Copy Number Variations and Cancer Adam Shlien*† and David Malkin*†‡
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Analysis of Retinopathy in Type 1 Diabetes
Genetic Analysis of Retinopathy in Type 1 Diabetes by Sayed Mohsen Hosseini A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Institute of Medical Science University of Toronto © Copyright by S. Mohsen Hosseini 2014 Genetic Analysis of Retinopathy in Type 1 Diabetes Sayed Mohsen Hosseini Doctor of Philosophy Institute of Medical Science University of Toronto 2014 Abstract Diabetic retinopathy (DR) is a leading cause of blindness worldwide. Several lines of evidence suggest a genetic contribution to the risk of DR; however, no genetic variant has shown convincing association with DR in genome-wide association studies (GWAS). To identify common polymorphisms associated with DR, meta-GWAS were performed in three type 1 diabetes cohorts of White subjects: Diabetes Complications and Control Trial (DCCT, n=1304), Wisconsin Epidemiologic Study of Diabetic Retinopathy (WESDR, n=603) and Renin-Angiotensin System Study (RASS, n=239). Severe (SDR) and mild (MDR) retinopathy outcomes were defined based on repeated fundus photographs in each study graded for retinopathy severity on the Early Treatment Diabetic Retinopathy Study (ETDRS) scale. Multivariable models accounted for glycemia (measured by A1C), diabetes duration and other relevant covariates in the association analyses of additive genotypes with SDR and MDR. Fixed-effects meta- analysis was used to combine the results of GWAS performed separately in WESDR, ii RASS and subgroups of DCCT, defined by cohort and treatment group. Top association signals were prioritized for replication, based on previous supporting knowledge from the literature, followed by replication in three independent white T1D studies: Genesis-GeneDiab (n=502), Steno (n=936) and FinnDiane (n=2194). -

PARSANA-DISSERTATION-2020.Pdf
DECIPHERING TRANSCRIPTIONAL PATTERNS OF GENE REGULATION: A COMPUTATIONAL APPROACH by Princy Parsana A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland July, 2020 © 2020 Princy Parsana All rights reserved Abstract With rapid advancements in sequencing technology, we now have the ability to sequence the entire human genome, and to quantify expression of tens of thousands of genes from hundreds of individuals. This provides an extraordinary opportunity to learn phenotype relevant genomic patterns that can improve our understanding of molecular and cellular processes underlying a trait. The high dimensional nature of genomic data presents a range of computational and statistical challenges. This dissertation presents a compilation of projects that were driven by the motivation to efficiently capture gene regulatory patterns in the human transcriptome, while addressing statistical and computational challenges that accompany this data. We attempt to address two major difficulties in this domain: a) artifacts and noise in transcriptomic data, andb) limited statistical power. First, we present our work on investigating the effect of artifactual variation in gene expression data and its impact on trans-eQTL discovery. Here we performed an in-depth analysis of diverse pre-recorded covariates and latent confounders to understand their contribution to heterogeneity in gene expression measurements. Next, we discovered 673 trans-eQTLs across 16 human tissues using v6 data from the Genotype Tissue Expression (GTEx) project. Finally, we characterized two trait-associated trans-eQTLs; one in Skeletal Muscle and another in Thyroid. Second, we present a principal component based residualization method to correct gene expression measurements prior to reconstruction of co-expression networks. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Mouse Mtus1 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Mtus1 Knockout Project (CRISPR/Cas9) Objective: To create a Mtus1 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Mtus1 gene (NCBI Reference Sequence: NM_001005863 ; Ensembl: ENSMUSG00000045636 ) is located on Mouse chromosome 8. 14 exons are identified, with the ATG start codon in exon 2 and the TGA stop codon in exon 14 (Transcript: ENSMUST00000059115). Exon 2~3 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Mice homozygous for a gene trap allele exhibit spontaneous heart hypertrophy and SLE-like lymphoproliferative disease. Exon 2 starts from the coding region. Exon 2~3 covers 62.26% of the coding region. The size of effective KO region: ~8609 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 14 Legends Exon of mouse Mtus1 Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. No significant tandem repeat is found in the dot plot matrix. So this region is suitable for PCR screening or sequencing analysis. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of Exon 3 is aligned with itself to determine if there are tandem repeats. -

Duke University Dissertation Template
Gene-Environment Interactions in Cardiovascular Disease by Cavin Keith Ward-Caviness Graduate Program in Computational Biology and Bioinformatics Duke University Date:_______________________ Approved: ___________________________ Elizabeth R. Hauser, Supervisor ___________________________ William E. Kraus ___________________________ Sayan Mukherjee ___________________________ H. Frederik Nijhout Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate Program in Computational Biology and Bioinformatics in the Graduate School of Duke University 2014 i v ABSTRACT Gene-Environment Interactions in Cardiovascular Disease by Cavin Keith Ward-Caviness Graduate Program in Computational Biology and Bioinformatics Duke University Date:_______________________ Approved: ___________________________ Elizabeth R. Hauser, Supervisor ___________________________ William E. Kraus ___________________________ Sayan Mukherjee ___________________________ H. Frederik Nijhout An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate Program in Computational Biology and Bioinformatics in the Graduate School of Duke University 2014 Copyright by Cavin Keith Ward-Caviness 2014 Abstract In this manuscript I seek to demonstrate the importance of gene-environment interactions in cardiovascular disease. This manuscript contains five studies each of which contributes to our understanding of the joint impact of genetic variation -

Egfr Activates a Taz-Driven Oncogenic Program in Glioblastoma
EGFR ACTIVATES A TAZ-DRIVEN ONCOGENIC PROGRAM IN GLIOBLASTOMA by Minling Gao A thesis submitted to Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland March 2020 ©2020 Minling Gao All rights reserved Abstract Hyperactivated EGFR signaling is associated with about 45% of Glioblastoma (GBM), the most aggressive and lethal primary brain tumor in humans. However, the oncogenic transcriptional events driven by EGFR are still incompletely understood. We studied the role of the transcription factor TAZ to better understand master transcriptional regulators in mediating the EGFR signaling pathway in GBM. The transcriptional coactivator with PDZ- binding motif (TAZ) and its paralog gene, the Yes-associated protein (YAP) are two transcriptional co-activators that play important roles in multiple cancer types and are regulated in a context-dependent manner by various upstream signaling pathways, e.g. the Hippo, WNT and GPCR signaling. In GBM cells, TAZ functions as an oncogene that drives mesenchymal transition and radioresistance. This thesis intends to broaden our understanding of EGFR signaling and TAZ regulation in GBM. In patient-derived GBM cell models, EGF induced TAZ and its known gene targets through EGFR and downstream tyrosine kinases (ERK1/2 and STAT3). In GBM cells with EGFRvIII, an EGF-independent and constitutively active mutation, TAZ showed EGF- independent hyperactivation when compared to EGFRvIII-negative cells. These results revealed a novel EGFR-TAZ signaling axis in GBM cells. The second contribution of this thesis is that we performed next-generation sequencing to establish the first genome-wide map of EGF-induced TAZ target genes. -

Identification of Significant Genes with Poor Prognosis in Ovarian Cancer Via Bioinformatical Analysis
Feng et al. Journal of Ovarian Research (2019) 12:35 https://doi.org/10.1186/s13048-019-0508-2 RESEARCH Open Access Identification of significant genes with poor prognosis in ovarian cancer via bioinformatical analysis Hao Feng1†, Zhong-Yi Gu2†, Qin Li2, Qiong-Hua Liu3, Xiao-Yu Yang4* and Jun-Jie Zhang2* Abstract Ovarian cancer (OC) is the highest frequent malignant gynecologic tumor with very complicated pathogenesis. The purpose of the present academic work was to identify significant genes with poor outcome and their underlying mechanisms. Gene expression profiles of GSE36668, GSE14407 and GSE18520 were available from GEO database. There are 69 OC tissues and 26 normal tissues in the three profile datasets. Differentially expressed genes (DEGs) between OC tissues and normal ovarian (OV) tissues were picked out by GEO2R tool and Venn diagram software. Next, we made use of the Database for Annotation, Visualization and Integrated Discovery (DAVID) to analyze Kyoto Encyclopedia of Gene and Genome (KEGG) pathway and gene ontology (GO). Then protein-protein interaction (PPI) of these DEGs was visualized by Cytoscape with Search Tool for the Retrieval of Interacting Genes (STRING). There were total of 216 consistently expressed genes in the three datasets, including 110 up-regulated genes enriched in cell division, sister chromatid cohesion, mitotic nuclear division, regulation of cell cycle, protein localization to kinetochore, cell proliferation and Cell cycle, progesterone-mediated oocyte maturation and p53 signaling pathway, while 106 down-regulated genes enriched in palate development, blood coagulation, positive regulation of transcription from RNA polymerase II promoter, axonogenesis, receptor internalization, negative regulation of transcription from RNA polymerase II promoter and no significant signaling pathways. -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

Variation in Copy Number of MTUS1 Gene Among Healthy Individuals and Cancer Patients from Gujarat
www.ijpsonline.com Variation in Copy Number of MTUS1 Gene among Healthy Individuals and Cancer Patients from Gujarat SUHANI H. ALMAL AND H. PADH* Department of Cell and Molecular Biology, B. V. Patel Pharmaceutical Education and Research Development (PERD) Centre, Thaltej-380 054, India Almal and Padh: MTUS1 Gene Copy Number and Risk to Cancer in Indians Genome variations in the form of single nucleotide polymorphism, INDELs (insertions or deletions), March-April 2017 Indian Journal of Pharmaceutical Sciences 311 www.ijpsonline.com duplications, inversions and copy number variations are more widely prevalent than initially predicted. Mitochondrial tumor suppressor gene maps on chromosome 8p, in which exon 4-specific deletion is associated with susceptibility towards breast and various other forms of cancer. In this study, 41 head and neck cancer, 15 breast cancer patients and 280 healthy control individuals were analysed for mitochondrial tumor suppressor gene copy number variation. The frequencies of wt/wt (homozygous wild-type), wt/Del (heterozygous variant) and Del/Del (homozygous deletion variant) mitochondrial tumor suppressor gene genotypes were found to be 73.3, 26.7 and 0% in breast cancer patients, 41.5, 58.5 and 0% in head and neck cancer patients and 43, 57 and 0% in healthy individuals, respectively. A significant association of the deletion variant with breast cancer (odds ratio=0.27, 95% confidence interval=0.08–0.87, P=0.0207) was found in our population. In addition, the allele and genotype frequency varied significantly (P<0.0001) among Indian and German populations, reflecting ethnic diversity. This pilot case-control study highlighted the indicative role of mitochondrial tumor suppressor gene deletion in protection from breast cancer in Indian population. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -
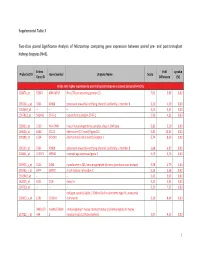
Supplemental Table 3 Two-Class Paired Significance Analysis of Microarrays Comparing Gene Expression Between Paired
Supplemental Table 3 Two‐class paired Significance Analysis of Microarrays comparing gene expression between paired pre‐ and post‐transplant kidneys biopsies (N=8). Entrez Fold q‐value Probe Set ID Gene Symbol Unigene Name Score Gene ID Difference (%) Probe sets higher expressed in post‐transplant biopsies in paired analysis (N=1871) 218870_at 55843 ARHGAP15 Rho GTPase activating protein 15 7,01 3,99 0,00 205304_s_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 6,30 4,50 0,00 1563649_at ‐‐ ‐‐ ‐‐ 6,24 3,51 0,00 1567913_at 541466 CT45‐1 cancer/testis antigen CT45‐1 5,90 4,21 0,00 203932_at 3109 HLA‐DMB major histocompatibility complex, class II, DM beta 5,83 3,20 0,00 204606_at 6366 CCL21 chemokine (C‐C motif) ligand 21 5,82 10,42 0,00 205898_at 1524 CX3CR1 chemokine (C‐X3‐C motif) receptor 1 5,74 8,50 0,00 205303_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 5,68 6,87 0,00 226841_at 219972 MPEG1 macrophage expressed gene 1 5,59 3,76 0,00 203923_s_at 1536 CYBB cytochrome b‐245, beta polypeptide (chronic granulomatous disease) 5,58 4,70 0,00 210135_s_at 6474 SHOX2 short stature homeobox 2 5,53 5,58 0,00 1562642_at ‐‐ ‐‐ ‐‐ 5,42 5,03 0,00 242605_at 1634 DCN decorin 5,23 3,92 0,00 228750_at ‐‐ ‐‐ ‐‐ 5,21 7,22 0,00 collagen, type III, alpha 1 (Ehlers‐Danlos syndrome type IV, autosomal 201852_x_at 1281 COL3A1 dominant) 5,10 8,46 0,00 3493///3 IGHA1///IGHA immunoglobulin heavy constant alpha 1///immunoglobulin heavy 217022_s_at 494 2 constant alpha 2 (A2m marker) 5,07 9,53 0,00 1 202311_s_at -

DLC1 Is a Chromosome 8P Tumor Suppressor Whose Loss Promotes Hepatocellular Carcinoma
Downloaded from genesdev.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press RESEARCH COMMUNICATION therapeutic potential (Downward 2003). Similarly, DLC1 is a chromosome 8p PTEN inhibits the PI3–kinase pathway, and inhibitors of tumor suppressor whose loss PI3K pathway components such as PI3K, AKT, and mTORs have entered clinic trials (Luo et al. 2003). promotes hepatocellular Recurrent chromosomal deletions found in sporadic carcinoma cancers often contain tumor suppressor genes. For ex- ample, PTEN loss on chromosome 10q23 frequently oc- Wen Xue,1 Alexander Krasnitz,1 Robert Lucito,1 curs in various cancers and promotes tumorigenesis by Raffaella Sordella,1 Linda VanAelst,1 deregulating the PI3 kinase pathway (Maser et al. 2007). 2 3 Similarly, heterozygous deletions on chromosome 8p22 Carlos Cordon-Cardo, Stephan Singer, in many hepatocellular carcinomas (HCC) (Jou et al. 4 1 1 Florian Kuehnel, Michael Wigler, Scott Powers, 2004) and other cancer types, including carcinomas of Lars Zender,1,6 and Scott W. Lowe,1,5,7 the breast, prostate, colon, and lung (Matsuyama et al. 1 2001; Durkin et al. 2007). Several genes, including Cold Spring Harbor Laboratory, Cold Spring Harbor, DLC1, MTUS1, FGL1 and TUSC3, have been identified New York 11724, USA; 2Columbia University Medical 3 as candidate tumor suppressors in this region (Yan et al. Center, New York 10032, USA; Institute of Pathology, 2004). Deleted in Liver Cancer 1 (DLC1) is a particularly University Hospital, Heidelberg 69120, Germany; 4 attractive candidate owing to its genomic deletion, pro- Department of Gastroenterology, Hepatology and moter methylation, and underexpressed mRNA in can- Endocrinology, Hannover Medical School, 5 cer (Yuan et al.