HP IBRIX 9000 Storage File System User Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HP 9000 Rp4410-4 and Rp4440-8 Servers Data Sheet
HP 9000 rp4410-4 and rp4440-8 Servers Data sheet From entry-class 2-processor systems up to the high-end, 128-way HP 9000 Superdome, the HP 9000 server family delivers world-class, high- performance computing to the Adaptive Enterprise. Powered by the new PA-8900 processor with increased performance—and running the HP-UX 11i operating environment—HP 9000 servers add greater strength to HP’s industry-leading server portfolio by integrating seamlessly into your existing IT infrastructure and providing the type of longevity that’s crucial to protecting your investment. HP introduces new 1-, 2-, and 4-way systems to its the high-availability features you’d expect in an enterprise HP 9000 family with the HP 9000 rp4410-4 Server, application server, and its elegant server design makes while offering improved 8-way scalability in the HP 9000 for easy installation, upgrading, and service. With rp4440-8 Server. Each server offers up to 128 GB of excellent performance scalability and dense form factor, memory, runs the rock-solid HP-UX 11i operating system, the HP 9000 rp4410-4 and rp4440-8 Servers deliver the and is powered by the new PA-8900 processor, which performance required for critical business applications delivers improved performance and larger memory cache such as ERP, CRM, and e-commerce—while conserving IT than before. The HP 9000 rp4400 server series has all of funds and data-center space. Key features: Key benefits: HP 9000 rp4410-4 and rp4440-8 HP 9000 rp4410-4 and rp4440-8 Servers Servers • Latest generation of PA-RISC PA-8900 -

Hp 9000 & Hp-Ux
HP 9000 & HP-UX 11i: Roadmap & Updates Ric Lewis Mary Kwan Director, Planning & Strategy Sr. Product Manager Hewlett-Packard Hewlett-Packard © 2004 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice Agenda • HP Integrity & HP 9000 Servers: Roadmap and Updates • HP-UX 11i : Roadmap & Updates HP-UX 11i - Proven foundation for the Adaptive Enterprise 2 HP’s industry standards-based server strategy Moving to 3 leadership product lines – built on 2 industry standard architectures Current Future HP NonStop server Industry standard Mips HP NonStop HP Integrity server Common server Itanium® technologies Itanium® Enabling larger • Adaptive HP 9000 / investment in HP Integrity Management e3000 server value-add PA-RISC server innovation Itanium® • Virtualization HP AlphaServer systems • HA Alpha HP ProLiant server • Storage HP ProLiant server x86 • Clustering x86 3 HP 9000 servers Max. CPUs Up to 128-way • 4 to 128 PA-8800 processors (max. 64 per partition) HP Superdome scalability with hard 128 and virtual partitioning • Up to 1 TB memory server for leading • 192 PCI-X slots (with I/O expansion) consolidation • Up to 16 hard partitions • 2 to 32 PA-8800 processors HP 9000 32-way scalability 32 with virtual and hard • Up to 128 GB memory rp8420-32 server partitioning for • 32 PCI-X slots (with SEU) consolidation • Up to 4 hard partitions (with SEU) • 2 servers per 2m rack 16-way flexibility • 2 to 16 PA-8800 processors with high • Up to 64 GB memory HP 9000 16 performance, • 15 PCI-X slots -

Meet the HP Superdome Servers
Overview of the HP 9000 rp3410-2, rp3440-4, rp4410-4, and rp4440-8 Servers A technical white paper from HP Executive summary............................................................................................................................... 3 Introducing the PA-8900 processor ........................................................................................................ 3 Introducing the HP 9000 rp4410-4 Server.............................................................................................. 4 HP 9000 PA-8900–based servers.......................................................................................................... 4 HP 9000 rp3410-2 and 3440-4 Servers ................................................................................................ 4 HP 9000 rp3410-2 Server at a glance ............................................................................................... 4 HP 9000 rp3410-2 Server details...................................................................................................... 4 HP 9000 rp3410-2 Server product specifications............................................................................. 4 Physical and environmental specifications ....................................................................................... 6 HP 9000 rp3440-4 Server at a glance ............................................................................................... 6 HP 9000 rp3440-4 Server details..................................................................................................... -

Virtualizing Legacy PA-RISC Based Servers and Applications
Virtualizing Legacy PA-RISC Based Servers and Applications Patrick Wallek Critical Systems Software Engineer Service IT Direct ©2018 Service IT Direct, Inc. All rights reserved. Virtualizing Legacy PA-RISC Based Servers and Applications Table of Contents Abstract 3 Customer Problems 3 Customer 1 Legacy Configuration 4 Test & Development Servers 4 Production Servers 4 Totals 5 Customer 2 Legacy Configuration 6 Servers & Storage 6 Totals 7 Solution 8 What are HP9000 Containers? 8 Customer 1 Solution 9 Customer 2 Solution 10 Container Setup 11 Conclusion 12 About Service IT Direct 13 2 www.serviceitdirect.com ©2018 Service IT Direct, Inc. All rights reserved. Virtualizing Legacy PA-RISC Based Servers and Applications Abstract Hewlett Packard Enterprise (HPE) offers a product called HPE 9000 Containers. This product allows you to virtualize older, legacy, PA-RISC based HP-UX servers and their applications onto newer Itanium-based HP-UX servers. In this white paper we will explore how Service IT Direct has used this product with two of its customers to increase their application performance and availability while decreasing rack space usage, power and cooling requirements, and maintenance costs. Customer Problems Service IT Direct was approached by two customers asking for a solution that would allow them to modernize their aging PA-RISC based hardware, running HP-UX, and storage environment. However, they still need to run legacy versions of the HP-UX operating system and their databases and applications currently in production. Some of the reasons given for this request were: age of the hardware; increasing number of service calls for the hardware; increasing cost of hardware maintenance; system and application performance, or lack thereof; lack of system redundancy; rack space usage; power inefficiency. -
HP 9000 Model K460 Enterprise Server Client/Server with 8 E Series
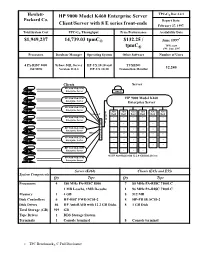
Hewlett- HP 9000 Model K460 Enterprise Server TPC-C® Rev 3.2.1 Packard Co. Report Date: Client/Server with 8 E series front-ends February 27, 1997. Total System Cost TPC-C® Throughput Price/Performance Availability Date * $1,949,237 14,739.03 tpmC® $132.25 / June 1997 tpmC *HW: now ® SW: June 1997 Processors Database Manager Operating System Other Software Number of Users 4 PA-RISC 8000 Sybase SQL Server HP-UX 10.10 and TUXEDO 180 MHz Version 11.0.3 HP-UX 10.30 Transaction Monitor 12,240 Clients Server HP 9000 Model E45 Enterprise Server console HP 9000 Model E45 HP 9000 Model K460 Enterprise Server Enterprise Server HP 9000 Model E45 Enterprise Server F Auto Auto Auto Auto Auto Auto 10Base-T D Raid Raid Raid Raid Raid Raid HP 9000 Model E45 ’’ ’’ ’’ ’’ ’’ ’’ Enterprise Server D S I W ’’ ’’ ’’ ’’ ’’ ’’ HP 9000 Model E45 I Enterprise Server T ’’ ’’ ’’ ’’ ’’ ’’ 10Base-T C ’’ ’’ ’’ ’’ ’’ ’’ HP 9000 Model E45 H Enterprise Server ’’ ’’ ’’ ’’ ’’ ’’ ’’ ’’ ’’ ’’ ’’ ’’ HP 9000 Model E55 Enterprise Server ’’ ’’ ’’ ’’ 46 HP AutoRaid with 12 2.0 GB Disk Drives HP 9000 Model E45 Enterprise Server Server (K460) Clients (E45s and E55) System Components Qty Type Qty Type Processors 4 180 MHz PA-RISC 8000 7 80 MHz PA-RISC 7100LC 1 MB I-cache, 1MB D-cache 1 96 MHz PA-RISC 7100LC Memory 1 4 GB 8 512 MB Disk Controllers 6 HP-HSC FWD SCSI-2 8 HP-PB SE SCSI-2 Disk Drives 46 HP AutoRAID with 12 2 GB Disks 8 1 GB Disk Total Storage (GB) 919 GB Tape Drives 1 DDS Storage System Terminals 1 Console terminal 8 Console terminal v TPC Benchmark® C Full Disclosure Hewlett- TPC-C® Rev 3.2.1 Packard Co. -

HP9000 Series 9000/700/800 HP-UX Application Software DVD Part Number - 5014-1459
HP9000 Series 9000/700/800 HP-UX Application Software DVD Part Number - 5014-1459 1 of 1 DVDs DVD CONTENT LIST CPL Product: 100BaseT-00 Codeword Req.: No Size: 589243 Description: EISA 100BaseT;Supptd HW=A4308B;SW=J2780BA CPL Product: 100BaseT-01 Codeword Req.: No Size: 1315789 Description: HP-PB 100BaseT;Supptd HW=A3495A;SW=J2759BA CPL Product: 10GigEthr-00 Codeword Req.: No Size: 1037317 Description: PCI-X 10 Gigabit Ethernet;Supptd HW=AB287, HW=AD385 CPL Product: 32070B Codeword Req.: Yes Size: 74763773 Description: OSI Trnspt and Srvcs for 9000/800 CPL Product: ATM-00 Codeword Req.: No Size: 12609950 Description: PCI ATM;Supptd HW=A5483A/A5513A/A5515A/J3557A;SW=J3572AA/J3572BA CPL Product: ATM-01 Codeword Req.: No Size: 12452735 Description: HSC ATM;Supptd HW=J2468A/J2469A/J2499A/J3420B/J3573A;SW=J2806CA CPL Product: AppDiscAgent Codeword Req.: No Size: 3369261 Description: HP Application Discovery Agent CPL Product: B1033B Codeword Req.: Yes Size: 13857060 Description: FTAM bundle CPL Product: B2491BA Codeword Req.: Yes Size: 1397973 Description: MirrorDisk/UX CPL Product: B3187B Codeword Req.: Yes Size: 1570423 Description: DCE/9000 CDS Server, Media and Manuals CPL Product: B3188B Codeword Req.: Yes Size: 8005390 Description: DCE/9000 Security Server, Media and Manuals CPL Product: B3394BA Codeword Req.: No Size: 58233585 Description: HP-UX Developer's Toolkit for 11.11 CPL Product: B3693AA Codeword Req.: Yes Size: 32871198 Description: HP GlancePlus/UX For HP-UX 11i CPL Product: B3693AA_TRY Codeword Req.: No Size: 32871198 Description: -

HP Laserjet 9000 Series Uninstaller
hp LaserJet 9000 9000n•9000dn•9000hns software technical reference Software Technical Reference for the HP LaserJet 9000 printers Notice The information contained in this document is subject to change without notice. HEWLETT-PACKARD COMPANY MAKES NO WARRANTY OF ANY KIND WITH REGARD TO THIS MATERIAL, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. Hewlett-Packard shall not be liable for errors contained herein or for incidental or consequential damages in connection with the furnishing, performance, or use of this material. Version 1 (5/01) (C) Copyright Hewlett-Packard Company 2001. All rights reserved. Reproduction, adaptation, or translation without prior written permission is prohibited, except as allowed under the copyright laws. Trademark notices Adobe (R), Acrobat (R) , Reader (TM) and PostScript (R) are trademarks of Adobe Systems Incorporated. AutoCAD (TM) is a U.S. trademark of Autodesk, Inc. Java (TM) is a U.S. trademark of Sun Microsystems, Inc. Microsoft (R), Windows (R), and Windows NT (R) are U.S. registered trademarks of Microsoft Corporation. Netscape and Netscape Navigator are trademarks or registered trademarks of Netscape Communications, Inc. TrueType (TM) is a U.S. trademark of Apple Computer, Inc. UNIX (R) is a registered trademark of the Open Group. ii Software Technical Reference for the HP LaserJet 9000 printers Table of Contents Notice .............................................................................................................................................................................. -

Service Processor (GSP Or MP) User Guide
Service Processor (GSP or MP) User Guide HP Part Number: A5201-90017-ed2 Published: October 2009 Edition: 2nd Edition © Copyright 2004-2009 Legal Notices The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Printed in U.S.A. Intel, Pentium, Intel Inside, Itanium, and the Intel Inside logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Linux is a U.S. registered trademark of Linus Torvalds. Table of Contents About This Document.........................................................................................................7 Intended Audience.................................................................................................................................7 Publishing History..................................................................................................................................7 Document Organization.........................................................................................................................7 Typographic Conventions......................................................................................................................8 HP-UX Release Name and Release Identifier.........................................................................................8 -

Hp 9000 Rp4440 Operation and Maintenance Guide
hp 9000 rp4440 Operation and Maintenance Guide Regulatory Model Number: RSVLA-0201 Manufacturing Part Number: rp4440_OpMaint January 2004 U.S.A. © Copyright 2004 Hewlett-Packard Development Company, L.P.. Legal Notices Copyright Notices. ©Copyright 2004 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Adobe and Acrobat are trademarks of Adobe Systems Incorporated. HP-UX Release 10.20 and later and HP-UX Release 11.00 and later (in both 32 and 64-bit configurations) on all HP 9000 computers are Open Group UNIX 95 branded products. Itanium is a trademark or registered trademark of Intel Corporation or its subsidiaries in the United States and other countries. Linux is a registered trademark of Linus Torvalds. UNIX is a registered trademark of The Open Group. Windows is a registered trademark of Microsoft Corporation. Printed in the U.S.A. Reproduction, adaptation, or translation of this document without prior written permission is prohibited, except as allowed under the copyright laws. Related Documents. The HP Server Documentation CD-ROM has been provided with your server. It contains a complete documentation set for the server, including localized versions of key documents. Included on the CD-ROM are the Site Preparation and Operations and Maintenance guides, which contain in-depth troubleshooting, installation, and repair information. -

COMPUTATION ,, ,, - Product Advances from Hewlettmpackard
MEASUREMENT a COMPUTATION ,, ,, - product advances from HewlettmPackard HP's new transportable personal computer offers the UNIXTMoperating system Now you can have the power of a UNIX'" operating system Multitasking, multiwindow capabilities in a personal, transportable computer. Hewlett-Packard's The Integral PC can perform several processes at the same new Integral Personal Computer is a 25-pound, flexible-disc- time. It can print files or monitor instruments while you do based computer with multitasking and multiwindow capabil- other computer-aided activities such as spreadsheet analysis. ities. Its operating system is HP-UX*/RO 2.1, derived from You can keep track of all these activites by using the HP the UNIX System 111 operating system. Based on the Motorola Windows capability, which provides layering of multiple 24 68000 16132-bit processor and a 16-bit HP graphics processor, line-by-80-character windows in the display. this powerful computer provides fast response to user com- mands, including graphics commands. Expandable memory and 110 capabilities The Integral PC's name derives from its fully integrated Standard memory is 800K bytes, including512K bytes of user packaging. Housed within this single unit are a built-in RAM and 32K bytes of display RAM. An additional 1.5M bytes ThinkJet Printer, a 90-key full-size keyboard with numeric of RAM can be installed in the system itself, and up to 5.5M bytes can be achieved by using optional dual bus expanders. aad, a 3 112-inch double-sided disc drive, and a nine-inch electroluminescent display. The 512-X-255-pixel flat-panel The Integral PC's 256K-byte ROM contains the operating amber display is bit-mapped and features an adjustable view- system, HP Windows, and Personal Applications Manager ing angle for easy reading. -

Hewlett Packard
HEWLETT PACKARD Computer News for HP OEMs and Independent Software VendorsFocus May 1985 - INTERNATIONAL VERSION MARKETING New high-performance graphics system 3 General introduced June commercial VAR conference to focus on HP-UX 5.0 now available for HP 9000 "Leaders In Solutions" Series 500 Software Supplier Survey - Hewlett-Packard ME solutions on the HP 987008 Graphics invites your comments Display Station 4 Supplies HP-HIL input devices for the HP 98700H Graphics System HP's Spring/Summer 1985 Computer Users Catalog published New server and cables enhance SRM system DMK direct order phone numbers HP 9000 language system obsolescence HP 9000 Series 200 BASIC and Pascal now on PERSONAL COIVIPUTERS double-sided media 5 HP Series 80 BUSINESS COMPUTERS New extended mass storage ROM for HP Series 80 personal computers 19 HP3000 HP 3000 Series 37 pricing structure update 5 HP 1 00 Series HP 7914CT supported on HP 3000 The HP 150 11 personal computer family HP 9144A and HP 7945A supported across HP Touch accessory available for HP 150 11 HP 3000 line personal computer Introducing EtherStart/l50 PERIPHERALS New personal data storage solutions for HP 150 11personal computer 20 Mass Storage Software Catalog for the HP 150 personal New mass storage alternative for HP 1000 and 0 computer and The Portable HP 9000 systems Introducing the new Touchscreen Technical System support on the new HP 7907A products Discontinuance plans for HP 7970/7971 tape New high-performance, low-cost data product family acquisition system for the HP Integral PC 22 Networks -

HP 9000 Superdome Data Sheet
HP 9000 Superdome Data sheet From entry-class 2-processor systems up to the high-end, 128-way HP 9000 Superdome, the HP 9000 server family delivers world-class, high-performance computing to the Adaptive Enterprise. Powered by the new PA-8900 processor with increased performance—and running the HP-UX 11i operating environment—HP 9000 servers add greater strength to HP’s industry-leading server portfolio by integrating seamlessly into your existing IT infrastructure and providing the type of longevity that’s crucial to protecting your investment. The HP 9000 Superdome delivers world-leading anything previously offered. Featuring unmatched performance density, unmatched investment protection, processor density of up to 128 processors per system, the and the ideal platform to reduce complexity through HP Super-Scalable Processor Chipset sx1000, flexible enhanced server consolidation. The HP 9000 Superdome, hard and virtual partitioning, and outstanding memory with the new PA-8900 processor, delivers breakthrough scalability, the HP 9000 Superdome provides high- performance improvements based on increased clock performance, high-availability, 64-bit UNIX® computing to speeds and cache levels over the previous generation of handle your most demanding workloads. PA-RISC processors—and a level of value well beyond Key features: Key benefits: HP 9000 Superdome HP 9000 Superdome • New PA-8900 processors, cell-based technology, and • Blazing-fast application performance to meet your the HP Super-Scalable Processor Chipset sx1000 demanding business