AEZ V5: Authenticated Encryption by Enciphering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MD5 Collisions the Effect on Computer Forensics April 2006
Paper MD5 Collisions The Effect on Computer Forensics April 2006 ACCESS DATA , ON YOUR RADAR MD5 Collisions: The Impact on Computer Forensics Hash functions are one of the basic building blocks of modern cryptography. They are used for everything from password verification to digital signatures. A hash function has three fundamental properties: • It must be able to easily convert digital information (i.e. a message) into a fixed length hash value. • It must be computationally impossible to derive any information about the input message from just the hash. • It must be computationally impossible to find two files to have the same hash. A collision is when you find two files to have the same hash. The research published by Wang, Feng, Lai and Yu demonstrated that MD5 fails this third requirement since they were able to generate two different messages that have the same hash. In computer forensics hash functions are important because they provide a means of identifying and classifying electronic evidence. Because hash functions play a critical role in evidence authentication, a judge and jury must be able trust the hash values to uniquely identify electronic evidence. A hash function is unreliable when you can find any two messages that have the same hash. Birthday Paradox The easiest method explaining a hash collision is through what is frequently referred to as the Birthday Paradox. How many people one the street would you have to ask before there is greater than 50% probability that one of those people will share your birthday (same day not the same year)? The answer is 183 (i.e. -

Key Agreement from Weak Bit Agreement
Key Agreement from Weak Bit Agreement Thomas Holenstein Department of Computer Science Swiss Federal Institute of Technology (ETH) Zurich, Switzerland [email protected] ABSTRACT In cryptography, much study has been devoted to find re- Assume that Alice and Bob, given an authentic channel, lations between different such assumptions and primitives. For example, Impagliazzo and Luby show in [9] that imple- have a protocol where they end up with a bit SA and SB , respectively, such that with probability 1+ε these bits are mentations of essentially all non-trivial cryptographic tasks 2 imply the existence of one-way functions. On the other equal. Further assume that conditioned on the event SA = hand, many important primitives can be realized if one-way SB no polynomial time bounded algorithm can predict the δ functions exist. Examples include pseudorandom generators bit better than with probability 1 − 2 . Is it possible to obtain key agreement from such a primitive? We show that [7], pseudorandom functions [5], and pseudorandom permu- 1−ε tations [12]. for constant δ and ε the answer is yes if and only if δ > 1+ε , both for uniform and non-uniform adversaries. For key agreement no such reduction to one-way functions The main computational technique used in this paper is a is known. In fact, in [10] it is shown that such a reduction strengthening of Impagliazzo’s hard-core lemma to the uni- must be inherently non-relativizing, and thus it seems very form case and to a set size parameter which is tight (i.e., hard to find such a construction. -

Network Security Chapter 8
Network Security Chapter 8 Network security problems can be divided roughly into 4 closely intertwined areas: secrecy (confidentiality), authentication, nonrepudiation, and integrity control. Question: what does non-repudiation mean? What does “integrity” mean? • Cryptography • Symmetric-Key Algorithms • Public-Key Algorithms • Digital Signatures • Management of Public Keys • Communication Security • Authentication Protocols • Email Security -- skip • Web Security • Social Issues -- skip Revised: August 2011 CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Network Security Security concerns a variety of threats and defenses across all layers Application Authentication, Authorization, and non-repudiation Transport End-to-end encryption Network Firewalls, IP Security Link Packets can be encrypted on data link layer basis Physical Wireless transmissions can be encrypted CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Network Security (1) Some different adversaries and security threats • Different threats require different defenses CN5E by Tanenbaum & Wetherall, © Pearson Education-Prentice Hall and D. Wetherall, 2011 Cryptography Cryptography – 2 Greek words meaning “Secret Writing” Vocabulary: • Cipher – character-for-character or bit-by-bit transformation • Code – replaces one word with another word or symbol Cryptography is a fundamental building block for security mechanisms. • Introduction » • Substitution ciphers » • Transposition ciphers » • One-time pads -

Modes of Operation for Compressed Sensing Based Encryption
Modes of Operation for Compressed Sensing based Encryption DISSERTATION zur Erlangung des Grades eines Doktors der Naturwissenschaften Dr. rer. nat. vorgelegt von Robin Fay, M. Sc. eingereicht bei der Naturwissenschaftlich-Technischen Fakultät der Universität Siegen Siegen 2017 1. Gutachter: Prof. Dr. rer. nat. Christoph Ruland 2. Gutachter: Prof. Dr.-Ing. Robert Fischer Tag der mündlichen Prüfung: 14.06.2017 To Verena ... s7+OZThMeDz6/wjq29ACJxERLMATbFdP2jZ7I6tpyLJDYa/yjCz6OYmBOK548fer 76 zoelzF8dNf /0k8H1KgTuMdPQg4ukQNmadG8vSnHGOVpXNEPWX7sBOTpn3CJzei d3hbFD/cOgYP4N5wFs8auDaUaycgRicPAWGowa18aYbTkbjNfswk4zPvRIF++EGH UbdBMdOWWQp4Gf44ZbMiMTlzzm6xLa5gRQ65eSUgnOoZLyt3qEY+DIZW5+N s B C A j GBttjsJtaS6XheB7mIOphMZUTj5lJM0CDMNVJiL39bq/TQLocvV/4inFUNhfa8ZM 7kazoz5tqjxCZocBi153PSsFae0BksynaA9ZIvPZM9N4++oAkBiFeZxRRdGLUQ6H e5A6HFyxsMELs8WN65SCDpQNd2FwdkzuiTZ4RkDCiJ1Dl9vXICuZVx05StDmYrgx S6mWzcg1aAsEm2k+Skhayux4a+qtl9sDJ5JcDLECo8acz+RL7/ ovnzuExZ3trm+O 6GN9c7mJBgCfEDkeror5Af4VHUtZbD4vALyqWCr42u4yxVjSj5fWIC9k4aJy6XzQ cRKGnsNrV0ZcGokFRO+IAcuWBIp4o3m3Amst8MyayKU+b94VgnrJAo02Fp0873wa hyJlqVF9fYyRX+couaIvi5dW/e15YX/xPd9hdTYd7S5mCmpoLo7cqYHCVuKWyOGw ZLu1ziPXKIYNEegeAP8iyeaJLnPInI1+z4447IsovnbgZxM3ktWO6k07IOH7zTy9 w+0UzbXdD/qdJI1rENyriAO986J4bUib+9sY/2/kLlL7nPy5Kxg3 Et0Fi3I9/+c/ IYOwNYaCotW+hPtHlw46dcDO1Jz0rMQMf1XCdn0kDQ61nHe5MGTz2uNtR3bty+7U CLgNPkv17hFPu/lX3YtlKvw04p6AZJTyktsSPjubqrE9PG00L5np1V3B/x+CCe2p niojR2m01TK17/oT1p0enFvDV8C351BRnjC86Z2OlbadnB9DnQSP3XH4JdQfbtN8 BXhOglfobjt5T9SHVZpBbzhDzeXAF1dmoZQ8JhdZ03EEDHjzYsXD1KUA6Xey03wU uwnrpTPzD99cdQM7vwCBdJnIPYaD2fT9NwAHICXdlp0pVy5NH20biAADH6GQr4Vc -

Identifying Open Research Problems in Cryptography by Surveying Cryptographic Functions and Operations 1
International Journal of Grid and Distributed Computing Vol. 10, No. 11 (2017), pp.79-98 http://dx.doi.org/10.14257/ijgdc.2017.10.11.08 Identifying Open Research Problems in Cryptography by Surveying Cryptographic Functions and Operations 1 Rahul Saha1, G. Geetha2, Gulshan Kumar3 and Hye-Jim Kim4 1,3School of Computer Science and Engineering, Lovely Professional University, Punjab, India 2Division of Research and Development, Lovely Professional University, Punjab, India 4Business Administration Research Institute, Sungshin W. University, 2 Bomun-ro 34da gil, Seongbuk-gu, Seoul, Republic of Korea Abstract Cryptography has always been a core component of security domain. Different security services such as confidentiality, integrity, availability, authentication, non-repudiation and access control, are provided by a number of cryptographic algorithms including block ciphers, stream ciphers and hash functions. Though the algorithms are public and cryptographic strength depends on the usage of the keys, the ciphertext analysis using different functions and operations used in the algorithms can lead to the path of revealing a key completely or partially. It is hard to find any survey till date which identifies different operations and functions used in cryptography. In this paper, we have categorized our survey of cryptographic functions and operations in the algorithms in three categories: block ciphers, stream ciphers and cryptanalysis attacks which are executable in different parts of the algorithms. This survey will help the budding researchers in the society of crypto for identifying different operations and functions in cryptographic algorithms. Keywords: cryptography; block; stream; cipher; plaintext; ciphertext; functions; research problems 1. Introduction Cryptography [1] in the previous time was analogous to encryption where the main task was to convert the readable message to an unreadable format. -

The Design and Evolution Of
J Cryptol (2021) 34:36 https://doi.org/10.1007/s00145-021-09399-8 The Design and Evolution of OCB Ted Krovetz Computer Science Department, California State University, 6000 J Street, Sacramento, California 95819, USA [email protected] Phillip Rogaway Department of Computer Science, Kemper Hall of Engineering, University of California, Davis, California 95616, USA [email protected] Communicated by Tetsu Iwata. Received 20 December 2019 / Revised 26 August 2020 / Accepted 14 September 2020 Abstract. We describe OCB3, the final version of OCB, a blockcipher mode for au- thenticated encryption (AE). We prove the construction secure, up to the birthday bound, assuming its underlying blockcipher is secure as a strong-PRP. We study the scheme’s software performance, comparing its speed, on multiple platforms, to a variety of other AE schemes. We reflect on the history and development of the mode. Keywords. AEAD, Authenticated encryption, CAESAR competition, Cryptographic standards, Fast software encryption, Modes of operation, OCB. 1. Introduction Schemes for authenticated encryption (AE) symmetrically encrypt a message in a way that ensures both its confidentiality and authenticity. OCB is a well-known algorithm for achieving this aim. It is a blockcipher mode of operation, the blockcipher usually being AES. There are three main variants of OCB. The first, now called OCB1 (2001) [39], was mo- tivated by Charanjit Jutla’s IAPM [24]. A second version, now called OCB2 (2004) [18, 38], added support for associated data (AD) [37] and redeveloped the mode using the idea of a tweakable blockcipher [30]. OCB2 was recently found to have a disastrous bug [17]. -

Investigation of Ice Particle Habits to Be Used for Ice Cloud Remote Sensing for the GCOM-C Satellite Mission
Atmos. Chem. Phys., 16, 12287–12303, 2016 www.atmos-chem-phys.net/16/12287/2016/ doi:10.5194/acp-16-12287-2016 © Author(s) 2016. CC Attribution 3.0 License. Investigation of ice particle habits to be used for ice cloud remote sensing for the GCOM-C satellite mission Husi Letu1,2, Hiroshi Ishimoto3, Jerome Riedi4, Takashi Y. Nakajima1, Laurent C.-Labonnote4, Anthony J. Baran5, Takashi M. Nagao6, and Miho Sekiguchi7 1Research and Information Center (TRIC), Tokai University, 4-1-1 Kitakaname Hiratsuka, Kanagawa 259-1292, Japan 2Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences (CAS), DaTun Road No. 20 (North), Beijing 100101, China 3Meteorological Research Institute, 1-1 Nagamine, Tsukuba, Ibaraki 305-0052, Japan 4Laboratoire d’Optique Atmosphérique, UMR CNRS 8518, Université de Lille 1-Sciences et Technologies, Villeneuve d’Ascq, France 5Met Office, Fitzroy Road, Exeter, EX1 3PB, UK 6Earth Observation Research Center (EORC), Japan Aerospace Exploration Agency (JAXA), 2-1-1 Sengen Tsukuba, Ibaraki 305-8505, Japan 7Tokyo University of Marine Science and Technology, Tokyo 135-8533, Japan Correspondence to: Takashi Y. Nakajima ([email protected]) Received: 29 September 2015 – Published in Atmos. Chem. Phys. Discuss.: 11 November 2015 Revised: 10 September 2016 – Accepted: 15 September 2016 – Published: 29 September 2016 Abstract. In this study, various ice particle habits are in- phase matrix. The characteristics of calculated extinction ef- vestigated in conjunction with inferring the optical proper- ficiency, single-scattering albedo, and asymmetry factor of ties of ice clouds for use in the Global Change Observa- the five ice particle habits are compared. -

Generic Attacks Against Beyond-Birthday-Bound Macs
Generic Attacks against Beyond-Birthday-Bound MACs Gaëtan Leurent1, Mridul Nandi2, and Ferdinand Sibleyras1 1 Inria, France {gaetan.leurent,ferdinand.sibleyras}@inria.fr 2 Indian Statistical Institute, Kolkata [email protected] Abstract. In this work, we study the security of several recent MAC constructions with provable security beyond the birthday bound. We con- sider block-cipher based constructions with a double-block internal state, such as SUM-ECBC, PMAC+, 3kf9, GCM-SIV2, and some variants (LightMAC+, 1kPMAC+). All these MACs have a security proof up to 22n/3 queries, but there are no known attacks with less than 2n queries. We describe a new cryptanalysis technique for double-block MACs based on finding quadruples of messages with four pairwise collisions in halves of the state. We show how to detect such quadruples in SUM-ECBC, PMAC+, 3kf9, GCM-SIV2 and their variants with O(23n/4) queries, and how to build a forgery attack with the same query complexity. The time com- plexity of these attacks is above 2n, but it shows that the schemes do not reach full security in the information theoretic model. Surprisingly, our attack on LightMAC+ also invalidates a recent security proof by Naito. Moreover, we give a variant of the attack against SUM-ECBC and GCM-SIV2 with time and data complexity O˜(26n/7). As far as we know, this is the first attack with complexity below 2n against a deterministic beyond- birthday-bound secure MAC. As a side result, we also give a birthday attack against 1kf9, a single-key variant of 3kf9 that was withdrawn due to issues with the proof. -
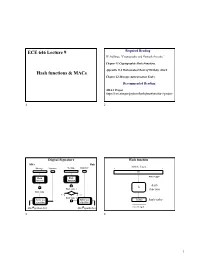
Hash Functions & Macs ECE 646 Lecture 9
ECE 646 Lecture 9 Required Reading W. Stallings, "Cryptography and Network-Security,” Chapter 11 Cryptographic Hash Functions Appendix 11A Mathematical Basis of Birthday Attack Hash functions & MACs Chapter 12 Message Authentication Codes Recommended Reading SHA-3 Project https://csrc.nist.gov/projects/hash-functions/sha-3-project 1 2 Digital Signature Hash function Alice Bob arbitrary length Message Signature Message Signature m message Hash Hash function function hash h Hash value 1 function Hash value yes no Hash value 2 Public key Public key h(m) hash value algorithm algorithm fixed length Alice’s private key Alice’s public key 3 4 1 Vocabulary Hash functions Basic requirements hash function hash value 1. Public description, NO key message digest message digest hash total 2. Compression fingerprint arbitrary length input ® fixed length output imprint 3. Ease of computation cryptographic checksum compressed encoding MDC, Message Digest Code 5 6 Hash functions Hash functions Security requirements Dependence between requirements It is computationally infeasible Given To Find 1. Preimage resistance 2nd preimage resistant y x, such that h(x) = y collision resistant 2. 2nd preimage resistance x’ ¹ x, such that x and y=h(x) h(x’) = h(x) = y 3. Collision resistance x’ ¹ x, such that h(x’) = h(x) 7 8 2 Hash functions Brute force attack against (unkeyed) One-Way Hash Function Given y mi’ One-Way Collision-Resistant i=1..2n Hash Functions Hash Functions 2n messages with the contents required by the forger OWHF CRHF h preimage resistance ? 2nd preimage resistance h(mi’) = y collision resistance n - bits 9 10 Creating multiple versions of Brute force attack against Yuval the required message Collision Resistant Hash Function state thereby borrowed I confirm - that I received r messages r messages acceptable for the signer required by the forger $10,000 Mr. -

Hash Function Luffa Supporting Document
Hash Function Luffa Supporting Document Christophe De Canni`ere ESAT-COSIC, Katholieke Universiteit Leuven Hisayoshi Sato, Dai Watanabe Systems Development Laboratory, Hitachi, Ltd. 15 September 2009 Copyright °c 2008-2009 Hitachi, Ltd. All rights reserved. 1 Luffa Supporting Document NIST SHA3 Proposal (Round 2) Contents 1 Introduction 4 1.1 Updates of This Document .................... 4 1.2 Organization of This Document ................. 4 2 Design Rationale 5 2.1 Chaining .............................. 5 2.2 Non-Linear Permutation ..................... 6 2.2.1 Sbox in SubCrumb ..................... 6 2.2.2 MixWord .......................... 7 2.2.3 Constants ......................... 9 2.2.4 Number of Steps ..................... 9 2.2.5 Tweaks .......................... 9 3 Security Analysis of Permutation 10 3.1 Basic Properties .......................... 10 3.1.1 Sbox S (Luffav2) ..................... 10 3.1.2 Differential Propagation . 11 3.2 Collision Attack Based on A Differential Path . 13 3.2.1 General Discussion .................... 13 3.2.2 How to Find A Collision for 5 Steps without Tweaks . 14 3.3 Birthday Problem on The Unbalanced Function . 15 3.4 Higher Order Differential Distinguisher . 15 3.4.1 Higher Order Difference . 16 3.4.2 Higher Order Differential Attack on Luffav1 . 16 3.4.3 Higher Order Differential Property of Qj of Luffav2 . 17 3.4.4 Higher Order Differential Attack on Luffav2 . 18 4 Security Analysis of Chaining 18 4.1 Basic Properties of The Message Injection Functions . 20 4.2 First Naive Attack ........................ 21 4.2.1 Long Message Attack to Find An Inner Collision . 21 4.2.2 How to Reduce The Message Length . 21 4.2.3 Complexity of The Naive Attack . -

International Journal of Advance Engineering and Research Development Birthday Attack on Cryptography Applications
International Journal of Advance Engineering and Research Development Scientific Journal of Impact Factor (SJIF): 4.72 Special Issue SIEICON-2017,April -2017 e-ISSN : 2348-4470 p-ISSN : 2348-6406 Birthday Attack on Cryptography Applications Concept and Real Time Uses Keyur Patel1, Digvijaysinh Mahida2 1Asst. Prof. Department of Information Technology, Sigma Institute of Engineering 2 Asst. Prof. Department of Information Technology, Sigma Institute of Engineering Abstract — In many network communications it is crucial to be able to authenticate both the contents and the origin of a message. This paper will study in detail the problem known in probability theory as the Birthday Paradox (or the Birthday problem), as well as its implications and different related aspects we consider relevant. The Birthday attack makes use of what’s known as the Birthday paradox to try to attack cryptographic hash functions. Among other desirable properties of hash functions, an interesting one is that it should be collision-resistant, that is it should be difficult to find two messages with the same hash value. To find a collision the birthday attack is used, which shows that attacker may not need to examine too many messages before he finds a collision. The purpose of this paper is thus to give the reader a general overview of the general aspects and applications of the Birthday Paradox. Keywords-Birthday Paradox, Hash Function, Cryptography Algorithm, Application. I. INTRODUCTION Computer networks are used today for many applications (like banking, e-government etc.) where security is an absolute necessary. Changing or stealing data stored in electronic form is so widely spread that not having cryptographic tools to preserve the safety of information would make pointless any serious communication or data exchange. -

Cryptographic Hash Functions
Cryptographic Hash Functions Chester Rebeiro IIT Madras CR STINSON : chapter4 Issues with Integrity Alice unsecure channel Bob “Attack at Dusk!!” Message “Attack at Dawn!!” Change ‘Dawn’ to ‘Dusk’ How can Bob ensure that Alice’s message has not been modified? Note…. We are not concerned with confidentiality here CR 2 Hashes y = h(x) Alice Bob “Message digest” h secure channel = “Attack at Dawn!!” h “Attack at Dawn!!” Message unsecure channel “Attack at Dawn!!” Alice passes the message through a hash function, which produces a fixed length message digest. • The message digest is representative of Alice’s message. • Even a small change in the message will result in a completely new message digest • Typically of 160 bits, irrespective of the message size. Bob re-computes a message hash and verifies the digest with Alice’s message digest. CR 3 Integrity with Hashes y = h(x) Alice Bob “Message digest” h secure channel = “Attack at Dawn!!” h “Attack at Dawn!!” Message insecure channel “Attack at Dawn!!” Mallory does not have access to the digest y. Her task (to modify Alice’s message) is much y = h(x) more difficult. y = h(x’) If she modifies x to x’, the modification can be detected unless h(x) = h(x’) Hash functions are specially designed to resist such collisions CR 4 Message Authentication Codes (MAC) y = h (x) Alice K Bob K hK = “Attack at Dawn!!” Message Digest h K Message unsecure channel K “Attack at Dawn!!” MACs allow the message and the digest to be sent over an insecure channel However, it requires Alice and Bob to share a common key CR 5 Avalanche Effect Short Message Hash fixed length also called M Function digest ‘hash’ Hash functions provide unique digests with high probability.