Pdf Field Stands on a Separate Tier
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FREQUENCY EFFECTS on ESL COMPOSITIONAL MULTI-WORD SEQUENCE PROCESSING by Sarut Supasiraprapa a DISSERTATION Submitted to Michiga
FREQUENCY EFFECTS ON ESL COMPOSITIONAL MULTI-WORD SEQUENCE PROCESSING By Sarut Supasiraprapa A DISSERTATION Submitted to Michigan State University in partial fulfillment of the requirements for the degree of Second Language Studies – Doctor of Philosophy 2017 ABSTRACT FREQUENCY EFFECTS ON ESL COMPOSITIONAL MULTI-WORD SEQUENCE PROCESSING By Sarut Supasiraprapa The current study investigated whether adult native English speakers and English- as-a-second-language (ESL) learners exhibit sensitivity to compositional English multi- word sequences, which have a meaning derivable from word parts (e.g., don’t have to worry as opposed to sequences like He left the US for good, where for good cannot be taken apart to derive its meaning). In the current study, a multi-word sequence specifically referred to a word sequence beyond the bigram (two-word) level. The investigation was motivated by usage-based approaches to language acquisition, which predict that first (L1) and second (L2) speakers should process more frequent compositional phrases faster than less frequent ones (e.g., Bybee, 2010; Ellis, 2002; Gries & Ellis, 2015). This prediction differs from the prediction in the mainstream generative linguistics theory, according to which frequency effects should be observed from the processing of items stored in the mental lexicon (i.e., bound morphemes, single words, and idioms), but not from compositional phrases (e.g., Prasada & Pinker, 1993; Prasada, Pinker, & Snyder, 1990). The present study constituted the first attempt to investigate frequency effects on multi-word sequences in both language comprehension and production in the same L1 and L2 speakers. The study consisted of two experiments. In the first, participants completed a timed phrasal-decision task, in which they decided whether four-word target phrases were possible English word sequences. -

Talk Bank: a Multimodal Database of Communicative Interaction
Talk Bank: A Multimodal Database of Communicative Interaction 1. Overview The ongoing growth in computer power and connectivity has led to dramatic changes in the methodology of science and engineering. By stimulating fundamental theoretical discoveries in the analysis of semistructured data, we can to extend these methodological advances to the social and behavioral sciences. Specifically, we propose the construction of a major new tool for the social sciences, called TalkBank. The goal of TalkBank is the creation of a distributed, web- based data archiving system for transcribed video and audio data on communicative interactions. We will develop an XML-based annotation framework called Codon to serve as the formal specification for data in TalkBank. Tools will be created for the entry of new and existing data into the Codon format; transcriptions will be linked to speech and video; and there will be extensive support for collaborative commentary from competing perspectives. The TalkBank project will establish a framework that will facilitate the development of a distributed system of allied databases based on a common set of computational tools. Instead of attempting to impose a single uniform standard for coding and annotation, we will promote annotational pluralism within the framework of the abstraction layer provided by Codon. This representation will use labeled acyclic digraphs to support translation between the various annotation systems required for specific sub-disciplines. There will be no attempt to promote any single annotation scheme over others. Instead, by promoting comparison and translation between schemes, we will allow individual users to select the custom annotation scheme most appropriate for their purposes. -

Towards a Practical Phonology of Korean
Towards a practical phonology of Korean Research Master programme in Linguistics Leiden University Graduation thesis Lorenzo Oechies Supervisor: Dr. J.M. Wiedenhof Second reader: Dr. A.R. Nam June 1, 2020 The blue silhouette of the Korean peninsula featured on the front page of this thesis is taken from the Korean Unification Flag (Wikimedia 2009), which is used to represent both North and South Korea. Contents Introduction ..................................................................................................................................................... iii 0. Conventions ............................................................................................................................................... vii 0.1 Romanisation ........................................................................................................................................................ vii 0.2 Glosses .................................................................................................................................................................... viii 0.3 Symbols .................................................................................................................................................................. viii 0.4 Phonetic transcription ........................................................................................................................................ ix 0.5 Phonemic transcription..................................................................................................................................... -

International Computer Science Institute Activity Report 2007
International Computer Science Institute Activity Report 2007 International Computer Science Institute, 1947 Center Street, Suite 600, Berkeley, CA 94704-1198 USA phone: (510) 666 2900 (510) fax: 666 2956 [email protected] http://www.icsi.berkeley.edu PRINCIPAL 2007 SPONSORS Cisco Defense Advanced Research Projects Agency (DARPA) Disruptive Technology Offi ce (DTO, formerly ARDA) European Union (via University of Edinburgh) Finnish National Technology Agency (TEKES) German Academic Exchange Service (DAAD) Google IM2 National Centre of Competence in Research, Switzerland Microsoft National Science Foundation (NSF) Qualcomm Spanish Ministry of Education and Science (MEC) AFFILIATED 2007 SPONSORS Appscio Ask AT&T Intel National Institutes of Health (NIH) SAP Volkswagen CORPORATE OFFICERS Prof. Nelson Morgan (President and Institute Director) Dr. Marcia Bush (Vice President and Associate Director) Prof. Scott Shenker (Secretary and Treasurer) BOARD OF TRUSTEES, JANUARY 2008 Prof. Javier Aracil, MEC and Universidad Autónoma de Madrid Prof. Hervé Bourlard, IDIAP and EPFL Vice Chancellor Beth Burnside, UC Berkeley Dr. Adele Goldberg, Agile Mind, Inc. and Pharmaceutrix, Inc. Dr. Greg Heinzinger, Qualcomm Mr. Clifford Higgerson, Walden International Prof. Richard Karp, ICSI and UC Berkeley Prof. Nelson Morgan, ICSI (Director) and UC Berkeley Dr. David Nagel, Ascona Group Prof. Prabhakar Raghavan, Stanford and Yahoo! Prof. Stuart Russell, UC Berkeley Computer Science Division Chair Mr. Jouko Salo, TEKES Prof. Shankar Sastry, UC Berkeley, Dean -

The Morphosyntax of Jejuan – Ko Clause Linkages
The Morphosyntax of Jejuan –ko Clause Linkages † Soung-U Kim SOAS University of London ABSTRACT While clause linkage is a relatively understudied area within Koreanic linguistics, the Korean –ko clause linkage has been studied more extensively. Authors have deemed it interesting since depending on the successive/non-successive interpretation of its events, a –ko clause linkage exhibits all or no properties of what is traditionally known as coordination or subordination. Jejuan –ko clauses may look fairly similar to Korean on the surface, and exhibit a similar lack of semantic specification. This study shows that the traditional, dichotomous coordination-subordination opposition is not applicable to Jejuan –ko clauses. I propose that instead of applying a-priori categories to the exploration of clause linkage in Koreanic varieties, one should apply a multidimensional model that lets patterns emerge in an inductive way. Keywords: clause linkage, –ko converb, Jejuan, Jejueo, Ceycwu dialect 1. Introduction Koreanic language varieties are well-known for their richness in manifestations of clause linkage, much of which is realised by means of specialised verb forms. Connecting to an ever-growing body of research in functional-typological studies (cf. Haspelmath and König 1995), a number of authors in Koreanic linguistics have adopted the term converb for these forms (Jendraschek and Shin 2011, 2018; Kwon et al. 2006 among others). Languages such as Jejuan (Song S-J 2011) or Korean (Sohn H-M 2009) make extensive use of an unusually high number of converbs, connecting clauses within a larger sentence structure which may correspond to * This work was supported by the Laboratory Programme for Korean Studies through the Ministry of Education of the Republic of Korea and Korean Studies Promotion Service of the Academy of Korean Studies (AKS-2016-LAB-2250003), the Endangered Languages Documentation Programme of the Arcadia Fund (IGS0208), as well as the British Arts and Humanities Research Council. -

A Resource of Corpus-Derived Typed Predicate Argument Structures for Croatian
CROATPAS: A Resource of Corpus-derived Typed Predicate Argument Structures for Croatian Costanza Marini Elisabetta Ježek University of Pavia University of Pavia Department of Humanities Department of Humanities costanza.marini01@ [email protected] universitadipavia.it Abstract 2014). The potential uses and purposes of the resource range from multilingual The goal of this paper is to introduce pattern linking between compatible CROATPAS, the Croatian sister project resources to computer-assisted language of the Italian Typed-Predicate Argument learning (CALL). Structure resource (TPAS1, Ježek et al. 2014). CROATPAS is a corpus-based 1 Introduction digital collection of verb valency structures with the addition of semantic Nowadays, we live in a time when digital tools type specifications (SemTypes) to each and resources for language technology are argument slot, which is currently being constantly mushrooming all around the world. developed at the University of Pavia. However, we should remind ourselves that some Salient verbal patterns are discovered languages need our attention more than others if following a lexicographical methodology they are not to face – to put it in Rehm and called Corpus Pattern Analysis (CPA, Hegelesevere’s words – “a steadily increasing Hanks 2004 & 2012; Hanks & and rather severe threat of digital extinction” Pustejovsky 2005; Hanks et al. 2015), (2018: 3282). According to the findings of initiatives such as whereas SemTypes – such as [HUMAN], [ENTITY] or [ANIMAL] – are taken from a the META-NET White Paper Series (Tadić et al. shallow ontology shared by both TPAS 2012; Rehm et al. 2014), we can state that and the Pattern Dictionary of English Croatian is unfortunately among the 21 out of 24 Verbs (PDEV2, Hanks & Pustejovsky official languages of the European Union that are 2005; El Maarouf et al. -

2016 Research Enhancement Grant Application (Division of Arts and Humanities)
2016 Research Enhancement Grant Application (Division of Arts and Humanities) Title: The Sound and Grammar of Jeju Korean Name: Seongyeon Ko E-mail: [email protected] Department: Classical, Middle Eastern, and Asian Languages & Cultures PROJECT DESCRIPTION This project aims to collect data of Jeju, an endangered Koreanic language to be used to produce an illustration of its sound structure and further develop a larger project to eventually publish a comprehensive grammar of the language. Jeju Korean Jeju Korean is a regional variety of Korean, spoken mainly on Jeju Island by approximately 5,000 to 10,000 fluent speakers as well as in the Osaka area in Japan by some diasporic Jeju speakers. Traditionally considered a regional dialect of Korean, it is almost unintelligible with other “mainland” varieties of Korean and, therefore, is often treated as a separate language nowadays. In 2010, UNESCO designated it as one of the world’s “critically endangered languages” based on the fact that the Jeju language was spoken largely by elderly speakers in their 70s or older primarily in informal settings and rapidly falling out of use under the influence of Standard Korean. In fact, younger speakers speak a kind of “mixed” language of the Standard Korean and the Jeju Korean. Born and raised in Jeju Island before my college education, I was one of those younger speakers of the “mixed” language. And this is one of the major reasons that I became a linguist who have felt obliged to conduct research on this particular vernacular. Jeju Korean has been of much interest to both historical/comparative linguist group and general linguist group. -

1. Introduction 2. Studies on Jeju and Efforts to Preserve It
An Endangered Language: Jeju Language Yeong-bong Kang Jeju National University 1. Introduction It has been a well-known fact that language is closely connected with both speaker's mind and its local culture. Cultural trait, one of the core properties of language, means that language reflects culture of the society at large. Even though Jeju language samchun 'uncle' is a variation of its standard Korean samchon, it is hard to say that samchun has the same dictionary definition of samchon, the brother of father, especially unmarried. In Jeju, if he/she is older than the speaker, everyone, regardless of his/her sex, can be samchun whether or not he/she is the speaker's relative. It means that Jeju language well reflects local culture and social aspects of Jeju. In other words, Jeju language reflects Jeju culture and society, and it reveals Jeju people's soul. This paper aims to investigate efforts to preserve Jeju language which reflect Jeju people's soul and cultures, processes which Jeju was included in the Atlas of languages in danger by UNESCO, and substantive approaches for preserving Jeju. 2. Studies on Jeju and efforts to preserve it There have been lots of studies on Jeju and efforts to preserve it by individuals, institutions, media, and etc. 2.1 Individual studies on Jeju language and efforts to preserve it Individual studies on Jeju language started with Japanese linguist Ogura Shinpei's Jeju Dialect in 1913. He also presented The Value of Jeju Dialect and Jeju Dialect: Cheong-gu Journal in 1924 and 1931 each. -

Multilingvální Systémy Rozpoznávání Řeči a Jejich Efektivní Učení
Multilingvální systémy rozpoznávání řeči a jejich efektivní učení Disertační práce Studijní program: P2612 – Elektrotechnika a informatika Studijní obor: 2612V045 – Technická kybernetika Autor práce: Ing. Radek Šafařík Vedoucí práce: prof. Ing. Jan Nouza, CSc. Liberec 2020 Multilingual speech recognition systems and their effective learning Dissertation Study programme: P2612 – Electrotechnics and informatics Study branch: 2612V045 – Technical cybernetics Author: Ing. Radek Šafařík Supervisor: prof. Ing. Jan Nouza, CSc. Liberec 2020 Prohlášení Byl jsem seznámen s tím, že na mou disertační práci se plně vztahu- je zákon č. 121/2000 Sb., o právu autorském, zejména § 60 – školní dílo. Beru na vědomí, že Technická univerzita v Liberci (TUL) nezasahu- je do mých autorských práv užitím mé disertační práce pro vnitřní potřebu TUL. Užiji-li disertační práci nebo poskytnu-li licenci k jejímu využi- tí, jsem si vědom povinnosti informovat o této skutečnosti TUL; v tomto případě má TUL právo ode mne požadovat úhradu nákla- dů, které vynaložila na vytvoření díla, až do jejich skutečné výše. Disertační práci jsem vypracoval samostatně s použitím uvedené literatury a na základě konzultací s vedoucím mé disertační práce a konzultantem. Současně čestně prohlašuji, že texty tištěné verze práce a elektro- nické verze práce vložené do IS STAG se shodují. 1. 12. 2020 Ing. Radek Šafařík Abstract The diseratation thesis deals with creation of automatic speech recognition systems (ASR) and with effective adaptation of already existing system to a new language. Today’s ASR systems have modular stucture where individual moduls can be consi- dered as language dependent or independent. The main goal of this thesis is research and development of methods that automate and make the development of language dependent modules effective as much as possible using free available data fromthe internet, machine learning methods and similarities between langages. -
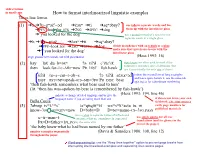
How to Format Interlinearized Linguistic Examples Three-Line Format
abbreviations in small caps How to format interlinearized linguistic examples Three-line format (1) ➜a.➜ʔu–gʷəč’–əd ➜čəxʷ ➜ti ➜sqʷəbayʔ use tabs to separate words and line them up with the interlinear gloss ➜PFV–look.for–ICS ➜2SG ➜SPEC ➜dog ➜‘you looked for the dog’ use a period instead of a space to join separate words in a single gloss ➜b.➜ *ʔu–gʷəč ➜čəxʷ ➜ti ➜sqʷəbayʔ ➜PFV–look.for ➜2SG ➜SPEC ➜dog divide morphemes with an n-dash or a plus; make sure they match one-to-one with the ➜*‘you looked for the dog’ interlinear gloss align glosses with words, not with punctuation (Hess 1993: 16) equal signs are often used to mark clitic- (2) hay la%–du–b=#x" !# ti!i& c’i%c’i% boundaries and other special divisions (but then look.for–LC–MD=now PR DIST fish.hawk use it consistently for only one of these) indent the second line of long examples ti!i& tu=s=cut–t–#b=s !# ti!i& s$#tx"#d and leave space before it; use the same tab DIST PST=NP=speak–ICS–MD=3PO PR DIST bear spacing as for subordinate numbering ‘then fish-hawk remembers what bear said to him’ (lit. ‘then his was-spoken-by-bear is remembered by fish-hawk’) indicate a change of cited language and/or give the (Hess 1993: 194, line 46) language name if you are using more than one if data is not from your own Bella Coola fieldwork, cite your sources (with page numbers for (3) !a&nap–is=k"=c’ ta=qiiqtii=t% wa=s=k"acta–tu–m published material) know–3SG:3SG=QTV=now D=baby=D D=NP=name–CS–3SG.PASS use a colon to separate values of inflectional use single quotes for all free categories that are cumulatively expressed x=ti=man=& translations (and for glosses in the by the same affix PR=D=father=1PL.PO text of the paper) ‘the baby knew what he had been named by our father’ number examples sequentially (Davis & Saunders 1980: 108, line 12) throughout the paper Word-processing tip: use the “Keep lines together” option to prevent page breaks from interrupting interlinearized examples and separating lines across pages. -

Automatic Interlinear Glossing for Under-Resourced Languages Leveraging Translations
Automatic Interlinear Glossing for Under-Resourced Languages Leveraging Translations Xingyuan Zhaoy, Satoru Ozakiy, Antonios Anastasopoulosz, Graham Neubigy, Lori Leviny yLanguage Technologies Institute, Carnegie Mellon University zDepartment of Computer Science, George Mason University {xingyuanz,sozaki}@andrew.cmu.edu [email protected] {gneubig,lsl}@cs.cmu.edu Abstract Interlinear Glossed Text (IGT) is a widely used format for encoding linguistic information in language documentation projects and scholarly papers. Manual production of IGT takes time and requires linguistic expertise. We attempt to address this issue by creating automatic gloss- ing models, using modern multi-source neural models that additionally leverage easy-to-collect translations. We further explore cross-lingual transfer and a simple output length control mech- anism, further refining our models. Evaluated on three challenging low-resource scenarios, our approach significantly outperforms a recent, state-of-the-art baseline, particularly improving on overall accuracy as well as lemma and tag recall. 1 Introduction The under-documentation of endangered languages is an imminent problem for the linguistic commu- nity. Of the 7,000 languages in the world, an estimated 50% will face extinction in the coming decades, while around 35–42% still remain substantially undocumented (Austin and Sallabank, 2011; Seifart et al., 2018). Perhaps these numbers are no surprise when one acknowledges the difficulty of language documentation – fieldwork demands time, cultural understanding, linguistic expertise, and financial sup- port among a myriad of other factors. Consequently, an important task for the linguistic community is to facilitate the otherwise daunting documentation process as much as possible. Documentation is not a cure-all for language loss, but it is an important part of language preservation; even in an unfortunate worst-case scenario where a language does disappear, a permanent record of the language is saved for posterity, and could hopefully be useful for revitalization purposes. -

Here ACL Makes a Return to Asia!
Handbook Production: Jung-jae Kim, Nanyang Technological University, Singapore Message from the General Chair Welcome to Jeju Island — where ACL makes a return to Asia! As General Chair, I am indeed honored to pen the first words of ACL 2012 proceedings. In the past year, research in computational linguistics has con- tinued to thrive across Asia and all over the world. On this occasion, I share with you the excitement of our community as we gather again at our annual meeting. On behalf of the organizingteam, it is my great pleasure to welcome you to Jeju Island and ACL 2012. In 2012, ACL turns 50. I feel privileged to chair the conference that marks such an important milestone for our community. We have prepared special programs to commemorate the 50th anniversary, including ‘Rediscovering 50 Years of Discovery’, a main conference workshop chaired by Rafael Banchs with a program on ‘the People, the Contents, and the Anthology’, which rec- ollects some of the great moments in ACL history, and ‘ACL 50th Anniver- sary Lectures’ by Mark Johnson, Aravind K. Joshi and a Lifetime Achieve- ment Award Recipient. A large number of people have worked hard to bring this annual meeting to fruition. It has been an unforgettable experience for everyone involved. My deepest thanks go to the authors, reviewers, volunteers, participants, and all members and chairs of the organizing committees. It is your participation that makes a difference. Program Chairs, Chin-Yew Lin and Miles Osborne, deserve our gratitude for putting an immense amount of work to ensure that each of the 940 sub- missions was taken care of.