Conditional Self-Attention for Query-Based Summarization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pure Magazine
PURE MAGAZINOctobeEr 2017 Jack O’Rourke Talks Music, Electric Picnic, Father John Misty and more… The Evolution Of A Modern Gentleman Jimmy Star chats with Hollywood actor... Sean Kanan Sony’s VR capabilities establishes them as serious contenders in the Virtual Reality headset war! Eli Lieb Talks Music, Creating & Happiness… Featured Artist Dionne Warwick Marilyn Manson Cheap Trick Otherkin Eileen Shapiro chats with award winning artist Emma Langford about her Debut + much more EalbumM, tour neMws plus mAore - T urLn to pAage 16 >N> GFORD @PureMzine Pure M Magazine ISSUE 22 Mesmerising WWW.PUREMZINE.COM forty seven Editor in Chief Trevor Padraig [email protected] and a half Editorial Paddy Dunne [email protected] minutes... Sarah Swinburne [email protected] Shane O’ Rielly [email protected] Marilyn Manson Heaven Upside Down Contributors Dave Simpson Eileen Shapiro Jimmy Star Garrett Browne lt-rock icon Marilyn Manson is back “Say10” showcases a captivatingly creepy Danielle Holian brandishing a brand new album coalescence of hauntingly hushed verses and Simone Smith entitled Heaven Upside Down. fantastically fierce choruses next as it Irvin Gamede ATackling themes such as sex, romance, saunters unsettlingly towards the violence and politics, the highly-anticipated comparatively cool and catchy “Kill4Me”. Front Cover - Ken Coleman sequel to 2015’s The Pale Emperor features This is succeeded by the seductively ten typically tumultuous tracks for fans to psychedelic “Saturnalia”, the dreamy yet www.artofkencoleman.com feast upon. energetic delivery of which ensures it stays It’s introduced through the sinister static entrancing until “Je$u$ Cri$i$” arrives to of “Revelation #12” before a brilliantly rivet with its raucous refrain and rebellious bracing riff begins to blare out beneath a instrumentation. -

Visual Metaphors on Album Covers: an Analysis Into Graphic Design's
Visual Metaphors on Album Covers: An Analysis into Graphic Design’s Effectiveness at Conveying Music Genres by Vivian Le A THESIS submitted to Oregon State University Honors College in partial fulfillment of the requirements for the degree of Honors Baccalaureate of Science in Accounting and Business Information Systems (Honors Scholar) Presented May 29, 2020 Commencement June 2020 AN ABSTRACT OF THE THESIS OF Vivian Le for the degree of Honors Baccalaureate of Science in Accounting and Business Information Systems presented on May 29, 2020. Title: Visual Metaphors on Album Covers: An Analysis into Graphic Design’s Effectiveness at Conveying Music Genres. Abstract approved:_____________________________________________________ Ryann Reynolds-McIlnay The rise of digital streaming has largely impacted the way the average listener consumes music. Consequentially, while the role of album art has evolved to meet the changes in music technology, it is hard to measure the effect of digital streaming on modern album art. This research seeks to determine whether or not graphic design still plays a role in marketing information about the music, such as its genre, to the consumer. It does so through two studies: 1. A computer visual analysis that measures color dominance of an image, and 2. A mixed-design lab experiment with volunteer participants who attempt to assess the genre of a given album. Findings from the first study show that color scheme models created from album samples cannot be used to predict the genre of an album. Further findings from the second theory show that consumers pay a significant amount of attention to album covers, enough to be able to correctly assess the genre of an album most of the time. -
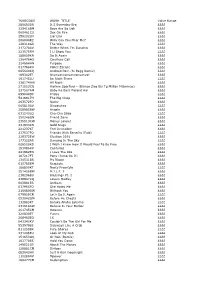
TUNECODE WORK TITLE Value Range 289693DR
TUNECODE WORK_TITLE Value Range 289693DR It S Everyday Bro ££££ 329418BM Boys Are So Ugh ££££ 060461CU Sex On Fire ££££ 258202LN Liar Liar ££££ 2680048Z Willy Can You Hear Me? ££££ 128318GR The Way ££££ 217278AV Better When I'm Dancing ££££ 223575FM I Ll Show You ££££ 188659KN Do It Again ££££ 136476HS Courtesy Call ££££ 224684HN Purpose ££££ 017788KU Police Escape ££££ 065640KQ Android Porn (Si Begg Remix) ££££ 189362ET Nyanyanyanyanyanyanya! ££££ 191745LU Be Right There ££££ 236174HW All Night ££££ 271523CQ Harlem Spartans - (Blanco Zico Bis Tg Millian Mizormac) ££££ 237567AM Baby Ko Bass Pasand Hai ££££ 099044DP Friday ££££ 5416917H The Big Chop ££££ 263572FQ Nasty ££££ 065810AV Dispatches ££££ 258985BW Angels ££££ 031243LQ Cha-Cha Slide ££££ 250248GN Friend Zone ££££ 235513CW Money Longer ££££ 231933KN Gold Slugs ££££ 221237KT Feel Invincible ££££ 237537FQ Friends With Benefits (Fwb) ££££ 228372EW Election 2016 ££££ 177322AR Dancing In The Sky ££££ 006520KS I Wish I Knew How It Would Feel To Be Free ££££ 153086KV Centuries ££££ 241982EN I Love The 90s ££££ 187217FT Pony (Jump On It) ££££ 134531BS My Nigga ££££ 015785EM Regulate ££££ 186800KT Nasty Freestyle ££££ 251426BW M.I.L.F. $ ££££ 238296BU Blessings Pt. 1 ££££ 238847KQ Lovers Medley ££££ 003981ER Anthem ££££ 037965FQ She Hates Me ££££ 216680GW Without You ££££ 079929CR Let's Do It Again ££££ 052042GM Before He Cheats ££££ 132883KT Baraka Allahu Lakuma ££££ 231618AW Believe In Your Barber ££££ 261745CM Ooouuu ££££ 220830ET Funny ££££ 268463EQ 16 ££££ 043343KV Couldn't Be The Girl -

Bcsfazine #536 | Felicity Walker
The Newsletter of the British Columbia Science Fiction Association #536 $3.00/Issue January 2018 In This Issue: This and Next Month in BCSFA..........................................0 About BCSFA.......................................................................0 Letters of Comment............................................................1 Calendar...............................................................................3 News-Like Matter................................................................8 Herbie (Taral Wayne).........................................................17 Art Credits..........................................................................18 BCSFAzine © January 2018, Volume 46, #1, Issue #536 is the monthly club news- letter published by the British Columbia Science Fiction Association, a social organ- ization. ISSN 1490-6406. Please send comments, suggestions, and/or submissions to Felicity Walker (the editor), at felicity4711@ gmail .com or Apartment 601, Manhattan Tower, 6611 Coo- ney Road, Richmond, BC, Canada, V6Y 4C5 (new address). BCSFAzine is distributed monthly at White Dwarf Books, 3715 West 10th Aven- ue, Vancouver, BC, V6R 2G5; telephone 604-228-8223; e-mail whitedwarf@ deadwrite.com. Single copies C$3.00/US$2.00 each. Cheques should be made pay- able to “West Coast Science Fiction Association (WCSFA).” This and Next Month in BCSFA Friday 19 January 2018: Submission deadline for February BCSFAzine (ideally). Sunday 21 January 2018 at 6 PM: January BCSFA meeting—at ABC Country Res- taurant, -

Leggi. Milano. Domani. Distribuzione Gra Tuita N
A PAGINA 5 Da Maciachini a NYC A PAGINA 12 Il coworking fai da te A PAGINA 15 Ogni dolce, un cocktail il crack di Brian Pallas scopriamo Make Milano l'idea dello chef Moschella Per le tue segnalazioni sulla nostra Milano 331.95.25.828 MITOMORROW.IT MITOMORROW.IT LUNEDÌ 18 GIUGNO 2018 LUNEDÌ ❱ ANNO 5 ❱ N. 109 DISTRIBUZIONE GRATUITA ❱ A due anni, domani, dal ballottaggio tra Sala e Parisi, DOMANI. il voto al primo cittadino da parte di un suo illustre predecessore. Albertini: «Per ora MILANO. è promosso, ma...» da pagina 10 LEGGI. cambiamilano Dal prossimo autunno Comune e Amsa avvieranno lo strumento del “Contatore Ambientale” per valutare i benefici della gestione dei rifiuti NAVIGLI RIAPERTI? OK DAGLI ARTIGIANI La differenziata che fa bene Il focus di vetro, alluminio, acciaio, carta, carto- saranno stati potenziati i servizi di rac- Piero Cressoni ne, legno e plastica vengono riciclati ri- colta differenziata nella zona ovest di ecuperare i Na- utilizzati e dunque quante e quali mate- Milano, estendendo a tutte le utenze vigli è un'ottima uanto vale la raccolta dif- rie prime vergini vengono risparmiate. I domestiche il servizio porta a porta del idea, soprattutto ferenziata a Milano? Dal dati, disponibili sul portale Open Data, cartone e riducendo la frequenza di riti- «Rse nel progetto prossimo autunno sul sito saranno facilmente consultabili sul sito ro del rifiuto indifferenziato. Il sistema, di fondo si riscoprono eccellenze Q del Comune sarà possibile istituzionale comune.milano.it. attivo nel 50% delle utenze milanesi, e tradizioni e si coglie l'occasione conoscere esattamente quali e quanti raggiungerà tutta la città entro il 2019. -

The Broadsheet
May 2018 Issue XXIV THE BROADSHEET Seniors pose with inductees to Sigma Tau Delta Fifth Annual English Awards Ceremony This Issue: Celebrates Shared Scholarship, Award-Winning Verse, and Seniors Preparing for Graduation Poetry, Sanity, and By The Broadsheet Staff the Fifth Annual English Award Approximately fifty faculty, staff, students and family attended the fifth Ceremony annual English Awards Ceremony held on April 12 at 4 pm at the Merrimack College Writers House. The event consisted of a robust agenda, which Guest Speaker Tanya included the induction of eight new members into the Sigma Tau Delta Larkin Guides International Honor Society, the distribution of graduation cords to nine Majors along an seniors, a slide show from four of the five English majors who presented Important Path original scholarly and creative works at this year’s Sigma Tau Delta annual Sigma Tau Delta convention, the awarding of cash prizes to the three place winners in the Rev. John R. Aherne 2018 Poetry Contest, and a reading by poet Tanya Larkin, Conference 2018 Tufts University Lecturer in Creative Writing and author of two collections of original poetry, My Scarlet Ways, winner of the 2011 Saturnalia prize, and The Cryptic Manson Hothouse Orphan. of Heaven Upside Down The program also included readings by Aherne Poetry contest winners Bridget Kennedy (“Where I’m From,” first place), Dan Roussel (“Things Creating a Life in the I’ve Never Done,” second place), and Dakota Durbin (“Deer” and “Lucy Automated Future: Brook,” which tied for third place in the contest voting). In addition to her Mark Cuban on the reading, Larkin shared her thoughts about why poetry remains crucial to Liberal Arts emotional wellbeing. -

“I Am Your Faggot Anti-Pope”: an Exploration of Marilyn Manson As a Transgressive Artist
European journal of American studies 12-2 | 2017 Summer 2017, including Special Issue: Popularizing Politics: The 2016 U.S. Presidential Election “I Am Your Faggot Anti-Pope”: An Exploration of Marilyn Manson as a Transgressive Artist Coco d’Hont Electronic version URL: http://journals.openedition.org/ejas/12098 DOI: 10.4000/ejas.12098 ISSN: 1991-9336 Publisher European Association for American Studies Electronic reference Coco d’Hont, « “I Am Your Faggot Anti-Pope”: An Exploration of Marilyn Manson as a Transgressive Artist », European journal of American studies [Online], 12-2 | 2017, document 14, Online since 01 August 2017, connection on 19 April 2019. URL : http://journals.openedition.org/ejas/12098 ; DOI : 10.4000/ ejas.12098 This text was automatically generated on 19 April 2019. Creative Commons License “I Am Your Faggot Anti-Pope”: An Exploration of Marilyn Manson as a Transgres... 1 “I Am Your Faggot Anti-Pope”: An Exploration of Marilyn Manson as a Transgressive Artist Coco d’Hont 1 “As a performer,” Marilyn Manson announced in his autobiography, “I wanted to be the loudest, most persistent alarm clock I could be, because there didn’t seem to be any other way to snap society out of its Christianity- and media-induced coma” (Long Hard Road 80).i With this mission statement, expressed in 1998, the performer summarized a career characterized by harsh-sounding music, disturbing visuals, and increasingly controversial live performances. At first sight, the red thread running through the albums he released during the 1990s is a harsh attack on American ideologies. On his debut album Portrait of an American Family (1994), for example, Manson criticizes ideological constructs such as the nuclear family, arguing that the concept is often used to justify violent pro-life activism.ii Proclaiming that “I got my lunchbox and I’m armed real well” and that “next motherfucker’s gonna get my metal,” he presents himself as a personification of teenage angst determined to destroy his bullies, be they unfriendly classmates or the American government. -

Preisgestaltung Liste.Xlsx
Position Schallplatte Preis 1 10 CC - How dare you - FOC, OIS - Mercury 9102 501 - Made in England 8,00 € 2 10 CC - In Concert - Contour CN 2056 - Made in England 8,00 € 3 10 CC - Live and let Live - 2 LP FOC - Mercury 6641 714 - Made in Germany 9,00 € 4 10 CC - Profile - DECCA 6.24012 AL 8,00 € 5 10 psychotherapeutische Behandlungsverfahren 6,00 € 6 38 Special - Rockin' into the night - A&M AMLH 64782 - Made in Holland 15,00 € 7 A Band Called O - Within Reach - UAG 29942 - UK 10,00 € 8 A flock of seagulls - Listen 10,00 € 9 A flock of seagulls - Same - Picture Disc 36,00 € 10 A flock of seagulls - The story of a young heart 13,00 € 11 A Split Second - From the inside 13,00 € 12 A Tribute to Duke Ellington - We love you madly - 2 LP FOC - Verve 2632 022 - Made in Germany 10,00 € 13 A.C. Bhaktivedanta Swami Prabhupada - Krsna Meditation - RKP 1005 12,00 € 14 A.R. Machines - Die grüne Reise, The Green Journey - (Achim Reichel) - Polydor 2459 057 - Made in Germany 60,00 € 15 ABBA - Arrival - Club Edition - Polydor 65 940 9 - Made in Germany 5,00 € 16 ABBA - Greatest Hits Vol. 2 9,00 € 17 ABBA - Super Trouper 9,00 € 18 ABBA - The Album - Dig It PL 3012 - Made in Italy 2,00 € 19 ABBA - The Very Best Of - 2 LP FOC - Polydor DA 2612 032 (on Cover, Labels are different) 5,00 € 20 ABBA - The Visitors 9,00 € 21 ABBA - Voulez Vous 10,00 € 22 Abbi Hübner & the Jailhouse Jazzmen - Same - Storyville 6.23803 18,00 € 23 Abbi Hübner's Low Down Wizards - 1964-1971 - Warnung: Nur für Sammler - PF 085 18,00 € 24 Abbi Hübner's Low Down Wizards - 20 Jahre, -

Masarykova Univerzita Ústav Filmu a Audiovizuální Kultury
Masarykova univerzita Filozofická fakulta Ústav filmu a audiovizuální kultury Barbora Cibulová (FAV, bakalárske prezenčné štúdium) Dokumentarizmus – edukačná funkcia filmu Glen or Glenda. Neoformalistická analýza filmu Bakalárska diplomová práca Vedúci práce: Mgr. Marie Barešová Brno 2012 Poďakovnie: Ďakujem vedúcej práce Mgr. Marii Barešovej za trpezlivosť, rady a pripomienky, ktorými mi pomáhala pri písaní tejto práce. 2 Prehlásenie: Prehlasujem, ţe som pracovala samostatne s pouţitím uvede- ných zdrojov. 24.4.2012 Podpis: ............... 3 Obsah 1. Úvod....................................................6 1.2. Teoreticko-metodologická reflexia..................7 1.2.1. Princípy neoformalistickej analýzy filmu......7 1.2.2. Analýza filmu.................................8 2. Ekonomický a kultúrne-historický kontext................10 2.1. Vznik filmu........................................10 2.1.1. Autor a prípad Jorgensen......................11 2.1.2. Spolupráca....................................14 2.1.3. Distribúcia a predvádzanie....................15 2.2. Ďalší ţivot filmu po uvedení a jeho šírenie........17 2.2.1. Spôsoby šírenia a zmena vnímania..............18 3. Neoformalistická analýza................................22 3.1. Úvod k analýze.....................................22 3.2. Segmentácia syţetu.................................23 3.3. Naratologická analýza..............................25 3.3.1. Štruktúra syţetu..............................26 3.3.2. Rozsah a hĺbka narácie........................29 3.4. Štylistická analýza................................31 -

Features Sports No One Fights Alone!
Features Sports World News Page 2-3 Page 4 Page 5 Shark7878 Shark Way, Naples, FLBites 34119 Volume/Edition 2 By: Brenna Audrey No One Fights Alone! Photo Courtesy of Google Images One in eight women will be diagnosed is a higher risk of diagnosis. Thankfully, this disease. Excessive alcohol consumption, or tion comes from MammographySavesLives. with a form of breast cancer in her lifetime, is the case with less than 15% of women frequent consumption at all, can raise the org which is another website encouraging one case happens every two minutes. Out battling breast cancer. In addition to hered- risk 1.5 times if more than one alcoholic women to participate in a mammogram. In of these people, one will leave our lives itary inheritance of cancerous cells, being beverage is digested. Overall, one of the addition to mammograms, every woman every 13 minutes, making a total of roughly overweight or obese can play a large role in most deadly risks is the age of the person should self-examine herself monthly, as 79% 40,500 women dying in the United States the development of cancer cells. Scientists affected. Below the age of 30 years, the risk of of cancerous lumps are found by wom- alone out of the 252,710 diagnosed yearly. recommend maintaining a healthy weight, as of developing breast cancer is very low and en themselves. Thankfully, 80% of lumps The sad truth is that over 230,000 women a person who gains 21 to 30 pounds since age highly uncommon in high school or college detected are non cancerous, also known as are diagnosed with a new and invasive type eighteen while not carrying a child is 40% aged women, with the risk at 30 increasing at benign lumps. -
Loudwire.Com/Ozzy-Osbourne-Rob-Zombie-Ozzfest-2018-Photos- Recap/ A
JANUARY 1, 2019 Link to article: https://loudwire.com/ozzy-osbourne-rob-zombie-ozzfest-2018-photos- recap/ A Courtesy of MSO Ozzfest has taken many forms over the years, but on Dec. 31, 2018 it served as a way send out 2018 with a major location-based event and ring in 2019 with some of rock and metal's finest throwing a bash to remember. Ozzy Osbourne, who months earlier had to postpone a Los Angeles concert due to health issues, returned to the concert stage at the Forum full of energy and ready to count down the final minutes of the year. But before that, a stellar lineup rocked fans inside and outdoors at the Forum during a brisk but sunny afternoon. Wednesday 13 kicked off the festivities at 2:30PM, with a crew member getting in the spirit by shooting fake snow into the crowd. Their high energy set gave way to a more crushing performance from Dez Fafara and his DevilDriver crew. The moshpits started to form in the Forum parking lot as Fafara rallied the audience into a frenzy. The singer and guitarist Mike Spreitzer also showed their appreciation hanging around to meet with fans and take photos following their set. As DevilDriver came to a close, the almighty Zakk Wylde rolled up on a golf cart, greeted fans and signed autographs as he made is way to the stage. Other than Osbourne of course, Wylde may very well have been on the most Ozzfests between playing with Ozzy and Black Label Society. Wylde, fresh off the "Generation Axe" tour, played an hour-long set with his tribute band Zakk Sabbath, riffing through classics like “Snowblind,” “Into the Void,” and “N.I.B.” With the sun starting to fade, it was time to move the show indoors for the remainder of the night. -
Ed Wood Appelez-Le Ann Gora Sylvie Gendron
Document generated on 09/25/2021 2:45 p.m. Séquences La revue de cinéma Ed Wood Appelez-le Ann Gora Sylvie Gendron Robert Morin Number 175, November–December 1994 URI: https://id.erudit.org/iderudit/49799ac See table of contents Publisher(s) La revue Séquences Inc. ISSN 0037-2412 (print) 1923-5100 (digital) Explore this journal Cite this article Gendron, S. (1994). Ed Wood : appelez-le Ann Gora. Séquences, (175), 21–25. Tous droits réservés © La revue Séquences Inc., 1994 This document is protected by copyright law. Use of the services of Érudit (including reproduction) is subject to its terms and conditions, which can be viewed online. https://apropos.erudit.org/en/users/policy-on-use/ This article is disseminated and preserved by Érudit. Érudit is a non-profit inter-university consortium of the Université de Montréal, Université Laval, and the Université du Québec à Montréal. Its mission is to promote and disseminate research. https://www.erudit.org/en/ É t u d ED WOOD Appelez-le Ann Gora * Ed Wood. Avant la Les débuts pantalons. Le petit Ed en resta, apparemment, marqué Monsieur et Madame Wood menaient sans doute pour le reste de ses jours. Ed Wood, grand amateur sortie du film de une petite vie sans histoire dans la bonne ville de d'angora devant l'Éternel allait devenir le plus mauvais Poughkeepsie, New York, lorsque leur naquit, le 10 cinéaste de tous les temps. En plus d'avoir fait la Tim Burton, seuls octobre 1924, Edward junior. Difficile de savoir si Seconde Guerre mondiale avec les Marines, d'avoir tra madame Wood en fut heureuse puisque, à ce qu'il paraît, vaillé dans un cirque ambulant comme attraction mi- elle préférait vêtir son petit Ed de robes plutôt que de homme, mi-femme, et de croire qu'il serait un jour les psychotroniques célèbre.