A Formal Study of Syllable, Tone, Stress and Domain in Chinese Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Contrastive Study Farah Hafedh Ibrahim College of Arts,Mustansiriyah University, Baghdad, Iraq Email : [email protected]
36 Syllables in English and Arabic : A contrastive Study Farah Hafedh Ibrahim College of Arts,Mustansiriyah University, Baghdad, Iraq Email : [email protected] Abstract The present study investigates syllables in both English and Arabic for the sake of revealing the similarities and differences between them in these two languages. The syllable is regarded as the basic unit or the building block of speech that has attracted the attention of English and Arab phoneticians. The present study tackles the nature of English and Arabic syllables, sheds light on some of the theories that described them as well as classifying them into types and describing their structure. The study arrives at the conclusion that there are many differences between syllables in English and syllables in Arabic. These differences concern the way syllables are viewed, their types and their structure. However, both languages consider the syllable to be the basic unit of speech. Phonetically, syllables are described in English as consisting of a centre which has little or no obstruction to airflow preceded and followed by great obstruction; whereas in Arabic, syllables are phonetically described as chest pulses. Keywords: Syllable; Syllable Nature; Syllable Type; Structure Introduction The term syllable, in English language, is not easy to define since it can be defined phonetically, or phonologically or both phonetically and phonologically. Starting with Ladefoged (2006:242) who describes the syllable as “the smallest unit of speech. Every utterance must contain at least one syllable”. He (ibid.) further states that speech is composed of segments such as vowels or consonants and these segments are considered to be aspects of the syllable. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

The Analects of Confucius
The analecTs of confucius An Online Teaching Translation 2015 (Version 2.21) R. Eno © 2003, 2012, 2015 Robert Eno This online translation is made freely available for use in not for profit educational settings and for personal use. For other purposes, apart from fair use, copyright is not waived. Open access to this translation is provided, without charge, at http://hdl.handle.net/2022/23420 Also available as open access translations of the Four Books Mencius: An Online Teaching Translation http://hdl.handle.net/2022/23421 Mencius: Translation, Notes, and Commentary http://hdl.handle.net/2022/23423 The Great Learning and The Doctrine of the Mean: An Online Teaching Translation http://hdl.handle.net/2022/23422 The Great Learning and The Doctrine of the Mean: Translation, Notes, and Commentary http://hdl.handle.net/2022/23424 CONTENTS INTRODUCTION i MAPS x BOOK I 1 BOOK II 5 BOOK III 9 BOOK IV 14 BOOK V 18 BOOK VI 24 BOOK VII 30 BOOK VIII 36 BOOK IX 40 BOOK X 46 BOOK XI 52 BOOK XII 59 BOOK XIII 66 BOOK XIV 73 BOOK XV 82 BOOK XVI 89 BOOK XVII 94 BOOK XVIII 100 BOOK XIX 104 BOOK XX 109 Appendix 1: Major Disciples 112 Appendix 2: Glossary 116 Appendix 3: Analysis of Book VIII 122 Appendix 4: Manuscript Evidence 131 About the title page The title page illustration reproduces a leaf from a medieval hand copy of the Analects, dated 890 CE, recovered from an archaeological dig at Dunhuang, in the Western desert regions of China. The manuscript has been determined to be a school boy’s hand copy, complete with errors, and it reproduces not only the text (which appears in large characters), but also an early commentary (small, double-column characters). -

English Vowels Basic Vowel Description Tense And
Main vowel symbols of GA and WCE Front Central Back* Height [i] ‘beat’ [u] ‘boot’ higher high English vowels [I] ‘bit’ [U] ‘book’ lower high [e] ‘bait’ [o] ‘boat’ higher mid [E] ‘bet’ [´] ‘sofa’ [ç] ‘ bought, GA’ lower mid Narrow transcription [! ] ‘but’ [Å] ‘Bob, bought WCE’ higher low [Q] ‘bat’ [A] ‘Bob, GA’ lower low •Back vowels except [A] are rounded; the rest are unrounded • [Å] is described as lower low in your text and IPA. I’ll take either. It is ROUNDED • [e] and [o] are the first part (nucleus) of the diphthongs [ej] and [ow] 1 3 Basic vowel description Tense and Lax • The basic descriptors for vowels are HAR • English phonology traditionally makes the – Height distinction between tense and lax vowels – Advancement – This is not phonetically well-defined as a single – Rounding characteristic • It is useful to subdivide each height class into a – You just need to learn which vowels are classed as tense and lax ‘higher’ and ‘lower’ subdivision – You should learn all the heights in the next chart • This distinction based mainly on phonotactics – Phonotactics is the description of which sounds can occur together in a legal word or syllable of a language 2 4 Duration patterns tense and lax Occurrence of TENSE Vs vowels • Vowels called ‘tense’ occur freely at the ends of • Tense vowels are longer than lax vowels of the one syllable words same general height class i, ej, u, ow, Å ( A and ç in GA) /i/ longer than /I/ /u/ longer than /U/ • Also tense : aj, aw, çj /ej/ longer than /E/ • Examples : • The tense back vowels /ow/ and /Å/ (both /A/ and – ‘bee’, ‘bay’, ‘too’, ‘tow’ , ‘law’ ( ‘spa’ and ‘law’ in GA) /ç/ in GA) are longer than the lax central /! / • An exception to the ‘lax vowels shorter than tense’ is /Q/ – It is often as long as any other vowel 5 7 Length of tense v. -
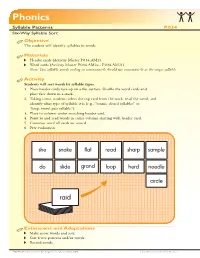
Six-Way Syllable Sort Objective the Student Will Identify Syllables in Words
Phonics Syllable Patterns P.034 Six-Way Syllable Sort Objective The student will identify syllables in words. Materials Header cards (Activity Master P.034.AM1) Word cards (Activity Master P.034.AM2a - P.034.AM2f) Note: Two syllable words ending in consonant-le should use consonant-le as the target syllable. Activity Students will sort words by syllable types. 1. Place header cards face up on a flat surface. Shuffle the word cards and place face down in a stack. 2. Taking turns, students select the top card from the stack, read the word, and identify what type of syllable it is (e.g., “tennis, closed syllables” or “loop, vowel pair syllable”). 3. Place in column under matching header card. 4. Point to and read words in entire column starting with header card. 5. Continue until all cards are sorted. 6. Peer evaluation Extensions and Adaptations Make more words and sort. Sort fewer patterns and/or words. Record words. 2006 The Florida Center for Reading Research (Revised July, 2007) 2-3 Student Center Activities: Phonics Phonics P.034.AM1 Six-Way Syllable Sort flat she closed syllables open syllables snake sharp vowel-consonant-e syllables r-controlled syllables read sample vowel pair syllables consonant-le syllables header cards 2-3 Student Center Activities: Phonics 2006 The Florida Center for Reading Research (Revised July, 2007) Phonics Six-Way Syllable Sort P.034.AM2a witness bobbin grand suffix tennis camp panic happen closed syllable word cards 2006 The Florida Center for Reading Research (Revised July, 2007) 2-3 Student Center Activities: -

49 Stress-Timed Vs. Syllable- Timed Languages
TBC_049.qxd 7/13/10 19:21 Page 1 49 Stress-timed vs. Syllable- timed Languages Marina Nespor Mohinish Shukla Jacques Mehler 1Introduction Rhythm characterizes most natural phenomena: heartbeats have a rhythmic organization, and so do the waves of the sea, the alternation of day and night, and bird songs. Language is yet another natural phenomenon that is charac- terized by rhythm. What is rhythm? Is it possible to give a general enough definition of rhythm to include all the phenomena we just mentioned? The origin of the word rhythm is the Greek word osh[óp, derived from the verb oeí, which means ‘to flow’. We could say that rhythm determines the flow of different phenomena. Plato (The Laws, book II: 93) gave a very general – and in our opinion the most beautiful – definition of rhythm: “rhythm is order in movement.” In order to under- stand how rhythm is instantiated in different natural phenomena, including language, it is necessary to discover the elements responsible for it in each single case. Thus the question we address is: which elements establish order in linguistic rhythm, i.e. in the flow of speech? 2The rhythmic hierarchy: Rhythm as alternation Rhythm is hierarchical in nature in language, as it is in music. According to the metrical grid theory, i.e. the representation of linguistic rhythm within Generative Grammar (cf., amongst others, Liberman & Prince 1977; Prince 1983; Nespor & Vogel 1989; chapter 43: representations of word stress), the element that “establishes order” in the flow of speech is stress: universally, stressed and unstressed positions alternate at different levels of the hierarchy (see chapter 40: stress: phonotactic and phonetic evidence). -

A Phonetic Study of Length and Duration in Kyrgyz Vowels
Swarthmore College Works Linguistics Faculty Works Linguistics 2019 A Phonetic Study Of Length And Duration In Kyrgyz Vowels Nathaniel Ziv Stern , '20 Jonathan North Washington Swarthmore College, [email protected] Follow this and additional works at: https://works.swarthmore.edu/fac-linguistics Part of the Linguistics Commons Let us know how access to these works benefits ouy Recommended Citation Nathaniel Ziv Stern , '20 and Jonathan North Washington. (2019). "A Phonetic Study Of Length And Duration In Kyrgyz Vowels". Proceedings Of The Workshop On Turkic And Languages In Contact With Turkic. Volume 4, 119-131. DOI: 10.3765/ptu.v4i1.4577 https://works.swarthmore.edu/fac-linguistics/256 This work is licensed under a Creative Commons Attribution 4.0 License. This work is brought to you for free by Swarthmore College Libraries' Works. It has been accepted for inclusion in Linguistics Faculty Works by an authorized administrator of Works. For more information, please contact [email protected]. 2019. Proceedings of the Workshop on Turkic and Languages in Contact with Turkic 4. 119–131. https://doi.org/10.3765/ptu.v4i1.4577 A phonetic study of length and duration in Kyrgyz vowels Nathaniel Ziv Stern & Jonathan North Washington∗ Abstract. This paper examines the phonetic correlates of the (phonological) vowel length contrast in Kyrgyz to address a range of questions about the nature of this contrast, and also explores factors that affect (phonetic) duration in short vowels. Measurement and analysis of the vowels confirms that there is indeed a significant duration distinction be- tween the Kyrgyz vowel categories referred to as short and long vowels. -

Teach Vowel Team Syllable Type- There Are Six Types of Syllables: 1
Vowel Team Syllables Information In this intervention group, the following skills are taught: Teach Vowel Team Syllable Type- There are six types of syllables: 1. A closed syllable ends in a consonant. The vowel has a short vowel sound, as in the word bat. 2. A vowel-consonant-e syllable is typically found at the end of a word. The final e is silent and makes the next vowel before it long, as in the word name. 3. An open syllable ends in a vowel. The vowel has a long vowel sound, as in the first syllable of apron. 4. An r-controlled syllable contains a vowel followed by the letter r. The r controls the vowel and changes the way it is pronounced, as in the word car. 5. A vowel team syllable has two vowels next to each other that together say a new sound, as in the word south. 6. A consonant +l-e syllable is found in words like handle, puzzle, and middle. Read Words With ai,ay- fail, aim, de/tail, con/tain, re/frain, day, tray, dis/play, pay/ment, hay/stack Spelling Patterns for Long a (a, ai, ay, a-e, eigh, ea)- eight, save, a/pron, hay, neigh/bor, sub/way, train, pro/claim, re/frig/er/ate, ba/gel, great, break/ing Read Words With ee,ey- they, grey, en/trée, fi/an/cée Spelling Patterns for Long e (e, ee, ea, ie, y, ey, e-e)- ba/by, key, me, be, feed, creek, thief, pier, re/lief, bee/tle, bun/ny, cra/zy, mon/ey, Pete, bum/ble/bee Read Words With oa,oe,ue- Oa and oe say the long o sound as in boat, and toe. -

Tao Yuanming's Perspectives on Life As Reflected in His Poems on History
Journal of chinese humanities 6 (2020) 235–258 brill.com/joch Tao Yuanming’s Perspectives on Life as Reflected in His Poems on History Zhang Yue 張月 Associate Professor of Department of Chinese Language and Literature, University of Macau, Taipa, Macau, China [email protected] Abstract Studies on Tao Yuanming have often focused on his personality, reclusive life, and pas- toral poetry. However, Tao’s extant oeuvre includes a large number of poems on history. This article aims to complement current scholarship by exploring his viewpoints on life through a close reading of his poems on history. His poems on history are a key to Tao’s perspectives with regard to the factors that decide a successful political career, the best way to cope with difficulties and frustrations, and the situations in which literati should withdraw from public life. Examining his positions reveals the connec- tions between these different aspects. These poems express Tao’s perspectives on life, as informed by his historical predecessors and philosophical beliefs, and as developed through his own life experience and efforts at poetic composition. Keywords Tao Yuanming – poems on history – perspectives on life Tao Yuanming 陶淵明 [ca. 365–427], a native of Xunyang 潯陽 (contem- porary Jiujiang 九江, Jiangxi), is one of the best-known and most-studied Chinese poets from before the Tang [618–907]. His extant corpus, comprising 125 poems and 12 prose works, is one of the few complete collections to survive from early medieval China, largely thanks to Xiao Tong 蕭統 [501–531], a prince of the Liang dynasty [502–557], who collected Tao’s works, wrote a preface, and © ZHANG YUE, 2021 | doi:10.1163/23521341-12340102 This is an open access article distributed under the terms of the CC BY 4.0Downloaded license. -

An Introduction to the Phonological Basis of Chinese Characters in Modern Mandarin
An Introduction to the Phonological Basis of Chinese Characters in Modern Mandarin by Stephen M. Kraemer American English Institute University of Oregon [email protected] 现代汉字语音简介 雷思遠 American English Institute University of Oregon [email protected] © Copyright 2009 Stephen M. Kraemer Phonetic Compound (形声字xingshengzi) • A “signific” part, which indicates meaning • plus • A “phonetic” part which indicates sound • 妈 [ma1] = 女 (female) + 马 [ma3] The Mandarin Syllable • A syllable in Modern Standard Mandarin • Consists of: • An initial • A final • A tone The Final • The final can also be broken down into a medial (vowel), a nucleus (vowel) and an ending (vowel or consonant) • Final = (M)N(E) Mandarin Consonants Source: Labial Labio- Dental Alveolar Alveo- Palatal Velar Kratochvil dental palatal (1968:25) stop p, p’ t, t’ k, k’ nasal m n (ŋ) fricative f s ʂ, ʐ(r) ɕ x lateral l affricate ts, ts’ tʂ, tʂ’ tɕ, tɕ’ Mandarin Vowels i ʅ i y(ü) u e ə ɤ o ɛ a ɑ Source: Cheng(1973:12) Background Literature • Xu Shen–說 文 解 字Shuo Wen Jie Zi (2nd cent. A.D.) • Soothill-1911 • Karlgren-1916, 1923a, 1923b, 1926, 1940, 1949, 1958 • Wieger-1927/1965 • Astor-1970 • Zhou Youguang-周有光 1978,1980, 2003 • Kraemer-1980, 1991a, 1991b • DeFrancis-1984 • Alber-1986, 1989 周有光 Zhou Youguang (1980) 汉字声旁读音便查 Hanzi shengpang duyin biancha ( A handy look up for the pronunciation of phonetics in Chinese characters) • Zhou analyzes characters in the Xin Hua Zidian (1971) based on Phonetic elements and sets up three categories of phonetic compound characters based on the similarity of the phonetic compound to the pronunciation of the phonetic itself. -

(Mandarin), Phonology Of
1 Chinese (Mandarin), Phonology of (For Encyclopedia of Language and Linguistics, 2nd edition, Elsevier Publishing House) San Duanmu, University of Michigan, MI USA February 2005 Chinese is the first language of over 1,000 million speakers. There are several dialect families of Chinese (each in turn consisting of many dialects), which are often mutually unintelligible. However, there are systematic correspondences among the dialects and it is easy for speakers of one dialect to pick up another dialect rather quickly. The largest dialect family is the Northern family (also called the Mandarin family), which consists of over 70% of all Chinese speakers. Standard Chinese (also called Mandarin Chinese) is a member of the Northern family; it is based on the pronunciation of the Beijing dialect. There are, therefore, two meanings of Mandarin Chinese, one referring to the Northern dialect family and one referring to the standard dialect. To avoid the ambiguity, I shall use Standard Chinese (SC) for the latter meaning. SC is spoken by most of those whose first tongue is another dialect. In principle, over 1,000 million people speak SC, but in fact less than 1% of them do so without some accent. This is because even Beijing natives do not all speak SC. SC has five vowels, shown in Table 1 in IPA symbols (Chao 1968, Cheng 1973, Lin 1989, Duanmu 2002). [y] is a front rounded vowel. When the high vowels occur before another vowel, they behave as glides [j, , w]. [i] and [u] can also follow a non-high vowel to form a diphthong. The mid vowel can change frontness and rounding depending on the environment. -

A Corpus-Based Study of N1-N2 Words in Archaic Chinese
A Corpus-Based Study of N1-N2 Words in Archaic Chinese By Jane Chanell 17970091 Supervisor: Associate Professor Robert Mailhammer Western Sydney University School of Humanities and Communication Arts June 2019 A thesis submitted in partial fulfilments of the requirements for the degree of Master of Research Acknowledgements I would like to express my sincere gratitude to my supervisor Associate Professor Robert Mailhammer, for his whole-hearted support of my Master’s study and research, for his patience, immense knowledge, invaluable assistance and for providing valuable guidance along every step of the way. Without his unwavering support and constant encouragement, I would never have been able to complete this thesis. I would also like to thank Dr Chong Han for being kind enough to provide details of the Chinese online corpus used for this linguistic research. A special thank you to Weicong Li, for providing all the essential technical support for working with the online corpus. I am very grateful to Dr Geoff Hyde for his invaluable advice on my writing. STATEMENT OF AUTHENTICATION The work presented in this thesis is, to the best of my knowledge and belief, original except as acknowledged in the text. I hereby declare that I have not submitted this material, either in full or in part, for a degree at this or any other institution. …………J…an…e…C…h…an…e…ll …………….. (Name) ………………………………………….. (Signature) ……………2…0…/0…6/…20…1…9………………. (Date) ii Table of Contents Acknowledgements .............................................................................................................................i