 assimilation products 5 6 Authors: 7 Joan Ballester (1,2), Simona Bordoni (1), Desislava Petrova (2), Xavier Rodó (2,3) 8 9 Affiliations: 10 (1) California Institute of Technology (Caltech), Pasadena, California, United States 11 (2) Institut Català de Ciències del Clima (IC3), Barcelona, Catalonia, Spain 12 (3) Institució Catalana de Recerca i Estudis Avançats (ICREA), Barcelona, Catalonia, Spain 13 14 Corresponding author: 15 Joan Ballester 16 California Institute of Technology (Caltech) 17 1200 E California Blvd, Pasadena, CA 91125, US 18 Mail Code: 131-24 19 Tel.: +1-626-395-8703 20 Email: [email protected] 21 22 Manuscript 23 Submitted to Journal of Climate 24 1 25 26 Abstract 27 28 The oscillatory nature of El Niño-Southern Oscillation results from an intricate 29 superposition of near-equilibrium balances and out-of-phase disequilibrium processes between the 30 ocean and the atmosphere. Several authors have shown that the heat content stored in the equatorial 31 subsurface is key to provide memory to the system. Here we use an ensemble of ocean assimilation 32 products to describe how heat advection is maintained in each dataset during the different stages of 33 the oscillation. 34 Our analyses show that vertical advection due to surface horizontal convergence and 35 downwelling motion is the only process contributing significantly to the initial subsurface warming 36 in the western equatorial Pacific. This initial warming is found to be advected to the central Pacific 37 by the equatorial undercurrent, which, together with the equatorward advection associated with 38 anomalies in both the meridional temperature gradient and circulation at the level of the 39 thermocline, explains the heat buildup in the central Pacific during the recharge phase. -
Pressure Gradient Force
2/2/2015 Chapter 7: Forces and Force Balances Forces that Affect Atmospheric Motion Pressure gradient force Fundamental force - Gravitational force Frictional force Centrifugal force Apparent force - Coriolis force • Newton’s second law of motion states that the rate of change of momentum (i.e., the acceleration) of an object, as measured relative to coordinates fixed in space, equals the sum of all the forces acting. • For atmospheric motions of meteorological interest, the forces that are of primary concern are the pressure gradient force, the gravitational force, and friction. These are the • Forces that Affect Atmospheric Motion fundamental forces. • Force Balance • For a coordinate system rotating with the earth, Newton’s second law may still be applied provided that certain apparent forces, the centrifugal force and the Coriolis force, are • Geostrophic Balance and Jetstream ESS124 included among the forces acting. ESS124 Prof. Jin-Yi Yu Prof. Jin-Yi Yu Pressure Gradient Force Examples of Pressure Gradient Hurricane Andrew, 1992 Extratropical Cyclone (from Meteorology Today) • PG = (pressure difference) / distance • Pressure gradient force goes from high pressure to low pressure. • Closely spaced isobars on a weather map indicate steep pressure gradient. ESS124 ESS124 Prof. Jin-Yi Yu Prof. Jin-Yi Yu 1 2/2/2015 Balance of Force in the Vertical: Pressure Gradients Hydrostatic Balance • Pressure Gradients – The pressure gradient force initiates movement of atmospheric mass, wind, from areas of higher to areas of lower pressure Vertical -

Contribution of Horizontal Advection to the Interannual Variability of Sea Surface Temperature in the North Atlantic
964 JOURNAL OF PHYSICAL OCEANOGRAPHY VOLUME 33 Contribution of Horizontal Advection to the Interannual Variability of Sea Surface Temperature in the North Atlantic NATHALIE VERBRUGGE Laboratoire d'Etudes en GeÂophysique et OceÂanographie Spatiales, Toulouse, France GILLES REVERDIN Laboratoire d'Etudes en GeÂophysique et OceÂanographie Spatiales, Toulouse, and Laboratoire d'OceÂanographie Dynamique et de Climatologie, Paris, France (Manuscript received 9 February 2002, in ®nal form 15 October 2002) ABSTRACT The interannual variability of sea surface temperature (SST) in the North Atlantic is investigated from October 1992 to October 1999 with special emphasis on analyzing the contribution of horizontal advection to this variability. Horizontal advection is estimated using anomalous geostrophic currents derived from the TOPEX/ Poseidon sea level data, average currents estimated from drifter data, scatterometer-derived Ekman drifts, and monthly SST data. These estimates have large uncertainties, in particular related to the sea level product, the average currents, and the mixed-layer depth, that contribute signi®cantly to the nonclosure of the surface tem- perature budget. The large scales in winter temperature change over a year present similarities with the heat ¯uxes integrated over the same periods. However, the amplitudes do not match well. Furthermore, in the western subtropical gyre (south of the Gulf Stream) and in the subpolar regions, the time evolutions of both ®elds are different. In both regions, advection is found to contribute signi®cantly to the interannual winter temperature variability. In the subpolar gyre, advection often contributes more to the SST variability than the heat ¯uxes. It seems in particular responsible for a low-frequency trend from 1994 to 1998 (increase in the subpolar gyre and decrease in the western subtropical gyre), which is not found in the heat ¯uxes and in the North Atlantic Oscillation index after 1996. -

Potential Vorticity
POTENTIAL VORTICITY Roger K. Smith March 3, 2003 Contents 1 Potential Vorticity Thinking - How might it help the fore- caster? 2 1.1Introduction............................ 2 1.2WhatisPV-thinking?...................... 4 1.3Examplesof‘PV-thinking’.................... 7 1.3.1 A thought-experiment for understanding tropical cy- clonemotion........................ 7 1.3.2 Kelvin-Helmholtz shear instability . ......... 9 1.3.3 Rossby wave propagation in a β-planechannel..... 12 1.4ThestructureofEPVintheatmosphere............ 13 1.4.1 Isentropicpotentialvorticitymaps........... 14 1.4.2 The vertical structure of upper-air PV anomalies . 18 2 A Potential Vorticity view of cyclogenesis 21 2.1PreliminaryIdeas......................... 21 2.2SurfacelayersofPV....................... 21 2.3Potentialvorticitygradientwaves................ 23 2.4 Baroclinic Instability . .................... 28 2.5 Applications to understanding cyclogenesis . ......... 30 3 Invertibility, iso-PV charts, diabatic and frictional effects. 33 3.1 Invertibility of EPV ........................ 33 3.2Iso-PVcharts........................... 33 3.3Diabaticandfrictionaleffects.................. 34 3.4Theeffectsofdiabaticheatingoncyclogenesis......... 36 3.5Thedemiseofcutofflowsandblockinganticyclones...... 36 3.6AdvantageofPVanalysisofcutofflows............. 37 3.7ThePVstructureoftropicalcyclones.............. 37 1 Chapter 1 Potential Vorticity Thinking - How might it help the forecaster? 1.1 Introduction A review paper on the applications of Potential Vorticity (PV-) concepts by Brian -

Lecture 18 Condensation And
Lecture 18 Condensation and Fog Cloud Formation by Condensation • Mixed into air are myriad submicron particles (sulfuric acid droplets, soot, dust, salt), many of which are attracted to water molecules. As RH rises above 80%, these particles bind more water and swell, producing haze. • When the air becomes supersaturated, the largest of these particles act as condensation nucleii onto which water condenses as cloud droplets. • Typical cloud droplets have diameters of 2-20 microns (diameter of a hair is about 100 microns). • There are usually 50-1000 droplets per cm3, with highest droplet concentra- tions in polluted continental regions. Why can you often see your breath? Condensation can occur when warm moist (but unsaturated air) mixes with cold dry (and unsat- urated) air (also contrails, chimney steam, steam fog). Temp. RH SVP VP cold air (A) 0 C 20% 6 mb 1 mb(clear) B breath (B) 36 C 80% 63 mb 55 mb(clear) C 50% cold (C)18 C 140% 20 mb 28 mb(fog) 90% cold (D) 4 C 90% 8 mb 6 mb(clear) D A • The 50-50 mix visibly condenses into a short- lived cloud, but evaporates as breath is EOM 4.5 diluted. Fog Fog: cloud at ground level Four main types: radiation fog, advection fog, upslope fog, steam fog. TWB p. 68 • Forms due to nighttime longwave cooling of surface air below dew point. • Promoted by clear, calm, long nights. Common in Seattle in winter. • Daytime warming of ground and air ‘burns off’ fog when temperature exceeds dew point. • Fog may lift into a low cloud layer when it thickens or dissipates. -

Wind Enhances Differential Air Advection in Surface Snow at Sub- Meter Scales Stephen A
Wind enhances differential air advection in surface snow at sub- meter scales Stephen A. Drake1, John S. Selker2, Chad W. Higgins2 1College of Earth, Ocean and Atmospheric Sciences, Oregon State University, Corvallis, 97333, USA 5 2Biological and Ecological Engineering, Oregon State University, Corvallis, 97333, USA Correspondence to: Stephen A. Drake ([email protected]) Abstract. Atmospheric pressure gradients and pressure fluctuations drive within-snow air movement that enhances gas mobility through interstitial pore space. The magnitude of this enhancement in relation to snow microstructure properties cannot be well predicted with current methods. In a set of field experiments we injected a dilute mixture of 1% carbon 10 monoxide and nitrogen gas of known volume into the topmost layer of a snowpack and, using a distributed array of thin film sensors, measured plume evolution as a function of wind forcing. We found enhanced dispersion in the streamwise direction and also along low resistance pathways in the presence of wind. These results suggest that atmospheric constituents contained in snow can be anisotropically mixed depending on the wind environment and snow structure, having implications for surface snow reaction rates and interpretation of firn and ice cores. 15 1 Introduction Atmospheric pressure changes over a broad range of temporal and spatial scales stimulate air movement in near-surface snow pore space (Clarke et al., 1987) that redistribute radiatively and chemically active trace species (Waddington et al., 1996) such as O3 (Albert et al., 2002), OH (Domine and Shepson, 2002) and NO (Pinzer et al., 2010) thereby influencing their reaction rates. Pore space in snow is saturated within a few millimeters of depth in the snowpack that does not have 20 large air spaces (Neumann et al., 2009) so atmospheric pressure changes induce interstitial air movement that enhances snow metamorphism (Calonne et al., 2015; Ebner et al., 2015) and augments vapor exchange between the snowpack and atmosphere. -

Chapter 7 Isopycnal and Isentropic Coordinates
Chapter 7 Isopycnal and Isentropic Coordinates The two-dimensional shallow water model can carry us only so far in geophysical uid dynam- ics. In this chapter we begin to investigate fully three-dimensional phenomena in geophysical uids using a type of model which builds on the insights obtained using the shallow water model. This is done by treating a three-dimensional uid as a stack of layers, each of con- stant density (the ocean) or constant potential temperature (the atmosphere). Equations similar to the shallow water equations apply to each layer, and the layer variable (density or potential temperature) becomes the vertical coordinate of the model. This is feasible because the requirement of convective stability requires this variable to be monotonic with geometric height, decreasing with height in the case of water density in the ocean, and increasing with height with potential temperature in the atmosphere. As long as the slope of model layers remains small compared to unity, the coordinate axes remain close enough to orthogonal to ignore the complex correction terms which otherwise appear in non-orthogonal coordinate systems. 7.1 Isopycnal model for the ocean The word isopycnal means constant density. Recall that an assumption behind the shallow water equations is that the water have uniform density. For layered models of a three- dimensional, incompressible uid, we similarly assume that each layer is of uniform density. We now see how the momentum, continuity, and hydrostatic equations appear in the context of an isopycnal model. 7.1.1 Momentum equation Recall that the horizontal (in terms of z) pressure gradient must be calculated, since it appears in the horizontal momentum equations. -

1050 Clicker Questions Exam 1
Answers to Clicker Questions Chapter 1 What component of the atmosphere is most important to weather? A. Nitrogen B. Oxygen C. Carbon dioxide D. Ozone E. Water What location would have the lowest surface pressure? A. Chicago, Illinois B. Denver, Colorado C. Miami, Florida D. Dallas, Texas E. Los Angeles, California What is responsible for the distribution of surface pressure shown on the previous map? A. Temperature B. Elevation C. Weather D. Population If the relative humidity and the temperature at Denver, Colorado, compared to that at Miami, Florida, is as shown below, how much absolute water vapor is in the air between these two locations? A. Denver has more absolute water vapor B. Miami has more absolute water vapor C. Both have the same amount of water vapor Denver 10°C Air temperature 50% Relative humidity Miami 20°C Air temperature 50% Relative humidity Chapter 2 Convert our local time of 9:45am MST to UTC A. 0945 UTC B. 1545 UTC C. 1645 UTC D. 2345 UTC A weather observation made at 0400 UTC on January 10th, would correspond to what local time (MST)? A. 11:00am January10th B. 9:00pm January 10th C. 10:00pm January 9th D. 9:00pm January 9th A weather observation made at 0600 UTC on July 10th, would correspond to what local time (MDT)? A. 12:00am July 10th B. 12:00pm July 10th C. 1:00pm July 10th D. 11:00pm July 9th A rawinsonde measures all of the following variables except: Temperature Dew point temperature Precipitation Wind speed Wind direction What can a Doppler weather radar measure? Position of precipitation Intensity of precipitation Radial wind speed All of the above Only a and b In this sounding from Denver, the tropopause is located at a pressure of approximately: 700 mb 500 mb 300 mb 100 mb Which letter on this radar reflectivity image has the highest rainfall rate? A B C D C D B A Chapter 3 • Using this surface station model, what is the temperature? (Assume it’s in the US) 26 °F 26 °C 28 °F 28 °C 22.9 °F Using this surface station model, what is the current sea level pressure? A. -

Thickness and Thermal Wind
ESCI 241 – Meteorology Lesson 12 – Geopotential, Thickness, and Thermal Wind Dr. DeCaria GEOPOTENTIAL l The acceleration due to gravity is not constant. It varies from place to place, with the largest variation due to latitude. o What we call gravity is actually the combination of the gravitational acceleration and the centrifugal acceleration due to the rotation of the Earth. o Gravity at the North Pole is approximately 9.83 m/s2, while at the Equator it is about 9.78 m/s2. l Though small, the variation in gravity must be accounted for. We do this via the concept of geopotential. l A surface of constant geopotential represents a surface along which all objects of the same mass have the same potential energy (the potential energy is just mF). l If gravity were constant, a geopotential surface would also have the same altitude everywhere. Since gravity is not constant, a geopotential surface will have varying altitude. l Geopotential is defined as z F º ò gdz, (1) 0 or in differential form as dF = gdz. (2) l Geopotential height is defined as F 1 z Z º = ò gdz (3) g0 g0 0 2 where g0 is a constant called standard gravity, and has a value of 9.80665 m/s . l If the change in gravity with height is ignored, geopotential height and geometric height are related via g Z = z. (4) g 0 o If the local gravity is stronger than standard gravity, then Z > z. o If the local gravity is weaker than standard gravity, then Z < z. -

Temperature Gradient
Temperature Gradient Derivation of dT=dr In Modern Physics it is shown that the pressure of a photon gas in thermodynamic equilib- rium (the radiation pressure PR) is given by the equation 1 P = aT 4; (1) R 3 with a the radiation constant, which is related to the Stefan-Boltzman constant, σ, and the speed of light in vacuum, c, via the equation 4σ a = = 7:565731 × 10−16 J m−3 K−4: (2) c Hence, the radiation pressure gradient is dP 4 dT R = aT 3 : (3) dr 3 dr Referring to our our discussion of opacity, we can write dF = −hκiρF; (4) dr where F = F (r) is the net outward flux (integrated over all wavelengths) of photons at a distance r from the center of the star, and hκi some properly taken average value of the opacity. The flux F is related to the luminosity through the equation L(r) F (r) = : (5) 4πr2 Considering that pressure is force per unit area, and force is a rate of change of linear momentum, and photons carry linear momentum equal to their energy divided by c, PR and F obey the equation 1 P = F (r): (6) R c Differentiation with respect to r gives dP 1 dF R = : (7) dr c dr Combining equations (3), (4), (5) and (7) then gives 1 L(r) 4 dT − hκiρ = aT 3 ; (8) c 4πr2 3 dr { 2 { which finally leads to dT 3hκiρ 1 1 = − L(r): (9) dr 16πac T 3 r2 Equation (9) gives the local (i.e.