Design and Implementation of 4-Bit Decimal Multiplier Using Sign Magnitude Encoding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

High Performance Decimal Floating-Point Units
UNIVERSIDADE DE SANTIAGO DE COMPOSTELA DEPARTAMENTO DE ELECTRONICA´ E COMPUTACION´ PhD. Dissertation High-Performance Decimal Floating-Point Units Alvaro´ Vazquez´ Alvarez´ Santiago de Compostela, January 2009 To my family A´ mina˜ familia Acknowledgements It has been a long way to see this thesis successfully concluded, at least longer than what I imagined it. Perhaps the moment to thank and acknowledge everyone’s contributions is the most eagerly awaited. This thesis could not have been possible without the support of several people and organizations whose contributions I am very grateful. First of all, I want to express my sincere gratitude to my thesis advisor, Elisardo Antelo. Specially, I would like to emphasize the invaluable support he offered to me all these years. His ideas and contributions have a major influence on this thesis. I would like to thank all people in the Departamento de Electronica´ e Computacion´ for the material and personal help they gave me to carry out this thesis, and for providing a friendly place to work. In particular, I would like to mention to Prof. Javier D. Bruguera and the other staff of the Computer Architecture Group. Many thanks to Paula, David, Pichel, Marcos, Juanjo, Oscar,´ Roberto and my other workmates for their friendship and help. I am very grateful to IBM Germany for their financial support though a one-year research contract. I would like to thank Ralf Fischer, lead of hardware development, and Peter Roth and Stefan Wald, team managers at IBM Deutchland Entwicklung in Boblingen.¨ I would like to extend my gratitude to the FPU design team, in special to Silvia Muller¨ and Michael Kroner,¨ for their help and the warm welcome I received during my stay in Boblingen.¨ I would also like to thank Eric Schwarz from IBM for his support. -

Fully Redundant Decimal Arithmetic
2009 19th IEEE International Symposium on Computer Arithmetic Fully Redundant Decimal Arithmetic Saeid Gorgin and Ghassem Jaberipur Dept. of Electrical & Computer Engr., Shahid Beheshti Univ. and School of Computer Science, institute for research in fundamental sciences (IPM), Tehran, Iran [email protected], [email protected] Abstract In both decimal and binary arithmetic, partial products in multipliers and partial remainders in Hardware implementation of all the basic radix-10 dividers are often represented via a redundant number arithmetic operations is evolving as a new trend in the system (e.g., Binary signed digit [11], decimal carry- design and implementation of general purpose digital save [5], double-decimal [6], and minimally redundant processors. Redundant representation of partial decimal [9]). Such use of redundant digit sets, where products and remainders is common in the the number of digits is sufficiently more than the radix, multiplication and division hardware algorithms, allows for carry-free addition and subtraction as the respectively. Carry-free implementation of the more basic operations that build-up the product and frequent add/subtract operations, with the byproduct of remainder, respectively. In the aforementioned works enhancing the speed of multiplication and division, is on decimal multipliers and dividers, inputs and outputs possible with redundant number representation. are nonredundant decimal numbers. However, a However, conversion of redundant results to redundant representation is used for the intermediate conventional representations entails slow carry partial products or remainders. The intermediate propagation that can be avoided if the results are kept additions and subtractions are semi-redundant in redundant format for later use as operands of other operations in that only one of the operands as well as arithmetic operations. -

Algorithms and Architectures for Decimal Transcendental Function Computation
Algorithms and Architectures for Decimal Transcendental Function Computation A Thesis Submitted to the College of Graduate Studies and Research in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy in the Department of Electrical and Computer Engineering University of Saskatchewan Saskatoon, Saskatchewan, Canada By Dongdong Chen c Dongdong Chen, January, 2011. All rights reserved. Permission to Use In presenting this thesis in partial fulfilment of the requirements for a Postgraduate degree from the University of Saskatchewan, I agree that the Libraries of this University may make it freely available for inspection. I further agree that permission for copying of this thesis in any manner, in whole or in part, for scholarly purposes may be granted by the professor or professors who supervised my thesis work or, in their absence, by the Head of the Department or the Dean of the College in which my thesis work was done. It is understood that any copying or publication or use of this thesis or parts thereof for financial gain shall not be allowed without my written permission. It is also understood that due recognition shall be given to me and to the University of Saskatchewan in any scholarly use which may be made of any material in my thesis. Requests for permission to copy or to make other use of material in this thesis in whole or part should be addressed to: Head of the Department of Electrical and Computer Engineering 57 Campus Drive University of Saskatchewan Saskatoon, Saskatchewan Canada S7N 5A9 i Abstract Nowadays, there are many commercial demands for decimal floating-point (DFP) arith- metic operations such as financial analysis, tax calculation, currency conversion, Internet based applications, and e-commerce. -

History of Binary and Other Nondecimal Numeration
HISTORY OF BINARY AND OTHER NONDECIMAL NUMERATION BY ANTON GLASER Professor of Mathematics, Pennsylvania State University TOMASH PUBLISHERS Copyright © 1971 by Anton Glaser Revised Edition, Copyright 1981 by Anton Glaser All rights reserved Printed in the United States of America Library of Congress Cataloging in Publication Data Glaser, Anton, 1924- History of binary and other nondecimal numeration. Based on the author's thesis (Ph. D. — Temple University), presented under the title: History of modern numeration systems. Bibliography: p. 193 Includes Index. 1. Numeration — History. I. Title QA141.2.G55 1981 513'.5 81-51176 ISBN 0-938228-00-5 AACR2 To My Wife, Ruth ACKNOWLEDGMENTS THIS BOOK is based on the author’s doctoral dissertation, History of Modern Numeration Systems, written under the guidance of Morton Alpren, Sara A. Rhue, and Leon Steinberg of Temple University in Philadelphia, Pa. Extensive help was received from the libraries of the Academy of the New Church (Bryn Athyn, Pa.), the American Philosophical Society, Pennsylvania State University, Temple University, the University of Michigan, and the University of Pennsylvania. The photograph of Figure 7 was made available by the New York Public Library; the library of the University of Pennsylvania is the source of the photographs in Figures 2 and 6. The author is indebted to Harold Hanes, Joseph E. Hofmann, Donald E. Knuth, and Brian J. Winkel, who were kind enough to communicate their comments about the strengths and weaknesses of the original edition. The present revised edition is the better for it. A special thanks is also owed to John Wagner for his careful editorial work and to Adele Clark for her thorough preparation of the Index. -

Ed 040 737 Institution Available from Edrs Price
DOCUMENT RESUME ED 040 737 LI 002 060 TITLE Automatic Data Processing Glossary. INSTITUTION Bureau of the Budget, Washington, D.C. NOTE 65p. AVAILABLE FROM Reprinted and distributed by Datamation Magazine, 35 Mason St., Greenwich, Conn. 06830 ($1.00) EDRS PRICE EDRS Price MF-$0.50 HC-$3.35 DESCRIPTORS *Electronic Data Processing, *Glossaries, *Word Lists ABSTRACT The technology of the automatic information processing field has progressed dramatically in the past few years and has created a problem in common term usage. As a solution, "Datamation" Magazine offers this glossary which was compiled by the U.S. Bureau of the Budget as an official reference. The terms appear in a single alphabetic sequence, ignoring commas or hyphens. Definitions are given only under "key word" entries. Modifiers consisting of more than one word are listed in the normally used sequence (record, fixed length). In cases where two or more terms have the same meaning, only the preferred term is defined, all synonylious terms are given at the end of the definition.Other relationships between terms are shown by descriptive referencing expressions. Hyphens are used sparingly to avoid ambiguity. The derivation of an acronym is shown by underscoring the appropriate letters in the words from which the acronym is formed. Although this glossary is several years old, it is still considered the best one available. (NH) Ns U.S DEPARTMENT OF HEALTH, EDUCATION & WELFARE OFFICE OF EDUCATION THIS DOCUMENT HAS BEEN REPRODUCED EXACTLY AS RECEIVED FROM THE PERSON OR ORGANIZATION ORIGINATING IT POINTS OF VIEW OR OPINIONS STATED DO NOT NECES- SARILY REPRESENT OFFICIAL OFFICE OF EDU- CATION POSITION OR POLICY automatic data processing GLOSSA 1 I.R DATAMATION Magazine reprints this Glossary of Terms as a service to the data processing field. -

Report Association for Computing Machinery
June 1954 REPORT TO THE ASSOCIATION FOR COMPUTING MACHINERY FIRST GLOSSARY of PROGRAMMING TERMINOLOGY Committee on Nomenclature 'Co Wo Adams R. FoOsborn J 0 W 0 Backus G. W. Patterson J 0 W. Carr, III J. Svigals J. Wegstein Grace Murray Hopper, Chairman COPIES Copies of this glossary are available at 25, each. When ordered by mail, the price is 50~for the first copy and 25<'f for each 'additional copy sent to one address. Please address all orders, with cash or -check enclosed" to the Association for Computing Machinery" 2 East 63rd Street, New York 2'1" N.Y. ACKNOWLEDQ]lJIENT This (·programmer's glossary" had its ,inception in a glos sary compiled by Dr. Grace Murray Hopper for the Workshops on AutomaticOoding held in 1953 under the sponsorship of the Bur eau of Oensus, the Office of the Air Comptroller, and Remington Rand" Inc. '!he answers to the plea for criticisms and sugges tions made in that first version were most generous o Everyef fort has been made to include all of them or to arbitrate fairly those in conflict. Both versions have borrowed heavi~y from the "St1mdards on Electronic Computers: l)efinitionsof' Terms" 1950"" Proceedipgs of the I.R.E." Vol. 39 No.3" pp. 271-277" March 1951" and from the "Glossary", Computers and Automation~ Vol. 2" Nos. 2" 4 and 9" March" May, and December" 1953. The commit tee extends its thanks to the authors ,of those glossaries and to the many others who have contributed their time and thoughts to the preparation of this glossary. -
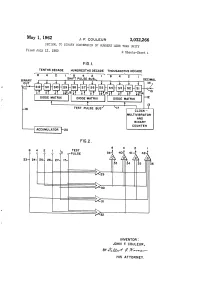
Is Hirihiti?H DECIMAL
May 1, 1962 J. F. COULEUR 3,032,266 DECIMAL TO BINARY CONVERSION OF NUMBERS LESS THAN UNITY Filed July 12, l960 2 Sheets-Sheet l FG.I. TENTHS DECADE HUNDREDTHS DECADE THOUSANDTHS DECADE 4. 2 is hirihiti?h DECIMAL TERAF DODE MATRIX DODE MATRIX DODE MATRIX TEST PULSE BUS CLOCK - MULTIVBRATOR AND BNARY COUNTER ACCUMULATOR NVENTOR: JOHN F. COULEUR, BY (4-f (? W2----- HIS AT TORNEY. May 1, 1962 J. F. COULEUR 3,032,266 DECIMAL TO BINARY CONVERSION OF NUMBERS LESS THAN UNITY Filed July 12, 1960 2. Sheets-Sheet 2 F.G.3. BINARY BINARY CODED DECMAL TENTHS HUNDREDTHS THOUSANDTHS Row 3 2 8 NUMBER O O OOO OOO () OO OOO O T (2) O O O O O OO S (3) O OO OOO OO T (4) O OO OOO OOO S (5) O OO OOO OOO T (6) OO O O OOO OOO S (7) OO OO OOO OOO T (8) OO OOO OO O OOO S (9) OO OOO OOO O T (O) OOO OOO OO OO S (I) OOO OOO OO OO T (2) OOOO OO OO OOO S (3) OOOO OO OO OOO T (4) OOOO OO OOO OO O S (5) OOOO OO O OOO. T (6) OOOO OO OO OOO S (7) OOOO OO OO O T (8) OOOO OO OO O O S (9) OOOO OO OO OO T (20) OOOO OOO O OO O S (2) T MEANS TEST AND ADD THREE TO ANY DECADE 2 5 S MEANS SHIFT FIG.4. BINARY BNARY CODED DECMA -------------------IO- IO-2 IO-3 IO-4 10-5 O-6 (3) (2) (8) () (2) (5) OO OOO OOO OOO OOO OO OO OOO O OOO OOO OOO T O O O Oi Oi O O OOO O. -

Design and Architecture of New 11:2 Decimal Compressors
Sådhanå (2019) 44:125 Ó Indian Academy of Sciences https://doi.org/10.1007/s12046-019-1110-4Sadhana(0123456789().,-volV)FT3](0123456789().,-volV) Design and architecture of new 11:2 decimal compressors PRABIR SAHA* and PUJA SAMANTA National Institute of Technology Meghalaya, Shillong, India e-mail: [email protected]; [email protected] MS received 5 January 2018; revised 11 March 2019; accepted 19 March 2019; published online 25 April 2019 Abstract. Design and architectures of new 11:2 decimal compressors have been reported in this paper. Two design methodologies viz. delay and area optimized compressors have been introduced and implemented through tree structure of decimal number system. The architectures have been realized through vertical carry save addition algorithm, wherein to build up such addition of unconventional (4221 and 5211) binary coded decimal technique has been incorporated. Configurations of such compressors have been prototyped and tran- sistor level implementation have been carried out to evaluate performance parameters like speed (propagation delay), power dissipation, area and area delay product. The architecture has been validated by Cadence virtuoso platform using 90 nm, 65 nm and 45 nm CMOS technology which provides useful statistics to determine the compressor’s performance parameters. The propagation delay of the delay optimized compressor equals to *0.094 ns while the propagation delay of the area optimized compressor is *0.124 ns using 90 nm CMOS technology at 1 V supply voltage. The reported architectures are *24% and *41% faster from its counterpart. Keywords. Cadence; decimal compressor; layout area; power consumption; propagation delay. 1. Introduction multiplication; hence it reduces the overall delay of the multiplication. -
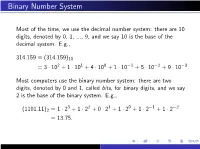
Binary Number System
Binary Number System Most of the time, we use the decimal number system: there are 10 digits, denoted by 0, 1, ..., 9, and we say 10 is the base of the decimal system. E.g., 314:159 ≡ (314:159)10 = 3 · 102 + 1 · 101 + 4 · 100 + 1 · 10−1 + 5 · 10−2 + 9 · 10−3: Most computers use the binary number system: there are two digits, denoted by 0 and 1, called bits, for binary digits, and we say 2 is the base of the binary system. E.g., 3 2 1 0 −1 −2 (1101:11)2 = 1 · 2 + 1 · 2 + 0 · 2 + 1 · 2 + 1 · 2 + 1 · 2 = 13:75: DECIMAL FLOATING-POINT NUMBERS Floating point notation is akin to what is called scientific notation in high school algebra. For a nonzero number x, we can write it in the form x = σ · ξ · 10e with e an integer, 1 ≤ ξ < 10, and σ = +1 or −1. Thus 50 = (1:66666 ··· ) · 101; with σ = +1 3 10 On a decimal computer or calculator, we store x by instead storing σ, ξ, and e. We must restrict the number of digits in ξ and the size of the exponent e. For example, on an HP-15C calculator, the number of digits kept in ξ is 10, and the exponent is restricted to −99 ≤ e ≤ 99. BINARY FLOATING-POINT NUMBERS We now do something similar with the binary representation of a number x. Write x = σ · ξ · 2e with 1 ≤ ξ < (10)2 = 2 and e an integer. For example, −4 (:1)10 = (1:10011001100 ··· )2 · 2 ; σ = +1 The number x is stored in the computer by storing the σ, ξ, and e. -

Downloading from Naur's Website: 19
1 2017.04.16 Accepted for publication in Nuncius Hamburgensis, Band 20. Preprint of invited paper for Gudrun Wolfschmidt's book: Vom Abakus zum Computer - Begleitbuch zur Ausstellung "Geschichte der Rechentechnik", 2015-2019 GIER: A Danish computer from 1961 with a role in the modern revolution of astronomy By Erik Høg, lektor emeritus, Niels Bohr Institute, Copenhagen Abstract: A Danish computer, GIER, from 1961 played a vital role in the development of a new method for astrometric measurement. This method, photon counting astrometry, ultimately led to two satellites with a significant role in the modern revolution of astronomy. A GIER was installed at the Hamburg Observatory in 1964 where it was used to implement the entirely new method for the meas- urement of stellar positions by means of a meridian circle, then the fundamental instrument of as- trometry. An expedition to Perth in Western Australia with the instrument and the computer was a suc- cess. This method was also implemented in space in the first ever astrometric satellite Hipparcos launched by ESA in 1989. The Hipparcos results published in 1997 revolutionized astrometry with an impact in all branches of astronomy from the solar system and stellar structure to cosmic distances and the dynamics of the Milky Way. In turn, the results paved the way for a successor, the one million times more powerful Gaia astrometry satellite launched by ESA in 2013. Preparations for a Gaia suc- cessor in twenty years are making progress. Zusammenfassung: Eine elektronische Rechenmaschine, GIER, von 1961 aus Dänischer Herkunft spielte eine vitale Rolle bei der Entwiklung einer neuen astrometrischen Messmethode. -
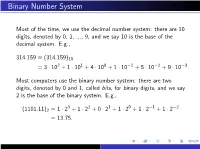
Binary Number System
Binary Number System Most of the time, we use the decimal number system: there are 10 digits, denoted by 0, 1, ..., 9, and we say 10 is the base of the decimal system. E.g., 314:159 ≡ (314:159)10 = 3 · 102 + 1 · 101 + 4 · 100 + 1 · 10−1 + 5 · 10−2 + 9 · 10−3: Most computers use the binary number system: there are two digits, denoted by 0 and 1, called bits, for binary digits, and we say 2 is the base of the binary system. E.g., 3 2 1 0 −1 −2 (1101:11)2 = 1 · 2 + 1 · 2 + 0 · 2 + 1 · 2 + 1 · 2 + 1 · 2 = 13:75: DECIMAL FLOATING-POINT NUMBERS Floating point notation is akin to what is called scientific notation in high school algebra. For a nonzero number x, we can write it in the form x = σ · ξ · 10e with e an integer, 1 ≤ ξ < 10, and σ = +1 or −1. Thus 50 = (1:66666 ··· ) · 101; with σ = +1 3 10 On a decimal computer or calculator, we store x by instead storing σ, ξ, and e. We must restrict the number of digits in ξ and the size of the exponent e. For example, on an HP-15C calculator, the number of digits kept in ξ is 10, and the exponent is restricted to −99 ≤ e ≤ 99. BINARY FLOATING-POINT NUMBERS We now do something similar with the binary representation of a number x. Write x = σ · ξ · 2e with 1 ≤ ξ < (10)2 = 2 and e an integer. For example, −4 (:1)10 = (1:10011001100 ··· )2 · 2 ; σ = +1 The number x is stored in the computer by storing the σ, ξ, and e. -

A High Performance Binary to BCD Converter
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875 International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering (An ISO 3297: 2007 Certified Organization) Vol. 4, Issue 8, August 2015 A High Performance Binary to BCD Converter A. Hari Priya1 Assistant Professor, Dept. of ECE, Indur Institute of Engineering. and Technology, Siddipet, Medak, India1 ABSTRACT: Decimal data processing applications have grown exponentially in recent years thereby increasing the need to have hardware support for decimal arithmetic. Binary to BCD conversion forms the basic building block of decimal digit multipliers. This paper presents novel high speed low power architecture for fixed bit binary to BCD conversion which is at least 28% better in terms of power-delay product than the existing designs. KEYWORDS:Decimal Arithmetic, Binary to BCD Converter I.INTRODUCTION In commercial business and internet based applications, decimal arithmetic is receiving significant importance. Decimal arithmetic is important in many applications such as banking, tax calculation, insurance, accounting and many more. Even though binary arithmetic is used widely, decimal computation is essential. The decimal arithmetic is not only required when numbers are presented for inspection by humans, but also it is a necessity when fractions are being used. Rational numbers whose denominator is a power of ten are decimal fractions and most them cannot be represented by binary fractions. For example, the value 0.01 may require an infinitely recurring binary number. Even though the arithmetic is correct, but if binary approximation is used instead of an exact decimal fraction, results can be wrong. This extensive use of decimal data indicates that it is important to analyse how the data can be used and how the decimal arithmetic can be defined.