1 What Is Efficiency? 2 Optimizing Matlab Code
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding Integer Overflow in C/C++
Appeared in Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, June 2012. Understanding Integer Overflow in C/C++ Will Dietz,∗ Peng Li,y John Regehr,y and Vikram Adve∗ ∗Department of Computer Science University of Illinois at Urbana-Champaign fwdietz2,[email protected] ySchool of Computing University of Utah fpeterlee,[email protected] Abstract—Integer overflow bugs in C and C++ programs Detecting integer overflows is relatively straightforward are difficult to track down and may lead to fatal errors or by using a modified compiler to insert runtime checks. exploitable vulnerabilities. Although a number of tools for However, reliable detection of overflow errors is surprisingly finding these bugs exist, the situation is complicated because not all overflows are bugs. Better tools need to be constructed— difficult because overflow behaviors are not always bugs. but a thorough understanding of the issues behind these errors The low-level nature of C and C++ means that bit- and does not yet exist. We developed IOC, a dynamic checking tool byte-level manipulation of objects is commonplace; the line for integer overflows, and used it to conduct the first detailed between mathematical and bit-level operations can often be empirical study of the prevalence and patterns of occurrence quite blurry. Wraparound behavior using unsigned integers of integer overflows in C and C++ code. Our results show that intentional uses of wraparound behaviors are more common is legal and well-defined, and there are code idioms that than is widely believed; for example, there are over 200 deliberately use it. -

Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation
applied sciences Article Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation Razvan Raducu * , Gonzalo Esteban , Francisco J. Rodríguez Lera and Camino Fernández Grupo de Robótica, Universidad de León. Avenida Jesuitas, s/n, 24007 León, Spain; [email protected] (G.E.); [email protected] (F.J.R.L.); [email protected] (C.F.) * Correspondence: [email protected] Received:29 December 2019; Accepted: 7 February 2020; Published: 13 February 2020 Abstract: Different Machine Learning techniques to detect software vulnerabilities have emerged in scientific and industrial scenarios. Different actors in these scenarios aim to develop algorithms for predicting security threats without requiring human intervention. However, these algorithms require data-driven engines based on the processing of huge amounts of data, known as datasets. This paper introduces the SonarCloud Vulnerable Code Prospector for C (SVCP4C). This tool aims to collect vulnerable source code from open source repositories linked to SonarCloud, an online tool that performs static analysis and tags the potentially vulnerable code. The tool provides a set of tagged files suitable for extracting features and creating training datasets for Machine Learning algorithms. This study presents a descriptive analysis of these files and overviews current status of C vulnerabilities, specifically buffer overflow, in the reviewed public repositories. Keywords: vulnerability; sonarcloud; bot; source code; repository; buffer overflow 1. Introduction In November 1988 the Internet suffered what is publicly known as “the first successful buffer overflow exploitation”. The exploit took advantage of the absence of buffer range-checking in one of the functions implemented in the fingerd daemon [1,2]. Even though it is considered to be the first exploited buffer overflow, different researchers had been working on buffer overflow for years. -

RICH: Automatically Protecting Against Integer-Based Vulnerabilities
RICH: Automatically Protecting Against Integer-Based Vulnerabilities David Brumley, Tzi-cker Chiueh, Robert Johnson [email protected], [email protected], [email protected] Huijia Lin, Dawn Song [email protected], [email protected] Abstract against integer-based attacks. Integer bugs appear because programmers do not antici- We present the design and implementation of RICH pate the semantics of C operations. The C99 standard [16] (Run-time Integer CHecking), a tool for efficiently detecting defines about a dozen rules governinghow integer types can integer-based attacks against C programs at run time. C be cast or promoted. The standard allows several common integer bugs, a popular avenue of attack and frequent pro- cases, such as many types of down-casting, to be compiler- gramming error [1–15], occur when a variable value goes implementation specific. In addition, the written rules are out of the range of the machine word used to materialize it, not accompanied by an unambiguous set of formal rules, e.g. when assigning a large 32-bit int to a 16-bit short. making it difficult for a programmer to verify that he un- We show that safe and unsafe integer operations in C can derstands C99 correctly. Integer bugs are not exclusive to be captured by well-known sub-typing theory. The RICH C. Similar languages such as C++, and even type-safe lan- compiler extension compiles C programs to object code that guages such as Java and OCaml, do not raise exceptions on monitors its own execution to detect integer-based attacks. -

Secure Coding Frameworks for the Development of Safe, Secure and Reliable Code
Building Cybersecurity from the Ground Up Secure Coding Frameworks For the Development of Safe, Secure and Reliable Code Tim Kertis October 2015 The 27 th Annual IEEE Software Technology Conference Copyright © 2015 Raytheon Company. All rights reserved. Customer Success Is Our Mission is a registered trademark of Raytheon Company. Who Am I? Tim Kertis, Software Engineer/Software Architect Chief Software Architect, Raytheon IIS, Indianapolis Master of Science, Computer & Information Science, Purdue Software Architecture Professional through the Software Engineering Institute (SEI), Carnegie-Mellon University (CMU) 30 years of diverse Software Engineering Experience Advocate for Secure Coding Frameworks (SCFs) Author of the JAVA Secure Coding Framework (JSCF) Inventor of Cybersecurity thru Lexical And Symbolic Proxy (CLaSP) technology (patent pending) Secure Coding Frameworks 10/22/2015 2 Top 5 Cybersecurity Concerns … 1 - Application According to the 2015 ISC(2) Vulnerabilities Global Information Security 2 - Malware Workforce Study (Paresh 3 - Configuration Mistakes Rathod) 4 - Mobile Devices 5 - Hackers Secure Coding Frameworks 10/22/2015 3 Worldwide Market Indicators 2014 … Number of Software Total Cost of Cyber Crime: Developers: $500B (McCafee) 18,000,000+ (www.infoq.com) Cost of Cyber Incidents: Number of Java Software Low $1.6M Developers: Average $12.7M 9,000,000+ (www.infoq.com) High $61.0M (Ponemon Institute) Software with Vulnerabilities: 96% (www.cenzic.com) Secure Coding Frameworks 10/22/2015 4 Research -

Integer Overflow
Lecture 05 – Integer overflow Stephen Checkoway University of Illinois at Chicago Unsafe functions in libc • strcpy • strcat • gets • scanf family (fscanf, sscanf, etc.) (rare) • printf family (more about these later) • memcpy (need to control two of the three parameters) • memmove (same as memcpy) Replacements • Not actually safe; doesn’t do what you think • strncpy • strncat • Available on Windows in C11 Annex K (the optional part of C11) • strcpy_s • strcat_s • BSD-derived, moderately widely available, including Linux kernel but not glibc • strlcpy • strlcat Buffer overflow vulnerability-finding strategy 1. Look for the use of unsafe functions 2. Trace attacker-controlled input to these functions Real-world examples from my own research • Voting machine: SeQuoia AVC Advantage • About a dozen uses of strcpy, most checked the length first • One did not. It appeared in infreQuently used code • Configuration file with fixed-width fields containing NUL-terminated strings, one of which was strcpy’d to the stack • Remote compromise of cars • Lots of strcpy of attacker-controlled Bluetooth data, first one examined was vulnerable • memcpy of attacker-controlled data from cellular modem Reminder: Think like an attacker • I skimmed some source code for a client/server protocol • The server code was full of trivial buffer overflows resulting from the attacker not following the protocol • I told the developer about the issue, but he wasn’t concerned because the client software he wrote wouldn’t send too much data • Most people don’t think like attackers. Three flavors of integer overflows 1. Truncation: Assigning larger types to smaller types int i = 0x12345678; short s = i; char c = i; Truncation example struct s { int main(int argc, char *argv[]) { unsigned short len; size_t len = strlen(argv[0]); char buf[]; }; struct s *p = malloc(len + 3); p->len = len; void foo(struct s *p) { strcpy(p->buf, argv[0]); char buffer[100]; if (p->len < sizeof buffer) foo(p); strcpy(buffer, p->buf); return 0; // Use buffer } } Three flavors of integer overflows 2. -
Practical Integer Overflow Prevention
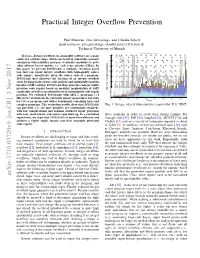
Practical Integer Overflow Prevention Paul Muntean, Jens Grossklags, and Claudia Eckert {paul.muntean, jens.grossklags, claudia.eckert}@in.tum.de Technical University of Munich Memory error vulnerabilities categorized 160 Abstract—Integer overflows in commodity software are a main Other Format source for software bugs, which can result in exploitable memory Pointer 140 Integer Heap corruption vulnerabilities and may eventually contribute to pow- Stack erful software based exploits, i.e., code reuse attacks (CRAs). In 120 this paper, we present INTGUARD, a symbolic execution based tool that can repair integer overflows with high-quality source 100 code repairs. Specifically, given the source code of a program, 80 INTGUARD first discovers the location of an integer overflow error by using static source code analysis and satisfiability modulo 60 theories (SMT) solving. INTGUARD then generates integer multi- precision code repairs based on modular manipulation of SMT 40 Number of VulnerabilitiesNumber of constraints as well as an extensible set of customizable code repair 20 patterns. We evaluated INTGUARD with 2052 C programs (≈1 0 Mil. LOC) available in the currently largest open-source test suite 2000 2002 2004 2006 2008 2010 2012 2014 2016 for C/C++ programs and with a benchmark containing large and Year complex programs. The evaluation results show that INTGUARD Fig. 1: Integer related vulnerabilities reported by U.S. NIST. can precisely (i.e., no false positives are accidentally repaired), with low computational and runtime overhead repair programs with very small binary and source code blow-up. In a controlled flows statically in order to avoid them during runtime. For experiment, we show that INTGUARD is more time-effective and example, Sift [35], TAP [56], SoupInt [63], AIC/CIT [74], and achieves a higher repair success rate than manually generated CIntFix [11] rely on a variety of techniques depicted in detail code repairs. -

Ada for the C++ Or Java Developer
Quentin Ochem Ada for the C++ or Java Developer Release 1.0 Courtesy of July 23, 2013 This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 3.0 Unported License. CONTENTS 1 Preface 1 2 Basics 3 3 Compilation Unit Structure 5 4 Statements, Declarations, and Control Structures 7 4.1 Statements and Declarations ....................................... 7 4.2 Conditions ................................................ 9 4.3 Loops ................................................... 10 5 Type System 13 5.1 Strong Typing .............................................. 13 5.2 Language-Defined Types ......................................... 14 5.3 Application-Defined Types ........................................ 14 5.4 Type Ranges ............................................... 16 5.5 Generalized Type Contracts: Subtype Predicates ............................ 17 5.6 Attributes ................................................. 17 5.7 Arrays and Strings ............................................ 18 5.8 Heterogeneous Data Structures ..................................... 21 5.9 Pointers .................................................. 22 6 Functions and Procedures 25 6.1 General Form ............................................... 25 6.2 Overloading ............................................... 26 6.3 Subprogram Contracts .......................................... 27 7 Packages 29 7.1 Declaration Protection .......................................... 29 7.2 Hierarchical Packages ......................................... -

Security Analysis Methods on Ethereum Smart Contract Vulnerabilities — a Survey
1 Security Analysis Methods on Ethereum Smart Contract Vulnerabilities — A Survey Purathani Praitheeshan?, Lei Pan?, Jiangshan Yuy, Joseph Liuy, and Robin Doss? Abstract—Smart contracts are software programs featuring user [4]. In consequence of these issues of the traditional both traditional applications and distributed data storage on financial systems, the technology advances in peer to peer blockchains. Ethereum is a prominent blockchain platform with network and decentralized data management were headed up the support of smart contracts. The smart contracts act as autonomous agents in critical decentralized applications and as the way of mitigation. In recent years, the blockchain hold a significant amount of cryptocurrency to perform trusted technology is being the prominent mechanism which uses transactions and agreements. Millions of dollars as part of the distributed ledger technology (DLT) to implement digitalized assets held by the smart contracts were stolen or frozen through and decentralized public ledger to keep all cryptocurrency the notorious attacks just between 2016 and 2018, such as the transactions [1], [5], [6], [7], [8]. Blockchain is a public DAO attack, Parity Multi-Sig Wallet attack, and the integer underflow/overflow attacks. These attacks were caused by a electronic ledger equivalent to a distributed database. It can combination of technical flaws in designing and implementing be openly shared among the disparate users to create an software codes. However, many more vulnerabilities of less sever- immutable record of their transactions [7], [9], [10], [11], ity are to be discovered because of the scripting natures of the [12], [13]. Since all the committed records and transactions Solidity language and the non-updateable feature of blockchains. -

Security Coding Module Integer Error – “You Can’T Count That High” – CS1
Security Coding Module Integer Error – “You Can’t Count That High” – CS1 Summary: Integer values that are too large or too small may fall outside the allowable range for their data type, leading to undefined behavior that can both reduce the robustness of your code and lead to security vulnerabilities. Description: Declaring a variable as type int allocates a fixed amount of space in memory. Most languages include several integer types, including short, int, long, etc. , to allow for less or more storage. The amount of space allocated limits the range of values that can be stored. For example, a 32-bit int variable can hold values from -231 through 231-1. Input or mathematical operations such as addition, subtraction, and multiplication may lead to values that are outside of this range. This results in an integer error or overflow, which causes undefined behavior and the resulting value will likely not be what the programmer intended. Integer overflow is a common cause of software errors and vulnerabilities. Risk – How Can It Happen? An integer error can lead to unexpected behavior or may be exploited to cause a program crash, corrupt data, or allow the execution of malicious software. Example of Occurrence: 1. There is a Facebook group called “If this group reaches 4,294,967,296 it might cause an integer overflow.” This value is the largest number that can fit in a 32 bit unsigned integer. If the number of members of the group exceeded this number, it might cause an overflow. Whether it will cause an overflow or not depends upon how Facebook is implemented and which language is used – they might use data types that can hold larger numbers. -

Teaching Security Stealthily
Education Editors: Matt Bishop, [email protected] Cynthia Irvine, [email protected] Teaching Security Stealthily Matt Bishop University of California, Davis Many people and institutions are considering how to make students who aren’t taking computer security classes aware of the issues and make them think about how to improve the state of software and systems. Elementary programming classes teach problem-solving skills as well as programming-language syntax and semantics. Database classes focus on the theory and practice of storing, viewing, and extracting data. Algorithm classes emphasize algorithm design and analysis. Their teaching objectives might not even mention security. A class’s topic constrains its content, and any information or practice of security is strictly incidental to the students’ understanding and internalization of the material relevant to the topic. However, information assurance and computer security are cross-disciplinary topics. They arise in all computer science disciplines. Thus, their material can and should be integrated into existing classes—but doing so presents a conundrum. Already, computer science classes’ curriculum covers more material than can be comfortably taught in each class. So, rather than remove material about the class’s primary topic, classes can introduce security-related concepts in homework exercises, thereby emphasizing those concepts in the context of that topic. Here, I present four exercises: one from a class introducing nonmajors to computers and programming, and three from a beginning programming class for majors. We focus on introductory classes because they form the basis for students’ computing experiences. Introducing concepts of information assurance and computer security early makes the students more aware of these issues. -

CSE 127 Computer Security Stefan Savage, Spring 2019, Lecture 5
CSE 127 Computer Security Stefan Savage, Spring 2019, Lecture 5 Low Level Software Security III: Integers, ROP, & CFI Goals for today ▪ Understand how integers work – And that they are incredibly dangerous ▪ Why stopping malicious code injection doesn’t stop malicious code from being executed – Code-reuse attacks/Return-oriented programming ▪ Understand the promise of general “control flow integrity” (CFI) defenses (not sure we’ll get to this today) Integer Arithmetic in C ▪ Quiz time! a = 100; b = 200; ▪ What does this code produce? c = a+b; – 100 200 300 printf("%d %d %d\n", – 100 200 44 (int)a, – 100 -56 44 (int)b, (int)c); ▪ Depends on how a, b, and c are defined Integer Overflow/Underflow ▪ C defines fixed-width integer types (short, int, long, etc.) that do not always behave like Platonic integers from elementary school. ▪ Because of the fixed width, it is possible to overflow or wrap maximum expressible number for the type used – Or underflow in case of negative numbers What if: len1 == 0xFFFFFFFE Classic overflow example len2 == 0x000000102 void *ConcatBytes(void *buf1, unsigned int len1, char *buf2, unsigned int len2) { void *buf = malloc(len1 + len2); if (buf == NULL) return; 0x100 bytes allocated… not enough. Ooops. memcpy(buf, buf1, len1); memcpy(buf + len1, buf2, len2); } Integer Overflow/Underflow ▪ When a value of an unsigned integer type overflows (or underflows), it simply wraps. – As if arithmetic operation was performed modulo 2(size of the type). ▪ Overflow (and underflow) of signed integer types is undefined in C. -

Control Hijacking Attacks
Control Hijacking Attacks Note: project 1 is out Section this Friday 3:15pm (Gates B01) Control hijacking attacks ! Attacker’s goal: n" Take over target machine (e.g. web server) w"Execute arbitrary code on target by hijacking application control flow ! This lecture: three examples. n" Buffer overflow attacks n" Integer overflow attacks n" Format string vulnerabilities ! Project 1: Build exploits 1. Buffer overflows ! Extremely common bug. n" First major exploit: 1988 Internet Worm. fingerd. 600 ≈"20% of all vuln. 500 400 2005-2007: ≈ 10% 300 200 100 0 Source: NVD/CVE 1995 1997 1999 2001 2003 2005 ! Developing buffer overflow attacks: n" Locate buffer overflow within an application. n" Design an exploit. What is needed ! Understanding C functions and the stack ! Some familiarity with machine code ! Know how systems calls are made ! The exec() system call ! Attacker needs to know which CPU and OS are running on the target machine: n" Our examples are for x86 running Linux n" Details vary slightly between CPUs and OSs: w"Little endian vs. big endian (x86 vs. Motorola) w"Stack Frame structure (Unix vs. Windows) w"Stack growth direction Linux process memory layout 0xC0000000 user stack %esp shared libraries 0x40000000 brk run time heap Loaded from exec 0x08048000 unused 0 Stack Frame Parameters Return address Stack Frame Pointer Local variables Stack Growth SP What are buffer overflows? ! Suppose a web server contains a function: void func(char *str) { char buf[128]; strcpy(buf, str); do-something(buf); } ! When the function is invoked the stack looks like: top buf sfp ret-addr str of stack ! What if *str is 136 bytes long? After strcpy: top *str ret str of stack Basic stack exploit ! Problem: no range checking in strcpy().