Parmesan: Sanitizer-Guided Greybox Fuzzing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding Integer Overflow in C/C++
Appeared in Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, June 2012. Understanding Integer Overflow in C/C++ Will Dietz,∗ Peng Li,y John Regehr,y and Vikram Adve∗ ∗Department of Computer Science University of Illinois at Urbana-Champaign fwdietz2,[email protected] ySchool of Computing University of Utah fpeterlee,[email protected] Abstract—Integer overflow bugs in C and C++ programs Detecting integer overflows is relatively straightforward are difficult to track down and may lead to fatal errors or by using a modified compiler to insert runtime checks. exploitable vulnerabilities. Although a number of tools for However, reliable detection of overflow errors is surprisingly finding these bugs exist, the situation is complicated because not all overflows are bugs. Better tools need to be constructed— difficult because overflow behaviors are not always bugs. but a thorough understanding of the issues behind these errors The low-level nature of C and C++ means that bit- and does not yet exist. We developed IOC, a dynamic checking tool byte-level manipulation of objects is commonplace; the line for integer overflows, and used it to conduct the first detailed between mathematical and bit-level operations can often be empirical study of the prevalence and patterns of occurrence quite blurry. Wraparound behavior using unsigned integers of integer overflows in C and C++ code. Our results show that intentional uses of wraparound behaviors are more common is legal and well-defined, and there are code idioms that than is widely believed; for example, there are over 200 deliberately use it. -

“实时交互”的im技术,将会有什么新机遇? 2019-08-26 袁武林
ᭆʼn ᩪᭆŊ ᶾݐᩪᭆᔜߝ᧞ᑕݎ ғמஙے ᤒ 下载APPڜහਁʼn Ŋ ឴ݐռᓉݎ 开篇词 | 搞懂“实时交互”的IM技术,将会有什么新机遇? 2019-08-26 袁武林 即时消息技术剖析与实战 进入课程 讲述:袁武林 时长 13:14 大小 12.13M 你好,我是袁武林。我来自新浪微博,目前在微博主要负责消息箱和直播互动相关的业务。 接下来的一段时间,我会给你带来一个即时消息技术方面的专栏课程。 你可能会很好奇,为什么是来自微博的技术人来讲这个课程,微博会用到 IM 的技术吗? 在我回答之前,先请你思考一个问题: 除了 QQ 和微信,你知道还有什么 App 会用到即时(实时)消息技术吗? 其实,除了 QQ 和微信外,陌陌、抖音等直播业务为主的 App 也都深度用到了 IM 相关的 技术。 比如在线学习软件中的“实时在线白板”,导航打车软件中的“实时位置共享”,以及和我 们生活密切相关的智能家居的“远程控制”,也都会通过 IM 技术来提升人和人、人和物的 实时互动性。 我觉得可以这么理解:包括聊天、直播、在线客服、物联网等这些业务领域在内,所有需 要“实时互动”“高实时性”的场景,都需要、也应该用到 IM 技术。 微博因为其多重的业务需求,在许多业务中都应用到了 IM 技术,目前除了我负责的消息箱 和直播互动业务外,还有其他业务也逐渐来通过我们的 IM 通用服务,提升各自业务的用户 体验。 为什么这么多场景都用到了 IM 技术呢,IM 的技术究竟是什么呢? 所以,在正式开始讲解技术之前,我想先从应用场景的角度,带你了解一下 IM 技术是什 么,它为互联网带来了哪些巨大变革,以及自身蕴含着怎样的价值。 什么是 IM 系统? 我们不妨先看一段旧闻: 2014 年 Facebook 以 190 亿美元的价格,收购了当时火爆的即时通信工具 WhatsApp,而此时 WhatsApp 仅有 50 名员工。 是的,也就是说这 50 名员工人均创造了 3.8 亿美元的价值。这里,我们不去讨论当时谷歌 和 Facebook 为争抢 WhatsApp 发起的价格战,从而推动这笔交易水涨船高的合理性,从 另一个侧面我们看到的是:依托于 IM 技术的社交软件,在完成了“连接人与人”的使命 后,体现出的巨大价值。 同样的价值体现也发生在国内。1996 年,几名以色列大学生发明的即时聊天软件 ICQ 一 时间风靡全球,3 年后的深圳,它的效仿者在中国悄然出现,通过熟人关系的快速构建,在 一票基于陌生人关系的网络聊天室中脱颖而出,逐渐成为国内社交网络的巨头。 那时候这个聊天工具还叫 OICQ,后来更名为 QQ,说到这,大家应该知道我说的是哪家公 司了,没错,这家公司叫腾讯。在之后的数年里,腾讯正是通过不断优化升级 IM 相关的功 能和架构,凭借 QQ 和微信这两大 IM 工具,牢牢控制了强关系领域的社交圈。 ےۓ由此可见,IM 技术作为互联网实时互动场景的底层架构,在整个互动生态圈的价值所在。᧗ 随着互联网的发展,人们对于实时互动的要求越来越高。于是,IMᴠྊෙๅ 技术不止应用于 QQ、 微信这样的面向聊天的软件,它其实有着宽广的应用场景和足够有想象力的前景。甚至在不 。ғ 系统已经根植于我们的互联网生活中,成为各大 App 必不可少的模块מஙݎ知不觉之间,IMḒ 除了我在前面图中列出的业务之外,如果你希望在自己的 App 里加上实时聊天或者弹幕的 功能,通过 IM 云服务商提供的 SDK 就能快速实现(当然如果需求比较简单,你也可以自 己动手来实现)。 比如,在极客时间 App 中,我们可以加上一个支持大家点对点聊天的功能,或者增加针对 某一门课程的独立聊天室。 例子太多,我就不做一一列举了。其实我想说的是:IM -

Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation
applied sciences Article Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation Razvan Raducu * , Gonzalo Esteban , Francisco J. Rodríguez Lera and Camino Fernández Grupo de Robótica, Universidad de León. Avenida Jesuitas, s/n, 24007 León, Spain; [email protected] (G.E.); [email protected] (F.J.R.L.); [email protected] (C.F.) * Correspondence: [email protected] Received:29 December 2019; Accepted: 7 February 2020; Published: 13 February 2020 Abstract: Different Machine Learning techniques to detect software vulnerabilities have emerged in scientific and industrial scenarios. Different actors in these scenarios aim to develop algorithms for predicting security threats without requiring human intervention. However, these algorithms require data-driven engines based on the processing of huge amounts of data, known as datasets. This paper introduces the SonarCloud Vulnerable Code Prospector for C (SVCP4C). This tool aims to collect vulnerable source code from open source repositories linked to SonarCloud, an online tool that performs static analysis and tags the potentially vulnerable code. The tool provides a set of tagged files suitable for extracting features and creating training datasets for Machine Learning algorithms. This study presents a descriptive analysis of these files and overviews current status of C vulnerabilities, specifically buffer overflow, in the reviewed public repositories. Keywords: vulnerability; sonarcloud; bot; source code; repository; buffer overflow 1. Introduction In November 1988 the Internet suffered what is publicly known as “the first successful buffer overflow exploitation”. The exploit took advantage of the absence of buffer range-checking in one of the functions implemented in the fingerd daemon [1,2]. Even though it is considered to be the first exploited buffer overflow, different researchers had been working on buffer overflow for years. -

Seed Selection for Successful Fuzzing
Seed Selection for Successful Fuzzing Adrian Herrera Hendra Gunadi Shane Magrath ANU & DST ANU DST Australia Australia Australia Michael Norrish Mathias Payer Antony L. Hosking CSIRO’s Data61 & ANU EPFL ANU & CSIRO’s Data61 Australia Switzerland Australia ABSTRACT ACM Reference Format: Mutation-based greybox fuzzing—unquestionably the most widely- Adrian Herrera, Hendra Gunadi, Shane Magrath, Michael Norrish, Mathias Payer, and Antony L. Hosking. 2021. Seed Selection for Successful Fuzzing. used fuzzing technique—relies on a set of non-crashing seed inputs In Proceedings of the 30th ACM SIGSOFT International Symposium on Software (a corpus) to bootstrap the bug-finding process. When evaluating a Testing and Analysis (ISSTA ’21), July 11–17, 2021, Virtual, Denmark. ACM, fuzzer, common approaches for constructing this corpus include: New York, NY, USA, 14 pages. https://doi.org/10.1145/3460319.3464795 (i) using an empty file; (ii) using a single seed representative of the target’s input format; or (iii) collecting a large number of seeds (e.g., 1 INTRODUCTION by crawling the Internet). Little thought is given to how this seed Fuzzing is a dynamic analysis technique for finding bugs and vul- choice affects the fuzzing process, and there is no consensus on nerabilities in software, triggering crashes in a target program by which approach is best (or even if a best approach exists). subjecting it to a large number of (possibly malformed) inputs. To address this gap in knowledge, we systematically investigate Mutation-based fuzzing typically uses an initial set of valid seed and evaluate how seed selection affects a fuzzer’s ability to find bugs inputs from which to generate new seeds by random mutation. -

RICH: Automatically Protecting Against Integer-Based Vulnerabilities
RICH: Automatically Protecting Against Integer-Based Vulnerabilities David Brumley, Tzi-cker Chiueh, Robert Johnson [email protected], [email protected], [email protected] Huijia Lin, Dawn Song [email protected], [email protected] Abstract against integer-based attacks. Integer bugs appear because programmers do not antici- We present the design and implementation of RICH pate the semantics of C operations. The C99 standard [16] (Run-time Integer CHecking), a tool for efficiently detecting defines about a dozen rules governinghow integer types can integer-based attacks against C programs at run time. C be cast or promoted. The standard allows several common integer bugs, a popular avenue of attack and frequent pro- cases, such as many types of down-casting, to be compiler- gramming error [1–15], occur when a variable value goes implementation specific. In addition, the written rules are out of the range of the machine word used to materialize it, not accompanied by an unambiguous set of formal rules, e.g. when assigning a large 32-bit int to a 16-bit short. making it difficult for a programmer to verify that he un- We show that safe and unsafe integer operations in C can derstands C99 correctly. Integer bugs are not exclusive to be captured by well-known sub-typing theory. The RICH C. Similar languages such as C++, and even type-safe lan- compiler extension compiles C programs to object code that guages such as Java and OCaml, do not raise exceptions on monitors its own execution to detect integer-based attacks. -

Darwinian Code Optimisation
Darwinian Code Optimisation Michail Basios A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy of University College London. Department of Computer Science University College London January 18, 2019 2 I, Michail Basios, confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the work. Abstract Programming is laborious. A long-standing goal is to reduce this cost through automation. Genetic Improvement (GI) is a new direction for achieving this goal. It applies search to the task of program improvement. The research conducted in this thesis applies GI to program optimisation and to enable program optimisation. In particular, it focuses on automatic code optimisation for complex managed runtimes, such as Java and Ethereum Virtual Machines. We introduce the term Darwinian Data Structures (DDS) for the data structures of a program that share a common interface and enjoy multiple implementations. We call them Darwinian since we can subject their implementations to the survival of the fittest. We introduce ARTEMIS, a novel cloud-based multi-objective multi-language optimisation framework that automatically finds optimal, tuned data structures and rewrites the source code of applications accordingly to use them. ARTEMIS achieves substantial performance improvements for 44 diverse programs. ARTEMIS achieves 4:8%, 10:1%, 5:1% median improvement for runtime, memory and CPU usage. Even though GI has been applied succesfully to improve properties of programs running in different runtimes, GI has not been applied in Blockchains, such as Ethereum. -

Secure Coding Frameworks for the Development of Safe, Secure and Reliable Code
Building Cybersecurity from the Ground Up Secure Coding Frameworks For the Development of Safe, Secure and Reliable Code Tim Kertis October 2015 The 27 th Annual IEEE Software Technology Conference Copyright © 2015 Raytheon Company. All rights reserved. Customer Success Is Our Mission is a registered trademark of Raytheon Company. Who Am I? Tim Kertis, Software Engineer/Software Architect Chief Software Architect, Raytheon IIS, Indianapolis Master of Science, Computer & Information Science, Purdue Software Architecture Professional through the Software Engineering Institute (SEI), Carnegie-Mellon University (CMU) 30 years of diverse Software Engineering Experience Advocate for Secure Coding Frameworks (SCFs) Author of the JAVA Secure Coding Framework (JSCF) Inventor of Cybersecurity thru Lexical And Symbolic Proxy (CLaSP) technology (patent pending) Secure Coding Frameworks 10/22/2015 2 Top 5 Cybersecurity Concerns … 1 - Application According to the 2015 ISC(2) Vulnerabilities Global Information Security 2 - Malware Workforce Study (Paresh 3 - Configuration Mistakes Rathod) 4 - Mobile Devices 5 - Hackers Secure Coding Frameworks 10/22/2015 3 Worldwide Market Indicators 2014 … Number of Software Total Cost of Cyber Crime: Developers: $500B (McCafee) 18,000,000+ (www.infoq.com) Cost of Cyber Incidents: Number of Java Software Low $1.6M Developers: Average $12.7M 9,000,000+ (www.infoq.com) High $61.0M (Ponemon Institute) Software with Vulnerabilities: 96% (www.cenzic.com) Secure Coding Frameworks 10/22/2015 4 Research -
Microsoft / Vcpkg
Microsoft / vcpkg master vcpkg / ports / Create new file Find file History Fetching latest commit… .. abseil [abseil][aws-sdk-cpp][breakpad][chakracore][cimg][date][exiv2][libzip… Apr 13, 2018 ace Update to ACE 6.4.7 (#3059) Mar 19, 2018 alac-decoder [alac-decoder] Fix x64 Mar 7, 2018 alac [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 alembic [alembic] update to 1.7.7 Mar 25, 2018 allegro5 [many ports] Updates to latest Nov 30, 2017 anax [anax] Use vcpkg_from_github(). Add missing vcpkg_copy_pdbs() Sep 25, 2017 angle [angle] Add CMake package with modules. (#2223) Nov 20, 2017 antlr4 [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 apr-util vcpkg_configure_cmake (and _meson) now embed debug symbols within sta… Sep 9, 2017 apr [ports] Mark several ports as unbuildable on UWP Nov 26, 2017 arb [arb] prefer ninja Nov 26, 2017 args [args] Fix hash Feb 24, 2018 armadillo add armadillo (#2954) Mar 8, 2018 arrow Update downstream libraries to use modularized boost Dec 19, 2017 asio [asio] Avoid boost dependency by always specifying ASIO_STANDALONE Apr 6, 2018 asmjit [asmjit] init Jan 29, 2018 assimp [assimp] Fixup: add missing patchfile Dec 21, 2017 atk [glib][atk] Disable static builds, fix generation to happen outside t… Mar 5, 2018 atkmm [vcpkg-build-msbuild] Add option to use vcpkg's integration. Fixes #891… Mar 21, 2018 atlmfc [atlmfc] Add dummy port to detect atl presence in VS Apr 23, 2017 aubio [aubio] Fix missing required dependencies Mar 27, 2018 aurora Added aurora as independant portfile Jun 21, 2017 avro-c -

Integer Overflow
Lecture 05 – Integer overflow Stephen Checkoway University of Illinois at Chicago Unsafe functions in libc • strcpy • strcat • gets • scanf family (fscanf, sscanf, etc.) (rare) • printf family (more about these later) • memcpy (need to control two of the three parameters) • memmove (same as memcpy) Replacements • Not actually safe; doesn’t do what you think • strncpy • strncat • Available on Windows in C11 Annex K (the optional part of C11) • strcpy_s • strcat_s • BSD-derived, moderately widely available, including Linux kernel but not glibc • strlcpy • strlcat Buffer overflow vulnerability-finding strategy 1. Look for the use of unsafe functions 2. Trace attacker-controlled input to these functions Real-world examples from my own research • Voting machine: SeQuoia AVC Advantage • About a dozen uses of strcpy, most checked the length first • One did not. It appeared in infreQuently used code • Configuration file with fixed-width fields containing NUL-terminated strings, one of which was strcpy’d to the stack • Remote compromise of cars • Lots of strcpy of attacker-controlled Bluetooth data, first one examined was vulnerable • memcpy of attacker-controlled data from cellular modem Reminder: Think like an attacker • I skimmed some source code for a client/server protocol • The server code was full of trivial buffer overflows resulting from the attacker not following the protocol • I told the developer about the issue, but he wasn’t concerned because the client software he wrote wouldn’t send too much data • Most people don’t think like attackers. Three flavors of integer overflows 1. Truncation: Assigning larger types to smaller types int i = 0x12345678; short s = i; char c = i; Truncation example struct s { int main(int argc, char *argv[]) { unsigned short len; size_t len = strlen(argv[0]); char buf[]; }; struct s *p = malloc(len + 3); p->len = len; void foo(struct s *p) { strcpy(p->buf, argv[0]); char buffer[100]; if (p->len < sizeof buffer) foo(p); strcpy(buffer, p->buf); return 0; // Use buffer } } Three flavors of integer overflows 2. -
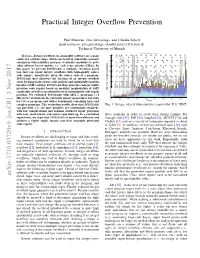
Practical Integer Overflow Prevention
Practical Integer Overflow Prevention Paul Muntean, Jens Grossklags, and Claudia Eckert {paul.muntean, jens.grossklags, claudia.eckert}@in.tum.de Technical University of Munich Memory error vulnerabilities categorized 160 Abstract—Integer overflows in commodity software are a main Other Format source for software bugs, which can result in exploitable memory Pointer 140 Integer Heap corruption vulnerabilities and may eventually contribute to pow- Stack erful software based exploits, i.e., code reuse attacks (CRAs). In 120 this paper, we present INTGUARD, a symbolic execution based tool that can repair integer overflows with high-quality source 100 code repairs. Specifically, given the source code of a program, 80 INTGUARD first discovers the location of an integer overflow error by using static source code analysis and satisfiability modulo 60 theories (SMT) solving. INTGUARD then generates integer multi- precision code repairs based on modular manipulation of SMT 40 Number of VulnerabilitiesNumber of constraints as well as an extensible set of customizable code repair 20 patterns. We evaluated INTGUARD with 2052 C programs (≈1 0 Mil. LOC) available in the currently largest open-source test suite 2000 2002 2004 2006 2008 2010 2012 2014 2016 for C/C++ programs and with a benchmark containing large and Year complex programs. The evaluation results show that INTGUARD Fig. 1: Integer related vulnerabilities reported by U.S. NIST. can precisely (i.e., no false positives are accidentally repaired), with low computational and runtime overhead repair programs with very small binary and source code blow-up. In a controlled flows statically in order to avoid them during runtime. For experiment, we show that INTGUARD is more time-effective and example, Sift [35], TAP [56], SoupInt [63], AIC/CIT [74], and achieves a higher repair success rate than manually generated CIntFix [11] rely on a variety of techniques depicted in detail code repairs. -

Ada for the C++ Or Java Developer
Quentin Ochem Ada for the C++ or Java Developer Release 1.0 Courtesy of July 23, 2013 This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 3.0 Unported License. CONTENTS 1 Preface 1 2 Basics 3 3 Compilation Unit Structure 5 4 Statements, Declarations, and Control Structures 7 4.1 Statements and Declarations ....................................... 7 4.2 Conditions ................................................ 9 4.3 Loops ................................................... 10 5 Type System 13 5.1 Strong Typing .............................................. 13 5.2 Language-Defined Types ......................................... 14 5.3 Application-Defined Types ........................................ 14 5.4 Type Ranges ............................................... 16 5.5 Generalized Type Contracts: Subtype Predicates ............................ 17 5.6 Attributes ................................................. 17 5.7 Arrays and Strings ............................................ 18 5.8 Heterogeneous Data Structures ..................................... 21 5.9 Pointers .................................................. 22 6 Functions and Procedures 25 6.1 General Form ............................................... 25 6.2 Overloading ............................................... 26 6.3 Subprogram Contracts .......................................... 27 7 Packages 29 7.1 Declaration Protection .......................................... 29 7.2 Hierarchical Packages ......................................... -

Security Analysis Methods on Ethereum Smart Contract Vulnerabilities — a Survey
1 Security Analysis Methods on Ethereum Smart Contract Vulnerabilities — A Survey Purathani Praitheeshan?, Lei Pan?, Jiangshan Yuy, Joseph Liuy, and Robin Doss? Abstract—Smart contracts are software programs featuring user [4]. In consequence of these issues of the traditional both traditional applications and distributed data storage on financial systems, the technology advances in peer to peer blockchains. Ethereum is a prominent blockchain platform with network and decentralized data management were headed up the support of smart contracts. The smart contracts act as autonomous agents in critical decentralized applications and as the way of mitigation. In recent years, the blockchain hold a significant amount of cryptocurrency to perform trusted technology is being the prominent mechanism which uses transactions and agreements. Millions of dollars as part of the distributed ledger technology (DLT) to implement digitalized assets held by the smart contracts were stolen or frozen through and decentralized public ledger to keep all cryptocurrency the notorious attacks just between 2016 and 2018, such as the transactions [1], [5], [6], [7], [8]. Blockchain is a public DAO attack, Parity Multi-Sig Wallet attack, and the integer underflow/overflow attacks. These attacks were caused by a electronic ledger equivalent to a distributed database. It can combination of technical flaws in designing and implementing be openly shared among the disparate users to create an software codes. However, many more vulnerabilities of less sever- immutable record of their transactions [7], [9], [10], [11], ity are to be discovered because of the scripting natures of the [12], [13]. Since all the committed records and transactions Solidity language and the non-updateable feature of blockchains.