Data Based Predictive Models for Odor Perception Rinu Chacko, Deepak Jain*, Manasi Patwardhan, Abhishek Puri, Shirish Karande & Beena Rai
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Medical Review Officer Manual
Department of Health and Human Services Substance Abuse and Mental Health Services Administration Center for Substance Abuse Prevention Medical Review Officer Manual for Federal Agency Workplace Drug Testing Programs EFFECTIVE OCTOBER 1, 2010 Note: This manual applies to Federal agency drug testing programs that come under Executive Order 12564 dated September 15, 1986, section 503 of Public Law 100-71, 5 U.S.C. section 7301 note dated July 11, 1987, and the Department of Health and Human Services Mandatory Guidelines for Federal Workplace Drug Testing Programs (73 FR 71858) dated November 25, 2008 (effective October 1, 2010). This manual does not apply to specimens submitted for testing under U.S. Department of Transportation (DOT) Procedures for Transportation Workplace Drug and Alcohol Testing Programs (49 CFR Part 40). The current version of this manual and other information including MRO Case Studies are available on the Drug Testing page under Medical Review Officer (MRO) Resources on the SAMHSA website: http://www.workplace.samhsa.gov Previous Versions of this Manual are Obsolete 3 Table of Contents Chapter 1. The Medical Review Officer (MRO)........................................................................... 6 Chapter 2. The Federal Drug Testing Custody and Control Form ................................................ 7 Chapter 3. Urine Drug Testing ...................................................................................................... 9 A. Federal Workplace Drug Testing Overview.................................................................. -

Color, Taste, and Odor: What You Should Know
Color, Taste, and Odor: What you should know From time to time the MassDEP receives consumer questions or complaints regarding the look, taste or the odor of drinking water. Listed below are common problems with drinking water and their most common causes. Please note that a particular problem in your drinking water may be the result of a cause not listed here; the only way to confirm a cause is to have a certified lab analyze the water and discuss the results with drinking water professional. If you receive water from a public drinking water system it is important to contact the Public Water Supply (PWS) before having a laboratory analyze the water. Information on private water testing is available. Filtering or treating the water may remedy persistent problems; however MassDEP does not recommend filtering or treating your water supply if your water is supplied by a MassDEP- approved PWS. MassDEP also does not regulate or recommend specific treatment systems for private home use. If you decide to use a filtration or treatment device in your home, the Department strongly encourages you to contact National Sanitation Foundation (NSF) for a list of approved devices. If you purchase a treatment device for private home use MassDEP also strongly recommends that it is maintained and provide active maintenance according to the manufacturer's instructions. Failure to maintain the equipment properly may make treatment ineffective and/or may create the potential for contamination. Common problems with drinking water are grouped into three categories: Color problems Taste / odor problems Particles in water If the problem with your water is not described here, if you are on a public water system please contact the public water department in your city or town or the MassDEP Drinking Water Program at your nearest regional MassDEP office. -
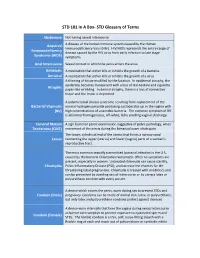
STD Glossary of Terms
STD 101 In A Box- STD Glossary of Terms Abstinence Not having sexual intercourse Acquired A disease of the human immune system caused by the Human Immunodeficiency Virus (HIV). HIV/AIDS represents the entire range of Immunodeficiency disease caused by the HIV virus from early infection to late stage Syndrome (AIDS) symptoms. Anal Intercourse Sexual contact in which the penis enters the anus. Antibiotic A medication that either kills or inhibits the growth of a bacteria. Antiviral A medication that either kills or inhibits the growth of a virus. A thinning of tissue modified by the location. In epidermal atrophy, the epidermis becomes transparent with a loss of skin texture and cigarette Atrophic paper-like wrinkling. In dermal atrophy, there is a loss of connective tissue and the lesion is depressed. A polymicrobial clinical syndrome resulting from replacement of the Bacterial Vaginosis normal hydrogen peroxide producing Lactobacillus sp. in the vagina with (BV) high concentrations of anaerobic bacteria. The common symptom of BV is abnormal homogeneous, off-white, fishy smelling vaginal discharge. Cervical Motion A sign found on pelvic examination suggestive of pelvic pathology; when Tenderness (CMT) movement of the cervix during the bimanual exam elicits pain. The lower, cylindrical end of the uterus that forms a narrow canal Cervix connecting the upper (uterus) and lower (vagina) parts of a woman's reproductive tract. The most common sexually transmitted bacterial infection in the U.S., caused by the bacteria Chlamydia trachomatis. Often no symptoms are present, especially in women. Untreated chlamydia can cause sterility, Chlamydia Pelvic Inflammatory Disease (PID), and increase the chances for life- threatening tubal pregnancies. -

A Pheromone Antagonist Liberates Female Sea Lamprey from a Sensory Trap to Enable Reliable Communication
A pheromone antagonist liberates female sea lamprey from a sensory trap to enable reliable communication Tyler J. Buchingera,1, Anne M. Scotta,1, Skye D. Fissettea, Cory O. Branta,2, Mar Huertasa,3,KeLia,4, Nicholas S. Johnsonb, and Weiming Lia,5 aDepartment of Fisheries and Wildlife, Michigan State University, East Lansing, MI 48824; and bHammond Bay Biological Station, US Geological Survey, Millersburg, MI 49759 Edited by John G. Hildebrand, University of Arizona, Tucson, AZ, and approved February 21, 2020 (received for review December 12, 2019) The evolution of male signals and female preferences remains a subsequent preference evolution precludes a full understanding central question in the study of animal communication. The sensory of how receiver biases shape communication. trap model suggests males evolve signals that mimic cues used Sea lamprey (Petromyzon marinus) are a useful model to track in nonsexual contexts and thus manipulate female behavior to the evolutionary trajectory of communication that originated via generate mating opportunities. Much evidence supports the sen- a sensory trap. Chemical cues and pheromones guide sea lam- sory trap model, but how females glean reliable information from prey behavior throughout their complex life history, especially both mimetic signals and their model cues remains unknown. We during the terminal reproductive phase (21). After parasitizing discovered a mechanism whereby a manipulative male signal guides fish in lakes or the Atlantic Ocean, prespawning sea lamprey reliable communication in sea lamprey (Petromyzon marinus). Mi- migrate into streams following chemical cues released by larvae gratory sea lamprey follow a larval cue into spawning streams; once residing in nursery habitats near spawning grounds. -

Taste and Odor Control, but Use As a Control Chemical Must Be Evaluated Carefully Due to the Formation of Thms and Chlorophenol When Organics Are Present
Taste and Odor Most customers judge the quality of drinking water by taste and odor. If the customer is satisfied with these qualities, it is assumed the water is safe to drink. Many harmful contaminants in water cannot be detected due to taste or smell and many of the contaminants found in drinking water that have a detectable taste or odor are not harmful. Sources of taste and odor problems can be found in surface water and groundwater. Source water protection involves the prevention of contaminants from entering the source. Surface water or groundwater may become contaminated by pollutants such as gasoline, industrial solvents or a wide variety of volatile organics. The removal of contaminants from surface water or groundwater is costly and may involve the use of aeration, powdered activated carbon, or both. If taste and odor must be controlled at the treatment plant, oxidation, aeration and adsorption can be effective in reducing taste and odor, and improved coagulation filtration. ODOR MEASUREMENTS One of the most common methods for measuring odor in water is the threshold odor test. It involves a series of flasks presented to an observer, who is told that some of the samples contain odors and that the series is arranged in order of increasing concentrations. The observer is also given a known odor-free blank for reference during the test. The observer compares the flasks in ascending order with the blank and then notes whether an odor is detected in any sample flask. Individuals vary in their reactions to certain types of odors. An odor stimulus that is agreeable to one may be disagreeable to another. -

Cracking the Odor Code: Molecular and Cellular Deconstruction of the Olfactory Circuit of Drosophila Larvae Kenta Asahina
Rockefeller University Digital Commons @ RU Student Theses and Dissertations 2008 Cracking the Odor Code: Molecular and Cellular Deconstruction of the Olfactory Circuit of Drosophila Larvae Kenta Asahina Follow this and additional works at: http://digitalcommons.rockefeller.edu/ student_theses_and_dissertations Part of the Life Sciences Commons Recommended Citation Asahina, Kenta, "Cracking the Odor Code: Molecular and Cellular Deconstruction of the Olfactory Circuit of Drosophila Larvae" (2008). Student Theses and Dissertations. Paper 196. This Thesis is brought to you for free and open access by Digital Commons @ RU. It has been accepted for inclusion in Student Theses and Dissertations by an authorized administrator of Digital Commons @ RU. For more information, please contact [email protected]. Cracking the Odor Code: Molecular and Cellular Deconstruction of the Olfactory Circuit of Drosophila Larvae A Thesis Presented to the Faculty of The Rockefeller University in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy By Kenta Asahina June 2008 © Copyright by Kenta Asahina 2008 CRACKING THE ODOR CODE: MOLECULAR AND CELLULAR DECONSTRUCTION OF THE OLFACTORY CIRCUIT OF DROSOPHILA LARVAE Kenta Asahina, Ph.D. The Rockefeller University 2008 The Drosophila larva offers a powerful model system to investigate the general principles by which the olfactory system processes behaviorally relevant sensory stimuli. The numerically reduced larval olfactory system relieves the formidable molecular and cellular complexity found in other organisms. This thesis presents a study in four parts that investigates molecular and neuronal mechanisms of larval odor coding. First, the larval odorant receptor (OR) repertoire was characterized. ORs define the olfactory receptive range of an animal. -

Distinct Signaling of Drosophila Chemoreceptors in Olfactory
Distinct signaling of Drosophila chemoreceptors in PNAS PLUS olfactory sensory neurons Li-Hui Caoa,b,c,d, Bi-Yang Jinga,b,c,d,1, Dong Yange,1, Xiankun Zengf,1, Ying Shene, Yuhai Tug, and Dong-Gen Luoa,b,c,d,2 aState Key Laboratory of Membrane Biology, College of Life Sciences, Peking University, Beijing 100871, China; bCenter for Quantitative Biology, Peking University, Beijing 100871, China; cMcGovern Institute for Brain Research, Peking University, Beijing 100871, China; dPeking–Tsinghua Center for Life Sciences, Academy for Advanced Interdisciplinary Studies, Peking University, Beijing 100871, China; eDepartment of Neurobiology, Zhejiang University School of Medicine, Hangzhou 310058, China; fJanelia Research Campus, Howard Hughes Medical Institute, Ashburn, VA 20147; and gIBM T. J. Watson Research Center, Yorktown Heights, NY 10598 Edited by Richard W. Aldrich, The University of Texas at Austin, Austin, TX, and approved December 24, 2015 (received for review September 15, 2015) In Drosophila, olfactory sensory neurons (OSNs) rely primarily on recordings of single OSNs could ideally overcome this issue while two types of chemoreceptors, odorant receptors (Ors) and iono- facilitating the experimental manipulations of a cell’s membrane tropic receptors (Irs), to convert odor stimuli into neural activity. potential; however, this standard method has unfortunately not The cellular signaling of these receptors in their native OSNs re- yet been routinely applied to Drosophila OSNs. mains unclear because of the difficulty of obtaining intracellular Here, we developed a Drosophila antennal preparation and Drosophila recordings from OSNs. Here, we developed an antennal succeeded in performing patch-clamp recordings of single iden- preparation that enabled the first recordings (to our knowledge) tified OSNs. -

Scent of a Woman—Or Man: Odors Influence Person Knowledge
brain sciences Article Scent of a Woman—Or Man: Odors Influence Person Knowledge Nicole L. Hovis 1,2, Paul R. Sheehe 3 and Theresa L. White 1,3,* 1 Department of Psychology, Le Moyne College, Syracuse, NY 13214, USA; [email protected] 2 Human Services Department, Capella University, Minneapolis, MN 55402, USA 3 Neuroscience and Physiology, SUNY Upstate Medical University, Syracuse, NY 13210, USA * Correspondence: [email protected] Abstract: First impressions of social traits are regularly, rapidly, and readily determined from limited information about another individual. Relatively little is known about the way that olfactory information, particularly from scents that are not body odors, alters a first impression. Can the attributes of an odorant be conferred onto a person associated with that scent? To explore this, 101 participants were asked to form an impression of a hypothetical person based on the following stimuli: A gender-neutral silhouette, a list of six personal characteristics, and one of five odorants. Participants then rated the likelihood that the hypothetical person possessed each of 51 personality traits that were determined a priori as falling into six attribute categories. Participants also directly rated all odorants for the six categories and intensity. A T-test showed that ratings of the hypothetical person were less disparate from the odor that was presented during impression formation than from other odors. ANOVA revealed that the effects were heterogeneous, with odorants varying in their effectiveness in associating the hypothetical person with categories. The present data suggest that a hypothetical person can be imbued with the specific attributes of an odor and that some odors are better at contributing to impressions than others. -

Lecture 14 --Olfaction.Pdf
14 Olfaction ClickChapter to edit 14 MasterOlfaction title style • Olfactory Physiology • Neurophysiology of Olfaction • From Chemicals to Smells • Olfactory Psychophysics, Identification, and Adaptation • Olfactory Hedonics • Associative Learning and Emotion: Neuroanatomical and Evolutionary Considerations ClickIntroduction to edit Master title style Olfaction: The sense of smell Gustation: The sense of taste ClickOlfactory to edit Physiology Master title style Odor: The translation of a chemical stimulus into a smell sensation. Odorant: A molecule that is defined by its physiochemical characteristics, which are capable of being translated by the nervous system into the perception of smell. To be smelled, odorants must be: • Volatile (able to float through the air) • Small • Hydrophobic (repellent to water) Figure 14.1 Odorants ClickOlfactory to edit Physiology Master title style The human olfactory apparatus • Unlike other senses, smell is tacked onto an organ with another purpose— the nose. Primary purpose—to filter, warm, and humidify air we breathe . Nose contains small ridges, olfactory cleft, and olfactory epithelium ClickOlfactory to edit Physiology Master title style The human olfactory apparatus (continued) • Olfactory cleft: A narrow space at the back of the nose into which air flows, where the main olfactory epithelium is located. • Olfactory epithelium: A secretory mucous membrane in the human nose whose primary function is to detect odorants in inhaled air. Figure 14.2 The nose ClickOlfactory to edit Physiology Master title style Olfactory epithelium: The “retina” of the nose • Three types of cells . Supporting cells: Provide metabolic and physical support for the olfactory sensory neurons. Basal cells: Precursor cells to olfactory sensory neurons. Olfactory sensory neurons (OSNs): The main cell type in the olfactory epithelium. -

RKA Odor Investigation Report
Odor Investigation Results Graphic Packaging International, LLC’s Recycled Paperboard Mill in Kalamazoo, MI November , 2020 Prepared for: Graphic Packaging International, LLC Prepared by: RK & ASSOCIATES, INC 2 South 631 Route 59 Suite B Warrenville, Illinois 60555 Phone: 630-393-9000 Fax: 630-393-9111 Odor Investigation Results Graphic Packaging Int’l – Kalamazoo 1. INTRODUCTION RK & Associates, Inc. (RKA) is retained to investigate and to evaluate potential odor impact in the nearby community of the Graphic Packaging International, LLC (GPI) recycled paperboard mill facility, located at 1500 North Pitcher Street in Kalamazoo, Michigan. An Odor Investigation Plan for determining this potential odor impact was submitted to, and subsequently approved by, the Michigan Department of Environment, Great Lakes and Energy (EGLE) on June 4, 2020 prior to initiating field investigation activities. Appendix A provides this approved Odor Investigation Plan. The odor investigations included odor monitoring at 24 GPI property perimeter and nearby community locations (as approved by EGLE) which were conducted three times per week for a period of 60 days. These odor monitoring events included characterizing odors, measuring odor thresholds and taking hydrogen sulfide (H2S) concentration measurements. In addition, RKA selected nine locations on site at the GPI facility to measure H2S concentrations and collect air samples to be evaluated by an RKA odor panel and analyzed by RKA with an Olfactometer for odor threshold. RKA also reviewed meteorological data for evaluation of potential odor impact in the nearby community. In the balance of this document, details of the investigation are presented including the procedures used, data results, and our findings. -

Taste and Odor-Causing Compounds in Drinking Water Fact Sheet
FACTSHEET TASTE AND ODOR Environmental Contaminant Treatment Taste and Odor -Causing Compounds in Drinking Water The primary sources of taste and odor problems common name “blue-green algae” has remained. Man-Made Chemicals in drinking water are algae and bacteria. However, Cyanobacteria are photosynthetic bacteria. In Man-made chemicals are another source of other anthropogenic sources such as wastewater addition to the blue-green color of many inferred taste and odor-causing chemicals in drinking discharges and chemical spills also act as sources by the name, other species can be red, brown, or water. For example, methyl tertiary butyl ether of chemicals that cause off tastes and odors. yellow. Cyanobacteria are most commonly found (MTBE), a gasoline additive persistent in Such chemicals can affect both groundwater and in eutrophic waters (waters with high levels of groundwater and recreational surface waters, surface water. nutrients) and shallow reservoirs, and can occur has an odor threshold as low as 5 parts per as surface scum, benthic (bottom) mats, and on billion. Dissolved in water, it smells oily and like TYPES OF TASTE AND aquatic weeds (Hoehn, 2002). In the 1960’s turpentine. Industrial phenols can create odor and 1970’s, it was discovered that cyanobacteria problems. Hydrocarbons and volatile organic ODOR PROBLEMS produce geosmin and MIB as intracellular by- compounds such as fuels and solvents produce products. As a bloom progresses, bacteria die, oily, paint-like, and medicinal odors. There are four basic taste types: sour, sweet, salty releasing these odorous chemicals into the water. and bitter. There are also a variety of odor types including earthy, musty, chemical, and chlorinous. -

Sense of Smell Unit
SENSE OF SMELL Some materials can be detected with your nose while they are below a life- threatening threshold; others cannot be detected until a life-threatening threshold has been exceeded. Detecting chemicals with your nose is the least desirable method of recognition and should be avoided, but it can also be the first warning that something is wrong. Enabling Objectives: When you have completed this module, you will be able to Recognize the basic anatomy of the nose and how it works, Recognize the meaning of olfactory fatigue and its effect, Identify the concept of odor threshold and how it works, and Recognize the difference between odor threshold and permissible exposure limit (PEL) and threshold limit value (TLV). Glossary: Glomerulus: (See explanation under The Olfactory System) Mitral Cells: (See explanation under The Olfactory System) New Jersey Right to Know Hazardous Substance Fact Sheet: There are more than 1,600 fact sheets that have been completed and more than 800 have been translated into Spanish. The fact sheets are prepared on pure substances and contain information on health hazards, exposure limits, personal protective equipment, proper handling, first aid, and emergency procedures for fires and spills. Odorant: A substance capable of eliciting an olfactory response: An odor is the sensation resulting from stimulation of the olfactory organs. Odors play an important part in our everyday life. Odor Detection Threshold: The lowest concentration of a certain odor compound that is perceivable by the human sense of smell. The thresholds of a chemical compound are determined in part by its shape, polarity, partial changes, and molecular mass.