Limit of Validity of the Models of Linear Regression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In Kanniyakumari District
Erstwhile 20% Reservation given to MBC has now been split as follows Vanniakula Kshatriya (including Vanniyar, Vanniya, Vannia Gounder, 10.5% Gounder or Kander, Padayachi, Palli and Agnikula Kshatriya) PART – MBC AND DNC (A) MOST BACKWARD CLASSES 7% (for 25 Most Backward Communities and 68 Denotified Communities) S.No Community Name 1 Ambalakarar 2 Arayar (in Kanniyakumari District) 3 Bestha, Siviar 4 Bhatraju (other than Kshatriya Raju) 5 Boyar, Oddar 6 Dasari 7 Dommara 8 Jambuvanodai 9 Jogi 10 Koracha 11 Latin Catholic Christian Vannar (in Kanniyakumari District) 12 Mond Golla 13 Mutlakampatti 14 Nokkar Paravar (except in Kanniyakumari District and Shencottah Taluk of Tenkasi District 15 where the Community is a Scheduled Caste) Paravar converts to Christianity including the Paravar converts to Christianity of 16 Kanniyakumari District and Shencottah Taluk of Tenkasi District. Meenavar (Parvatharajakulam, Pattanavar, Sembadavar) (including converts to 17 Christianity). 18 Mukkuvar or Mukayar (including converts to Christianity) 19 Punnan Vettuva Gounder 20 Telugupatty Chetty Thottia Naicker (including Rajakambalam, Gollavar, Sillavar, Thockalavar, Thozhuva 21 Naicker and Erragollar) 22 Valaiyar (including Chettinad Valayars) Vannar (Salavai Thozhilalar) (including Agasa, Madivala, Ekali, Rajakula, Veluthadar 23 and Rajaka) (except in Kanniyakumari District and Shencottah Taluk of Tenkasi District where the community is a Scheduled Caste) 24 Vettaikarar 25 Vettuva Gounder (B) DENOTIFIED COMMUNITIES S.No Community Name Attur Kilnad Koravars -

Covid – 19 Summary Analysis – 29 Nov 2020
DMK IT WING COVID – 19 SUMMARY ANALYSIS – 29 NOV 2020 Dr P.T.R.Palanivel Thiaga Rajan MLA Madurai Central Source : Media Bulletin By Health and Family Welfare Department, Tamil Nadu Govt. 11/30/2020 3 0% % 8 .2 2 7 5% 2 2 0% % 15 O %GT POSITIVECASE% F P OS IT IV 1 E CA POSITIVE CASE PERCENT 0% % 4 S .1 ES 0 B 1 Y D 5% IS TR AGE % I 3 CT 0 O . % N 6 29 N 0% 8 .4 % 5 1 O .4 % V Chennai|398 5 5 EM 3 . % BE Coimbatore|148 5 0 R 8 2020 Thiruvallur|88 . N 4 % U 8 M Chengalpattu|80 9 B . ER Tiruppur|79 3 % O 4 F N Salem|78 .7 % E 2 4 W Erode|70 5 C . % AS Kancheepuram|58 2 9 ES .1 % IN Vellore|40 2 2 TA .9 % M Nilgiris|37 5 I 1 1 L .8 % 00 N Thanjavur|32 1 8 % AD 7 % - U Namakkal|28 . 1 O 1 8 ,4 N .7 % 5 Madurai|27 9 29 1 4 N Cuddalore|26 .6 % O 1 4 V 4 EM Dindigul|26 . % B 1 0 ER Nagapattinam|24 .3 % 2 1 0 02 Trichy|21 1 % 0 . - 1 0 1, Villupuram|19 .1 % 45 1 3 9 Kanyakumari|16 .0 % 1 3 Pudukottai|16 .0 % DISTRICT|NUMBER OF CASES IN THA 1 6 Karur|15 .9 % Thoothukudi|15 0 2 .8 % Tenkasi|14 0 2 .8 % Sivagangai|12 0 5 .7 % Thirupathur|12 0 9 .6 % Ranipet|11 0 9 .6 % Dharmapuri|10 0 2 .6 % Thiruvarur|10 0 2 T DISTRICT .6 % Thiruvannamalai|9 0 5 .5 % Virudhunagar|9 0 8 .4 % Tirunelveli|8 0 1 .4 % Kallakurichi|7 0 7 .2 % Krishnagiri|6 0 7 .2 % Ramanathapuram|4 0 4 .1 % Theni|4 0 0 Ariyalur|2 .0 % 0 0 ASD|0 .0 % 0 0 ASI|0 .0 % 0 0 Perambalur|0 .0 0 RS|0 1 /1 11/30/2020 35% 30% % 4 .5 E 25% 7 S 2 CA L % A 20% O T F T O OT T AL T N G 15% UM % BE R O F TOT 10% P AL POSITIVE CASE PERCENT OS IT IV E CA 5% % S 2 ES .2 % B 6 8 Y AGE 0 D 0% . -
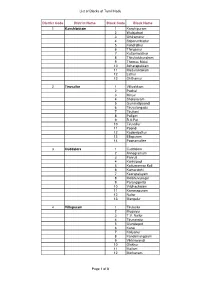
List of Blocks of Tamil Nadu District Code District Name Block Code
List of Blocks of Tamil Nadu District Code District Name Block Code Block Name 1 Kanchipuram 1 Kanchipuram 2 Walajabad 3 Uthiramerur 4 Sriperumbudur 5 Kundrathur 6 Thiruporur 7 Kattankolathur 8 Thirukalukundram 9 Thomas Malai 10 Acharapakkam 11 Madurantakam 12 Lathur 13 Chithamur 2 Tiruvallur 1 Villivakkam 2 Puzhal 3 Minjur 4 Sholavaram 5 Gummidipoondi 6 Tiruvalangadu 7 Tiruttani 8 Pallipet 9 R.K.Pet 10 Tiruvallur 11 Poondi 12 Kadambathur 13 Ellapuram 14 Poonamallee 3 Cuddalore 1 Cuddalore 2 Annagramam 3 Panruti 4 Kurinjipadi 5 Kattumannar Koil 6 Kumaratchi 7 Keerapalayam 8 Melbhuvanagiri 9 Parangipettai 10 Vridhachalam 11 Kammapuram 12 Nallur 13 Mangalur 4 Villupuram 1 Tirukoilur 2 Mugaiyur 3 T.V. Nallur 4 Tirunavalur 5 Ulundurpet 6 Kanai 7 Koliyanur 8 Kandamangalam 9 Vikkiravandi 10 Olakkur 11 Mailam 12 Merkanam Page 1 of 8 List of Blocks of Tamil Nadu District Code District Name Block Code Block Name 13 Vanur 14 Gingee 15 Vallam 16 Melmalayanur 17 Kallakurichi 18 Chinnasalem 19 Rishivandiyam 20 Sankarapuram 21 Thiyagadurgam 22 Kalrayan Hills 5 Vellore 1 Vellore 2 Kaniyambadi 3 Anaicut 4 Madhanur 5 Katpadi 6 K.V. Kuppam 7 Gudiyatham 8 Pernambet 9 Walajah 10 Sholinghur 11 Arakonam 12 Nemili 13 Kaveripakkam 14 Arcot 15 Thimiri 16 Thirupathur 17 Jolarpet 18 Kandhili 19 Natrampalli 20 Alangayam 6 Tiruvannamalai 1 Tiruvannamalai 2 Kilpennathur 3 Thurinjapuram 4 Polur 5 Kalasapakkam 6 Chetpet 7 Chengam 8 Pudupalayam 9 Thandrampet 10 Jawadumalai 11 Cheyyar 12 Anakkavoor 13 Vembakkam 14 Vandavasi 15 Thellar 16 Peranamallur 17 Arni 18 West Arni 7 Salem 1 Salem 2 Veerapandy 3 Panamarathupatti 4 Ayothiyapattinam Page 2 of 8 List of Blocks of Tamil Nadu District Code District Name Block Code Block Name 5 Valapady 6 Yercaud 7 P.N.Palayam 8 Attur 9 Gangavalli 10 Thalaivasal 11 Kolathur 12 Nangavalli 13 Mecheri 14 Omalur 15 Tharamangalam 16 Kadayampatti 17 Sankari 18 Idappady 19 Konganapuram 20 Mac. -

ANNUAL REPORT - 2005-2006 Live to Serve
` ANNUAL REPORT - 2005-2006 Live to Serve AMAR “Amar Seva Sangam's mission is to empower the disabled citizens by establishing a “Valley for the S EVA Disabled” as a Rehabilitation and Development Center for the region and to develop models for self-help S ANGAM initiatives by integrating the disabled individuals with the society for improved living conditions in the village”. Regn.No. TSI/ 16/1981 This is the year Amar Seva Sangam has entered its 25th year of glorious service and we have immense pleasure in presenting the activities that the year 2005-2006 witnessed. To crown it, the donations reached a new high of Rs.1.89 Crores. Awards: Besides many awards received earlier including National Award for the Welfare of People with Disabilities-2002 by President of India. The following awards are received during this year. Mr.S.Sankara Raman, Hony. Secretary was honoured with Helen Keller Award as a "Best Social Worker" by National Centre for Promotion of Employment for Disabled People, New Delhi on December 2nd, 2005 bestowed by Shri Arjun Singh, Human Resource Development Minister, Govt. of India. The Gandhigram Institute conferred an award on Amar Seva Sangam for its ‘Professionalism in Social Work'. The State Bank of India, Southern Region honoured us with an Award as the “Best Social Organization Associated with them" during their Bi-centennial celebrations Mr.S.Sankara Raman received the Award at Chennai on 1st July 05. Events The Juniper Foundation, USA has graciously contributed about Rs.6.8 lakhs for two class rooms equipped with computer facility for the school children and another Rs.5.7 lakhs to meet the recurring expenses of the Middle School. -
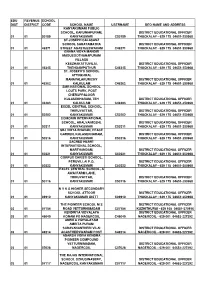
Deo &Ceo Address List
EDU REVENUE SCHOOL DIST DISTRICT CODE SCHOOL NAME USERNAME DEO NAME AND ADDRESS KANYAKUMARI PUBLIC SCHOOL, KARUNIAPURAM, DISTRICT EDUCATIONAL OFFICER 01 01 50189 KANYAKUMARI C50189 THUCKALAY - 629 175 04651-250968 ST.JOSEPH CALASANZ SCHOOL SAHAYAMATHA DISTRICT EDUCATIONAL OFFICER 01 01 46271 STREET AGASTEESWARAM C46271 THUCKALAY - 629 175 04651-250968 GNANA VIDYA MANDIR MADUSOOTHANAPURAM VILLAGE KEEZHAKATTUVILAI, DISTRICT EDUCATIONAL OFFICER 01 01 46345 THENGAMPUTHUR C46345 THUCKALAY - 629 175 04651-250968 ST. JOSEPH'S SCHOOL ATTINKARAI, MANAVALAKURICHY DISTRICT EDUCATIONAL OFFICER 01 01 46362 KALKULAM C46362 THUCKALAY - 629 175 04651-250968 SMR NATIONAL SCHOOL LOUTS PARK, POST CHERUPPALOOR KULASEKHARAM, TEH DISTRICT EDUCATIONAL OFFICER 01 01 46383 KALKULAM C46383 THUCKALAY - 629 175 04651-250968 EXCEL CENTRAL SCHOOL, THIRUVATTAR, DISTRICT EDUCATIONAL OFFICER 01 01 50202 KANYAKUMARI C50202 THUCKALAY - 629 175 04651-250968 COMORIN INTERNATIONAL SCHOOL, ARALVAIMOZHI, DISTRICT EDUCATIONAL OFFICER 01 01 50211 KANYAKUMARI C50211 THUCKALAY - 629 175 04651-250968 SBJ VIDYA BHAVAN, PEACE GARDEN, KULASEKHARAM, DISTRICT EDUCATIONAL OFFICER 01 01 50216 KANYAKUMARI C50216 THUCKALAY - 629 175 04651-250968 SACRED HEART INTERNATIONAL SCHOOL, MARTHANDAM, DISTRICT EDUCATIONAL OFFICER 01 01 50221 KANYAKUMARI C50221 THUCKALAY - 629 175 04651-250968 CORPUS CHRISTI SCHOOL, PERUVILLAI P.O, DISTRICT EDUCATIONAL OFFICER 01 01 50222 KANYAKUMARI C50222 THUCKALAY - 629 175 04651-250968 EXCEL CENTRAL SCHOOL, A AWAI FARM LANE, THIRUVATTAR, DISTRICT EDUCATIONAL OFFICER -

Officials from the State of Tamil Nadu Trained by NIDM During the Year 209-10 to 2014-15
Officials from the state of Tamil Nadu trained by NIDM during the year 209-10 to 2014-15 S.No. Name Designation & Address City & State Department 1 Shri G. Sivakumar Superintending National Highways 260 / N Jawaharlal Nehru Salai, Chennai, Tamil Engineer, Roads & Jaynagar - Arumbakkam, Chennai - 600166, Tamil Nadu Bridges Nadu, Ph. : 044-24751123 (O), 044-26154947 (R), 9443345414 (M) 2 Dr. N. Cithirai Regional Joint Director Animal Husbandry Department, Government of Tamil Chennai, Tamil (AH), Animal husbandry Nadu, Chennai, Tamil Nadu, Ph. : 044-27665287 (O), Nadu 044-23612710 (R), 9445001133 (M) 3 Shri Maheswar Dayal SSP, Police Superintending of Police, Nagapattinam District, Tamil Nagapattinam, Nadu, Ph. : 04365-242888 (O), 04365-248777 (R), Tamil Nadu 9868959868 (M), 04365-242999 (Fax), Email : [email protected] 4 Dr. P. Gunasekaran Joint Director, Animal Animal Husbandary, Thiruvaruru, Tamil Nadu, Ph. : Thiruvarur, Tamil husbandary 04366-205946 (O), 9445001125 (M), 04366-205946 Nadu (Fax) 5 Shri S. Rajendran Dy. Director of Department of Agriculture, O/o Joint Director of Ramanakapuram, Agriculture, Agriculture Agriculture, Ramanakapuram (Disa), Tamil Nadu, Ph. : Tamil Nadu 04567-230387 (O), 04566-225389 (R), 9894387255 (M) 6 Shri R. Nanda Kumar Dy. Director of Statistics, Department of Economics & Statistics, DMS Chennai, Tamil Economics & Statistics Compound, Thenampet, Chennai - 600006, Tamil Nadu Nadu, Ph. : 044-24327001 (O), 044-22230032 (R), 9865548578 (M), 044-24341929 (Fax), Email : [email protected] 7 Shri U. Perumal Executive Engineer, Corporation of Chennai, Rippon Building, Chennai - Chennai, Tamil Municipal Corporation 600003, Ph. : 044-25361225 (O), 044-65687366 (R), Nadu 9444009009 (M), Email : [email protected] National Institute of Disaster Management (NIDM) Trainee Database is available at http://nidm.gov.in/trainee2.asp 58 Officials from the state of Tamil Nadu trained by NIDM during the year 209-10 to 2014-15 8 Shri M. -

State Environment Impact Assessment Authority (SEIAA) Tamil Nadu 443
State Environment Impact Assessment Authority (SEIAA) Tamil Nadu 443 SEIAA Meeting AGENDA Venue: SEIAA Office Please Check MoEF&CC Website at www.parivesh.nic.in for details and updates From Date:05 May 2021 TO Date:05 May 2021 CONSIDERATION/RECONSIDERATION OF ENVIRONMENTAL CLEARANCE S.No Proposal K.Jayaprakash,Rough stone and Gravel quarry Extent of 1.59.5ha in S.F.Nos. 592/1B2A (P) & 592/1B2B (P) at Myvadi Village of Madathukulam Taluk, Tiruppur District S. (1) State District Tehsil Village No. (1.) Tamil Nadu Tiruppur Madathukulam Myvadi [SIA/TN/MIN/128588/2019 , 7124 ] N.Muthukumar,Gravel Quarry,Extent: 1.02.5Ha,S.F.NoS. 675/5 Udayarpalayam (East) Village, Udayarpalayam Taluk, Ariyalur District S. State District Tehsil Village (2) No. Udayarpalayam (1.) Tamil Nadu Ariyalur Udayarpalayam (East) [SIA/TN/MIN/139838/2020 , 7431 ] Thiru M.Munichandrappa Rough Stone Quarry over a total extent of 1.28.5 Ha in Alur Village S. State District Tehsil Village (3) No. (1.) Tamil Nadu Krishnagiri Hosur Alur [SIA/TN/MIN/158249/2020 , 7603 ] Thiru.D.Sundararajan Rough stone Quarry S. State District Tehsil Village (4) No. (1.) Tamil Nadu Perambalur Perambalur Keelakkarai [SIA/TN/MIN/165419/2020 , 7698 ] ROUGH STONE QUARRY OF THIRU.P.MANIKANDAN, AT SURVEY (5) NO.6/1 (PART-4) OVER AN AREA OF 1.00.0HA IN PAVUPATTU VILLAGE, TIRUVANNAMALAI TALUK, TIRUVANNAMALAI DISTRICT S. State District Tehsil Village No. Pavupattu (1.) Tamil Nadu Tiruvannamalai Tiruvannamalai Village (part- 4) [SIA/TN/MIN/169314/2020 , 7826 ] R.Lakshmanan Brick Earth Ex 0.79.5ha Karapattu Village S.F.NO 310/3B and 311/2 Ambur Tk Tirupathur DT S. -

The Tamil Nadu Special Reservation of Seats in Educational Institutions
The Tamil Nadu Special Reservation of seats in Educational Institutions including Private Educational Institutions and of appointments or posts in the services under the State within the Reservation for the Most Backward Classes and Denotified Communities Act, 2021 Act 8 of 2021 Keywords: Denotified Communities, Most Backward Classes of Citizens DISCLAIMER: This document is being furnished to you for your information by PRS Legislative Research (PRS). The contents of this document have been obtained from sources PRS believes to be reliable. These contents have not been independently verified, and PRS makes no representation or warranty as to the accuracy, completeness or correctness. In some cases the Principal Act and/or Amendment Act may not be available. Principal Acts may or may not include subsequent amendments. For authoritative text, please contact the relevant state department concerned or refer to the latest government publication or the gazette notification. Any person using this material should take their own professional and legal advice before acting on any information contained in this document. PRS or any persons connected with it do not accept any liability arising from the use of this document. PRS or any persons connected with it shall not be in any way responsible for any loss, damage, or distress to any person on account of any action taken or not taken on the basis of this document. © [Regd. No. TN/CCN/467/2012-14. GOVERNMENT OF TAMIL NADU [R. Dis. No. 197/2009. 2021 [Price: Rs. 4.80 Paise. TAMIL NADU GOVERNMENT GAZETTE EXTRAORDINARY PUBLISHED BY AUTHORITY No.No. 144] 144] CHENNAI,CHENNAI, FRIDAY,FRIDAY, FEBRUARY 26,26, 20212021 MaasiMaasi 14,14, Saarvari, Thiruvalluvar Aandu–2052Aandu–2051 Part IV—Section 2 Tamil Nadu Acts and Ordinances The following Act of the Tamil Nadu Legislative Assembly received the assent of the Governor on the 26th February 2021 and is hereby published for general information:— ACT No. -

District Library Office, Tirunelveli Branch Library Address
DISTRICT LIBRARY OFFICE, TIRUNELVELI BRANCH LIBRARY ADDRESS 1. Librarian 9. Librarian District Central Library Branch Library 2/32 North High Ground Road 35 N.H. Colony Palayamkottai 627 002 Perumalpuram 627 007 Tirunelveli .2 Palayamkottai Circle 0462-2561712 Tirunelveli Ditrict 2. Branch Librarian 10. Branch Librarian Siruvar Noolagam Branch Library Centuary Hall Road D 86 IInd Main Road Near to Lourdunathan Silai Maharaja Nagar 627 011 Palayamkottai 627 002 Palayamkottai Circle Tirunelveli District Tirunelveli District 3. Branch Librarian 11.Branch Librarian Branch Library Branch Library 60 V.K. Road Main Road Meenakshipuram Gopalasamudram 627 451 Tirunelveli Junction 627 001 Palayamkottai Circle Tirunelveli District 4. Branch Librarian 12. Branch Librarian Branch Library Branch Library 37 Kottikulam Road Irattai Vinayagar Koil Street Melapalayam 627 005 Sivalaperi 627 361 Palayamkottai Circle Palayamkottai Circle Tirunelveli District Tirunelveli District 5. Branch Librarian 13. Librarian Branch Library – II First Grade Library 167 Anna Veethi Bose Market Upstair Melapalayam 627 005 Tirunelveli Nagar 627 006 Palayamkottai Circle Tirunelveli Circle Tirunelveli District Tirunelveli District 6. Branch Librarian 14. Branch Librarian Branch Library Branch Library Keela Theru 13 Veerabagu Nagar Rettiyar Patti 627 007 Pettai 627 004 Palayamkottai Circle Tirunelveli Circle Tirunelveli District Tirunelveli District 7. Branch Librarian 15. Branch Librarian Branch Library Branch Library Vannarpettai 627 003 Near to Post Office Palayamkottai Circle Thallaiyuthu 627 357 Tirunelveli District Tirunelveli Circle Tirunelveli District 8. Branch Librarian 16.Branch Librarian Branch Library Branch Library 3/64 Perumal koil sannathi Theru Bharathiar Theru Thimmarajapuram 627 353 Tirunelveli Town 627 006 Palayamkottai Circle Tirunelveli Circle Tirunelveli District Tirunelveli District … 2 … 17. Branch Librarian 25. -

Kanyakumari District
KANYAKUMARI DISTRICT 1 KANYAKUMARI DISTRICT 1. Introduction i) Geographical location of the district Kanyakumari is the Southern most West it is bound by Kerala. With an area of district of Tamil Nadu. The district lies 1672 sq.km it occupies 1.29% of the total between 77 o 15 ' and 77 o 36 ' of the Eastern area of Tamil Nadu. It ranks first in literacy Longitudes and 8 o 03 ' and 8 o 35 ' of the among the districts in Tamil Nadu. Northern Latitudes. The district is bound by Tirunelveli district on the North and the East. ii) Administrative profile The South eastern boundary is the Gulf of The administrative profile of Mannar. On the South and the South West, Kanyakumari district is given in the table the boundaries are the Indian Ocean and the below Arabian sea. On the west and North Name of the No. of revenue Sl. No. Name of taluk No. of firka division villages 1 Agastheeswaram 4 43 1 Nagercoil 2 Thovalai 3 24 3 Kalkulam 6 66 2 Padmanabhapuram 4 Vilavancode 5 55 Total 18 188 ii) 2 Meteorological information and alluvial soils are found at Based on the agro-climatic and Agastheeswaram and Thovalai blocks. topographic conditions, the district can be divided into three regions, namely: the ii) Agriculture and horticulture uplands, the middle and the low lands, which are suitable for growing a number of crops. Based on the agro-climatic and The proximity of equator, its topography and topographic conditions, the district can be other climate factors favour the growth of divided into three regions, namely:- various crops. -

Ggtamilnadu State Transport Corporation(Tirunelveli) Ltd., Tirunelveli
1 GGTAMILNADU STATE TRANSPORT CORPORATION(TIRUNELVELI) LTD., TIRUNELVELI 1. History of TAMILNADU STATE TRANSPORT CORPORATION(TIRUNELVELI)Ltd FORMATION: This Corporation was formed by bifurcating from the established Pandian Roadways Corporation and registered under the Companies Act on 12.12.1973 as Kattabomman Transport Corporation Ltd and started its business from 01.01.1974 with the Head Quarters at Nagercoil. Then on 01.04.1983, this Corporation was bifurcated as Kattabomman Transport Corporation Ltd, having its Head Quarters at Tirunelveli to cater to the need of the public of then Tirunelveli & Thoothukudi Districts, and Nesamony Transport corporation Ltd, having its Head quarters at Nagercoil to cater the need of the public of Kanyakumari District . Again, the name of the Kattabomman Transport Corporation Ltd was changed as Tamil Nadu State Transport Corporation(MDU.Dvn-II)Ltd.,Tirunelveli and Nesamony Transport corporation Ltd was changed as Tamil Nadu State Transport Corporation(MDU.Dvn-III)Ltd.,Nagercoil with effect from 01.07.1997.Then this Corporation was amalgamated with Tamil nadu State Transport Corporation (Madurai)Ltd., under Amalgamation Policy , with the Head Quarters at Madurai from 12.02.2004 and made this as a Region under the direct control of the Managing Director,Madurai. 2 Again,Tamil Nadu State Transport Corporation (Tirunelveli) Ltd., Tirunelveli started its functions as a separate entity from 01/11/2010 onwards on bifurcation of the composite TNSTC(Madurai) Ltd., Madurai.For the benefit of the public of Thoothukudi District ,Thoothukudi region under the control of General manager was formed on 20.06.2013 with Six branches. The Hon’ble Chief Minister has ordered to increase the bus depots based on the fleet strength. -

List of Treasuries /Sub Treasuries with Code
LIST OF TREASURIES/SUB TREASURIES AGRICULTURAL AEW AGRICULTURAL ENGINEERING WORKS ENGINEERING WORKS ARIYALUR ARL ARIYALUR ARI ARIYALUR JAY JAYANKONDACHOLAPURAM SEN SENDURAI CHENGLEPET- CGT CHENGLEPET-KANCHEEPURAM KANCHEEPURAM ALN ALANDUR ALR WALAJABAD CGP CHINGLEPUT CHR CHEYYUR MDK MADURANTAKAM MML MAMALLAN NAGAR/KANCHEEPURAM ST SNR SHOLINGANALLUR SPR SRIPERUMBUDUR TAM TAMBARAM TNR TIRUKKALIKUNDRAM TRO TIRUPORUR UMR UTHIRAMERUR WBD WALAJABAD CHENNAI MDS CHENNAI EGM EGMORE, NUNGAMBAKKAM MYL MYLAPORE, TRIPLICANE PRB PERAMBUR, PURUSAWAKKAM SDT SAIDAPET, MAMBALAM, GUINDY COIMBATORE CBE COIMBATORE ANR ANNUR CBN COIMBATORE(NORTH)/TATABAD GNP COIMBATORE NORTH/GANAPATHY KNK KINATHUKADAVU MET METTUPALAYAM POL POLLACHI SCB COIMBATORE SOUTH SLR SULUR TOWN TTB TATABAD(COIMBATORE) VPR VALPARAI CUDDALORE VAL CUDDALORE CHD CHIDAMBARAM CUD TIRUPPAPULIYUR/ CUDDALORE ST KNJ KURUNJIPADI KTK KATTUMANNAKOIL NEY NEYVELI PNT PANRUTTI TIT TITTAGUDI VRC VRIDHACHALAM LIST OF TREASURIES/SUB TREASURIES DHARMAPURI DMP DHARMAPURI DMT DHARMAPURI TOWN/DHARMAPURI ST HAR HARUR PAP PAPPIREDDIPATTY/ KOZHIMEKKANUR/MOLIANUR PLC PALACODE PNG RMY PENNAGARAM DINDIGUL DGL DINDIGUL ATH ATHOOR KDK KODAIKANAL NHR NEHRUJI NAGAR, DGL/DINDIGUL ST NLK NILAKOTTAI NTM NATHAM ODN ODDANCHATHRAM PLN PALANI VDS VEDASANDUR ERODE PRY ERODE ANR ANTHIYUR BVN BHAVANI ERD ERODE GBP GOBICHETTIPALAYAM KDM KODUMUDI ADB PRN PERUNDURAI SMG SATHYAMANGALAM IB PAPPIREDDIPATTY/ PAP PAO PENSION KOZHIMEKKANUR/MOLI ANUR KANYAKUMARI KKM KANYAKUMARI BPT THOVALAI/BHOOTHAPANDY BTP BHOOTHAPANDY KLK KALKULAM/THUCKALAY