OPTIMIZING NBA LINEUPS by Jason Spector
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Defensive Rebounding
53 Basketball Rebounding Drills and Games BreakthroughBasketball.com By Jeff and Joe Haefner Copyright Notice All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical. Any unauthorized use, sharing, reproduction, or distribution is strictly prohibited. © Copyright 2009 Breakthrough Basketball, LLC Limits / Disclaimer of Warranty The authors and publishers of this book and the accompanying materials have used their best efforts in preparing this book. The authors and publishers make no representation or warranties with respect to the accuracy, applicability, fitness, or completeness of the contents of this book. They disclaim any warranties (expressed or implied), merchantability, or fitness for any particular purpose. The authors and publishers shall in no event be held liable for any loss or other damages, including but not limited to special, incidental, consequential, or other damages. This manual contains material protected under International and Federal Copyright Laws and Treaties. Any unauthorized reprint or use of this material is prohibited. Page | 3 Skill Codes for Each Drill Here’s an explanation of the codes associated with each drill. Most of the drills build a variety of rebounding skills, so we used codes to signify the skills that each drill will develop. Use the table of contents below and this key to find the drills that fit your needs. • Y = Youth • AG = Aggression • TH = Timing and Getting Hands Up • BX = Boxing out • SC = Securing / Chinning -

Instructions to and Duties of the Scorer for Basketball Games Rules Coverage: 7
2019 Scorers & Timers Sheets_2004 Basketball Scorers & timers.qxd 7/10/2019 10:07 AM Page 1 INSTRUCTIONS TO AND DUTIES OF THE SCORER FOR BASKETBALL GAMES RULES COVERAGE: 7. First of one-and-one: First made, bonus awarded: Rule 1-17: The scorer’s location at the scorer’s and timer’s table must be Bonus free throw made: clearly marked with an “x.” 8. Record the number of charged time-outs (who/when) for each team. Rule 2-1-3: It is recommended that the official scorer and timer be seated 9. Check the scoreboard often and have the progressive team totals next to each other. available at all times. Points scored in the wrong basket are never Rule 2-4-3: The referee designates the official scorebook and the official credited to a player, but are credited to the team in a footnote. Points scorer. awarded for basket interference or goaltending by the defense are Rule 2-11: The duties and responsibilities of the official scorer are indicat - credited to the shooter. When a live ball goes in the basket, the last ed. In case of doubt, signal the floor official as soon as conditions permit player who touched the ball causes it to go there. to verify the official’s decision. Rule 2-11-12: The official scorer is required to wear a black-and-white ver - tically striped garment. NOTIFY THE NEARER OFFICIAL WHEN: 1. The bonus penalty is in effect for the seventh, eighth and ninth team RESPONSIBILITY: foul in each half. The bonus display indicates a second free throw is awarded for all common fouls (other than player-control) if the first The scorer’s responsibility is so great that floor officials must establish the free throw is successful. -

Analysis of Different Types of Turnovers Between Winning and Losing Performances in Men’S NCAA Basketball
한국컴퓨터정보학회논문지 Journal of The Korea Society of Computer and Information Vol. 25 No. 7, pp. 135-142, July 2020 JKSCI https://doi.org/10.9708/jksci.2020.25.07.135 Analysis of different types of turnovers between winning and losing performances in men’s NCAA basketball 1)Doryung Han*, Mark Hawkins**, HyongJun Choi*** *Honorary principal professor, Major of Security secretary Studies Continuing Education Center, Kyonggi University, Seoul, Korea **Head coach, Performance Analysis of Sport, University of Wales, UK ***Associate Professor, Dept. of Physical Education (Performance Analysis in Sport), Dankook University, Yongin, Korea [Abstract] Basketball is a highly complex sport, analyses offensive and defensive rebounds, free throw percentages, minutes played and an efficiency rating. These statistics can have a large bearing and provide a lot of pressure on players as their every move can be analysed. Performance analysis in sport is a vital way of being able to track a team or individuals performance and more commonly used resource for player and team development. Discovering information such as this proves the importance of these types of analysis as with post competition video analysis a coach can reach a far more accurate analysis of the game leading to the ability to coach and correct the exact requirements of the team instead of their perceptions. A significant difference was found between winning and losing performances for different types of turnovers supporting current research that states that turnovers are not a valid predictor of match outcomes and that there is no specific type of turnover which can predict the outcome of a match as briefly mentioned in Curz and Tavares (1998). -

Official Basketball Statistics Rules Basic Interpretations
Official Basketball Statistics Rules With Approved Rulings and Interpretations (Throughout this manual, Team A players have last names starting with “A” the shooter tries to control and shoot the ball in the and Team B players have last names starting with “B.”) same motion with not enough time to get into a nor- mal shooting position (squared up to the basket). Article 2. A field goal made (FGM) is credited to a play- Basic Interpretations er any time a FGA by the player results in the goal being (Indicated as “B.I.” references throughout manual.) counted or results in an awarded score of two (or three) points except when the field goal is the result of a defen- sive player tipping the ball in the offensive basket. 1. APPROVED RULING—Approved rulings (indicated as A.R.s) are designed to interpret the spirit of the applica- Related rules in the NCAA Men’s and Women’s Basketball tion of the Official Basketball Rules. A thorough under- Rules and Interpretations: standing of the rules is essential to understanding and (1) 4-33: Definition of “Goal” applying the statistics rules in this manual. (2) 4-49.2: Definition of “Penalty for Violation” (3) 4-69: Definition of “Try for Field Goal” and definition of 2. STATISTICIAN’S JOB—The statistician’s responsibility is “Act of Shooting” to judge only what has happened, not to speculate as (4) 4-73: Definition of “Violation” to what would have happened. The statistician should (5) 5-1: “Scoring” not decide who would have gotten the rebound if it had (6) 9-16: “Basket Interference and Goaltending” not been for the foul. -

The Effect Alternate Player Efficiency Rating Has on NBA Franchises Regarding Winning and Individual Value to an Organization
St. John Fisher College Fisher Digital Publications Sport Management Undergraduate Sport Management Department Spring 2012 The Effect Alternate Player Efficiency Rating Has on NBA Franchises Regarding Winning and Individual Value to an Organization Anthony Van Curen St. John Fisher College Follow this and additional works at: https://fisherpub.sjfc.edu/sport_undergrad Part of the Sports Management Commons How has open access to Fisher Digital Publications benefited ou?y Recommended Citation Van Curen, Anthony, "The Effect Alternate Player Efficiency Rating Has on NBAr F anchises Regarding Winning and Individual Value to an Organization" (2012). Sport Management Undergraduate. Paper 35. Please note that the Recommended Citation provides general citation information and may not be appropriate for your discipline. To receive help in creating a citation based on your discipline, please visit http://libguides.sjfc.edu/citations. This document is posted at https://fisherpub.sjfc.edu/sport_undergrad/35 and is brought to you for free and open access by Fisher Digital Publications at St. John Fisher College. For more information, please contact [email protected]. The Effect Alternate Player Efficiency Rating Has on NBAr F anchises Regarding Winning and Individual Value to an Organization Abstract For NBA organizations, it can be argued that success is measured in terms of wins and championships. There are major emphases placed on the demand for “superstar” players and the ability to score. Both of which are assumed to be a player’s value to their respective organization. However, this study will attempt to show that scoring alone cannot measure success. The research uses statistics from the 2008-2011 seasons that can be used to measure success through aspects such as efficiency, productivity, value and wins a player contributes to their organization. -
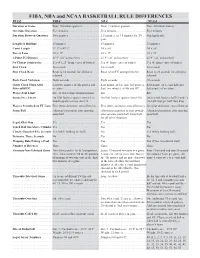
FIBA, NBA and NCAA BASKETBALL RULE DIFFERENCES RULE FIBA NBA NCAA Duration of Game
FIBA, NBA and NCAA BASKETBALL RULE DIFFERENCES RULE FIBA NBA NCAA Duration of Game . .Four, 10-minute quarters . .Four, 12-minute quarters . .Two, 20-minute halves Overtime Duration . .Five minutes . .Five minutes . .Five minutes Duration Between Quarters . .Two minutes . .2.5 minutes; or 3.5 minutes for TV . .Not Applicable . .game Length of Halftime . .15 minutes . .15 minutes . .15 minutes Court Length . .91' 9" x 49' 2" . .94' x 50' . .94' x 50' Size of Lane . .16’ x 19' . .16' x 19' . .12' x 19' 3-Point FG Distance . .23’9” (22’ on baseline) . .23’9” (22’ on baseline) . .23’9” (22’ on baseline) No Charge Semicircles . .Yes (4’1.25” from center of basket) . .Yes (4’ from center of basket) . .Yes (4’ from center of basket) Shot Clock . .24 seconds . .24 seconds . .30 seconds Shot Clock Reset . .Reset to 14 seconds for offensive . .Reset when FG attempt hits rim . .Reset to 20 seconds for offensive . .rebound . .rebound Back Court Violation . .Eight seconds . .Eight seconds . .10 seconds Game Clock Stops After . .Last two minutes of 4th quarter and . .Last minute of 1st, 2nd, 3rd quarters; .Last minute of second half and Successful FG . .overtime . .Last two minutes of 4th and OT . .last minute of overtime Player Foul Limit . .Five or two technical/unsportsman . .Six . .Five Bonus Free Throw . .On fifth foul per quarter (two FTs); . .On fitth foul per quarter (two FTs) . .On seventh foul per half (1-and-1); . .Fourth quarter carries into OT . .On 10th foul per half (two FTs) Players Permitted on FT Lane .Five (three defensive, two offensive) . -

Choking and Excelling at the Free-Throw Line
THE INTERNATIONAL JOURNAL OF CREATIVITY & PROBLEM SOLVING 2009, 19(1), 53-58 Choking and Excelling at the Free Throw Line Darrell A. Worthy, Arthur B. Markman, and W. Todd Maddox University of Texas, Austin Psychological research suggests that trying to avoid a negative outcome and trying to attain a positive outcome have different effects on performance (Higgins, 1997). We explored this prospect by examining free throw performance among NBA bas- ketball players at the ends of games when the player’s team was ahead or behind in a clutch situation. Players tended to shoot worse than their career average when their team was behind or when their team was ahead by one point. In contrast, players tended to shoot better than their career average when the game was tied. Thus, the point margin affected a player’s likelihood of choking or excelling under pressure. This research provides a novel real-world analysis of the phenomenon of choking under pressure that could guide and motivate future research. INTRODUCTION Many professional basketball games are decided by players’ ability to complete their free throws in the final moments of the contest. Free throws are an interesting case, because the player gets an unobstructed shot at the basket from a distance of 15 feet, and so the on-court conditions for taking this shot are always the same. There is anecdotal evidence for the phenomenon of “choking” under pressure in which a player is more likely to miss a crucial free throw late in a close game. In this paper we present an innovative approach to examining the effects of pressure on the free-throw performance of professional athletes in clutch situations. -
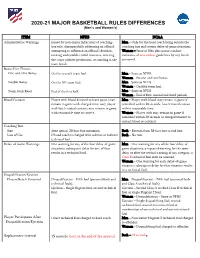
NCAA and NFHS Major Basketball Rules Differences
2020-21 MAJOR BASKETBALL RULES DIFFERENCES (Men’s and Women’s) ITEM NFHS NCAA Administrative Warnings Issued for non-major infractions of coaching- Men – Only for the head coach being outside the box rule, disrespectfully addressing an official, coaching box and certain delay-of-game situations. attempting to influence an official’s decision, Women – Same as Men plus minor conduct inciting undesirable crowd reactions, entering violations of misconduct guidelines by any bench the court without permission, or standing at the personnel. team bench. Bonus Free Throws One-and-One Bonus On the seventh team foul. Men – Same as NFHS. Women – No one-and-one bonus. Double Bonus On the 10th team foul. Men – Same as NFHS. Women – On fifth team foul. Team Fouls Reset End of the first half. Men – Same as NFHS. Women – End of first, second and third periods. Blood/Contacts Player with blood directed to leave game (may Men – Player with blood may remain in game if remain in game with charged time-out); player remedied within 20 seconds. Lost/irritated contact with lost/irritated contacts may remain in game within reasonable time. with reasonable time to correct. Women – Player with may remain in game if remedied within 20 seconds or charged timeout to correct blood or contacts. Coaching Box Size State option, 28-foot box maximum. Both – Extends from 38-foot line to end line. Loss of Use If head coach is charged with a direct or indirect Both – No rule. technical foul. Delay-of-Game Warnings One warning for any of the four delay-of-game Men – One warning for any of the four delay-of- situations; subsequent delay for any of four game situations; a repeated warning for the same results in a technical foul. -

Basketball Section 1: History in the Year 1891, Dr. James A. Naismith
1 Basketball Section 1: History In the year 1891, Dr. James A. Naismith an instructor at Springfield College in Massachusetts, was given the challenge of creating a new game that could be played indoors, basketball. Basketball is played on a rectangular court by two opposing teams of five players each. The object of the game is to score more points than the other opposing team in the allotted time. Scoring is accomplished by advancing the ball into position by passing or dribbling and then shooting the ball through the opponent's goal. The ball is passed, thrown, bounced, batted or rolled from one player to another. The team not in possession of the ball attempts to deny the offensive team the opportunity to score. Basketball presents the opportunity to learn ball skills, coordination, agility, and body control: participation in the game can contribute toward maintenance of an individual's total fitness. The fundamental skills needed are pivoting, catching, passing, dribbling, shooting and rebounding. Section 2: Equipment A. The Ground and ball The playing court has dimensions of not greater than 94 ft. in length by 50 ft. in width. Modifications are sometimes made to accommodate space limitations or for younger players. The ball is sperical with a circumference of 29 1/2 to 30 inches for men and 28 1/2 to 29 inches for women. B. Goal The two goals or baskets are fastened to the backboard on a metal ring 18 inches in diameter and 10 feet above the floor. C. Scoring A field goal is scored when a live ball enters the basket from above the basket and passes down through it. -

Does Player Performance Increase During the Postseason? a Look at Professional Basketball
Undergraduate Economic Review Volume 9 Issue 1 Article 2 2012 Does Player Performance Increase During the Postseason? A Look at Professional Basketball Jordan Weiss University of Southern California, [email protected] Follow this and additional works at: https://digitalcommons.iwu.edu/uer Recommended Citation Weiss, Jordan (2012) "Does Player Performance Increase During the Postseason? A Look at Professional Basketball," Undergraduate Economic Review: Vol. 9 : Iss. 1 , Article 2. Available at: https://digitalcommons.iwu.edu/uer/vol9/iss1/2 This Shorter Papers and Communications is protected by copyright and/or related rights. It has been brought to you by Digital Commons @ IWU with permission from the rights-holder(s). You are free to use this material in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you need to obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/ or on the work itself. This material has been accepted for inclusion by faculty at Illinois Wesleyan University. For more information, please contact [email protected]. ©Copyright is owned by the author of this document. Does Player Performance Increase During the Postseason? A Look at Professional Basketball Abstract This study examines the game logs of professional basketball players to determine whether they exhibit elevated performance during the postseason. In a survey of 10 players who were awarded the Most Valuable Player Award during the NBA Finals for the seasons 2001-02 thru 2010- 11, performance was found to be stable throughout the entire season. -

5V5 Basketball
University of Washington Bothell Intramural Sports Basketball Rules 1. PLAYERS AND SUBSTITUTES 1.1. A team consists of five (5) players, but may start with a minimum of four (4) players. A team must have four (4) players on the court at all times. Exception: Less than four (4) players are allowed if an individual cannot continue due to an injury or they have fouled out of the game, as long as the officials deem the team to have a legitimate chance to win the game. 1.2. When a team has forfeited, the opposing team must have at least three (3) players checked in with the supervisor to receive a win. 1.3. Substitutions must be reported to the scoring table before entering the game. Substitutes may enter the game only when the official beckons them. Penalty: Technical foul. 1.4. Teams must wear shirts of the same color, and each shirt must have a different number (numbers greater than 2-digits are not allowed). The size of each number must be at least three inches. Numbers must be written or painted. Numbers may not be taped onto the shirt. Only one player per team is permitted to wear either 0 or 00. 1.5. All players must wear non-marking rubber-soled athletic shoes. Barefoot running shoes are not permitted. 1.6. Jewelry, rubber bands, chains, rings and/or earrings, or headphones may not be worn. Medical alert bracelets may be taped to the body. Penalty: Technical foul. 1.7. Casts (plaster, metal or other hard substances in their final form) or any other item judged to be dangerous by the supervisor, official or Program Manager may not be worn during the game. -

Basketball Sport Rules
BASKETBALL SPORT RULES Basketball Sport Rules 1 VERSION: June 2018 © Special Olympics, Inc., 2018 All rights reserved BASKETBALL SPORT RULES TABLE OF CONTENTS 1. GOVERNING RULES ................................................................................................................................................................ 3 2. OFFICIAL EVENTS ................................................................................................................................................................... 3 3. SPEED DRIBBLE RULES .......................................................................................................................................................... 3 Equipment .................................................................................................................................. 3 Set-up: Mark a circle with a 1.5 meter (4 ft 11 in) diam. .................................................................. 4 Rules .......................................................................................................................................... 4 Scoring ....................................................................................................................................... 4 4. INDIVIDUAL SKILLS RULES ................................................................................................................................................... 4 Level I: .......................................................................................................................................