Tilburg University Effects of Literacy, Typology and Frequency On
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Theme Park As "De Sprookjessprokkelaar," the Gatherer and Teller of Stories
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2018 Exploring a Three-Dimensional Narrative Medium: The Theme Park as "De Sprookjessprokkelaar," The Gatherer and Teller of Stories Carissa Baker University of Central Florida, [email protected] Part of the Rhetoric Commons, and the Tourism and Travel Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Doctoral Dissertation (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Baker, Carissa, "Exploring a Three-Dimensional Narrative Medium: The Theme Park as "De Sprookjessprokkelaar," The Gatherer and Teller of Stories" (2018). Electronic Theses and Dissertations, 2004-2019. 5795. https://stars.library.ucf.edu/etd/5795 EXPLORING A THREE-DIMENSIONAL NARRATIVE MEDIUM: THE THEME PARK AS “DE SPROOKJESSPROKKELAAR,” THE GATHERER AND TELLER OF STORIES by CARISSA ANN BAKER B.A. Chapman University, 2006 M.A. University of Central Florida, 2008 A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the College of Arts and Humanities at the University of Central Florida Orlando, FL Spring Term 2018 Major Professor: Rudy McDaniel © 2018 Carissa Ann Baker ii ABSTRACT This dissertation examines the pervasiveness of storytelling in theme parks and establishes the theme park as a distinct narrative medium. It traces the characteristics of theme park storytelling, how it has changed over time, and what makes the medium unique. -

AUTO-RUTAS ÍNDICE Auto-Rutas
AUTO-RUTAS ABRIL 2020 • DICIEMBRE 2020 WINTER WONDERLA WINTER WINTER WONDERLA VIAJA A TU AIRE EN COCHE El mundo como tú quieras. Un tipo de viaje para los más independientes: vuelos, coche de alquiler y reserva en los hoteles para tener garantizado el alojamiento y disfrutar. con Catai TravelPricer calcula el precio final de tu viaje ÍNDICE Auto-rutas Toscana Express Italia 7 Al Sol de la Toscana Italia 8 Napoles y la Costa Amalfitana Italia 9 Sicilia en Libertad Italia 10 Azores en Libertad Portugal 11 Castillos Reales Francia 12 Bretaña Magica Francia 12 Reims y la Ruta del Champagne Francia 13 Alsacia, la Ruta del Vino Francia 13 Escapada a Flandes Bélgica 14 Lo Mejor de Flandes Bélgica 14 El Mundo Fantastico de Efteling Holanda 15 Berlín y Ciudades Clásicas Alemania 16 La Ruta Romántica Alemania 16 Selva Negra Alemania 17 Alemania y sus Autos Alemania 17 Europa-Park Alemania 18 Legoland Deutschland Resort Alemania 19 Legoland y Playmobil Alemania 20 Suiza Escenica Suiza 21 Tirol en Granjas Austria 22 Eslovenia, Tesoro Verde Eslovenia 23 Paisajes de Croacia Croacia 24 Creta, La Isla del Minotauro Grecia 25 Grecia Clasica Grecia 26 Chipre, la Isla de Afrodita Chipre 27 La Ruta del Rey Arturo Inglaterra 28 Escocia en Libertad Escocia 29 Irlanda Espectacular Irlanda 30 Irlanda del Norte Irlanda del Norte 31 Dinamarca Familiar Dinamarca 32 Dinamarca al Completo Dinamarca 33 Islas Faroe Dinamarca 34 Fiordos de Noruega Noruega 35 Fiordos Encantadores Noruega 36 Cabañas en los Fiordos Noruega 37 Lofoten y Alpes de Lynge Noruega 38 Islandia -

Hallo, Ik Ben Jayda
Deze kunstwerken zijn gemaakt door de kinderen van de Mare tijdens de lessen ‘Beeldende Vorming’. Voor meer kunstwerken: Bezoek ook eens ons virtuele Mare Museum. www.obsdemare.nl - Actueel - Kunstige Werkjes Voorwoord Beste ouder(s) / verzorger(s), Voor u ligt alweer het laatste Mare Magazine van dit schooljaar. De zomervakantie nadert met rasse schreden en op het moment van schrijven wanen we ons al in het ‘zomervakantiegevoel’ gezien de temperaturen. In dit Mare Magazine weer volop nieuws uit de groepen, maar ook een terugblik op verschillende activiteiten in de afgelopen periode. Natuurlijk foto’s van ons sportieve hoogtepunt in februari, het HaKobaltoernooi met als glorieuze winnaar groep B5 van meester Daan. Verder ook de herdenking en de schoolreisjes waarop nog even wordt teruggekeken. Rest mij u heel veel leesplezier toe te wensen en alvast een hele fijne zomer ! P.(Peter) van der Waal Directeur obs "De Mare" Inhoud Artikelen van de kinderen Schoolreis naar de Efteling 25 Hugo de Groot 1 Elfjes maken 28 IFFR 3 Vervolg Efteling 29-34 Kleine brief aan grote stad 3 Paashazenbroodjesbakdag 35-36 Eerste medailles 3 Dichters 37-38 Goud voor team Holland 5-7 Kranslegging 39-40 Romeinse boekenrol 7 Dolle boel in Dippie Doe 41-45 Als ik een medaille zou winnen 9-10 Wij weten alles over slakken 46 Wij doen ons best bij Blink 11-12 Lente op de boerderij 47-48 B5 is de nieuwe kampioen 13-14 Vrolijk Pasen 49-50 Elke stem telt 16 Wij zorgen goed voor de vogels 17-19 Chinees op school? 22 Verkeersacties 22 Paasfeest 23 Vaste Rubrieken De artikelen -
Shows Und Live-Entertainment !.!# Thailändischer Tempel Mit Panoramablick
WEG ZUM R EFTELING2HOTEL MARERIJK RUIG IJK ! Sprookjesbos (Märchenwald) #! Kinderspoor Pedalbetriebener Tretzug. !.)! Dornröschen !.!% Tischlein deck dich, Esel streck dich !.)" Das Zwergendorf #" "& !.)* Die sechs Diener (Langhals) !.!& Schneewittchen Halve Maen !.)# Rotkäppchen !.!' Genovevas Brautkleid Riesen-Schiaschaukel. !.)$ Pinocchio !.!( Aschenputtel #* De Oude Tu?erbaan #$ !.)% Die roten Schuhe !.") Der Froschkönig H"& !.)& Der Trollkönig !."! Die magische Uhr Fahrt in einem Oldtimer. !.)' Die ungezogene Prinzessin !."" Die indischen Seerosen (sprechender Papagei) !."* Der kleine Däumling ## Polka Marina #* H#$ !.)( Rapunzel !."# Rumpelstilzchen Wellen-Karussell. !.!) Die kleine Meerjungfrau !."$ Das kleine Mädchen mit den Schwefelhölzern #$ Stoomtrein #! !.!! Der Drache H"$ !.!" Der Wolf und die sieben Geißlein !."% Des Kaisers neue Kleider Zugfahrt durch Efteling in einer echten Dampfeisenbahn.. !.!* Hänsel und Gretel !."& Märchenbaum ## #% #% !.!# Frau Holle !."' Der Gärtner und der Fakir Python "$ !.!$ Bertram Botschafter !."( Die chinesische Nachtigall Stählerne Achterbahn mit Loopings. (Wartungsarbeiten bis 31. März 2018) "" "% " Sprookjesboom Show Carnaval Ruigrijk Plein #& Festival Plein Freilichtvorstellung mit Märchenwaldbewohnern De Vliegende Hollander #" (in Niederländisch). Geheimnisvoller Wassercoaster. H## S#" * De Sprookjessprokkelaar #' Joris en de Draak S"" "# Begegnung mit De Sprookjessprokkelaar (der Märchensammler). Zweigleisige hölzerne Racing-Achterbahn. # Diorama #( Baron CFNF ZENRI Miniaturwelt. Dive -

Arrangement De Lux 2 Overnachtingen, Incl. 1 Dag Entree
Arrangement de lux 2 overnachtingen, incl. 1 dag Entree Efteling + parkeerkaart ! Prijs 2 personen €242,00 euro Prijs 3 personen €278,00 euro Prijs 4 personen €314,00 euro *Excl. € 0,89 p.p. / p.d. Toeristen belasting. *Excl Ontbijt. (kan er los bij geboekt worden, € 7,50 p.p / p.d.) Wat is er mooier om in een sprookjes achtingen wereld als de Efteling op een rustige manier te ontdekken, na of voor een overnachting in Villa Pats. Villa Pats ligt op 15 minuten rijden afstand van de Efteling. De Efteling is een adembenemend natuurschoon en een van de meeste populaire pretparken van Europa en heeft heel veel te beiden, zoals de snelle achtbanen, met o.a. De Python, Joris en de Draak, Vogelrok, De Vliegende Hollander en de Baron 1898. Maar ook de sprookjes achtige Droomvlucht en Symbolica en de Fata Morgana, en natuurlijk niet vergeten het prachtige Sproojes bos. Ook zijn er voldoende restaurantjes voor een lekker maaltijd of om gewoon lekker wat te drinken en natuurlijk mag je de fontein show Aquanura niet missen voordat u weer terug rijd naar huis of naar Villa Pats. Tip: combineer u reis met een bezoek aan de zoo de Beekse Bergen ( 10 minuten rijden vanaf Villa Pats), of maak een stedentrip naar Breda (7 km), Tilburg (6 km), Eindhoven (42 km), den Bosch (32 km), Rotterdam (62 km) of Antwerpen (59 km) of de vele andere bezienswaardige in de omgeving: Speelboederij indoor / outdoor Vossenberg, Gilze (3 km) Kids wonderland, Molenschot (5,4 km) Oliemeulen insecten dierenpark, Tilburg (11 km) Brabants museum, den Bosch (37 km) Baarle nassau -

André Rieu in Wonderland
André Rieu in Wonderland A walk through the amusement park "Efteling" where this DVD was recorded. Version 1.4, Jun 2011 The Wonderland walk. Page 1 of 34 Introduction In the summer of 2007, André Rieu and the JSO recorded the DVD “Wonderland” in the fairytale park “Efteling” in The Netherlands. From several people we received requests for more information on this park. In this document we provide some useful information (how to get there, opening times, etc.) and a "Wonderland walk" through the park, passing by many places you will see in the “Wonderland” DVD. History of the “Efteling” Ask any Dutch person above the age of 40 about the “Efteling”. Ten to one they all give you the same answers: “the flying carpet”, “dancing red shoes”, “musical mushrooms”, the “trains” and “Long Neck”, to name a few. Below a picture of my brother and I in one of the little trains. I was about eight years old at that time (±1963). The other picture was taken recently (April 2008). I don’t know why, but it looks like those trains have shrunk quite a lot, but you still have to peddle like a madman to get around the track in a record time. And still no brakes, but good bumpers. But most important: all those popular attractions from the early days of the park are still there and in high demand! The history of the Efteling goes back to 1933, when a few people had an idea to start a sports park with a soccer field and a small playground. -
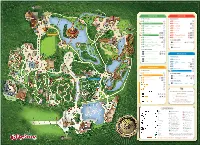
Internetversie Plattegrond MT.Indd
ROUTE TO EFTELING HOTEL MARERIJK RUIGRIJK ATTRACTIONS ATTRACTIONS Sprookjesbos Kinderspoor Fairytale Tree, Once upon a time... Halve Maen Diorama D'Oude Tu er Ruigrijkplein Stoomcarrousel Polka Marina Carnaval Festivalplein Stoomtrein Stoomtrein Droomvlucht Python REIZENRIJK Raveleijn De Vliegende Hollander Villa Volta Joris en de Draak RUIGRIJK Kindervreugd FOOD AND DRINKS Volk van laaf (Monorail) Station de Oost Carrousels Anton Pieckplein SHOPS Efteling Museum Game Gallery FOOD AND DRINKS Het Wapen van Raveleijn Anton Pieckplein Het Witte Paard ANDERRIJK SHOPS ATTRACTIONS In den ouden Marskramer PandaDroom Efteling Brink Loetiek Spookslot Piraña Bob REIZENRIJK Fata Morgana Witte Paardplein ATTRACTIONS Aquanura Carnaval Festival FOOD AND DRINKS MARERIJK WACHT EN SHOWTIJDENBORD Jokie and Jet Pirañaplein Restaurant Applaus Ton Vogel Rok van de Ven Octopus plein ANDERRIJK Monsieur Cannibale FOOD AND DRINKS Avonturen Doolhof Efteldingen Kleuterhof Pagode Gondoletta FOOD AND DRINKS SHOWS AND LIVE ENTERTAINMENT Dates and times: Polles Keuken Steenbokplein Check the waiting and show time board or the Efteling app. Welkom Spieltage und zeiten: Siehe Warte- und Showzeiten-Bord oder Efteling-App. SHOPS Les jours et les heures : Herautenplein Consultez le tableau des heures d'attente et de Pardoes Promenade Jokies Wereld représentation ou l'application Efteling. BEST VIEW! Fata Morgana plein • LEGENDA • Information/park map Waiter service Information/ Parkplan Bedienung Shows & live-entertainment Gluten-free items available Informations/plan du parc Service Glutenfrei möglich Toilets Self-service Indoor attraction Egalement disponible sans gluten Toiletten Selbstbedienung Überdachte Attraktion Not accessible for disabled people Toilettes Self-service Attraction couverte Nicht barrierefrei Non accessible aux personnes Telephone Take away Open-air attraction à mobilité réduite Dwarrelplein Telefon Take away Attraktion im Freien Téléphone A emporter Attraction en plein air Min. -

New Waterpark a Big Hit at Iowa's Adventureland Park
TM www.AmusementToday.com Vol. 14, Issue 7 OCTOBER 2010 $5.00 Great Coasters opens ProSlide delivers slide package racer at Efteling New waterpark a big hit at Iowa's Adventureland Park Pam Sherborne Amusement Today Adventureland Park’s Bill Fisher, director of marketing, wasn’t sure how guests would take to going from a dry park to a wet park than back to a dry park with all those things that go along with that trans- formation. Two years ago, that was one of the questions park of- ficials in the Altoona, Iowa, park had when the facility opened the season with the RainFortress, a water attrac- tion with seven slides and a huge dumping bucket made by WhiteWater West Indus- tries, Vancouver, B.C. PHOTO COURTESY ADVENTURELAND “I did wonder how they The new $6 million Adventure Bay Water Park, part of would like going from the amusement park into the wa- Adventureland Park, Altoona, Iowa, opened mid-July and ter area, changing into a swim- response was great, according to park officials. Park manage- suit, getting wet, then chang- ment decided to invent in the waterpark after water elements ing back out of their swimsuit installed in 2008 and 2009 were met with great success. PHOTO COURTESY GCII and going back into the amuse- The race is on! Efteling in The Netherlands debuts Joris ment park,” Fisher said. “As it WWA show en de Draak, an exciting new racing coaster from Great turned out, it didn’t faze them a bit. They loved it.” Coasters International, Inc. -

Over Kwaliteit, Kitsch En Kozijntjes
Over kwaliteit, kitsch en kozijntjes Een avond bij Michel den Dulk Eftelist, 10 juli 2006 “Het zit ’m vaak in heel kleine dingen. Details die door de meeste mensen niet eens meteen worden waargenomen.” 2 Over kwaliteit, kitsch en kozijntjes - Een avond bij Michel den Dulk De herinnering aan zes maart 2005 zal de meeste Eftelingliefhebbers niet direct doen vervallen in anekdotes over aan de grond genageld staan, of de theepot pardoes uit de handen laten vallen. Maar we keken er in de vroege lente van vorig jaar allemaal wél ontzettend van op toen we hoorden dat Michel den Dulk - protégé van Ton van de Ven en ontwerper van kunststukjes als het Anton Pieckplein en het Meisje met de Zwavelstokjes - niet meer werkzaam was bij de Efteling. Veel begrepen we er niet van. De jonge creatieveling had de naam een lastpak te zijn, maar had in korte tijd al zoveel prachtigs aan het Kaatsheuvelse park toegevoegd, dat niemand het ook maar een ogenblik zag aankomen. Het had zo veilig geleken; het vertrek van Van de Ven als creatief directeur was een stuk beter te verdragen in de geruststellende wetenschap dat het stokje werd doorgegeven aan een jonge opvolger die het werken met de geleende hand van Anton Pieck in elk geval uitstekend voor elkaar kreeg, en misschien nog wel veel meer in zijn mars had. Na het vertrek van Michel den Dulk uit de Efteling lijkt het park het befaamde ‘korset van het Pieckeriaanse denken’ als een oude nachtpon op de kar van de lorrenman te hebben gegooid, jammer genoeg. -

Spreekbeurtpakket De Vliegende Hollander
Spreekbeurtpakket De Vliegende Hollander Een spreekbeurt voor waaghalzen! 1. De Vliegende Hollander in de Efteling 2. De sage van De Vliegende Hollander 3. Een uitstapje naar de Gouden Eeuw 4. The making off: van idee tot attractie 5. Leuk om te weten: feiten en cijfers 6. Bekende scheepvaartgezegden 7. De Vliegende Hollander quiz 8. Foto’s en logboeken om te downloaden 9. De beste links naar de beste websites 10. Boek over De Vliegende Hollander 11. Tips voor het houden van je spreekbeurt 1. De Vliegende Hollander in de Efteling 1.1 Wat is De Vliegende Hollander? De Vliegende Hollander is een spectaculaire Efteling-attractie. Op 1 april 2007 ging de attractie open voor het publiek. De Vliegende Hollander is een sensationeel avontuur voor iedereen met stalen zenuwen. Maar… niet helemaal voor iedereen. Je mag er pas in als je 1.20 meter of groter bent! De attractie is gemaakt naar een eeuwenoude sage van het Spookschip De Vliegende Hollander. Je vindt de attractie in het Ruigrijk, tussen de Python en de Pegasus. De sage in het kort: Het verhaal speelt zich af in De Gouden Eeuw. Aan boord van een schip staat kapitein Willem van der Decken. Hij vaart in 1678 de haven uit, tegen alle regels in. Dat wordt zijn noodlot. Zijn prachtige zeeschip wordt vervloekt. Het verandert in een mysterieus, vurig Spookschip. Het schip is gedoemd om voor eeuwig de zeven wereldzeeën te bevaren. Als ‘De Vliegende Hollander’… Het verhaal wordt al honderden jaren verteld over de hele wereld. Er zijn heel veel verschillende versies van. Nog steeds zijn er mensen die zeggen dat ze het Spookschip hebben gezien. -

Internetversie Plattegrond Zomer.Indd
EFTELING HOTEL MARERIJK RUIGRIJK S ATTRACTIES ATTRACTIES E Sprookjesbos Kinderspoor Sprookjesboom, Er was eens... Halve Maen Ruigrijk Plein Diorama D’Oude Tu er Carnaval Festival Plein S Stoomcarrousel Polka Marina S Stoomtrein Stoomtrein REIZENRIJK T Droomvlucht Python Raveleijn De Vliegende Hollander RUIGRIJK Villa Volta Joris en de Draak Kindervreugd Baron 1898 (Zomer/Summer/Sommer/ Été 2015) Volk van Laaf (Monorail) zomer/summer/Sommer/été 2015 ETEN EN DRINKEN Carrousels Anton Pieck Plein S Station de Oost Efteling Museum Anton T Pieck Plein De Kombuys ETEN EN DRINKEN A SOUVENIRS Het Wapen van Raveleijn S Efteling Brink S D Game Gallery ‘t Po ertje D F F Het Witte Paard B ANDERRIJK SOUVENIRS Witte Paard Plein S ATTRACTIES In den Ouden Marskramer WACHT EN SHOWTIJDENBORD WAITING AND SHOW TIME BOARD S WARTE UND SHOWZEITENTAFEL PANNEAU DE TEMPS D’ATTENTE ET D’HEURES DE SPECTACLE S PandaDroom Loetiek WACHT EN SHOWTIJDENBORD Piraña Plein MARERIJK WAITING AND SHOW TIME BOARD WARTE UND SHOWZEITENTAFEL PANNEAU DE TEMPS D’ATTENTE ET D’HEURES DE SPECTACLE Spookslot Ton van de Ven Plein ANDERRIJK Piraña A REIZENRIJK Bob ATTRACTIES Fata Morgana Carnaval Festival Aquanura Jokie en Jet ETEN EN DRINKEN H Vogel Rok Steenbok C Plein Restaurant Applaus Monsieur Cannibale X H Octopus Avonturen Doolhof Pardoes Promenade X De Steenbok Herauten Plein Kleuterhof KIJKTIP Fata Morgana Pagode Plein SOUVENIRS Gondoletta S De Bazaar S S Efteldingen ETEN EN DRINKEN B Polles Keuken Dwarrel -

20150727Wonderlijke Wandelroute.Indd
Efteling Wandelroute Ontdek de Efteling nog beter met deze Wandelroute Laat je verrassen door de vele wonderlijke en avontuurlijke attracties! Naam: Inleiding Deze Efteling wandelroute is een wandeling langs de mooiste plekjes, attracties en diverse horecapunten van de Efteling. Ook komen leuke wetenswaardigheden en een stukje geschiedenis aan bod. Het duurt ongeveer drie uur om deze wandelroute te lopen, maar je kunt er ook de hele dag over doen. Dit is afhankelijk van je tempo en het aantal attracties dat je bezoekt. Uiteraard heb je ook alle gelegenheid om tijdens de wandeling af en toe te pauzeren voor een kopje koffie, een lunch of diner. De route begint direct bij het Huis van de Vijf Zintuigen, de hoofdentree van de Efteling. Vervolgens staat beschreven hoe je het beste kunt lopen om optimaal van het attractiepark te genieten. Veel plezier tijdens de wandeling! Entree Het Huis van de Vijf Zintuigen (de hoofdentree) is in 1996 in gebruik genomen. Voor de rieten kap zijn speciaal 800 bomen gekweekt. De hoogte van het dak is 43 meter en de oppervlakte is 4.500 m². Onder de kap broeden verschillende vogelsoorten, waaronder de bosuil. In dit indrukwekkende gebouw bevinden zich de kassa´s en de Gastenservice. Het plein dat je na de controlepoortjes op loopt heet het Dwarrelplein. Voordat je aan het einde van het Dwarrelplein het spoor oversteekt, kom je langs de watershow Aquanura. Dit is de grootste watershow van Europa en een eerbetoon aan één van de eerste sprookjes die de Efteling rijk was, namelijk De Kikkerkoning. Deze sensationele watershow is speciaal voor de viering van het 60 jarig bestaan van de Efteling gebouwd door WET design.