Lab2 Handout
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building a SAN-Less Private Cloud with IBM Powervm and IBM Powervc
Front cover Building a SAN-less Private Cloud with IBM PowerVM and IBM PowerVC Javier Bazan Lazcano Stephen Lutz Redpaper International Technical Support Organization Building a SAN-less Private Cloud with IBM PowerVM and IBM PowerVC July 2018 REDP-5455-02 Note: Before using this information and the product it supports, read the information in “Notices” on page v. Third Edition (July 2018) This edition applies to Version 1, Release 4, Modification 1 of IBM Cloud PowerVC Manager for Software-Defined Infrastructure V1.1 (product number 5765-VCD). © Copyright International Business Machines Corporation 2017, 2018. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . .v Trademarks . vi Preface . vii Authors. vii Now you can become a published author, too! . viii Comments welcome. viii Stay connected to IBM Redbooks . viii Chapter 1. Architecture of a software-defined infrastructure solution with IBM Power Systems servers and IBM PowerVC . 1 1.1 Software-defined infrastructure . 2 1.2 The motivation behind software-defined infrastructure . 2 1.3 Use cases . 4 1.3.1 Use case 1: Building a storage area network-less cloud . 4 1.3.2 Use case 2: Building an iSCSI-backed cloud . 5 1.3.3 More use cases. 5 1.4 Rack topologies and components . 6 1.4.1 Starter cloud . 7 1.4.2 Mini cloud . 8 1.4.3 Rack scale . 9 1.4.4 Storage/management switches. 10 1.4.5 Data switches . 10 1.4.6 Network nodes . -

IBM Worklight V5.0.6 Technology Overview
IBM Software Technical White Paper WebSphere IBM Worklight V5.0.6 Technology overview IBM Worklight—Overview Contents IBM® Worklight® software helps enable organizational leaders to extend their business to mobile devices. This software provides an open, 1 IBM Worklight—Overview comprehensive and advanced mobile application platform for smart- phones and tablets, helping organizations of all sizes to efficiently 2 IBM Worklight—Components develop, connect, run and manage mobile and omni-channel applications. 3 Development tools Leveraging standards-based technologies and tools, the IBM team has created Worklight software that provides a single integrated platform. 8 Runtime server environment This platform includes a comprehensive development environment, 9 The IBM Worklight Console mobile-optimized runtime middleware, a private enterprise application store and an integrated management and analytics console—all supported 9 IBM Worklight Device by a variety of security mechanisms. Runtime components 10 Security and authentication Develop. The IBM Worklight Studio and the IBM Worklight software mechanisms development kit (SDK) simplify the development of mobile and omni- channel applications (apps) throughout multiple mobile platforms, includ- ing iOS, Android, BlackBerry, Windows 8, Windows Phone and Java ME. The IBM Worklight optimization framework fosters code reuse while delivering rich user experiences that match the styling requirements of each target environment. With such code reuse, IBM Worklight reduces costs of development, reduces time-to-market and provides strong support for your ongoing management efforts. Connect. The IBM Worklight Server architecture and adapter technol- ogy simplifies the integration of mobile apps with back-end enterprise systems and cloud-based services. The IBM Worklight Server is designed IBM Software Technical White Paper WebSphere to fit quickly into your organization’s IT infrastructure and is Console. -

AIX Dec 2004.P65
110 December 2004 In this issue 3 Finding the biggest file in directories on the same filesystem 4 Creating a physical partition map of an hdisk by logical volume 9 AIX console mirroring 11 Using ClamAV 14 Happy 18th birthday AIX 16 Deploying multiple compiler versions on AIX 27 Mirroring tips and techniques in AIX 36 Generating a logo 41 Default user password settings in AIX 47 AIX news © Xephon Inc 2004 AIX Update Published by Disclaimer Xephon Inc Readers are cautioned that, although the PO Box 550547 information in this journal is presented in good Dallas, Texas 75355 faith, neither Xephon nor the organizations or USA individuals that supplied information in this Phone: 214-340-5690 journal give any warranty or make any Fax: 214-341-7081 representations as to the accuracy of the material it contains. Neither Xephon nor the contributing Editor organizations or individuals accept any liability of Trevor Eddolls any kind howsoever arising out of the use of such E-mail: [email protected] material. Readers should satisfy themselves as to the correctness and relevance to their Publisher circumstances of all advice, information, code, Bob Thomas JCL, scripts, and other contents of this journal E-mail: [email protected] before making any use of it. Subscriptions and back-issues Contributions A year’s subscription to AIX Update, When Xephon is given copyright, articles comprising twelve monthly issues, costs published in AIX Update are paid for at the rate $275.00 in the USA and Canada; £180.00 in of $160 (£100 outside North America) per the UK; £186.00 in Europe; £192.00 in 1000 words and $80 (£50) per 100 lines of code Australasia and Japan; and £190.50 elsewhere. -

OSS Alphabetical List and Software Identification
Annex: OSS Alphabetical list and Software identification Software Short description Page A2ps a2ps formats files for printing on a PostScript printer. 149 AbiWord Open source word processor. 122 AIDE Advanced Intrusion Detection Environment. Free replacement for Tripwire(tm). It does the same 53 things are Tripwire(tm) and more. Alliance Complete set of CAD tools for the specification, design and validation of digital VLSI circuits. 114 Amanda Backup utility. 134 Apache Free HTTP (Web) server which is used by over 50% of all web servers worldwide. 106 Balsa Balsa is the official GNOME mail client. 96 Bash The Bourne Again Shell. It's compatible with the Unix `sh' and offers many extensions found in 147 `csh' and `ksh'. Bayonne Multi-line voice telephony server. 58 Bind BIND "Berkeley Internet Name Daemon", and is the Internet de-facto standard program for 95 turning host names into IP addresses. Bison General-purpose parser generator. 77 BSD operating FreeBSD is an advanced BSD UNIX operating system. 144 systems C Library The GNU C library is used as the C library in the GNU system and most newer systems with the 68 Linux kernel. CAPA Computer Aided Personal Approach. Network system for learning, teaching, assessment and 131 administration. CVS A version control system keeps a history of the changes made to a set of files. 78 DDD DDD is a graphical front-end for GDB and other command-line debuggers. 79 Diald Diald is an intelligent link management tool originally named for its ability to control dial-on- 50 demand network connections. Dosemu DOSEMU stands for DOS Emulation, and is a linux application that enables the Linux OS to run 138 many DOS programs - including some Electric Sophisticated electrical CAD system that can handle many forms of circuit design. -

Versatile Vintage More and More Windows Applications Run on Linux Thanks to Wine
COVER STORIES Practical Wine Building a Wine environment for Windows applications Versatile Vintage More and more Windows applications run on Linux thanks to Wine. If you spend a little time on configuration and troubleshooting, you won’t be stuck in Windows – even with applications that no one dreamed would run on Linux. By Harald Jele eyond the easily replaceable large office and graphics packages, the market bustles with countless, typically smaller programs that cater to the needs of small- to B medium-sized niches. Commonly, companies or govern- ment offices create their own custom, mission-critical applications. The famous Wine system libraries [1] provide a means for running Windows applications from within Linux. Right now, version 1.4 is the stable release, and development release 1.5.6 is also available. Configuring Wine has completely changed in the course of the years. Al- though Wine was once regarded as complicated, it has become significantly easier and clearer, and it handles many annoying details that were formerly left to the admin. These details that once caused grief and are now rel- atively painless include integrating removable devices such as DVDs or integrating the CUPS printing sys- tem. An equally significant change in the architecture of Wine was the in- troduction of prefixes (since 2003, AUTHOR also known as bottles). Setting up a prefix means you can install and op- Dr. Harald Jele works for the University of Klagenfurt and is currently engaged erate Windows software within a with the technical aspects of putting pre-defined context without conflict- Klagenfurt author Robert Musil’s works ing with other software. -

Warppls Emulator for Macos Introduction
WarpPLS emulator for macOS Dao Duy Tung Tay Do University, Vietnam Introduction Windows programs which don’t have a dedicated version for Mac OS X cannot be ran on Mac directly, but they can be ran with the help of a special tool. There are two basic ways to run Windows programs on a Mac. One is emulation, and another is virtualization. Emulation refers to simulating the basic portions of the Windows environment necessary to run some Windows programs on a non-Windows system. The most well-known emulator is WINE, which is a humorous acronym for “WINE Is Not an Emulator”. While it is possible to build WINE on Mac an official pre-built binary package is not available and building it yourself is probably exceedingly difficult. That’s where third party WINE distributions come in. Likely the best among them is PlayOnMac which comes as a standard Mac app and features an easy to use interface with which you can browse and install compatible Windows applications. PLAYONMAC is a graphical front-end for Wine compatibility layer. It simplifies the installation of Windows apps and (especiall)y games on GNU/Linux by auto-configuring Wine. It provides wrapper shell scripts to specify the configuration of Wine for any particular software. It also uses an online database of scripts to apply for different programs. Link download at here. *Note: PLAYONMAC incompatibility macOS Catalina (10.15) and next, because it dropped 32bits support. CHANGELOGS - Instead of function “DOWNLOAD” to “LOCAL” on my script. - Fixed error “Wine packages website is unavailable”. - Fixed error “failed download wine 2.20” on PLAYONMAC. -

I/O Kit Drivers for L4
THE UNIVERSITY OF NEW SOUTH WALES SCHOOL OF COMPUTER SCIENCE AND ENGINEERING I/O Kit Drivers for L4 Geoffrey Lee Submitted as a requirement for the degree Bachelor of Engineering (Computer Engineering) Submitted: November 3, 2005 Supervisor: Professor Gernot Heiser Accessor: Dr. Sergio Ruocco 2 Contents 1 Introduction 9 1.1 Overview . 9 1.2 Outline . 9 2 Background 11 2.1 Introduction . 11 2.2 Darwin . 11 2.2.1 Overview . 11 2.2.2 User environment . 11 2.2.3 Kernel environment . 11 2.3 Mac OS X . 13 2.4 L4 ................................................ 14 2.5 Motivation . 15 2.5.1 Performance . 15 2.5.2 Robustness . 15 2.5.3 Ease of porting . 16 2.6 Justification . 16 3 The I/O Kit 17 3.1 An Overview of the I/O Kit . 17 3.1.1 Driver layering . 17 3.1.2 Families and drivers . 17 3.1.3 Drivers and nubs . 19 3.1.4 The I/O Registry and the I/O Catalog . 19 3.1.5 Work loops . 19 3.1.6 Direct memory access . 20 3.1.7 Asynchronous events . 21 3.1.8 Power management . 21 3.1.9 Hot-plugging . 23 3.2 An Overview of a Typical I/O Kit Driver . 23 3.3 The I/O Kit Driver Code . 24 3.4 The Driver Property List . 24 4 Related Work 27 4.1 OSKit . 27 4.2 L4-Darwin . 27 4.3 Device Driver OS . 29 3 4 CONTENTS 4.4 User-level Device Drivers . 29 4.5 Nooks . -

Guide to Installing Iman on a New System
Guide to Installing Iman on a New System Introduction The Iman suite contains full source code but is not easily recompiled. However, because the binary programs are already present, they can be run on x86-based Linux systems. This guide details the configuration steps necessary. Follow this guide while logged in as idl. Host System This guide assumes a host running Ubuntu 14.04 LTS. The host processor must use the x86 instruction set and a word length of 32 bits or greater. Intel’s Pentium and Core processors and AMD’s Athlon processors are examples. The host requires an internet connection to download additional software necessary to support Iman. Unpacking the Software Iman and its attendant libraries are stored in three tarballs (ending in .tgz or .tar.gz): one for the cc directory containing Iman itself; one containing the pgplot library; and one containing necessary libraries from /usr/local/lib. pgplot First, extract the tarball for pgplot. It will deposit a directory, libpgplot, in the current directory. Use the sudo command to move that directory to /usr/local: sudo mv libpgplot /usr/local /usr/local/lib Next, extract the tarball for /usr/local/lib. It will deposit a directory containing several dynamic libraries (named lib*.so). Use the sudo command to move all of the libraries into /usr/local/lib. cd ./usr_local_lib sudo mv * /usr/local/lib cc Finally, extract the tarball for cc. This will deposit the entire Iman source tree in your current directory. The object files and executable binaries were compiled in-place and are located throughout the tree. -

From Windows to Ubuntu & Ticket to Read Instructions
From Windows to Ubuntu & Ticket to Read Instructions This document is intended to help you use your new computer by helping you understand the Ubuntu Operating system that is installed on it and most often relating it to the same Windows feature that you are more likely to be familiar with. Keep in mind that this is more of a simple starter document, if you want to research more about these topics I would encourage it and let you know that Google [ www.google.com ] is your friend J At the bottom of this document you will find instructions for using www.tickettoread.com as well as other websites requiring Adobe Flash player. Index 1. Setting up your computer. a. Plugging your computer in b. Logging on/Changing your account name/password 2. The Desktop 3. Common Relations to Windows 4. Updating your computer 5. Running Programs in Ubuntu 6. Microsoft Office to LibreOffice 7. Getting New Ubuntu Programs 8. Running Windows Programs (Wine) 9. Help Resources 10. About Ubuntu and Operating Systems 1. Setting up your computer Plugging your computer in: Your computer will need several things attached to it in order for it to work for you. You will need a power supply box, it is about half the size of the computer itself with two cables coming out of it. They a monitor, mouse and keyboard. These plug in relatively straight forward into their own distinctive sockets. Just remember that the computer and monitor will need to plug into the wall to get power, otherwise everything plugs into the computer itself. -

Lecture Note 2. Programming Environment
System Programming Lecture Note 2. Programming Environment September 4, 2020 Jongmoo Choi Dept. of Software Dankook University http://embedded.dankook.ac.kr/~choijm (Copyright © 2020 by Jongmoo Choi, All Rights Reserved. Distribution requires permission) Objectives Discuss the history of Linux Understand key concepts of Linux Learn how to access Linux Learn how to use commands in Linux Learn how to make programs in Linux Refer to Chapter 1, 2 in the LPI 2 Linux Introduction (1/7) Operating System ü Definition: Resource Manager ü Examples: Linux, Windows, OS X and so on. (source: https://www.deviantart.com/nick- os/art/Os-war-choose-your-poison-110510677) (source: https://maxhemingway.com/2015/ (Source: IEEE Spectrum, 2001) 10/21/iot-device-security-considerations-and- security-layers-operating-system/) 3 Linux Introduction (2/7) Linux Definition ü Linux is a clone of the UNIX Operating System ü Written from scratch by Linus B. Torvalds, with assistance from a loosely-knit team of Hackers across the Network ü Univ. of Helsinki in Finland ü May, 1991: Release 0.0.1 version ü 4. September, 2020: Release 5.8.5 (refer to https://www.kernel.org/) 4 Linux Introduction (3/7) Unix-like OSes (Source: wikipedia.org) F POSIX (Portable Operating 5Systems Interface for UNIX) Linux Introduction (4/7) Ken and Dennis 6 Linux Introduction (5/7) Contributors ü GNU (www.gnu.org) § Richard M. Stallman (rms) § Free software ü Minix § Andrew Tanenbaum ü BSD § Bill Joy (cofounder of Sun Microsystems), FFS, TCP/IP, … § Linus Torvalds has said that if 386BSD had been available at the time, he probably would not have created Linux 7 Linux Introduction (6/7) Applications (Source: images at google) 8 Linux Introduction (7/7) Some notes about UNIX and Linux (From LPI Chapter 1) ü Linux is a member of the UNIX family ü One feature of the UNIX is that its development is contributed by many groups, both commercial and noncommercial ü History § 1969~ : UNIX Invented by Ken and Dennis, UNIX 1~7 edition at AT&T § 1975~ : popularly used at universities include Berkeley, MIT and CMU. -
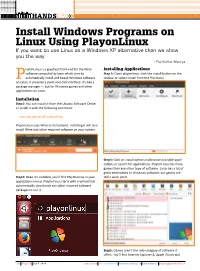
Install Windows Programs on Linux Using Playonlinux If You Want to Use Linux As a Windows XP Alternative Then We Show You the Way - Raj Kumar Maurya
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ -

Advanced Operating Systems
ADVANCED OPERATING SYSTEMS On Microkernel Construction The UNIX Time-Sharing System On micro-Kernel Construction (by Jochen Lietdke, 1995) 2 The topic of how to structure an OS implementation is a religious debate Other religious debates: § Threads vs events § CATOCS (group communication) § Windows vs Linux § Unix vs Unix § PL vs PL § Others? What kind of paper is this? 3 New big idea? Measurement paper? Experiences/lessons learnt paper? A system description? Performance study? Refute-conventional wisdom? Survey paper? What kind of paper is this? 4 Refute-conventional wisdom Big idea (microkernels are fast enough) Brief summary 5 There are two widely held beliefs: § Microkernel systems are inherently inefficient § Microkernel systems are not sufficiently flexible Paper’s claim: these are not correct beliefs Microkernel concept 6 What is the kernel? Microkernel concept 7 What is the kernel? § The part of the OS that is mandatory and common to all other software Microkernel concept: § Minimize the kernel Implement outside the kernel whatever is not absolutely necessary Advantages? Paper’s main message 8 MYTH: microkernels are inefficient and inflexible due to § increased user-kernel mode switches § address space switches (aka context switches) Lietdke states § “maybe it’s the developers at fault – poor implementation, not a poor concept” § If you build a microkernel correctly, then you get good performance AND flexibility § So what should you do? Reason carefully about microkernel concepts What must go in the microkernel?