The Regional Dimension a Bayesian Network Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

12. FORMULATION of the URBAN TRANSPORT MASTER PLAN Development of the RSTP Urban Transportation Master Plan (1) Methodology
The Project on The Revision and Updating of the Strategic Transport Plan for Dhaka (RSTP) Final Report 12. FORMULATION OF THE URBAN TRANSPORT MASTER PLAN Development of the RSTP Urban Transportation Master Plan (1) Methodology The development of the RSTP Urban Transportation Master Plan adopted the following methodology (see Figure 12.1): (i) Elaborate the master plan network through a screen line analysis by comparing the network capacity and future demand. (ii) Identify necessary projects to meet future demand at the same time avoiding excessive capacity. (iii) Conducts economic evaluation of each project to give priority on projects with higher economic return. (iv) Conduct preliminary environmental assessment of every project and consider countermeasures against environmental problems, if any. (v) Make a final prioritization of all physical projects by examining their respective characteristics from different perspectives. (vi) Classify the projects into three categories, namely short-, medium- and long-term projects, by considering the financial constraints. (vii) Prepare an action plan for short-term projects together with “soft” measures. Mid-term Project Source: RSTP Study Team Figure 12.1 Development Procedure for the Master Plan 12-1 The Project on The Revision and Updating of the Strategic Transport Plan for Dhaka (RSTP) Final Report (2) Output of the Transportation Network Plan The RSTP urban transportation network plan was developed based on a review and a modification of the STP network plan. The main points of the modification or adoption of the STP network master plan are as follows: i. Harmonization with future urban structure, land-use plan and development of network plan. -

Effect of Nitrogen and Boron on the Yield of Wheat Cv. Kanchan
J. Bangladesh Agril. Univ. 3(2): 215-220, 2005 ISSN 1810-3030 Effect of nitrogen and boron on the yield of wheat cv. Kanchan M.M. Khan', A.K. Hasan2, M.H. Rashid2, and F. Ahrned3 Palli Karma Sahayak Foundation (PKSF), Sher-e-Banglanagar, Dhaka, 2Department of Agronomy and 3 Department of Agroforestry, Bangladesh Agricultural University, Mymensingh Abstract An experiment was carried out at the Agronomy Field Laboratory, Bangladesh Agricultural University, Mymensingh during the period from January to April 2004 to study the effect of different levels of nitrogen and boron on the yield of wheat cv. Kanchan. The treatments included four levels of nitrogen VIZ., 45, 60, 85 and 110 kg N ha-1 and four levels of boron viz., 0, 1, 2 and 3 kg B ha-1. The experiment was laid out in a Randomized Complete Block Design with three replications. The results revealed that Yield and yield contributing characters were influenced significantly by both levels of nitrogen and boron. Among the levels of nitrogen, 110 kg N ha-1 produced the highest grain (5.54 t ha-1)and straw (8.21 t ha-1 ) yields. The lowest grain (3.23 t ha-1) and straw (5.52 t ha-1) yields were observed with the application of 45 kg N ha-1. The highest grain (4.95 t ha-1)and straw (7.38 t ha 1) yields were produced With 3 kg B ha-1. The minimum grain (3.59 t ha-1)and straw (6.14 t ha-1)yields were found in the control treatment. -

Heritage Report-Paul Roux
Phase 1 Heritage Impact Assessment for proposed new 1.5 km-long underground sewerage pipeline in Paul Roux, Thabo Mofutsanyane District Municipality, Free State Province. Report prepared by Paleo Field Services PO Box 38806, Langenhovenpark 9330 16 / 02 / 2020 Summary A heritage impact assessment was carried for a proposed new 1.5 km-long underground sewerage pipeline in Paul Roux in the Thabo Mofutsanyane District Municipality, Free State Province. The study area is situated on the farm Farm Mary Ann 712, next to the N5 national road covering a section of the Sand River floodplain which is located on the eastern outskirts of Paul Roux . The proposed footprint is underlain by well-developed alluvial and geologically recent overbank sediments of the Sand River. Investigation of exposed alluvial cuttings next to the bridge crossing shows little evidence of intact Quaternary fossil remains. Potentially fossil-bearing Tarkastad Subgroup and younger Molteno Formation strata are exposed to the southwest of the study area. These outcrops will not be impacted by the proposed development. There are no major palaeontological grounds to suspend the proposed development. The study area consists for the most part of open grassland currently used for cattle grazing. The foot survey revealed little evidence of in situ Stone Age archaeological material, capped or distributed as surface scatters on the landscape. There are also no indications of rock art, prehistoric structures or other historical structures or buildings older than 60 years within the vicinity of the study area. A large cemetery is located directly west of the proposed footprint. The modern bridge construction at the Sand River crossing is not considered to be of historical significance. -

Connecting Bangladesh: Economic Corridor Network
Connecting Bangladesh: Economic Corridor Network Economic corridors are anchored on transport corridors, and international experience suggests that the higher the level of connectivity within and across countries, the higher the level of economic growth. In this paper, a new set of corridors is being proposed for Bangladesh—a nine-corridor comprehensive integrated multimodal economic corridor network resembling the London Tube map. This paper presents the initial results of the research undertaken as an early step of that development effort. It recommends an integrated approach to developing economic corridors in Bangladesh that would provide a strong economic foundation for the construction of world-class infrastructure that, in turn, could support the growth of local enterprises and attract foreign investment. About the Asian Development Bank COnnecTING BANGLADESH: ADB’s vision is an Asia and Pacific region free of poverty. Its mission is to help its developing member countries reduce poverty and improve the quality of life of their people. Despite the region’s many successes, it remains home to a large share of the world’s poor. ADB is committed to reducing poverty through inclusive economic growth, environmentally sustainable growth, and regional integration. ECONOMIC CORRIDOR Based in Manila, ADB is owned by 67 members, including 48 from the region. Its main instruments for helping its developing member countries are policy dialogue, loans, equity investments, guarantees, grants, NETWORK and technical assistance. Mohuiddin Alamgir -

July 2016 Volume 3 No 3
6 VOLUME 3 NO 3 JULY 2016 DHAKA CENTRAL INTERNATIONAL MEDICAL COLLEGE JOURNAL (APPROVED BY BMDC) July 2016, Vol. 3 No. 3 Contents From the Desk of Editor-in-Chief 3 Instructions for Authors 4 Editorial Novel Treatment of Diabetic Nephropathy 12 Original Articles Incidence of Malignancy in Thyroid Nodule 14 Abedin SAMA, Alam MM, Islam MS, Fakir MAY Dyslipidemia and Atherogenic Index among the 21 Young Female Doctors ofBangladesh. Khanduker S, Hoque MM, Khanduker N, Chowdhury MAA, Nazneen M A Study on Stroke in Young Patients due to Cardiac 26 Disease in a Tertiary Care Hospital in Dhaka City Mukta M, Mohammad QD, Mir AS Variation of Transverse Diameter ofDry Ossified 33 Human Atlas Vertebra of Male and Female Rahman S, Ara S, Sayeed S, Rashid S, Ferdous Z, Kashem K Study on Health Effects of Teenage Pregnancies among the Patients 36 Attending Antenatal Care Centre of Chittagong Medical College Hospital Tarafdar MA, Begum N, Das SR, Begum S, Sultana A, Rahman R, Begum R Identification ofDifferent Clinical Features and Complications of 41 Type 2 Diabetes Mellitus in Bengaladeshi Males Begum F, Shamim KM, Akter S, Hossain S, Nazma N, Afrin M, Moureen A Review Articles Female Genital Tuberculosis- A Review Article 46 Shaheed S, Mamun SMAA, Khanom M Case Reports Round Worm induced Acute Appendicitis- an Incidental 51 Finding during Colonoscopy Masum QAA, Islam MN 1 Dhaka Central International Medical College Journal Vol.13 No. 3July 2016 An Official Organ of Dhaka Central International Medical College CHIEF PATRON ADVISORS The Dhaka Central International Prof. Md. Anwarul Islam Md. -

The South African Qualifications Authority
THE SOUTH AFRICAN QUALIFICATIONS AUTHORITY Articulation Between Technical and Vocational Education and Training (TVET) Colleges and Higher Education Institutions (HEIs): National Articulation Baseline Study Report October 2017 ARTICULATION BETWEEN TECHNICAL AND VOCATIONAL EDUCATION AND TRAINING (TVET) COLLEGES AND HIGHER EDUCATION INSTITUTIONS (HEIs) NATIONAL ARTICULATION BASELINE STUDY REPORT October 2017 DISCLAIMER The views expressed in this report are not necessarily those of the South African Qualifications Authority (SAQA) and only those parts of the text clearly flagged as decisions or summaries of decisions taken by the Authority should be seen as reflecting SAQA policy and/or views. COPYRIGHT All rights are reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the South African Qualifications Authority (SAQA). ACKNOWLEDGEMENTS The National Articulation Baseline Study reported here forms part of SAQA’s long-term partnership research with the Durban University of Technology (DUT) “Developing an understanding of the enablers of student transitioning between Technical and Vocation Education and Training (TVET) Colleges and HEIs and beyond”. Data were gathered, and initial analyses done, for the National Articulation Baseline Study, by Dr Heidi Bolton, Dr Eva Sujee, Ms Renay Pillay, and Ms Tshidi Leso (all of SAQA). The in-depth analyses were conducted by -
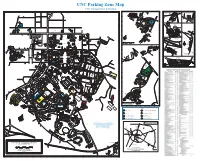
UNC Parking Zone Map UNC Transportation & Parking
UNC Parking Zone Map UNC Transportation & Parking Q R S T U V W X Y Z A B C D E F G H I J K L M N O P 26 **UNC LEASES SPACE CAROLINA . ROAD IN THESE BUILDINGS 21 21 MT HOMESTEAD NORTH LAND MGMT. PINEY OPERATIONS CTR. VD. (NC OFFICE HORACE WILLIAMS AIRPORT VD., HILL , JR. BL “RR” 41 1 1 Resident 41 CommuterRR Lot R12 UNC VD AND CHAPEL (XEROX) TE 40 MLK BL A PRINTING RIVE EXTENSION MLK BL ESTES D SERVICES TIN LUTHER KING TERST PLANT N O I AHEC T EHS HOMESTEAD ROAD MAR HANGER VD. 86) O I-40 STORAGE T R11 TH (SEE OTHER MAPS) 22 22 O 720, 725, & 730 MLK, JR. BL R1 T PHYSICAL NOR NORTH STREET ENVRNMEN HL .3 MILES TO TH. & SAFETY ESTES DRIVE 42 COMMUTER LOT T. 42 ER NC86 ELECTRICAL DISTRICENTBUTION OPERATIONS SURPLUS WA REHOUSE N1 ST GENERAL OREROOM 2 23 23 2 R1 CHAPEL HILL ES MLK JR. BOULE NORTH R1 ARKING ARD ILITI R1 / R2OVERFLOW ZONEP V VICES C R A F SHOPS GY SE EY 43 RN 43 ENERBUILDING CONSTRUCTION PRITCHARD STREET R1 NC 86 CHURCH STREET . HO , JR. BOULE ES F R1 / V STREET SER L BUILDING VICE ARD A ST ATIO GI EET N TR AIRPOR R2 S T DRIVE IN LUTHER KING BRANCH T L MAR HIL TH WEST ROSEMARY STREET EAST ROSEMARY STREET L R ACILITIES DRIVE F A NO 24 STUDRT 24 TH COLUMBI IO CHAPE R ADMINIST OFF R NO BUILDINGICE ATIVE R10 1700 N9 MLK 208 WEST 3 N10 FRANKLIN ST. -

South African TVET, CET and Private Colleges
Department of Higher Education and Training 123 Francis Baard Street Pretoria South Africa Private Bag X174 Pretoria 0001 Tel.: 0800 87 22 22 Published by the Department of Higher Education and Training. www.dhet.gov.za © Department of Higher Education and Training, 2019. This publication may be used in part or as a whole, provided that the Department of Higher Education and Training is acknowledged as the source of information. The Department of Higher Education and Training does all it can to accurately consolidate and integrate national education information, but cannot be held liable for incorrect data and for errors in conclusions, opinions and interpretations emanating from the information. Furthermore, the Department cannot be held liable for any costs, losses or damage that may arise as a result of any misuse, misunderstanding or misinterpretation of the statistical content of the publication. ISBN: 978-1-77018-854-9 This report is available on the Department of Higher Education and Training’s website: www.dhet.gov.za. Enquiries: Tel: +27 (0)12 312 6191/5961 Email: [email protected] ii FOREWORD In general, the Department of Higher Education and Training (the Department) publishes college examination data in its annual publication on Statistics on Post- School Education and Training, which can be found on the Department’s website at www.dhet.gov.za. However, owing to the unavailability of college examination data when the 2017 Statistics on Post-School Education and Training in South Africa was released in March 2019, I present to you a special issue of the 2017 Examination Data: South African Technical and Vocational Education and Training (TVET), Community Education and Training (CET) and Private Colleges. -

SANRAL-Integrated-Report-Volume-1
2020 INTEGRATED REPORT VOLUME ONE LEADER IN INFRASTRUCTURE DEVELOPMENT The South African National Roads Agency SOC Limited Integrated Report 2020 The 2020 Integrated Report of the South African National Roads Agency SOC Limited (SANRAL) covers the period 1 April 2019 to 31 March 2020 and describes how the Agency gave effect to its statutory mandate during this period. The report is available in print and electronic formats and is presented in two volumes: • Volume 1: Integrated Report is a narrative and statistical description of major developments during the year and of value generated in various ways. • Volume 2: Annual Financial Statements and the Corporate Governance Report. In selecting qualitative and quantitative information for the report, the Agency has strived to be concise but reasonably comprehensive and has followed the principle of materiality—content that shows the Agency’s value-creation in the short, medium and long term. The South African National Roads Agency SOC Limited | Reg no: 1998/009584/30 The South African National Roads Agency SOC Limited | Reg no: 1998/009584/30 THE SOUTH AFRICAN NATIONAL ROAD AGENCY SOC LTD INTEGRATED REPORT Volume One CHAIRPERSON’S REPORT 1 CHIEF EXECUTIVE OFFICER’S REPORT 5 SECTION 1: COMPANY OVERVIEW 12 Vision, Mission and Principal Tasks and Objectives 13 Business and Strategy 14 Implementation of Horizon 2030 15 Board of Directors 20 Executive Management 21 Regional Management 22 SECTION 2: CAPITALS AND PERFORMANCE 24 1. Manufactured Capital 25 1.1 Road development, improvement and rehabilitation -

Cape Town 2020/2021
campus guide CAPE TOWN 2020/2021 1 business online, but our students can • What are the sizes of the class? continue with their studies from the • What is the training methodology used comfort of their own home. to deliver skills and is it suited to your contents learning style? Learners’ needs are changing, technology is evolving, skills are different, automation CTU offers a variety of innovative campus & area history 3 is altering processes and globalisation is solutions and services in education to expanding our reach. Our ability to adapt enable modern learning in the new digital campus staff 4 and prepare for change often defines our world. Hybrid learning, CTU’s teaching cape town campus 5 success. While technology is helping lead methodology, is a knowledge and innovation, developing soft skills is just as skills learning process that uses various tips & to-do’s 6 necessary to stay relevant, communicate teaching methods which integrates value and supplement those important message from the ceo digital, recorded and traditional face-to- 10 things to do in cape town technical skills. Soft skills such as face class activities in a planned manner. You’ve finished school, you are a career for R100 or less 7 emotional intelligence, collaboration and The method ensures that the student self- changer or will finish school at the end of negotiation are growing more important direct their learning process by choosing this year - where to from here? success stories 8 as organisations become more global and the learning methods and materials diverse. When considering how to acquire the available that best fit their characteristics accommodation 9 and needs-oriented to reach competence right qualification or short course for your If you work in the IT field, it’s very much a in the required outcomes. -

2018 INTEGRATED REPORT Volume 1
2018 INTEGRATED REPORT VOLUME 1 Goals can only be achieved if efforts and courage are driven by purpose and direction Integrated Report 2017/18 The South African National Roads Agency SOC Limited Reg no: 1998/009584/30 THE SOUTH AFRICAN NATIONAL ROADS AGENCY SOC LIMITED The South African National Roads Agency SOC Limited Integrated Report 2017/18 About the Integrated Report The 2018 Integrated Report of the South African National Roads Agency (SANRAL) covers the period 1 April 2017 to 31 March 2018 and describes how the agency gave effect to its statutory mandate during this period. The report is available in printed and electronic formats and is presented in two volumes: • Volume 1: Integrated Report is a narrative on major development during the year combined with key statistics that indicate value generated in various ways. • Volume 2: Annual Financial Statements contains the sections on corporate governance and delivery against key performance indicators, in addition to the financial statements. 2018 is the second year in which SANRAL has adopted the practice of integrated reporting, having previously been guided solely by the approach adopted in terms of the Public Finance Management Act (PFMA). The agency has attempted to demonstrate the varied dimensions of its work and indicate how they are strategically coherent. It has continued to comply with the reporting requirements of the PFMA while incorporating major principles of integrated reporting. This new approach is supported by the adoption of an integrated planning framework in SANRAL’s new strategy, Horizon 2030. In selecting qualitative and quantitative information for the report, the agency has been guided by Horizon 2030 and the principles of disclosure and materiality. -

Government Gazette Staatskoerant REPUBLIC of SOUTH AFRICA REPUBLIEK VAN SUID AFRIKA
Government Gazette Staatskoerant REPUBLIC OF SOUTH AFRICA REPUBLIEK VAN SUID AFRIKA Regulation Gazette No. 10177 Regulasiekoerant March Vol. 657 13 2020 No. 43086 Maart PART 1 OF 2 ISSN 1682-5843 N.B. The Government Printing Works will 43086 not be held responsible for the quality of “Hard Copies” or “Electronic Files” submitted for publication purposes 9 771682 584003 AIDS HELPLINE: 0800-0123-22 Prevention is the cure 2 No. 43086 GOVERNMENT GAZETTE, 13 MARCH 2020 IMPORTANT NOTICE OF OFFICE RELOCATION Private Bag X85, PRETORIA, 0001 149 Bosman Street, PRETORIA Tel: 012 748 6197, Website: www.gpwonline.co.za URGENT NOTICE TO OUR VALUED CUSTOMERS: PUBLICATIONS OFFICE’S RELOCATION HAS BEEN TEMPORARILY SUSPENDED. Please be advised that the GPW Publications office will no longer move to 88 Visagie Street as indicated in the previous notices. The move has been suspended due to the fact that the new building in 88 Visagie Street is not ready for occupation yet. We will later on issue another notice informing you of the new date of relocation. We are doing everything possible to ensure that our service to you is not disrupted. As things stand, we will continue providing you with our normal service from the current location at 196 Paul Kruger Street, Masada building. Customers who seek further information and or have any questions or concerns are free to contact us through telephone 012 748 6066 or email Ms Maureen Toka at [email protected] or cell phone at 082 859 4910. Please note that you will still be able to download gazettes free of charge from our website www.gpwonline.co.za.