ESBM: an Entity Summarization Benchmark
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
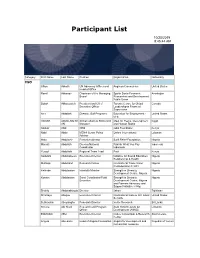
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

<5Regfe~G of ~Raflefon,E
t~t <5regfe~g of ~raflefon,e An Account of the Family, and Notes of its connexions by Marriage and Descent from the Norman Conquest to the Present Day With Appendixes, Pedigrees and lllustratz"ons COMPILED BY FALCONER MADAN, M.A. FELLOW OF BRASENOSE COLLEGE, OXFORD PRINTED FOR SUBSCRIBERS ~1forb HORACE HART, PRINTER TO THE UNIVERSITY THE GRESLEYS OF DRAKELOWE DERBYSHIRE. aF SIR R0BEiltT GRESLEY. BT. THE DRAKELOWE ESTATE. 1 MILE BURTON-OK-":RE~T. 10 MILES DERBY, 22 :,.nLEil NOTTINGHA:'.l. 30 MILES LEICESTEiR. 33 MILES BIRML'\GHAM. DRAKELOWE SOLD BY SIR ROBERT GRESLEY OWNERSHIP SINCE THE CONQUEST ENDED FROM OUR CORRESPONDENT BURTON-ON-TRENT, DEC. 19 Drakelowe Hall. an Elizabethan man sion with a park and estate of 760 acres, near Burton-on-Trent, was bought to-day by Marshall Brothers, timber merchants, of Lenton, Nottingham, and Sir Alb_ert. Ball a Nottingham landowner, actmg jointly. The price was £12,5,00. Thus ended the Gresley family ,; ownership of . Drakelowe, which had lasted for 28 generations, 1 since the Norman Conquesl. i Mr. E. Marshall, senior, a partner In the_ firm, I said that it was strictly a business deal without sentiment. The vendor was Sir Robert Gresley. ' Gres/eys rif Drake/owe Plate I SIR PETER DE GRESLEY d. about A.D. r3ro (From Brit. Mus. MS. Harl. 4205, fol. n2, of the IJth cent.: seep. 43) £1l@dfore jffl:ie quam jfortuna GRESLEY MOTTO, More Faz'thful than Fortunate. IN what old story far away, In what great action is enshrined, The sad sweet motto which to-day Around the Gresleys' name is twined? Was it for country or for crown They played a grand tho' tragic part? Or did they lay their fortune down To strive to win one careless heart? vVe cannot tell: but this we know, That they who chose in that dim past Those noble words,-come weal come woe Stood by. -
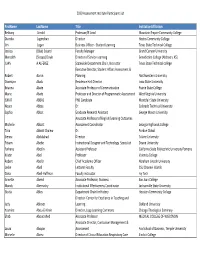
2020 Assessment Institute Participant List Firstname Lastname Title
2020 Assessment Institute Participant List FirstName LastName Title InstitutionAffiliation Bethany Arnold Professor/IE Lead Mountain Empire Community College Diandra Jugmohan Director Hostos Community College Jim Logan Business Officer ‐ Student Learning Texas State Technical College Jessica (Blair) Soland Faculty Manager Grand Canyon University Meredith (Stoops) Doyle Director of Service‐Learning Benedictine College (Atchison, KS) JUAN A ALFEREZ Statewide Department Chair, Instructor Texas State Technical college Executive Director, Student Affairs Assessment & Robert Aaron Planning Northwestern University Osomiyor Abalu Residence Hall Director Iowa State University Brianna Abate Associate Professor of Communication Prairie State College Marie Abate Professor and Director of Programmatic Assessment West Virginia University ISMAT ABBAS PhD Candidate Montclair State University Noura Abbas Dr. Colorado Technical University Sophia Abbot Graduate Research Assistant George Mason University Associate Professor of English/Learning Outcomes Michelle Abbott Assessment Coordinator Georgia Highlands College Talia Abbott Chalew Dr. Purdue Global Sienna Abdulahad Director Tulane University Fitsum Abebe Instructional Designer and Technology Specialist Doane University Farhana Abedin Assistant Professor California State Polytechnic University Pomona Kristin Abel Professor Valencia College Robert Abel Jr Chief Academic Officer Abraham Lincoln University Leslie Abell Lecturer Faculty CSU Channel Islands Dana Abell‐Huffman Faculty instructor Ivy Tech Annette -

Federal School Code List, 2004-2005. INSTITUTION Office of Federal Student Aid (ED), Washington, DC
DOCUMENT RESUME TITLE Federal School Code List, 2004-2005. INSTITUTION Office of Federal Student Aid (ED), Washington, DC. PUB DATE 2003-00-00 NOTE 162p.; The Federal School Code List is published annually. It includes schools that are participating at the.time of printing. For the 2003-2004 Code list, see ED 470 328. AVAILABLE FROM Office of Federal Student Aid, U.S. Department of Education; 830 First Street, NE, Washington, DC 20202. Tel: 800-433-3243 (Toll Free); Web site: http://www.studentaid.ed.gov. PUB TYPE Reference Materials - Directories/Catalogs (132) EDRS PRICE EDRS Price MFOl/PCO7 Plus Postage. DESCRIPTORS *Coding; *College Applicants; *Colleges; Higher Education; *Student Financial Aid IDENTIFIERS *Higher Education Act Title IV This list contains the unique codes assigned by the U.S. Department of Education to all postsecondary schools participating in Title IV student aid programs. The list is organized by state and alphabetically by school within each state. Students use these codes to apply for financial aid on Free Application for Federal Student Aid (EAFSA) forms or on the Web, entering the name of the school and its Federal Code for schools that should receive their information. The list includes schools in the United States and selected foreign schools. (SLD) I Reproductions supplied by EDRS are the best that can be made from the original document. FSA FEDERAL STUDENT AID SlJh4MARY: The Federal School Code List of Participating Schools for the 2004-2005 Award Year. Dear Partner, We are pleased to provide the 2004-2005 Federal School Code List. This list contains the unique codes assigned by the Department of Education to schools participating in the Title N student aid programs. -

2019-2020 Academic Catalog 4
ACADEMIC CATALOG 2019-2020 400 The Fenway Boston, Massachusetts 02115 www.emmanuel.edu Arts and Sciences Office of Admissions 617-735-9715 617-735-9801 (fax) [email protected] Graduate and Professional Programs 617-735-9700 617-507-0434 (fax) [email protected] The information contained in this catalog is accurate as of September 2019. Emmanuel College reserves the right, however, to make changes at its discretion affecting poli cies, fees, curricula or other matters announced in this catalog. It is the policy of Emmanuel College not to discriminate on the basis of race, color, religion, national origin, gender, sexual orientation or the presence of any disability in the recruitment and employment of faculty and staff and the operation of any of its programs and activities, as specified by federal laws and regulations. Emmanuel College is accredited by the New England Commission of Higher Education (NECHE). Inquiries regarding the accreditation status by the NECHE should be directed to the administrative staff of the institution. Individuals may also contact: New England Commission of Higher Education 3 Burlington Woods Drive, Suite 100 Burlington, MA 01803-4514 781-425-7785 2 Table of Contents Table of Contents About Emmanuel College................................5 Economics......................................................77 Economic Policy.............................78 Finance.................................78 General Information for Education........................................................79 Arts and Sciences Elementary -

English Heritage Properties 1600-1830 and Slavery Connections
English Heritage Properties 1600-1830 and Slavery Connections A Report Undertaken to Mark the Bicentenary of the Abolition of the British Atlantic Slave Trade Volume One: Report and Appendix 1 Miranda Kaufmann 2007 Report prepared by: Miranda Kaufmann Christ Church Oxford 2007 Commissioned by: Dr Susie West English Heritage Documented in registry file 200199/21 We are grateful for the advice and encouragement of Madge Dresser, University of West of England, and Jim Walvin, University of York Nick Draper generously made his parliamentary compensation database available 2 Contents List of properties and their codes Properties with no discovered links to the slave trade 1 Introduction 2 Property Family Histories 3 Family History Bibliography 4 Tables showing Property links to slavery 5 Links to Slavery Bibliography Appendices 1 List of persons mentioned in Family Histories with entries in the Oxford Dictionary of National Biography. 2 NRA Listings (separate volume) 3 Photocopies and printouts of relevant material (separate volume) 3 List of properties and their codes Appuldurcombe House, Isle of Wight [APD] Apsley House, London [APS] Audley End House and Gardens [AE] Battle Abbey House [BA] Bayham Old Abbey House, Kent [BOA] Belsay Hall, Castle and Gardens [BH] Bessie Surtees House, Newcastle [BSH] Bolsover Castle, Derbyshire [BC] Brodsworth Hall and Gardens [BRD] Burton Agnes Manor House [BAMH] Chiswick House, London [CH] De Grey Mausoleum, Flitton, Bedfordshire [DGM] Derwentcote Steel Furnace [DSF] Great Yarmouth Row Houses [GYRH] Hardwick -
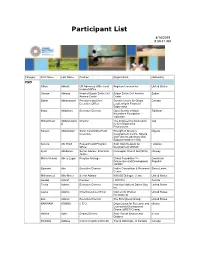
Participant List
Participant List 4/14/2019 8:59:41 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Osman Abbass Head of Sudan Sickle Cell Sudan Sickle Cell Anemia Sudan Anemia Center Center Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Ilhom Abdulloev Executive Director Open Society Institute Tajikistan Assistance Foundation - Tajikistan Mohammed Abdulmawjoo Director The Engineering Association Iraq d for Development & Environment Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Serena Abi Khalil Research and Program Arab NGO Network for Lebanon Officer Development (ANND) Kjetil Abildsnes Senior Adviser, Economic Norwegian Church Aid (NCA) Norway Justice Maria Victoria Abreu Lugar Program Manager Global Foundation for Dominican Democracy and Development Republic (GFDD) Edmond Abu Executive Director Native Consortium & Research Sierra Leone Center Mohammed Abu-Nimer Senior Advisor KAICIID Dialogue Centre United States Aouadi Achraf Founder I WATCH Tunisia Terica Adams Executive Director Hamilton National Dance Day United States Inc. Laurel Adams Chief Executive Officer Women for Women United States International Zoë Adams Executive Director The Strongheart Group United States BAKINAM ADAMU C E O Organization for Research and Ghana Community Development Ghana -

REGISTER of STUDENT SPONSORS Date: 26-April-2021
REGISTER OF STUDENT SPONSORS Date: 26-April-2021 Register of Licensed Sponsors This is a list of institutions licensed to sponsor migrants under the Student route of the points-based system. It shows the sponsor's name, their primary location, their sponsor type, the location of any additional centres being operated (including centres which have been recognised by the Home Office as being embedded colleges), the rating of their licence against each route (Student and/or Child Student) they are licensed for, and whether the sponsor is subject to an action plan to help ensure immigration compliance. Legacy sponsors cannot sponsor any new students. For further information about the Student route of the points-based system, please refer to the guidance for sponsors in the Student route on the GOV.UK website. No. of Sponsors Licensed under the Student route: 1,118 Sponsor Name Town/City Sponsor Type Additional Status Route Immigration Locations Compliance Abberley Hall Worcester Independent school Student Sponsor Child Student Abbey College Cambridge Cambridge Independent school Student Sponsor Child Student Student Sponsor Student Abbey College Manchester Manchester Independent school Student Sponsor Child Student Student Sponsor Student Abbotsholme School UTTOXETER Independent school Student Sponsor Child Student Student Sponsor Student Abercorn School London Independent school Student Sponsor Child Student Student Sponsor Student Aberdour School Educational Trust Tadworth Independent school Student Sponsor Child Student Abertay University -

Issue 1 – 2015
Old Emanuels Merchandise CONTENTS Introduction from the Headmaster ....1 Letter from the Editor .................2 Then & Now ..........................3 Welcome to The Rose & Portcullis FEATURE - Michel Roux . 4 Dear OE, The Memorial Bridge .................6 Welcome to the first printed version of the “Rose and Portcullis”, the School’s Alumni magazine. My thanks go to Emily Symmons, our Development Manager, for putting The Clapham Rail Disaster 1988 .......8 together this wonderful new production. FEATURE - Ben Wilkins . 10 I hope that you have also been enjoying the digital online version of this magazine, Emanuel School at War which Emily has now produced five times. But we also want to send you a “hard copy” School & Department News ..........12 Price: £30 (+ £15 UK postage) edition once a year to place on your shelves. Digital newsletters will come and go, but we want to leave something tangible behind for posterity. After all, there are printed Archive Matters......................14 An Illustrated History of Emanuel School copies of the Old Emanuel Newsletter going back many years (I have lots of back copies Price £5 (+ £5 UK postage) in my office) and there are printed copies of the Portcullis, in the School Library, going FEATURE – Ursula Antwi-Boasiako . 16 back to 1893. So we don’t want to say goodbye to the printed magazine just yet, at The History of Emanuel School Boat Club least for one edition per year. Girls at Emanuel .....................18 Price £15 (+ £5 UK postage) In this issue you can read about an interview with Michel Roux Jnr, who has been a The Holmes Interview ...............19 Please see the website for order forms great supporter of his old school and has been back to talk to the students not too long ago. -

PRESIDENT's REPORT ISSUE Dk-.-Pmwmij-~7~
-I RON~P-.;. BULLETIN, MASSACHUSETTS INSTITUTE OF TECHNOLOGY PRESIDENT'S REPORT ISSUE dk-.-PMWMij-~7~ Published by the Massachusetts Institute of Technology, Cambridge Station, Boston, Massachusetts, in October, November, February and June. Entered July 13, 1933, at the Post Office, Boston, Massachusetts, as second-class matter, under Act of Congress of August 24, 1912. .... .... VOLUME 70 NUMBER 1 VOLUME 70 NUMBER 1 MASSACHUSETTS INSTITUTE OF TECHNOLOGY President's Report Issue 1933-1934 Covering period from meeting of Corporation October, 1933 to meeting of Corporation October, 1934 • . .*.* ....... .... :: -.. .... .:..:. .. .-: :- -. .. .- THE TECHNOLOGY PRESS CAMBRIDGE, MASSACHUSETTS 1934 __ 6IAiR ULikiY Of AIA8A11ETIS JUL 28 19t37 ~I~~ -~~~· .. · -- .-. .- ..··1 - ' -. ... .~"· ··~ ·~ :'+ · ·• t· ":*:. i -:'! . ..*. .. ' .. .::. .: : . ., :~~~ee·2,:" ~~• ,:.. ··- ." ' . ~·······l······ ···.•-..w F··· · .e ron •L • _______ Is- TABLE OF CONTENTS THE CORPORATION PAGE Members of the Corporation ..... 5 Committees of the Corporation . 6 REPORT OF THE PRESIDENT Personnel .. ......... 10 Finances . 12 Students . 13 Facilities .......... 15 Educational Program 17 Research . ... 18 Industrial Co6peration and Public Service ..... 22 Alumni Association ........ 24 A Look Ahead .. ........ 25 REPORTS OF OTHER ADMINISTRATIVE OFFICERS Dean of Students .. Dean of the Graduate School Registrar . Chairman of Committee on Summer Session . Librarian .. Medical Director . Director of the Division of Industrial Co6peration Secretary of Society of Arts -

When Scotland Was Jewish
IIl a ll II' WHEN SCOTLAND WAS JEWISH DNA Evidence Archeology , , Analysis of Migrationsy and Public and Family Records Show Twelfth Century Semitic Roots Luzabeth Caldwell Hirschman and Donald N. Yates When Scotland Was Jewish DNA Evidence, Archeology, Analysis of Migrations, and Public and Family Records Show Twelfth Century Semitic Roots Elizabeth Caldwell Hirschman and Donald N. Yates McFarland & Company, Inc., Publishers Jefferson, North Carolina, and London Library of Congress Cataloguing-in-Publication Data Hirschman, Elizabeth Caldwell, 1949- When Scotland was Jewish : DNA evidence, archeology, analysis of migrations, and public and family records show twelfth century Semitic roots / Elizabeth Caldwell Hirschman and Donald N. Yates, p. cm. Includes bibliographical references and index. ISBN-13: 978-0-7864-2800-7 illustrated case binding : 50# alkaline paper (S) Jews— Scotland — History. 2. Jews— Scotland — Genealogy. 3. Scotland — History. 4. Scots— History. 5. Scots— Genealogy. I. Title. DS135.E5H57 2007 941.1'004924-dc22 2007006397 British Library cataloguing data are available ©2007 Elizabeth Caldwell Hirschman and Donald N. Yates. All rights reserved No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying or recording, or by any information storage and retrieval system, without permission in writing from the publisher. On the cover: Scotland Highlands ©2006 Photodisc; Thistle graphic by Mark Durr Manufactured in the United States of America McFarland & Company, Inc., Publishers Box 611, Jefferson, North Carolina 28640 www. mcfarlandpub. com 1. 2. Contents 3. 4. Preface 1 . 5. 6. The Origins of Scotland 3 7. DNA and Population Studies: “But Why Do 8. -

Board of Trustees of the City University of New York Committee on Faculty, Staff and Administration
Board of Trustees of The City University of New York Committee on Faculty, Staff and Administration June 8, 2020 I. ACTION ITEMS A. Approval of the Minutes of the April 27, 2020 Meeting B. POLICY CALENDAR 1. Committee Report 2. Amendment to The City University of New York Optional Retirement Program and Tax Deferred Annuity Plan 3. Amendment of the Stella and Charles Guttman Community College Governance Plan 4. Amendment of the John Jay College of Criminal Justice Governance Plan 5. Appointment of Corey Robin as Distinguished Professor at Brooklyn College 6. Appointment of Peter Tolias with Immediate Tenure at Brooklyn College 7. Appointment of Victoria Frye with Early Tenure at The CUNY School of Medicine 8. Appointment of Jose Sanchez with Early Tenure at Queens College 9. Appointment of Jamie Longazel with Early Tenure at John Jay College of Criminal Justice 10. Appointment of Joshua Mason with Early Tenure at John Jay College of Criminal Justice 11. Appointment of Liza Steele with Early Tenure at John Jay College of Criminal Justice 12. Appointment of Yuliya Zabyelina with Early Tenure at John Jay College of Criminal Justice 13. Appointment of Charles Pryor as Vice President of Student Engagement at Stella and Charles Guttman Community College 14. Appointment of Beth Douglas as Executive Legal Counsel and Labor Designee at Kingsborough Community College 15. Appointment of Sandy Curko as Executive Legal Counsel and Labor Designee at Queens College BOARD OF TRUSTEES THE CITY UNIVERSITY OF NEW YORK COMMITTEE ON MINUTES OF THE MEETING FACULTY, STAFF AND ADMINISTRATION APRIL 27, 2020 The meeting was called to order by Secretary of the Board Gayle M.