Text Classification for Azerbaijani Language Using Machine Learning and Embeddings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KHAZAR UNIVERSITY Faculty
KHAZAR UNIVERSITY Faculty: Education Major: General and Applied Linguistics Topic: “May your young people cast off the stone of singleness:” Azerbaijani “alqış phrases” (blessing formulas) and their American English equivalents, or what is revealed by the lack thereof Master student: Martha Lawry Scientific Advisor: Professor Hamlet Isaxanli Submitted January 2012 1 Summary This thesis by Martha Lawry is entitled “„may your young people cast off the stone of singleness:‟ Azerbaijani „alqış phrases‟ (blessing formulas) and their American English equivalents, or what is revealed by the lack thereof.” The objective of the research is to define the alqış phrases which are frequently used in modern spoken Azerbaijani, determine how best to define them in English, determine their linguistic functions in Azerbaijani, and compare them to the phrases that most closely fulfill the same functions in American English. Ethnographic and comparative research methods were used, including reviewing secondary sources (literature reviews) and qualitative research in the form of both semi- structured interviews conducted with native Azerbaijani speakers of varying ages and social strata living in the Azerbaijan Republic and open-ended structured interviews conducted via an online questionnaire with native English speakers living in the United States. The research led to the conclusion that alqış phrases should be defined as ―blessing formulas‖ in English. Most alqış phrases were determined to be grammatically distinguished by second or third person verbs in optative or imperative mood. They can have the expressive functions of being bono-recognitive, bono-petitive, malo-recognitive or malo-fugitive, although the most common are bono-petitive and malo-fugitive. Alqış phrases were also shown to be politeness strategies according to Levinson and Brown‘s politeness theory (used to protect the speaker‘s positive face or to protect the listener‘s negative face). -

Turkish Language in Iran (From the Ghaznavid Empire to the End of the Safavid Dynasty)
42 Khazar Journal of Humanities and Social Sciences Turkish Language in Iran (from the Ghaznavid Empire to the end of the Safavid Dynasty) Zivar Huseynova Khazar University The history of Turks in Iran goes back to very ancient times, and there are differences of opinion among historians about the Turks‟ ruling of Iranian lands. However, all historians accept the rulers of the Turkish territories since the Ghaznavid Empire. In that era, Turks took over the rule of Iran and took the first steps toward broadening the empire. The Ghaznavi Turks, continuing to rule according to the local government system in Iran, expanded their territories as far as India. The warmongering Turks, making up the majority of the army, spread their own language among the army and even in the regions they occupied. Even if they did not make a strong influence in many cultural spheres, they did propagate their languages in comparison to Persian. Thus, we come across many Turkish words in Persian written texts of that period. This can be seen using the example of the word “amirakhurbashi” or “mirakhurbashı” which is composed of Arabic elements.1 The first word inside this compound word is the Arabic “amir” (command), but the second and third words composing it are Turkish. Amirakhurbashi was the name of a high government officer rank. Aside from this example, the Turkish words “çomaq”(“chomak”) and “qalachur”(“kalachur”) or “qarachur” (“karachur”) are used as names for military ammunition. 2 It is likely that the word karachur, which means a long and curved weapon, was taken from the word qılınc (“kilinj,” sword) and is even noted as a Turkish word in many dictionaries. -

The Imposition of Translated Equivalents to Avoid T
International Humanities Studies Vol. 3 No.1; March 2016 ISSN 2311-7796 On some future tense participles in modern Turkic languages Aynel Enver Meshadiyeva Abstract This paper investigates phonetic and morphological-semantic features and the main functions of the future participle –ası/-esi in modern Turkic languages. At the present time, a series of questions concerning an etymology of the future participle –ası/-esi in the modern Turkic languages does not have a due and exhaustive treatment in the Turkology. In the course of the research, similar and distinctive features of the future participles –ası/-esi in Turkic languages were revealed. It should be noted that comparative-historical researches of the grammatical elements in the modern Turkic languages have gained a considerable scientific meaning and undoubted actuality. The actuality of the paper’s theme is conditioned by these factors. Keywords: Future tense participle –ası/-esi, comparative-historical analysis, etimology, oghuz group, kipchak group, Turkic languages, similar and distinctive features. Introduction This article is devoted to comparative historical analysis of the future tense participle –ası/- esi in modern Turkic languages. The purpose of this article is to study a comparative historical analysis of the future tense participle –ası/-esi in Turkic languages. It also aims to identify various characteristic phonetic, morphological, and syntactic features in modern Turkic languages. This article also analyses materials of different dialects of Turkic languages, and their old written monuments. The results of the detailed etymological analysis of the future tense participle –ası/-esi help to reveal the peculiarities of lexical-semantic and morphological structure of the Turkic languages’ participle. -

Religious Aspects of Bilingualism in Azerbaijan
Occasional Papers on Religion in Eastern Europe Volume 40 Issue 6 Article 5 8-2020 Religious Aspects of Bilingualism in Azerbaijan Malahat Veliyeva Azerbaijan University of Languages, Baku Follow this and additional works at: https://digitalcommons.georgefox.edu/ree Part of the Christianity Commons, European Languages and Societies Commons, and the Islamic Studies Commons Recommended Citation Veliyeva, Malahat (2020) "Religious Aspects of Bilingualism in Azerbaijan," Occasional Papers on Religion in Eastern Europe: Vol. 40 : Iss. 6 , Article 5. Available at: https://digitalcommons.georgefox.edu/ree/vol40/iss6/5 This Thirty-Year Anniversary since the Fall of Communism is brought to you for free and open access by Digital Commons @ George Fox University. It has been accepted for inclusion in Occasional Papers on Religion in Eastern Europe by an authorized editor of Digital Commons @ George Fox University. For more information, please contact [email protected]. RELIGIOUS ASPECT OF BILINGUALISM IN AZERBAIJAN In the name of Allah, the Most Gracious, the Most Merciful... By Malahat Veliyeva Malahat Veliyeva is an Associate Professor at the Department of English Linguistics at Azerbaijan University of Languages in Baku. She did her PhD in Germanic languages in 2008 and started the post-doctorate degree in Sociolinguistics in 2012. Her area of interest is also multiculturalism and religious studies. She was a SUSI scholar awarded by the scholarship of the US Department of State in 2019. She has three publications on General Linguistics. Email: [email protected] Introduction Azerbaijan is one of the former countries of the Union of Soviet Socialistic Republics (the USSR) that lost its independence in 1920 when the Russian XI Red Army brutally intervened in the country and imposed the Soviet regime throughout Azerbaijan. -

Foreign-Language Influence on the Morphological Structure of Dialects That Were Formed in the Bilingual Habitat
ISSN 2039-2117 (online) Mediterranean Journal of Social Sciences Vol.5 No.22 ISSN 2039-9340 (print) MCSER Publishing, Rome-Italy September 2014 Foreign-language influence on the morphological structure of dialects that were formed in the bilingual habitat Gurbanova Ilahe National Academy of Science of Azerbaijan, doctoral [email protected] DOI:10.5901/mjss.2014.v5n22p27 Abstract The purpose of this article is to find out whether there have been changes in the morphological structure of some dialects of the Azerbaijani language in the bilingual environment. Investigated the internal structure of any language. The structurally agglutinative Turkic languages, the segment force of which is vowel harmony, are more resistant to change than internally changing inflected languages . But some dialects were formed and developed in the bilingual and even polylingual environment. But does fairly close proximity to the morphological system of any dialect. The study shows the conservatism of the Turkic languages to some extent associated with agglutinative systems. In every language morphological structure and phonetic laws are interrelated and determine each other. Research shows foreign-language influence on morphological structure of dialects, it is first necessary to clarify whether there is influence in the phonetic level. Agglutination and vowel harmony always predetermined internal resistance of the Turkic languages . Key words: dialects, investigate, morphological Introduction It is known that dialects are the most unique event in the language, the reasons of emerging of which still produces different thinking on the part of scientists. All reflections, despite their dissimilarity, give logical conclusion. Dialects were formed by localization of tribal languages in some areas, while preserving the ancient conservative elements. -

History of Azerbaijan (Textbook)
DILGAM ISMAILOV HISTORY OF AZERBAIJAN (TEXTBOOK) Azerbaijan Architecture and Construction University Methodological Council of the meeting dated July 7, 2017, was published at the direction of № 6 BAKU - 2017 Dilgam Yunis Ismailov. History of Azerbaijan, AzMİU NPM, Baku, 2017, p.p.352 Referents: Anar Jamal Iskenderov Konul Ramiq Aliyeva All rights reserved. No part of this book may be reproduced or transmitted in any form by any means. Electronic or mechanical, including photocopying, recording or by any information storage and retrieval system, without permission in writing from the copyright owner. In Azerbaijan University of Architecture and Construction, the book “History of Azerbaijan” is written on the basis of a syllabus covering all topics of the subject. Author paid special attention to the current events when analyzing the different periods of Azerbaijan. This book can be used by other high schools that also teach “History of Azerbaijan” in English to bachelor students, master students, teachers, as well as to the independent learners of our country’s history. 2 © Dilgam Ismailov, 2017 TABLE OF CONTENTS Foreword…………………………………….……… 9 I Theme. Introduction to the history of Azerbaijan 10 II Theme: The Primitive Society in Azerbaijan…. 18 1.The Initial Residential Dwellings……….............… 18 2.The Stone Age in Azerbaijan……………………… 19 3.The Copper, Bronze and Iron Ages in Azerbaijan… 23 4.The Collapse of the Primitive Communal System in Azerbaijan………………………………………….... 28 III Theme: The Ancient and Early States in Azer- baijan. The Atropatena and Albanian Kingdoms.. 30 1.The First Tribal Alliances and Initial Public Institutions in Azerbaijan……………………………. 30 2.The Kingdom of Manna…………………………… 34 3.The Atropatena and Albanian Kingdoms…………. -

Turkic Toponyms of Eurasia BUDAG BUDAGOV
BUDAG BUDAGOV Turkic Toponyms of Eurasia BUDAG BUDAGOV Turkic Toponyms of Eurasia © “Elm” Publishing House, 1997 Sponsored by VELIYEV RUSTAM SALEH oglu T ranslated by ZAHID MAHAMMAD oglu AHMADOV Edited by FARHAD MAHAMMAD oglu MUSTAFAYEV Budagov B.A. Turkic Toponyms of Eurasia. - Baku “Elm”, 1997, -1 7 4 p. ISBN 5-8066-0757-7 The geographical toponyms preserved in the immense territories of Turkic nations are considered in this work. The author speaks about the parallels, twins of Azerbaijani toponyms distributed in Uzbekistan, Kazakhstan, Turkmenistan, Altay, the Ural, Western Si beria, Armenia, Iran, Turkey, the Crimea, Chinese Turkistan, etc. Be sides, the geographical names concerned to other Turkic language nations are elucidated in this book. 4602000000-533 В ------------------------- 655(07)-97 © “Elm” Publishing House, 1997 A NOTED SCIENTIST Budag Abdulali oglu Budagov was bom in 1928 at the village o f Chobankere, Zangibasar district (now Masis), Armenia. He graduated from the Yerevan Pedagogical School in 1947, the Azerbaijan State Pedagogical Institute (Baku) in 1951. In 1955 he was awarded his candidate and in 1967 doctor’s degree. In 1976 he was elected the corresponding-member and in 1989 full-member o f the Azerbaijan Academy o f Sciences. Budag Abdulali oglu is the author o f more than 500 scientific articles and 30 books. Researches on a number o f problems o f the geographical science such as geomorphology, toponymies, history o f geography, school geography, conservation o f nature, ecology have been carried out by academician B.A.Budagov. He makes a valuable contribution for popularization o f science. -

The Formation of Azerbaijani Collective Identity in Iran
Nationalities Papers ISSN: 0090-5992 (Print) 1465-3923 (Online) Journal homepage: http://www.tandfonline.com/loi/cnap20 The formation of Azerbaijani collective identity in Iran Brenda Shaffer To cite this article: Brenda Shaffer (2000) The formation of Azerbaijani collective identity in Iran, Nationalities Papers, 28:3, 449-477, DOI: 10.1080/713687484 To link to this article: http://dx.doi.org/10.1080/713687484 Published online: 19 Aug 2010. Submit your article to this journal Article views: 207 View related articles Citing articles: 5 View citing articles Full Terms & Conditions of access and use can be found at http://www.tandfonline.com/action/journalInformation?journalCode=cnap20 Download by: [Harvard Library] Date: 24 March 2016, At: 11:49 Nationalities Papers, Vol. 28, No. 3, 2000 THE FORMATION OF AZERBAIJANI COLLECTIVE IDENTITY IN IRAN Brenda Shaffer Iran is a multi-ethnic society in which approximately 50% of its citizens are of non-Persian origin, yet researchers commonly use the terms Persians and Iranians interchangeably, neglecting the supra-ethnic meaning of the term Iranian for many of the non-Persians in Iran. The largest minority ethnic group in Iran is the Azerbaijanis (comprising approximately a third of the population) and other major groups include the Kurds, Arabs, Baluchis and Turkmen.1 Iran’s ethnic groups are particularly susceptible to external manipulation and considerably subject to in uence from events taking place outside its borders, since most of the non-Persians are concen- trated in the frontier areas and have ties to co-ethnics in adjoining states, such as Azerbaijan, Turkmenistan, Pakistan and Iraq. -
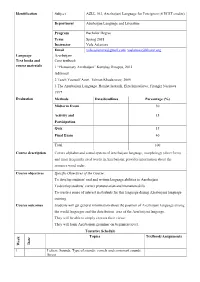
Identification Subject AZLL 103, Azerbaijani Language for Foreigners (6 ECST Credits)
Identification Subject AZLL 103, Azerbaijani Language for Foreigners (6 ECST credits) Department Azerbaijan Language and Literature Program Bachelor Degree Term Spring 2018 Instructor Vafa Aslanova Email [email protected], [email protected] Language Azerbaijani Text books and Core textbook course materials 1 “Elementary Azerbaijani” Kurtuluş Öztopçu, 2012 Aditional 2 Teach Yourself Azeri. Telman Khudazarov, 2005 3 The Azerbaijani Language. Hamlet Isaxanli, Elza Ismayilova, Firangiz Nasirova. 1997 Evaluation Methods Date/deadlines Percentage (%) Midterm Exam 30 Activity and 15 Participation Quiz 15 Final Exam 40 Total 100 Course description Covers alphabet and sound system of Azerbaijani language, morphology (short form) and most frequently used words in Azerbaijani; provides information about the sentence word order. Course objectives Specific Objectives of the Course: To develop students' oral and written language abilities in Azerbaijani To develop students’ correct pronunciation and intonation skills To create a sense of interest in students for this language during Azerbaijani language training Course outcomes Students will get general information about the position of Azerbaijani language among the world languages and the distribution area of the Azerbaijani language. They will be able to simply express their views. They will learn Azerbaijani grammar on beginners level. Tentative Schedule Topics Textbook/Assignments Date Week 1 Letters. Sounds. Type of sounds: vowels and consonant sounds. Stress. 2 Pronouns. Personal pronouns, demonstrative pronouns. Nominal predicate. Negation of the Present tense verb to be. Vowel harmony. 3 Noun, Plural nouns. Changing of names into Possession, Consenant alternations-q,-k. Yes/ no questions with the present tense verb to be. Question pronouns- nə, kim. Derivative suffixes – li, siz. -

Celtic Language As a Primary Branch of Ancient Japhetic Or Turanian Language
International Journal of English Linguistics; Vol. 4, No. 5; 2014 ISSN 1923-869X E-ISSN 1923-8703 Published by Canadian Center of Science and Education Celtic Language as a Primary Branch of Ancient Japhetic or Turanian Language Aygun Kosayeva1 1 Department of Linguoculturology, Azerbaijan University of Languages, Baku, Azerbaijan Correspondence: Aygun Kosayeva, Department of Linguoculturology, Azerbaijan University of Languages, Baku, Azerbaijan. E-mail: [email protected] Received: May 9, 2014 Accepted: September 1, 2014 Online Published: October 1, 2014 doi:10.5539/ijel.v4n5p70 URL: http://dx.doi.org/10.5539/ijel.v4n5p70 Abstract This article reports on a study of words affinity in Irish, Azerbaijani and other Turkic languages. In spite of Irishmen’s migration from territory of ancient Azerbaijan to Asia Minor and further to the British Isles, they could preserve not only culture, but also their language in a new motherland. The present paper discloses semantic similarities and etymology of several words in Irish, Gaelic, Welsh and other Turkic languages. Celtic language was a primary branch of ancient Japhetic or Turanian language, because the meaning of several words in Celtic and Turkic languages proves a kinship between Celts and Turkic nations. Keywords: Celtic, Turkic, Saca, Japhetic, semantic similarity, affinity 1. Introduction The history of language development is closely connected with a history of people’s progress. Therefore, it is impossible to study the formation and development of this or another language in separation from deep studying of history of development of state and people. Celtic language family includes: Irish, Scottish, and Manx (Gaelic languages) and Welsh, Breton and Cornish (Brythonic languages). -

“Long Live the Turkish-Azerbaijani Brotherhood”
“Long live the Turkish-Azerbaijani brotherhood” A Study of Turkish-Azerbaijani Relations Julia Aybeniz Ensrud Abedi Master’s Thesis in Political Science Department of Political Science UNIVERSITY OF OSLO Spring 2019 Word count: 39.024 II “Long live the Turkish-Azerbaijani brotherhood” A Study of Turkish-Azerbaijani Relations © Julia Aybeniz Ensrud Abedi 2019 “Long live the Turkish-Azerbaijani brotherhood” - A Study of Turkish-Azerbaijani Relations Julia Aybeniz Ensrud Abedi http://www.duo.uio.no Print: Grafiske Senter, Oslo III Abstract The bilateral relations between Turkey and Azerbaijan are often described as brotherly and friendly in everyday life as well as by foreign policy elites as their societies share several close cultural and linguistic ties. The influence of kinship and friendship on states is becoming a field within International Relations, and these concepts can be fruitful to better understand relations between states by providing a perspective that is often taken for granted or not studied systematically. Theoretically, the thesis draws on discourse analysis to uncover how foreign policy elites categorise the world, their interpretation of meaning, and how they perceive and describe kinship and friendship. The objective of this study has been to explain how and to what extent Turkish and Azerbaijani elites are using claims of historical and metaphorical kinship to legitimise their bilateral relationship and conduct foreign policy. This is more specifically analysed by looking at the frozen conflict in Nagorno-Karabakh in the South Caucasus because it underlines the special character of the bilateral relations between Turkey and Azerbaijan, as Ankara has been supporting Baku’s position against Armenia. -

September 1993 (1.3) Azerbaijani: Language of a Divided Nation The
September 1993 (1.3) Azerbaijani: Language of a Divided Nation The Differences Between the North and the South By Habib Azarsina / Naida Mamedova What happens to a language when the country in which it is spoken is divided and ruled by two separate and very different political systems? What kinds of influences shape the vocabulary, phonological and grammatical structure and even graphic presentation of the language? In 1828, Azerbaijan was divided into two separate entities – Northern Azerbaijan (ruled by Russian czars and later Soviet Union from which it gained independence in 1991) and Southern Azerbaijan (Iran). Habib Azarsina from Urmia (Southern Azerbijan) and his wife, Naida Mamedova from Baku (the Republic of Azerbaijan), experience the nuances of these language differences daily. Together they share their observations. Historical Overview Despite the separation into what is commonly referred to as “Nothern and Southern Azerbaijan,” the Azerbaijani language has remained basically the same. Azerbaijanis of Iran are able to carry on long conversations with Azerbaijanis of the Republic of Azerbaijan with very little difficulty. Although Azerbaijan has been divided for more than 150 years, no border control existed between the two regions until the 1920’s when the Bolsheviks took over in the North. Even after that date, two major migrations took place. During Stalin’s purges of the 1930’s, thousands of Azerbaijanis from Soviet Azerbaijan were either deported or escaped to the Iranian side. The reverse situation took place in December 1946 after the collapse of the short-lived Azerbaijan Democratic government when thousands of Southern Azerbaijanis fled north. But even up until 1947, Azerbaijanis living on either side of the border were in frequent contact with each other.