4.2. What Is a Service-Oriented Architecture? Section 4.3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Credit Suisse Group Announces Changes to the Corporate Governance Structure of Winterthur Group
Media Relations CREDIT SUISSE GROUP P.O. Box 1 CH-8070 Zurich www.credit-suisse.com Telephone +41 44 333 88 44 Telefax +41 44 333 88 77 [email protected] Credit Suisse Group Announces Changes to the Corporate Governance Structure of Winterthur Group Election of New Boards of Directors at Winterthur Zurich, May 3, 2005 – Credit Suisse Group today announced changes to the corporate governance structure of Winterthur Group, in line with the repositioning of the insurance business within the company. The Boards of Directors of "Winterthur" Swiss Insurance Company and Winterthur Life have been newly elected and will be chaired by Oswald J. Grübel, CEO of Credit Suisse Group, effective immediately. Following the announcement by Credit Suisse Group that it would reposition Winterthur as a financial investment and prepare it for a capital market flotation, the Group has now decided to adapt the corporate governance structure of Winterthur to reflect this change of parameters. The composition of the Boards of Directors of the two Winterthur entities was previously the same as that of the Board of Directors of Credit Suisse Group. The decision to establish separate Boards of Directors will enhance supervision at Winterthur Group and will enable specific insurance issues to be monitored more closely. The management structure of Winterthur Group will remain unchanged. The Boards of Directors, which comprise eight members, will be chaired by Oswald J. Grübel, CEO of Credit Suisse Group. Anton van Rossum has been appointed Vice-Chairman. A list of the members of the Boards of Directors and their Committees is attached. -
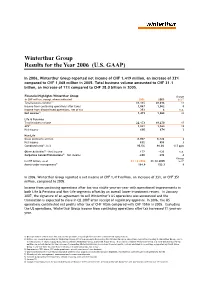
Winterthur Group Results for the Year 2006 (U.S
Winterthur Group Results for the Year 2006 (U.S. GAAP) In 2006, Winterthur Group reported net income of CHF 1,419 million, an increase of 33% compared to CHF 1,068 million in 2005. Total business volume amounted to CHF 31.1 billion, an increase of 11% compared to CHF 28.0 billion in 2005. Financial Highlights Winterthur Group Change in CHF million, except where indicated 2006 2005 in % 7) Total business volume1) 31,115 28,016 11 Income from continuing operations after taxes 1,067 1,062 0 Income from discontinued operations, net of tax 352 6 n.a. Net income2) 1,419 1,068 33 Life & Pensions Total business volume 22,173 19,270 15 APE3) 1,841 1,563 18 Net income 690 674 2 Non-Life Gross premiums written 8.907 8,726 2 Net income 832 809 3 Combined ratio4), in % 95.5% 96.0% -0.5 ppts Other Activities5) – Net income 177 -123 n.a. Corporate Center/Eliminations6) – Net income -280 -292 -4 Change in CHF billion, as of 31.12.2006 31.12.2005 in %7) Assets under management8) 164.8 153.3 8 In 2006, Winterthur Group reported a net income of CHF 1,419 million, an increase of 33%, or CHF 351 million, compared to 2005. Income from continuing operations after tax was stable year-on-year with operational improvements in both Life & Pensions and Non-Life segments offset by an overall lower investment return. In January 2007, the signature of an agreement to sell Winterthur’s US operations was announced and the transaction is expected to close in Q2 2007 after receipt of regulatory approval. -

LETTER to SHAREHOLDERS 1998 INTERIM RESULTS Share Performance
21558_Halbjahres98_E 07.09.1998 14:24 Uhr Seite 1 LETTER TO SHAREHOLDERS 1998 INTERIM RESULTS Share performance CHF Credit Suisse Group Swiss Market Index (adjusted) 350 300 250 200 150 100 J FMAMJ J ASONDJ FMAMJ J ASONDJ FMAMJ J A 1996 1997 1998 Change Share data 30 June 1998 31 Dec. 1997 in % Number of shares issued 267,142,861 266,128,097 0.4 Shares ranking for dividend 267,064,503 265,750,460 0.5 Market capitalisation (CHF m) 90,134 60,060 50 Share price (CHF) 337.50 226 49 high January–June 1998 341 low January–June 1998 216 Change 1st half 1998 1st half 1997 in % Earnings per share (CHF) 9.02 6.79 33 Average shares ranking for dividend 266,340,880 n.a. Financial Calendar Media conference for 1998 results Tuesday, 16 March 1999 1999 Annual General Meeting Friday, 28 May 1999 Contents Commentary on the consolidated half-year results 3 Consolidated income statement 6 Consolidated balance sheet 7 Consolidated off-balance sheet business, selected notes to the consolidated financial statements 8 Credit Suisse 10 Credit Suisse Private Banking 12 Credit Suisse First Boston 13 Credit Suisse Asset Management 16 Winterthur 17 Closing 20 21558_Halbjahres98_E 07.09.1998 14:24 Uhr Seite 3 DEAR SHAREHOLDERS Credit Suisse Group posted net profit of CHF 2.4 bn in the first half of 1998, exceeding the previous year’s corresponding figure by 36%. Return on equity amounted to 18.4%. All business units – Credit Suisse, Credit Suisse Private Banking, Credit Suisse First Boston, Credit Suisse Asset Management and Winterthur – improved substantially on their previous year’s results. -

Credit Suisse Celebrates
The Credit Suisse magazine 2006 anniversary edition Credit Suisse Celebrates Review What made the world go round – in 1856, the founding year Info section The global network of Credit Suisse Highlight Christo and Jeanne-Claude in Zurich Oracle Banking 17 of the 20 Largest Banks in the World Run Oracle Applications Information Age Applications oracle.com/banking or call 0800 55 25 74 Copyright © 2005, Oracle. All rights reserved. Oracle, JD Edwards and PeopleSoft are registered trademarks of Oracle Corporation and/or its affiliates. Editorial 03 Anniversaries Are In Vogue. Last year we celebrated Einstein and Schiller. And 2006 – the Mozart anniversary year – also happens to be the year in which Credit Suisse marks its 150th birthday. But why look back? Doesn’t that mean standing still? At a time when it is all too easy to lose touch with tradition, there is hardly a risk of that happening. Taking a constructive approach to our heritage helps to give us a sense of identity and cements our collective memory. Without a memory, we do not have any experience – and experience is vital for drawing the right conclusions from history. Hence this anniversary issue of the Credit Suisse Bulletin. We are taking the opportunity to recall our founder, Alfred Escher, and the age in which he lived. For Switzerland it was an age of change and upheaval. Alfred Escher was an exceptional person, and his birth a stroke of good fortune for Switzerland. He was much more than just the man who, in 1856, founded Schweizerische Kreditanstalt, today’s Credit Suisse. -

News Release
News Release Changes to Zurich’s Group Executive Committee Zurich, June 11, 2015 – Zurich Insurance Group (Zurich) today announced the following changes to its Group Executive Committee: Cecilia Reyes, currently Chief Investment Officer and Regional Chairman of Asia Pacific, to become Chief Risk Officer effective July 1, 2015, succeeding Axel P. Lehmann Urban Angehrn, currently Head of Alternative Investments, to become Chief Investment Officer effective July 1, 2015 After almost 20 years of highly successful work at Zurich, nearly 14 of which were as a member of the Group Executive Committee, Axel P. Lehmann, Chief Risk Officer and Regional Chairman of Europe, Middle East and Africa, has decided to pursue new opportunities outside of Zurich. He will leave the company by the end of this year. Cecilia Reyes, currently Chief Investment Officer and Regional Chairman of Asia Pacific, will assume the role of Chief Risk Officer effective July 1, 2015. She has been Chief Investment Officer and a member of the Group Executive Committee since 2010. In April 2015, Cecilia Reyes assumed additional responsibility as Regional Chairman of Asia Pacific, a role that she will keep. Axel Lehmann will remain Regional Chairman of Europe, Middle East and Africa, Chairman of the Board of Directors of Farmers Group, Inc. and of Zurich Insurance plc (Ireland), until a successor for each of these roles has been appointed. Urban Angehrn (50, Swiss citizen), currently Head of Alternative Investments, will succeed Cecilia Reyes as Chief Investment Officer and has been appointed a member of the Group Executive Committee effective July 1, 2015. He joined Zurich in 2007 as Page 2 Regional Investment Manager for Europe. -

Annual Report 2016 | Zurich Insurance Group
Zurich Insurance Group Annual Report 2016 Zurich Insurance Group Annual Report 2016 Highlights Zurich Insurance Group is a leading multi-line insurer that serves its customers USD 4.5 bn USD 3.2 bn in global and local markets. With about Business operating profit (BOP) 1 Net income attributable 54,000 employees, it provides a wide to shareholders (NIAS) range of property and casualty, and life insurance products and services in more than 210 countries and territories. Zurich’s customers include individuals, small businesses, and mid-sized and large companies, as well as multinational 11.6% USD 10.4 bn corporations. The Group is headquartered Business operating profit after tax return Cash remittances over 2014 – 2016 period in Zurich, Switzerland. on equity (BOPAT ROE) 2 USD 67.2 bn USD 190 bn Total revenues Total Group investments Z-ECM 122% AA–/stable Zurich Economic Capital Model ratio 3 Standard & Poor’s financial strength estimated as of December 31, 2016 rating of Zurich Insurance Company Ltd as of December 31, 2016 Our cover Formulated by our people, for our customers, our new strategy will guide us in our efforts to provide the best service and products. Our cover shows the individuals who worked with 12 senior Zurich leaders over five months to develop our new strategy. Learn more on page 7. Note on terminology As part of the simplification of our business, we are removing the segment layers of General Insurance and Global Life. The new business structure is focused on geographic regions and consists of Asia Pacific, Europe, Middle East & Africa (EMEA), Latin America and North America. -

Angebotsunterlage
Pflichtveröffentlichung nach § 34 i.V.m. § 14 Abs. 2 und 3 Wertpapiererwerbs- und Übernahmegesetz (WpÜG) Aktionäre der Joyou AG, insbesondere mit Wohnsitz, Sitz oder gewöhnlichem Aufenthalt außerhalb der Bundesrepublik Deutschland, sollten die Hinweise in Abschnitt I.1 (S. 6), "Allgemeine Hinweise für Aktionäre" beachten. Angebotsunterlage Freiwilliges Öffentliches Übernahmeangebot (Barangebot) der Grohe Asia AG Feldmühleplatz 15 40545 Düsseldorf an die Aktionäre der Joyou AG Westhafenplatz 1 60327 Frankfurt am Main zum Erwerb ihrer Aktien der Joyou AG gegen eine Geldleistung in Höhe von EUR 13,50 je Aktie Annahmefrist: 28. März 2011 bis 9. Mai 2011, 24.00 Uhr (mitteleuropäischer Sommerzeit) Aktien der Joyou AG: ISIN DE000A0WMLD8 (WKN A0WMLD) Zum Verkauf eingereichte Aktien der Joyou AG: ISIN DE000A1KRNH7 EUW_ACTIVE:\38173628\17\50805.0017 Inhaltsverzeichnis 1. Allgemeine Hinweise zur Durchführung des Übernahmeangebots..............................6 1.1 Durchführung des Übernahmeangebots nach den Vorschriften des deutschen Wertpapiererwerbs- und Übernahmegesetzes ............................................. 6 1.2 Veröffentlichung der Entscheidung zur Abgabe des Angebots .................................... 6 1.3 Veröffentlichung und Verbreitung der Angebotsunterlage .......................................... 6 1.4 Verbreitung der Angebotsunterlage durch Dritte ......................................................... 7 1.5 Annahme des Angebots außerhalb der Bundesrepublik Deutschland......................... 7 2. Hinweise zu den in der -

Learning Law for a Globalised World the GLOBAL SOCIETY POSES CHALLENGES for PROFESSIONAL ACTIVITY in NUMEROUS FIELDS and the LAW IS NO EXCEPTION
LEGAL AREA Learning Law for a globalised world THE GLOBAL SOCIETY POSES CHALLENGES FOR PROFESSIONAL ACTIVITY IN NUMEROUS FIELDS AND THE LAW IS NO EXCEPTION. THE CONSEQUENCES OF GLOBALISATION SHAPE CONTEMPORARY LEGAL PRACTISE AND THIS MEANS THAT LAWYERS HAVE TO WORK IN AREAS DIFFERENT FROM THE ONES THEY WERE TRAINED IN. (Lic&MD99) cesar.arjona @ esade.edu PhD in Law from Cornell University in the United States, he is currently Professor of Public Law at ESADE and has represented the Faculty of Law at the Center for Transnational Legal Studies, where he has taught the Professional Ethics in Business and Law course. CÉSAR ARJONA British national is named Vice-President for corpo- A rate responsibility of a mul- tinational domiciled in the Cay- man Islands and headquartered in the United States. His job is to ensure compliance with ethi- cal codes that the company has created or supported, as well as existing laws in the various countries where it operates. This leads him to perform his duties to begin arbitration proceedings the various procedural steps in throughout the world, opening through which he seeks to get the confrontation between the permanent offi ces in Chicago, the compensation specifi ed in company and its Vice-President. São Paulo, Lyon, London, Accra his employment agreement. This The case is a good refl ection of and Hong Kong. After verifying agreement, signed in the United the spirit of a centre that was set that what the company actually States, expressly provides for up to meet the challenge of giv- does in several of these places arbitration in case of disputes. -

Axa Appointments Release
AXA APPOINTMENTS RELEASE PARIS, NOVEMBER 17TH, 2014 The AXA Group announces several senior executive appointments Amélie Breitburd is appointed Regional Chief Financial Officer of AXA Asia (regional office gathering AXA’s activities in Asia, except Japan and Korea) and Regional BSD (Business Support Development). Amélie Breitburd will report to Mike Bishop, Chief Executive Officer of AXA Asia. Rainer Schoellhammer is appointed Head of Plan, Budget, Results & Controlling (PBRC). He will report to Gérald Harlin, Chief Financial Officer and member of the AXA Group’s Executive Committee. François-Valéry Lecomte is appointed Chief Executive Officer of AXA Direct Korea. He will report to Xavier Veyry, East Hub (Korea, Japan, China) Head of AXA Global Direct and Chairman of AXA Direct Korea. st These appointments will be effective as of March, 1 2015. Biographies Amélie Breitburd Amélie Breitburd has been Group Head of Plan, Budgets, Results & Controlling (PRBC) since November 2011. Previously, she had been Head of Accounting Policies, and then Head of Group Corporate Actuarial Team, Group Accounting policies and Control. Before joining AXA in 2004, Amélie notably worked with KPMG as external auditor and consultant, and with Allianz France in the internal strategic and organisational audit team. Amélie Breitburd is graduated from the ESSEC Business School and is an actuarial (CEA - Centre d'Etudes Actuarielles). Rainer Schoellhammer Rainer Schoellhammer was since 2012 CFO of AXA Corporate Solutions. He started his career in the accounting policy department of Winterthur Group in Winterthur in 2002 and since then held various roles including Head of Financial Controlling at Winterthur in Germany and AXA Germany, Head of PBR at AXA Germany and BSD for Japan and Asia-Pacific. -

Ii. Disposiciones Y Anuncios Del Estado Sumario
Suplemento al número 28, correspondiente al día 3 de febrero de 2009 Fascículo I SUMARIO II. DISPOSICIONES Y ANUNCIOS DEL ESTADO — Ministerios .................................... 1 IV. ADMINISTRACIÓN DE JUSTICIA — Juzgados de lo Social ............................ 109 II. DISPOSICIONES Y ANUNCIOS DEL ESTADO MINISTERIO DE TRABAJO E INMIGRACIÓN Se previene de que, caso de no obrar así, se iniciará el procedimiento de apremio, me- diante la emisión de la providencia de apremio, con aplicación de los recargos previstos en al artículo 27 de la mencionada Ley y el artículo 10 de dicho Reglamento General. Tesorería General de la Seguridad Social Contra el presente acto, y dentro del plazo de un mes a contar desde el día siguiente a su publicación, podrá interponerse recurso de alzada ante la Administración correspondiente; transcurridos tres meses desde su interposición si no ha sido resuelto, podrá entenderse de- Dirección Provincial de Madrid sestimado, de acuerdo con lo previsto en el artículo 115 de la Ley 30/1992, de 26 de noviem- bre, de Régimen Jurídico de las Administraciones Publicas y del Procedimiento Administra- Don Alfonso González Serrano, subdirector provincial de Gestión Recaudatoria de la Di- tivo Común (“Boletín Oficial del Estado” de 27 de noviembre de 1992), que no suspenderá rección Provincial de Madrid de la Tesorería General de la Seguridad Social, de acuerdo con el procedimiento recaudatorio, salvo que se garantice el importe de la deuda reclamada, con- lo dispuesto en el artículo 59.4 de la Ley 30/1992, de 26 de noviembre, de Régimen Jurídi- forme a lo dispuesto en el artículo 46 del citado Reglamento General de Recaudación de la co de las Administraciones Públicas y de Procedimiento Administrativo Común (“Boletín Seguridad Social. -

Axa Press Release
AXA PRESS RELEASE PARIS, 27 MAY 2016 AXA announces its new leadership team, focuses its organization on customers and transformation AXA announced today a series of appointments to form a new management team that will support Thomas Buberl, incoming CEO1, in the definition and implementation of the Group’s strategy and management of its global operations. The new Management Committee, AXA's senior executive governance body, will notably reflect the strategic importance of the Group’s interaction with its customers and its transformation ambition. It will reinforce the role of large countries (Large Markets) and Global Business Lines, while the Group’s Regions will be repositioned to focus on the development of emerging and smaller markets (Emerging Markets), in Asia and in the rest of the world. Effective as of July 1st, AXA’s Management Committee will be composed of the following 10 members, including Thomas Buberl: • three members of the current Management Committee, with renewed or confirmed roles and responsibilities: . Jean-Louis Laurent Josi, Chief Executive Officer of AXA Asia, . Mark Pearson, Chief Executive Officer of AXA US, . Véronique Weill is appointed Group Chief Customer Officer and Chief Executive Officer of a newly created business line AXA Global Asset Management, • six internally appointed new members: . Benoît Claveranne is appointed Group Chief Transformation Officer, . Paul Evans is appointed Chief Executive Officer of AXA Global Life & Savings and of AXA Global Health, . Gérald Harlin, Group Chief Financial Officer, . Gaëlle Olivier is appointed Chief Executive Officer of AXA Global P&C, . Jacques de Peretti is appointed Chief Executive Officer of AXA France, — 1 Thomas Buberl was appointed Deputy CEO of AXA on March 21, 2016, and will be CEO of AXA as of September 1, 2016. -

AXA GROUPE-RA2004-V7
UNITED STATES SECURITIES AND EXCHANGE COMMISSION WASHINGTON, D.C. 20549 FORM 20-F ANNUAL REPORT PURSUANT TO SECTION 13 OR 15 (d) OF THE SECURITIES EXCHANGE ACT OF 1934 for the fiscal year ended December 31, 2006 Commission File Number: 1-14410 AXA (Exact name of Registrant as specified in its charter) N/A The Republic of France (Translation of Registrant’s name into English) (Jurisdiction of incorporation or organization) 25, avenue Matignon - 75008 Paris - France (Address of registrant’s principal executive offices) Securities registered or to be registered pursuant to Section 12 (b) of the Act: Title of each class: Name of each exchange on which registered: Ordinary shares New York Stock Exchange American Depositary Shares (as evidenced by American Depositary Receipts), each representing one Ordinary Share New York Stock Exchange Securities registered or to be registered pursuant to Section 12 (g) of the Act: None Securities for which there is a reporting obligation pursuant to Section 15 (d) of the Act: None The number of outstanding shares of each of the issuer’s classes of capital or common stock as of December 31, 2006 was: 2,092,888,000 Ordinary Shares of euro 2.29 nominal value per share, including 83,666,378 American Depositary Shares (as evidenced by American Depositary Receipts), each representing one Ordinary Share. Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes IX No I If this report is an annual or transition report, indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or 15 (d) of the Securities Exchange Act of 1934.