Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CD56+ T-Cells in Relation to Cytomegalovirus in Healthy Subjects and Kidney Transplant Patients
CD56+ T-cells in Relation to Cytomegalovirus in Healthy Subjects and Kidney Transplant Patients Institute of Infection and Global Health Department of Clinical Infection, Microbiology and Immunology Thesis submitted in accordance with the requirements of the University of Liverpool for the degree of Doctor in Philosophy by Mazen Mohammed Almehmadi December 2014 - 1 - Abstract Human T cells expressing CD56 are capable of tumour cell lysis following activation with interleukin-2 but their role in viral immunity has been less well studied. The work described in this thesis aimed to investigate CD56+ T-cells in relation to cytomegalovirus infection in healthy subjects and kidney transplant patients (KTPs). Proportions of CD56+ T cells were found to be highly significantly increased in healthy cytomegalovirus-seropositive (CMV+) compared to cytomegalovirus-seronegative (CMV-) subjects (8.38% ± 0.33 versus 3.29%± 0.33; P < 0.0001). In donor CMV-/recipient CMV- (D-/R-)- KTPs levels of CD56+ T cells were 1.9% ±0.35 versus 5.42% ±1.01 in D+/R- patients and 5.11% ±0.69 in R+ patients (P 0.0247 and < 0.0001 respectively). CD56+ T cells in both healthy CMV+ subjects and KTPs expressed markers of effector memory- RA T-cells (TEMRA) while in healthy CMV- subjects and D-/R- KTPs the phenotype was predominantly that of naïve T-cells. Other surface markers, CD8, CD4, CD58, CD57, CD94 and NKG2C were expressed by a significantly higher proportion of CD56+ T-cells in healthy CMV+ than CMV- subjects. Functional studies showed levels of pro-inflammatory cytokines IFN-γ and TNF-α, as well as granzyme B and CD107a were significantly higher in CD56+ T-cells from CMV+ than CMV- subjects following stimulation with CMV antigens. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Structural Basis of UGUA Recognition by the Nudix Protein CFI 25
Structural basis of UGUA recognition by the Nudix protein CFIm25 and implications for a regulatory role in mRNA 3′ processing Qin Yang, Gregory M. Gilmartin1, and Sylvie Doublié1 Department of Microbiology and Molecular Genetics, Stafford Hall, University of Vermont, Burlington, VT 05405 Edited by Joan A. Steitz, Howard Hughes Medical Institute, New Haven, CT, and approved April 20, 2010 (received for review January 21, 2010) — Human Cleavage Factor Im (CFIm) is an essential component of the C-terminal RS/RD alternating charge domain a structure simi- pre-mRNA 3′ processing complex that functions in the regulation of lar to that of the SR-protein family of splicing regulators. The 25 poly(A) site selection through the recognition of UGUA sequences small subunit (CFIm ) contains a Nudix domain, a protein do- upstream of the poly(A) site. Although the highly conserved 25 kDa main that most often participates in the hydrolysis of substrates subunit (CFIm25) of the CFIm complex possesses a characteristic containing a nucleotide diphosphate linked to a variable moiety α β α / / Nudix fold, CFIm25 has no detectable hydrolase activity. Here X (15). Found throughout all three kingdoms, Nudix proteins we report the crystal structures of the human CFIm25 homodimer in participate in a wide range of crucial housekeeping functions, in- complex with UGUAAA and UUGUAU RNA sequences. CFIm25 is the cluding the hydrolysis of mutagenic nucleotides, the modulation first Nudix protein to be reported to bind RNA in a sequence- of the levels of signaling molecules, and the monitoring of meta- 25 α β specific manner. The UGUA sequence contributes to binding speci- bolic intermediates (15). -

CPSF6 Links Alternative Polyadenylation to Metabolism
Tan et al. Journal of Experimental & Clinical Cancer Research (2021) 40:85 https://doi.org/10.1186/s13046-021-01884-z RESEARCH Open Access CPSF6 links alternative polyadenylation to metabolism adaption in hepatocellular carcinoma progression Sheng Tan1†, Ming Zhang2†, Xinglong Shi3†, Keshuo Ding4, Qiang Zhao3, Qianying Guo4, Hao Wang4, Zhengsheng Wu4, Yani Kang3, Tao Zhu5*, Jielin Sun1* and Xiaodong Zhao1* Abstract Background: Alternative polyadenylation (APA) is an important mechanism of gene expression regulation through generation of RNA isoforms with distinct 3′ termini. Increasing evidence has revealed that APA is actively involved in development and disease, including hepatocellular carcinoma (HCC). However, how APA functions in tumor formation and progression remains elusive. In this study, we investigated the role of cleavage factor I (CFIm) subunit CPSF6 in human hepatocellular carcinoma (HCC). Methods: Expression levels of CPSF6 in clinical tissues and cell lines were determined by qRT-PCR and western blot. Functional assays, including the cell number, MTT, colony formation and transwell, were used to determine the oncogenic role of CPSF6 in HCC. Animal experiments were used to determine the role of CPSF6 in HCC tumorigenicity in vivo. Deep sequencing-based 3 T-seq was used to profile the transcriptome-wide APA sites in both HCC cells and CPSF6 knockdown HCC cells. The function of CPSF6-affected target NQO1 with distinct 3′UTRs was characterized by metabolism assays. Results: We observed CPSF6 was upregulated in HCC and the high expression of CPSF6 was associated with poor prognosis in patients. Overexpression of CPSF6 promoted proliferation, migration and invasion of HCC cells in vitro and in vivo. -
Primepcr™Assay Validation Report
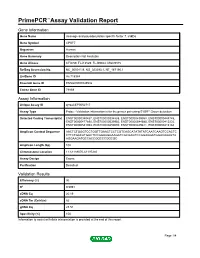
PrimePCR™Assay Validation Report Gene Information Gene Name cleavage and polyadenylation specific factor 7, 59kDa Gene Symbol CPSF7 Organism Human Gene Summary Description Not Available Gene Aliases CFIm59, FLJ12529, FLJ39024, MGC9315 RefSeq Accession No. NC_000011.9, NG_023393.1, NT_167190.1 UniGene ID Hs.718984 Ensembl Gene ID ENSG00000149532 Entrez Gene ID 79869 Assay Information Unique Assay ID qHsaCEP0052717 Assay Type Probe - Validation information is for the primer pair using SYBR® Green detection Detected Coding Transcript(s) ENST00000340437, ENST00000394888, ENST00000439958, ENST00000448745, ENST00000477890, ENST00000539952, ENST00000544585, ENST00000413232, ENST00000541963, ENST00000450000, ENST00000449811, ENST00000413184 Amplicon Context Sequence AACTCTGGGTCCTGGTTGAACTCCTCGTCAGCATATATATCAATCAAGTCCACTC CTTCTGACATGGCTCCGGAAGGAAGATCGCGAGTCCGGAGGATGGACAAAGTA AGGAAGATGCCACCGGCCCGGCGC Amplicon Length (bp) 102 Chromosome Location 11:61189070-61197240 Assay Design Exonic Purification Desalted Validation Results Efficiency (%) 96 R2 0.9991 cDNA Cq 20.19 cDNA Tm (Celsius) 82 gDNA Cq 28.51 Specificity (%) 100 Information to assist with data interpretation is provided at the end of this report. Page 1/4 PrimePCR™Assay Validation Report CPSF7, Human Amplification Plot Amplification of cDNA generated from 25 ng of universal reference RNA Melt Peak Melt curve analysis of above amplification Standard Curve Standard curve generated using 20 million copies of template diluted 10-fold to 20 copies Page 2/4 PrimePCR™Assay Validation Report Products used to generate validation data Real-Time PCR Instrument CFX384 Real-Time PCR Detection System Reverse Transcription Reagent iScript™ Advanced cDNA Synthesis Kit for RT-qPCR Real-Time PCR Supermix SsoAdvanced™ SYBR® Green Supermix Experimental Sample qPCR Human Reference Total RNA Data Interpretation Unique Assay ID This is a unique identifier that can be used to identify the assay in the literature and online. -

Joint Profiling of Chromatin Accessibility and CAR-T Integration Site Analysis at Population and Single-Cell Levels
Joint profiling of chromatin accessibility and CAR-T integration site analysis at population and single-cell levels Wenliang Wanga,b,c,d, Maria Fasolinoa,b,c,d, Benjamin Cattaua,b,c,d, Naomi Goldmana,b,c,d, Weimin Konge,f,g, Megan A. Fredericka,b,c,d, Sam J. McCrighta,b,c,d, Karun Kiania,b,c,d, Joseph A. Fraiettae,f,g,h, and Golnaz Vahedia,b,c,d,f,1 aDepartment of Genetics, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; bInstitute for Immunology, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; cEpigenetics Institute, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; dInstitute for Diabetes, Obesity and Metabolism, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; eDepartment of Microbiology, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; fAbramson Family Cancer Center, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; gCenter for Cellular Immunotherapies, University of Pennsylvania Perelman School of Medicine, Philadelphia, PA 19104; and hParker Institute for Cancer Immunotherapy, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA 19104 Edited by Anjana Rao, La Jolla Institute for Allergy and Immunology, La Jolla, CA, and approved January 30, 2020 (received for review November 3, 2019) Chimeric antigen receptor (CAR)-T immunotherapy has yielded tumor killing. To determine the extent to which these two sce- impressive results in several B cell malignancies, establishing itself narios occur in vivo, it is essential to simultaneously determine as a powerful means to redirect the natural properties of T lym- T cell fate and map where CAR-T vectors integrate into the phocytes. -

Association of Common Genetic Variants in the CPSF7 and SDHAF2 Genes with Canine Idiopathic Pulmonary Fibrosis in the West Highland White Terrier
G C A T T A C G G C A T genes Article Association of Common Genetic Variants in the CPSF7 and SDHAF2 Genes with Canine Idiopathic Pulmonary Fibrosis in the West Highland White Terrier Ignazio S. Piras 1, Christiane Bleul 1, Ashley Siniard 1, Amanda J. Wolfe 1, Matthew D. De Both 1, Alvaro G. Hernandez 2 and Matthew J. Huentelman 1,* 1 Neurogenomics Division, Translational Genomics Research Institute, Phoenix, AZ 85004, USA; [email protected] (I.S.P.); [email protected] (C.B.); [email protected] (A.S.); [email protected] (A.J.W.); [email protected] (M.D.D.B.) 2 Roy J. Carver Biotechnology Center, University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA; [email protected] * Correspondence: [email protected]; Tel.: +1-602-343-8730 Received: 7 April 2020; Accepted: 29 May 2020; Published: 30 May 2020 Abstract: Canine idiopathic pulmonary fibrosis (CIPF) is a chronic fibrotic lung disease that is observed at a higher frequency in the West Highland White Terrier dog breed (WHWT) and may have molecular pathological overlap with human lung fibrotic disease. We conducted a genome-wide association study (GWAS) in the WHWT using whole genome sequencing (WGS) to discover genetic variants associated with CIPF. Saliva-derived DNA samples were sequenced using the Riptide DNA library prep kit. After quality controls, 28 affected, 44 unaffected, and 1,843,695 informative single nucleotide polymorphisms (SNPs) were included in the GWAS. Data were analyzed both at the single SNP and gene levels using the GEMMA and GATES methods, respectively. -

Variation in Protein Coding Genes Identifies Information Flow
bioRxiv preprint doi: https://doi.org/10.1101/679456; this version posted June 21, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Animal complexity and information flow 1 1 2 3 4 5 Variation in protein coding genes identifies information flow as a contributor to 6 animal complexity 7 8 Jack Dean, Daniela Lopes Cardoso and Colin Sharpe* 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Institute of Biological and Biomedical Sciences 25 School of Biological Science 26 University of Portsmouth, 27 Portsmouth, UK 28 PO16 7YH 29 30 * Author for correspondence 31 [email protected] 32 33 Orcid numbers: 34 DLC: 0000-0003-2683-1745 35 CS: 0000-0002-5022-0840 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Abstract bioRxiv preprint doi: https://doi.org/10.1101/679456; this version posted June 21, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Animal complexity and information flow 2 1 Across the metazoans there is a trend towards greater organismal complexity. How 2 complexity is generated, however, is uncertain. Since C.elegans and humans have 3 approximately the same number of genes, the explanation will depend on how genes are 4 used, rather than their absolute number. -

SWI/SNF Chromatin-Remodeling Complexes Function in Noncoding RNA-Dependent Assembly of Nuclear Bodies
SWI/SNF chromatin-remodeling complexes function in noncoding RNA-dependent assembly of nuclear bodies Tetsuya Kawaguchia, Akie Tanigawab, Takao Naganumac, Yasuyuki Ohkawad, Sylvie Souqueree, Gerard Pierrone, and Tetsuro Hirosea,1 aInstitute for Genetic Medicine, Hokkaido University, Sapporo 060-0815, Japan; bRIKEN Center for Developmental Biology, Kobe 650-0047, Japan; cSchool of Life and Environmental Science, University of Tsukuba, Tsukuba 305-8572, Japan; dFaculty of Medicine, Kyushu University, Fukuoka 812-8582, Japan; and eCentre National de la Recherche Scientifique, UMR-8122, Institut Gustave Roussy, Villejuif 94805, France Edited by Joan A. Steitz, Howard Hughes Medical Institute, Yale University, New Haven, CT, and approved March 3, 2015 (received for review December 12, 2014) Paraspeckles are subnuclear structures that form around nuclear canonically polyadenylated NEAT1_1 isoform and a noncanonically paraspeckle assembly transcript 1 (NEAT1) long noncoding RNA processed NEAT1_2 isoform (6, 7, 14). Whereas NEAT1_2 is (lncRNA). Recently, paraspeckles were shown to be functional nu- required for de novo paraspeckle construction, NEAT1_1 is not clear bodies involved in stress responses and the development of required for this process (6, 14, 15). Extensive RNAi analyses of specific organs. Paraspeckle formation is initiated by transcription 40 paraspeckle proteins (PSPs) revealed that seven PSPs, namely of the NEAT1 chromosomal locus and proceeds in conjunction with heterogeneous nuclear RNP K (HNRNPK), NONO, RNA- NEAT1 lncRNA biogenesis and a subsequent assembly step involv- binding motif protein 14 (RBM14), SFPQ, DAZ-associated ing >40 paraspeckle proteins (PSPs). In this study, subunits of protein 1 (DAZAP1), fused in sarcoma (FUS), and HNRNPH3, SWItch/Sucrose NonFermentable (SWI/SNF) chromatin-remodeling are essential for paraspeckle formation (14). -

Nudt21 (NM 026623) Mouse Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for MG202679 Nudt21 (NM_026623) Mouse Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: Nudt21 (NM_026623) Mouse Tagged ORF Clone Tag: TurboGFP Symbol: Nudt21 Synonyms: 25kDa; 3110048P04Rik; 5730530J16Rik; AU014860; AW549947; Cpsf5 Vector: pCMV6-AC-GFP (PS100010) E. coli Selection: Ampicillin (100 ug/mL) Cell Selection: Neomycin ORF Nucleotide >MG202679 representing NM_026623 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGTCTGTGGTGCCGCCCAATCGCTCGCAGACGGGCTGGCCCCGGGGGGTCAACCAGTTCGGCAACAAGT ACATCCAGCAGACCAAGCCCCTCACCCTGGAGCGCACCATTAATCTGTACCCGCTTACCAATTATACTTT TGGTACAAAGGAGCCCCTCTATGAGAAGGACAGCTCTGTTGCAGCCAGATTTCAGCGCATGAGGGAGGAA TTTGATAAGATTGGGATGAGAAGGACTGTAGAAGGGGTTCTGATTGTTCATGAACACCGCCTGCCCCACG TGCTCCTGCTGCAGCTGGGGACAACTTTCTTCAAATTACCTGGTGGGGAACTTAACCCAGGAGAAGATGA AGTTGAAGGACTAAAACGCTTAATGACAGAGATACTTGGTCGTCAAGATGGAGTCCTGCAAGACTGGGTC ATTGATGACTGCATTGGGAACTGGTGGAGACCAAATTTTGAACCTCCTCAGTATCCGTATATTCCTGCAC ATATAACAAAACCCAAGGAACATAAGAAGTTGTTTCTGGTTCAGCTTCAAGAGAAAGCCTTGTTTGCAGT CCCTAAAAATTACAAGCTGGTAGCTGCACCATTGTTTGAGCTGTATGACAATGCACCGGGGTATGGACCC ATCATTTCTAGTCTTCCTCAGCTGCTGAGCAGGTTCAATTTTATATACAAC ACGCGTACGCGGCCGCTCGAG - GFP Tag - GTTTAA Protein Sequence: >MG202679 representing NM_026623 Red=Cloning site Green=Tags(s) MSVVPPNRSQTGWPRGVNQFGNKYIQQTKPLTLERTINLYPLTNYTFGTKEPLYEKDSSVAARFQRMREE -

The C. Elegans 3′ Utrome V2 Resource for Studying Mrna Cleavage and Polyadenylation, 3′-UTR Biology, and Mirna Targeting
Downloaded from genome.cshlp.org on October 8, 2021 - Published by Cold Spring Harbor Laboratory Press Resource The C. elegans 3′ UTRome v2 resource for studying mRNA cleavage and polyadenylation, 3′-UTR biology, and miRNA targeting Hannah S. Steber,1,2 Christina Gallante,3 Shannon O’Brien,2 Po-Lin Chiu,4 and Marco Mangone1,2,5 1Molecular and Cellular Biology Graduate Program, School of Life Sciences, Tempe, Arizona 85287; 2Virginia G. Piper Center for Personalized Diagnostics, The Biodesign Institute at Arizona State University, Tempe, Arizona 85281, USA; 3Barrett, The Honors College, Arizona State University, Tempe, Arizona 85281, USA; 4Center for Applied Structural Discovery, The Biodesign Institute at Arizona State University, Tempe, Arizona 85287, USA 3′ Untranslated regions (3′ UTRs) of mRNAs emerged as central regulators of cellular function because they contain im- portant but poorly characterized cis-regulatory elements targeted by a multitude of regulatory factors. The model nema- tode Caenorhabditis elegans is ideal to study these interactions because it possesses a well-defined 3′ UTRome. To improve its annotation, we have used a genome-wide bioinformatics approach to download raw transcriptome data for 1088 transcrip- tome data sets corresponding to the entire collection of C. elegans trancriptomes from 2015 to 2018 from the Sequence Read Archive at the NCBI. We then extracted and mapped high-quality 3′-UTR data at ultradeep coverage. Here, we describe and release to the community the updated version of the worm 3′ UTRome, which we named 3′ UTRome v2. This resource contains high-quality 3′-UTR data mapped at single-base ultraresolution for 23,084 3′-UTR isoform variants corresponding to 14,788 protein-coding genes and is updated to the latest release of WormBase. -

1 DUX4 Regulates Oocyte to Embryo Transition in Human 1 2 Sanna
bioRxiv preprint doi: https://doi.org/10.1101/732289; this version posted August 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 DUX4 regulates oocyte to embryo transition in human 2 3 Sanna Vuoristo1,2#*, Christel Hydén-Granskog3, Masahito Yoshihara1, Lisa 4 Gawriyski4, Anastassius Damdimopoulos5, Shruti Bhagat1,6, Kosuke Hashimoto6, 5 Kaarel Krjutškov1,7,8, Sini Ezer8,9, Priit Paluoja7, Karolina Lundin2, Pauliina 6 Paloviita2, Gaëlle Recher10, Vipin Ranga11, Tomi Airenne11, Mahlet Tamirat11, Eeva- 7 Mari Jouhilahti8, Timo Otonkoski8, Juha S. Tapanainen2,3,12, Hideya Kawaji6,13,14, 8 Yasuhiro Murakawa6,15, Thomas R. Bürglin16, Markku Varjosalo4, Mark S. Johnson11, 9 Timo Tuuri2, 3, Shintaro Katayama1,9* and Juha Kere1,8,9 * 10 11 1Karolinska Institutet, Department of Biosciences and Nutrition, Huddinge, Sweden 12 2University of Helsinki, Department of Obstetrics and Gynecology, Helsinki, Finland 13 3Helsinki University Hospital, Department of Obstetrics and Gynecology, Helsinki, 14 Finland 15 4University of Helsinki, Institute of Biotechnology, Helsinki, Finland 16 5Karolinska Institutet, Bioinformatics and Expression Analysis Core Facility, 17 Huddinge, Sweden 18 6RIKEN Center for Integrative Medical Sciences, Yokohama, Japan 19 7Competence Centre for Health Technologies, Tartu, Estonia 20 8 Stem Cells and Metabolism Research Program, University of Helsinki, Finland 21 9Folkhälsan Research Center, Helsinki, Finland 1 bioRxiv preprint doi: https://doi.org/10.1101/732289; this version posted August 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity.