A Uniform Platform for Security Analysis of Deep Learning Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

“实时交互”的im技术,将会有什么新机遇? 2019-08-26 袁武林
ᭆʼn ᩪᭆŊ ᶾݐᩪᭆᔜߝ᧞ᑕݎ ғמஙے ᤒ 下载APPڜහਁʼn Ŋ ឴ݐռᓉݎ 开篇词 | 搞懂“实时交互”的IM技术,将会有什么新机遇? 2019-08-26 袁武林 即时消息技术剖析与实战 进入课程 讲述:袁武林 时长 13:14 大小 12.13M 你好,我是袁武林。我来自新浪微博,目前在微博主要负责消息箱和直播互动相关的业务。 接下来的一段时间,我会给你带来一个即时消息技术方面的专栏课程。 你可能会很好奇,为什么是来自微博的技术人来讲这个课程,微博会用到 IM 的技术吗? 在我回答之前,先请你思考一个问题: 除了 QQ 和微信,你知道还有什么 App 会用到即时(实时)消息技术吗? 其实,除了 QQ 和微信外,陌陌、抖音等直播业务为主的 App 也都深度用到了 IM 相关的 技术。 比如在线学习软件中的“实时在线白板”,导航打车软件中的“实时位置共享”,以及和我 们生活密切相关的智能家居的“远程控制”,也都会通过 IM 技术来提升人和人、人和物的 实时互动性。 我觉得可以这么理解:包括聊天、直播、在线客服、物联网等这些业务领域在内,所有需 要“实时互动”“高实时性”的场景,都需要、也应该用到 IM 技术。 微博因为其多重的业务需求,在许多业务中都应用到了 IM 技术,目前除了我负责的消息箱 和直播互动业务外,还有其他业务也逐渐来通过我们的 IM 通用服务,提升各自业务的用户 体验。 为什么这么多场景都用到了 IM 技术呢,IM 的技术究竟是什么呢? 所以,在正式开始讲解技术之前,我想先从应用场景的角度,带你了解一下 IM 技术是什 么,它为互联网带来了哪些巨大变革,以及自身蕴含着怎样的价值。 什么是 IM 系统? 我们不妨先看一段旧闻: 2014 年 Facebook 以 190 亿美元的价格,收购了当时火爆的即时通信工具 WhatsApp,而此时 WhatsApp 仅有 50 名员工。 是的,也就是说这 50 名员工人均创造了 3.8 亿美元的价值。这里,我们不去讨论当时谷歌 和 Facebook 为争抢 WhatsApp 发起的价格战,从而推动这笔交易水涨船高的合理性,从 另一个侧面我们看到的是:依托于 IM 技术的社交软件,在完成了“连接人与人”的使命 后,体现出的巨大价值。 同样的价值体现也发生在国内。1996 年,几名以色列大学生发明的即时聊天软件 ICQ 一 时间风靡全球,3 年后的深圳,它的效仿者在中国悄然出现,通过熟人关系的快速构建,在 一票基于陌生人关系的网络聊天室中脱颖而出,逐渐成为国内社交网络的巨头。 那时候这个聊天工具还叫 OICQ,后来更名为 QQ,说到这,大家应该知道我说的是哪家公 司了,没错,这家公司叫腾讯。在之后的数年里,腾讯正是通过不断优化升级 IM 相关的功 能和架构,凭借 QQ 和微信这两大 IM 工具,牢牢控制了强关系领域的社交圈。 ےۓ由此可见,IM 技术作为互联网实时互动场景的底层架构,在整个互动生态圈的价值所在。᧗ 随着互联网的发展,人们对于实时互动的要求越来越高。于是,IMᴠྊෙๅ 技术不止应用于 QQ、 微信这样的面向聊天的软件,它其实有着宽广的应用场景和足够有想象力的前景。甚至在不 。ғ 系统已经根植于我们的互联网生活中,成为各大 App 必不可少的模块מஙݎ知不觉之间,IMḒ 除了我在前面图中列出的业务之外,如果你希望在自己的 App 里加上实时聊天或者弹幕的 功能,通过 IM 云服务商提供的 SDK 就能快速实现(当然如果需求比较简单,你也可以自 己动手来实现)。 比如,在极客时间 App 中,我们可以加上一个支持大家点对点聊天的功能,或者增加针对 某一门课程的独立聊天室。 例子太多,我就不做一一列举了。其实我想说的是:IM -

Seed Selection for Successful Fuzzing
Seed Selection for Successful Fuzzing Adrian Herrera Hendra Gunadi Shane Magrath ANU & DST ANU DST Australia Australia Australia Michael Norrish Mathias Payer Antony L. Hosking CSIRO’s Data61 & ANU EPFL ANU & CSIRO’s Data61 Australia Switzerland Australia ABSTRACT ACM Reference Format: Mutation-based greybox fuzzing—unquestionably the most widely- Adrian Herrera, Hendra Gunadi, Shane Magrath, Michael Norrish, Mathias Payer, and Antony L. Hosking. 2021. Seed Selection for Successful Fuzzing. used fuzzing technique—relies on a set of non-crashing seed inputs In Proceedings of the 30th ACM SIGSOFT International Symposium on Software (a corpus) to bootstrap the bug-finding process. When evaluating a Testing and Analysis (ISSTA ’21), July 11–17, 2021, Virtual, Denmark. ACM, fuzzer, common approaches for constructing this corpus include: New York, NY, USA, 14 pages. https://doi.org/10.1145/3460319.3464795 (i) using an empty file; (ii) using a single seed representative of the target’s input format; or (iii) collecting a large number of seeds (e.g., 1 INTRODUCTION by crawling the Internet). Little thought is given to how this seed Fuzzing is a dynamic analysis technique for finding bugs and vul- choice affects the fuzzing process, and there is no consensus on nerabilities in software, triggering crashes in a target program by which approach is best (or even if a best approach exists). subjecting it to a large number of (possibly malformed) inputs. To address this gap in knowledge, we systematically investigate Mutation-based fuzzing typically uses an initial set of valid seed and evaluate how seed selection affects a fuzzer’s ability to find bugs inputs from which to generate new seeds by random mutation. -

Darwinian Code Optimisation
Darwinian Code Optimisation Michail Basios A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy of University College London. Department of Computer Science University College London January 18, 2019 2 I, Michail Basios, confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the work. Abstract Programming is laborious. A long-standing goal is to reduce this cost through automation. Genetic Improvement (GI) is a new direction for achieving this goal. It applies search to the task of program improvement. The research conducted in this thesis applies GI to program optimisation and to enable program optimisation. In particular, it focuses on automatic code optimisation for complex managed runtimes, such as Java and Ethereum Virtual Machines. We introduce the term Darwinian Data Structures (DDS) for the data structures of a program that share a common interface and enjoy multiple implementations. We call them Darwinian since we can subject their implementations to the survival of the fittest. We introduce ARTEMIS, a novel cloud-based multi-objective multi-language optimisation framework that automatically finds optimal, tuned data structures and rewrites the source code of applications accordingly to use them. ARTEMIS achieves substantial performance improvements for 44 diverse programs. ARTEMIS achieves 4:8%, 10:1%, 5:1% median improvement for runtime, memory and CPU usage. Even though GI has been applied succesfully to improve properties of programs running in different runtimes, GI has not been applied in Blockchains, such as Ethereum. -
Microsoft / Vcpkg
Microsoft / vcpkg master vcpkg / ports / Create new file Find file History Fetching latest commit… .. abseil [abseil][aws-sdk-cpp][breakpad][chakracore][cimg][date][exiv2][libzip… Apr 13, 2018 ace Update to ACE 6.4.7 (#3059) Mar 19, 2018 alac-decoder [alac-decoder] Fix x64 Mar 7, 2018 alac [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 alembic [alembic] update to 1.7.7 Mar 25, 2018 allegro5 [many ports] Updates to latest Nov 30, 2017 anax [anax] Use vcpkg_from_github(). Add missing vcpkg_copy_pdbs() Sep 25, 2017 angle [angle] Add CMake package with modules. (#2223) Nov 20, 2017 antlr4 [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 apr-util vcpkg_configure_cmake (and _meson) now embed debug symbols within sta… Sep 9, 2017 apr [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 arb [arb] prefer ninja Nov 26, 2017 args [args] Fix hash Feb 24, 2018 armadillo add armadillo (#2954) Mar 8, 2018 arrow Update downstream libraries to use modularized boost Dec 19, 2017 asio [asio] Avoid boost dependency by always specifying ASIO_STANDALONE Apr 6, 2018 asmjit [asmjit] init Jan 29, 2018 assimp [assimp] Fixup: add missing patchfile Dec 21, 2017 atk [glib][atk] Disable static builds, fix generation to happen outside t… Mar 5, 2018 atkmm [vcpkg-build-msbuild] Add option to use vcpkg's integration. Fixes #891… Mar 21, 2018 atlmfc [atlmfc] Add dummy port to detect atl presence in VS Apr 23, 2017 aubio [aubio] Fix missing required dependencies Mar 27, 2018 aurora Added aurora as independant portfile Jun 21, 2017 avro-c -

PDF Bekijken
OSS voor Windows: Fotografie en Grafisch Ook Ook Naam Functie Website Linux NL Wireless photo download from Airnef Nikon, Canon and Sony ja nee testcams.com/airnef cameras ArgyllCMS Color Management System ja nee argyllcms.com Birdfont Font editor ja ja birdfont.org 3D grafisch modelleren, Blender animeren, weergeven en ja ja www.blender.org terugspelen RAW image editor (sinds Darktable ja ja www.darktable.org versie 2.4 ook voor Windows) Creating and editing technical Dia ja nee live.gnome.org/Dia diagrams Geavanceerd programma voor Digikam ja ja www.digikam.org het beheren van digitale foto's Display Calibration and DisplayCAL Characterization powered by ja nee displaycal.net Argyll CMS Drawpile Tekenprogramma ja nee drawpile.net Reading, writing and editing Exiftool photographic metadata in a ja ? sno.phy.queensu.ca/~phil/exiftool/ wide variety of files Met Fotowall kunnen FotoWall fotocollages in hoge resolutie ja nee www.enricoros.com/opensource/fotowall worden gemaakt. 3D CAD and CAM (Computer gCAD3D Aided Design and ja nee gcad3d.org Manufacturing) A Gtk/Qt front-end to gImageReader Tesseract OCR (Optical ja nee github.com/.../gImageReader Character Recognition). GNU Image Manipulation Program voor het bewerken The GIMP ja ja www.gimp.org van digitale foto's en maken van afbeeldingen Workflow oriented photo GTKRawGallery ja nee gtkrawgallery.sourceforge.net retouching software Guetzli Perceptual JPEG encoder ja nee github.com/google/guetzli Maakt panorama uit meerdere Hugin ja ja hugin.sourceforge.net foto's Lightweight, versatile image ImageGlass nee nee www.imageglass.org viewer Create, edit, compose, or ImageMagick ja ? www.imagemagick.org convert bitmap images. -

Efficient Concolic Execution Via Branch Condition Synthesis
SYNFUZZ: Efficient Concolic Execution via Branch Condition Synthesis Wookhyun Han∗, Md Lutfor Rahmany, Yuxuan Chenz, Chengyu Songy, Byoungyoung Leex, Insik Shin∗ ∗KAIST, yUC Riverside, zPurdue, xSeoul National University Abstract—Concolic execution is a powerful program analysis the path exploration as if the target branch has been taken. To technique for exploring execution paths in a systematic manner. generate a concrete input that can follow the same path, the Compare to random-mutation-based fuzzing, concolic execution engine can ask the SMT solver to provide a feasible assignment is especially good at exploring paths that are guarded by complex and tight branch predicates (e.g., (a*b) == 0xdeadbeef). The to all the symbolic input bytes that satisfy the collected path drawback, however, is that concolic execution engines are much constraints. Thanks to the recent advances in SMT solvers, slower than native execution. One major source of the slowness is compare to random mutation based fuzzing, concolic execution that concolic execution engines have to the interpret instructions is known to be much more efficient at exploring paths that to maintain the symbolic expression of program variables. In this are guarded by complex and tight branch predicates (e.g., work, we propose SYNFUZZ, a novel approach to perform scal- (a*b) == 0xdeadbeef able concolic execution. SYNFUZZ achieves this goal by replacing ). interpretation with dynamic taint analysis and program synthesis. However, a critical limitation of concolic execution is its In particular, to flip a conditional branch, SYNFUZZ first uses scalability [6, 9, 61]. More specifically, a concolic execution operation-aware taint analysis to record a partial expression (i.e., engine usually takes a very long time to explore “deep” a sketch) of its branch predicate. -

Parmesan: Sanitizer-Guided Greybox Fuzzing
ParmeSan: Sanitizer-guided Greybox Fuzzing Sebastian Österlund, Kaveh Razavi, Herbert Bos, and Cristiano Giuffrida, Vrije Universiteit Amsterdam https://www.usenix.org/conference/usenixsecurity20/presentation/osterlund This paper is included in the Proceedings of the 29th USENIX Security Symposium. August 12–14, 2020 978-1-939133-17-5 Open access to the Proceedings of the 29th USENIX Security Symposium is sponsored by USENIX. ParmeSan: Sanitizer-guided Greybox Fuzzing Sebastian Österlund Kaveh Razavi Herbert Bos Cristiano Giuffrida Vrije Universiteit Vrije Universiteit Vrije Universiteit Vrije Universiteit Amsterdam Amsterdam Amsterdam Amsterdam Abstract to address this problem by steering the program towards lo- cations that are more likely to be affected by bugs [20, 23] One of the key questions when fuzzing is where to look for (e.g., newly written or patched code, and API boundaries), vulnerabilities. Coverage-guided fuzzers indiscriminately but as a result, they underapproximate overall bug coverage. optimize for covering as much code as possible given that bug coverage often correlates with code coverage. Since We make a key observation that it is possible to detect code coverage overapproximates bug coverage, this ap- many bugs at runtime using knowledge from compiler san- proach is less than ideal and may lead to non-trivial time- itizers—error detection frameworks that insert checks for a to-exposure (TTE) of bugs. Directed fuzzers try to address wide range of possible bugs (e.g., out-of-bounds accesses or this problem by directing the fuzzer to a basic block with a integer overflows) in the target program. Existing fuzzers potential vulnerability. This approach can greatly reduce the often use sanitizers mainly to improve bug detection and TTE for a specific bug, but such special-purpose fuzzers can triaging [38]. -

Intelligen: Automatic Driver Synthesis for Fuzz Testing
IntelliGen: Automatic Driver Synthesis for Fuzz Testing Mingrui Zhang1, Jianzhong Liu2, Fuchen Ma1, Huafeng Zhang3, Yu Jiang*1 KLISS, BNRist, School of Software, Tsinghua Universiy1 ShanghaiTech University2 Huawei Technologies Co. Ltd, Beijing, China3 Abstract—Fuzzing is a technique widely used in vulnerability generate fuzz drivers semi-automatically. FUDGE constructs detection. The process usually involves writing effective fuzz fuzz drivers by scanning the program’s source code to find driver programs, which, when done manually, can be extremely vulnerable function calls and generates fuzz drivers using labor intensive. Previous attempts at automation leave much to be desired, in either degree of automation or quality of output. parameter replacement. It works well in specific scenarios In this paper, we propose IntelliGen, a framework that but tends to generate excessive fuzz drivers for large projects constructs valid fuzz drivers automatically. First, IntelliGen which require manual removal of invalid results. Furthermore, determines a set of entry functions and evaluates their respective it is infeasible to try all candidate drivers. Another example chance of exhibiting a vulnerability. Then, IntelliGen generates would be FuzzGen [14], which leverages a whole system anal- fuzz drivers for the entry functions through hierarchical param- eter replacement and type inference. We implemented IntelliGen ysis to infer the library’s interface and synthesize fuzz drivers and evaluated its effectiveness on real-world programs selected based on existing test cases accordingly. Its performance relies from the Android Open-Source Project, Google’s fuzzer-test- heavily upon the quality of existing test cases. suite and industrial collaborators. IntelliGen covered on average In production environments, we face two significant chal- 1.08×-2.03× more basic blocks and 1.36×-2.06× more paths over state-of-the-art fuzz driver synthesizers FUDGE and FuzzGen. -
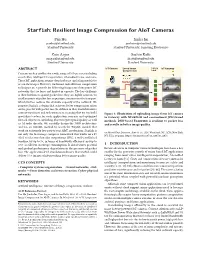
Starfish: Resilient Image Compression for Aiot Cameras
Starfish: Resilient Image Compression for AIoT Cameras Pan Hu Junha Im [email protected] [email protected] Stanford University Stanford University, Samsung Electronics Zain Asgar Sachin Katti [email protected] [email protected] Stanford University Stanford University IoT Camera Lossy Image Lossy IoT Gateway ABSTRACT Compression Link Cameras are key enablers for a wide range of IoT use cases including smart cities, intelligent transportation, AI-enabled farms, and more. These IoT applications require cloud software (including models) to Starfish act on the images. However, traditional task oblivious compression techniques are a poor fit for delivering images over low power IoT networks that are lossy and limited in capacity. The key challenge is their brittleness against packet loss; they are highly sensitive to small amounts of packet loss requiring retransmission for transport, which further reduces the available capacity of the network. We JPEG propose Starfish, a design that achieves better compression ratios and is graceful with packet loss. In addition to that, Starfish features content-awareness and task-awareness, meaning that we can build Figure 1: Illustration of uploading image from IoT camera specialized codecs for each application scenario and optimized to Gateway with Starfish and conventional JPEG-based for task objectives, including objective/perceptual quality as well methods. DNN-based Starfish is resilient to packet loss as AI tasks directly. We carefully design the DNN architecture and results in better image quality. and use an AutoML method to search for TinyML models that work on extremely low power/cost AIoT accelerators. Starfish is on Neural Gaze Detection, June 03–05, 2018, Woodstock, NY. -

Selecting Texture Resolution Using a Task-Specific Visibility Metric
Pacific Graphics 2019 Volume 38 (2019), Number 7 C. Theobalt, J. Lee, and G. Wetzstein (Guest Editors) Selecting texture resolution using a task-specific visibility metric K. Wolski1, D. Giunchi2, S. Kinuwaki, P. Didyk3, K. Myszkowski1 and A. Steed2, R. K. Mantiuk4 1Max Planck Institut für Informatik, Germany 2University College London, England 3UniversitÃa˘ della Svizzera italiana, Switzerland 3University of Cambridge, England Abstract In real-time rendering, the appearance of scenes is greatly affected by the quality and resolution of the textures used for image synthesis. At the same time, the size of textures determines the performance and the memory requirements of rendering. As a result, finding the optimal texture resolution is critical, but also a non-trivial task since the visibility of texture imperfections depends on underlying geometry, illumination, interactions between several texture maps, and viewing positions. Ideally, we would like to automate the task with a visibility metric, which could predict the optimal texture resolution. To maximize the performance of such a metric, it should be trained on a given task. This, however, requires sufficient user data which is often difficult to obtain. To address this problem, we develop a procedure for training an image visibility metric for a specific task while reducing the effort required to collect new data. The procedure involves generating a large dataset using an existing visibility metric followed by refining that dataset with the help of an efficient perceptual experiment. Then, such a refined dataset is used to retune the metric. This way, we augment sparse perceptual data to a large number of per-pixel annotated visibility maps which serve as the training data for application-specific visibility metrics. -

Pdf/Acyclic.1.Pdf
tldr pages Simplified and community-driven man pages Generated on Sun Sep 26 15:57:34 2021 Android am Android activity manager. More information: https://developer.android.com/studio/command-line/adb#am. • Start a specific activity: am start -n {{com.android.settings/.Settings}} • Start an activity and pass data to it: am start -a {{android.intent.action.VIEW}} -d {{tel:123}} • Start an activity matching a specific action and category: am start -a {{android.intent.action.MAIN}} -c {{android.intent.category.HOME}} • Convert an intent to a URI: am to-uri -a {{android.intent.action.VIEW}} -d {{tel:123}} bugreport Show an Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreport/. • Show a complete bug report of an Android device: bugreport bugreportz Generate a zipped Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreportz/. • Generate a complete zipped bug report of an Android device: bugreportz • Show the progress of a running bugreportz operation: bugreportz -p • Show the version of bugreportz: bugreportz -v • Display help: bugreportz -h cmd Android service manager. More information: https://cs.android.com/android/platform/superproject/+/ master:frameworks/native/cmds/cmd/. • List every running service: cmd -l • Call a specific service: cmd {{alarm}} • Call a service with arguments: cmd {{vibrator}} {{vibrate 300}} dalvikvm Android Java virtual machine. More information: https://source.android.com/devices/tech/dalvik. • Start a Java program: dalvikvm -classpath {{path/to/file.jar}} {{classname}} dumpsys Provide information about Android system services. -

Vol. 12 :: No. 1 :: Jan – Mar 2017
Vol. 12 :: No. 1 :: Jan – Mar 2017 Message from the Chairman Dear IEEE Members, At the outset, I express my sincere thanks to all the IEEE members in India for giving me the opportunity to serve them as the Chair of IEEE India Council in 2017. It is a great opportunity, but at the same time is a big responsibility. I would like to rise up to the expectations of the membership to the best of my ability. I also express my happiness to have a very strong and energetic team including office bearers and execom members to take forward to activities of IEEE IC in this year. Each of them is committed to the cause of IEEE and is geared up to give their best. My hearty thanks and appreciation to all of them for shouldering such responsibilities. The IC Newsletter is coming out in its new avatar through this first issue in 2017. As you may be aware that Mr. H.R.Mohan has once again taken up the challenging task of the Newsletter Editor (He was the editor during 2013). I convey my deep appreciation for the services extended by Mr. Mohan in coming up with a commendable version of the newsletter. I would also like to put on record that all the Sections extended their overwhelming cooperation in providing the inputs to the newsletter. I thank all the Section leaders for their support. The flagship program of IEEE IC, viz. INDICON 2017, will be held in IIT Roorkee in collaboration with IEEE UP Section. I hereby appeal to all IEEE members to make this INDICON another success story, as in the previous years.