An Algorithm to Learn Polytree Networks with Hidden Nodes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
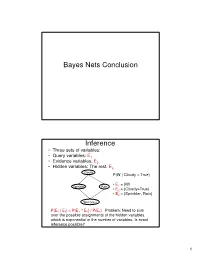
Bayes Nets Conclusion Inference
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -

Applications of DFS
(b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges 1 / 7 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 1 / 7 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 1 / 7 4. Connected components of a undirected graph (see Homework 6) 5. -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R. -

Lowest Common Ancestors in Trees and Directed Acyclic Graphs1
Lowest Common Ancestors in Trees and Directed Acyclic Graphs1 Michael A. Bender2 3 Martín Farach-Colton4 Giridhar Pemmasani2 Steven Skiena2 5 Pavel Sumazin6 Version: We study the problem of finding lowest common ancestors (LCA) in trees and directed acyclic graphs (DAGs). Specifically, we extend the LCA problem to DAGs and study the LCA variants that arise in this general setting. We begin with a clear exposition of Berkman and Vishkin’s simple optimal algorithm for LCA in trees. The ideas presented are not novel theoretical contributions, but they lay the foundation for our work on LCA problems in DAGs. We present an algorithm that finds all-pairs-representative : LCA in DAGs in O~(n2 688 ) operations, provide a transitive-closure lower bound for the all-pairs-representative-LCA problem, and develop an LCA-existence algorithm that preprocesses the DAG in transitive-closure time. We also present a suboptimal but practical O(n3) algorithm for all-pairs-representative LCA in DAGs that uses ideas from the optimal algorithms in trees and DAGs. Our results reveal a close relationship between the LCA, all-pairs-shortest-path, and transitive-closure problems. We conclude the paper with a short experimental study of LCA algorithms in trees and DAGs. Our experiments and source code demonstrate the elegance of the preprocessing-query algorithms for LCA in trees. We show that for most trees the suboptimal Θ(n log n)-preprocessing Θ(1)-query algorithm should be preferred, and demonstrate that our proposed O(n3) algorithm for all- pairs-representative LCA in DAGs performs well in both low and high density DAGs. -

Trees a Tree Is a Graph Which Is (A) Connected and (B) Has No Cycles (Acyclic)
Trees A tree is a graph which is (a) Connected and (b) has no cycles (acyclic). 1 Lemma 1 Let the components of G be C1; C2; : : : ; Cr, Suppose e = (u; v) 2= E, u 2 Ci; v 2 Cj. (a) i = j ) !(G + e) = !(G). (b) i 6= j ) !(G + e) = !(G) − 1. (a) v u (b) u v 2 Proof Every path P in G + e which is not in G must contain e. Also, !(G + e) ≤ !(G): Suppose (x = u0; u1; : : : ; uk = u; uk+1 = v; : : : ; u` = y) is a path in G + e that uses e. Then clearly x 2 Ci and y 2 Cj. (a) follows as now no new relations x ∼ y are added. (b) Only possible new relations x ∼ y are for x 2 Ci and y 2 Cj. But u ∼ v in G + e and so Ci [ Cj becomes (only) new component. 2 3 Lemma 2 G = (V; E) is acyclic (forest) with (tree) components C1; C2; : : : ; Ck. jV j = n. e = (u; v) 2= E, u 2 Ci; v 2 Cj. (a) i = j ) G + e contains a cycle. (b) i 6= j ) G + e is acyclic and has one less com- ponent. (c) G has n − k edges. 4 (a) u; v 2 Ci implies there exists a path (u = u0; u1; : : : ; u` = v) in G. So G + e contains the cycle u0; u1; : : : ; u`; u0. u v 5 (a) v u Suppose G + e contains the cycle C. e 2 C else C is a cycle of G. C = (u = u0; u1; : : : ; u` = v; u0): But then G contains the path (u0; u1; : : : ; u`) from u to v – contradiction. -
![Arxiv:1901.04560V1 [Math.CO] 14 Jan 2019 the flexibility That Makes Hypergraphs Such a Versatile Tool Complicates Their Analysis](https://docslib.b-cdn.net/cover/7775/arxiv-1901-04560v1-math-co-14-jan-2019-the-exibility-that-makes-hypergraphs-such-a-versatile-tool-complicates-their-analysis-817775.webp)
Arxiv:1901.04560V1 [Math.CO] 14 Jan 2019 the flexibility That Makes Hypergraphs Such a Versatile Tool Complicates Their Analysis
MINIMALLY CONNECTED HYPERGRAPHS MARK BUDDEN, JOSH HILLER, AND ANDREW PENLAND Abstract. Graphs and hypergraphs are foundational structures in discrete mathematics. They have many practical applications, including the rapidly developing field of bioinformatics, and more generally, biomathematics. They are also a source of interesting algorithmic problems. In this paper, we define a construction process for minimally connected r-uniform hypergraphs, which captures the intuitive notion of building a hypergraph piece-by-piece, and a numerical invariant called the tightness, which is independent of the construc- tion process used. Using these tools, we prove some fundamental properties of minimally connected hypergraphs. We also give bounds on their chromatic numbers and provide some results involving edge colorings. We show that ev- ery connected r-uniform hypergraph contains a minimally connected spanning subhypergraph and provide a polynomial-time algorithm for identifying such a subhypergraph. 1. Introduction Graphs and hypergraphs provide many beautiful results in discrete mathemat- ics. They are also extremely useful in applications. Over the last six decades, graphs and their generalizations have been used for modeling many biological phenomena, ranging in scale from protein-protein interactions, individualized cancer treatments, carcinogenesis, and even complex interspecial relationships [12, 15, 16, 19, 22]. In the last few years in particular, hypergraphs have found an increasingly prominent position in the biomathematical literature, as they allow scientists and practitioners to model complex interactions between arbitrarily many actors [22]. arXiv:1901.04560v1 [math.CO] 14 Jan 2019 The flexibility that makes hypergraphs such a versatile tool complicates their analysis. Because of this, many different algorithms and metrics have been devel- oped to assist with their application [18, 23]. -

9 the Graph Data Model
CHAPTER 9 ✦ ✦ ✦ ✦ The Graph Data Model A graph is, in a sense, nothing more than a binary relation. However, it has a powerful visualization as a set of points (called nodes) connected by lines (called edges) or by arrows (called arcs). In this regard, the graph is a generalization of the tree data model that we studied in Chapter 5. Like trees, graphs come in several forms: directed/undirected, and labeled/unlabeled. Also like trees, graphs are useful in a wide spectrum of problems such as com- puting distances, finding circularities in relationships, and determining connectiv- ities. We have already seen graphs used to represent the structure of programs in Chapter 2. Graphs were used in Chapter 7 to represent binary relations and to illustrate certain properties of relations, like commutativity. We shall see graphs used to represent automata in Chapter 10 and to represent electronic circuits in Chapter 13. Several other important applications of graphs are discussed in this chapter. ✦ ✦ ✦ ✦ 9.1 What This Chapter Is About The main topics of this chapter are ✦ The definitions concerning directed and undirected graphs (Sections 9.2 and 9.10). ✦ The two principal data structures for representing graphs: adjacency lists and adjacency matrices (Section 9.3). ✦ An algorithm and data structure for finding the connected components of an undirected graph (Section 9.4). ✦ A technique for finding minimal spanning trees (Section 9.5). ✦ A useful technique for exploring graphs, called “depth-first search” (Section 9.6). 451 452 THE GRAPH DATA MODEL ✦ Applications of depth-first search to test whether a directed graph has a cycle, to find a topological order for acyclic graphs, and to determine whether there is a path from one node to another (Section 9.7). -

Context-Bounded Analysis of Concurrent Queue Systems*
Context-Bounded Analysis of Concurrent Queue Systems Salvatore La Torre1, P. Madhusudan2, and Gennaro Parlato1,2 1 Universit`a degli Studi di Salerno, Italy 2 University of Illinois at Urbana-Champaign, USA Abstract. We show that the bounded context-switching reachability problem for concurrent finite systems communicating using unbounded FIFO queues is decidable, where in each context a process reads from only one queue (but is allowed to write onto all other queues). Our result also holds when individual processes are finite-state recursive programs provided a process dequeues messages only when its local stack is empty. We then proceed to classify architectures that admit a decidable (un- bounded context switching) reachability problem, using the decidability of bounded context switching. We show that the precise class of decid- able architectures for recursive programs are the forest architectures, while the decidable architectures for non-recursive programs are those that do not have an undirected cycle. 1 Introduction Networks of concurrent processes communicating via message queues form a very natural and useful model for several classes of systems with inherent paral- lelism. Two natural classes of systems can be modeled using such a framework: asynchronous programs on a multi-core computer and distributed programs com- municating on a network. In parallel programming languages for multi-core or even single-processor sys- tems (e.g., Java, web service design), asynchronous programming or event-driven programming is a common idiom that programming languages provide [19,7,13]. In order to obtain higher performance and low latency, programs are equipped with the ability to issue tasks using asynchronous calls that immediately return, but are processed later, either in parallel with the calling module or perhaps much later, depending on when processors and other resources such as I/O be- come free. -

A Low Complexity Topological Sorting Algorithm for Directed Acyclic Graph
International Journal of Machine Learning and Computing, Vol. 4, No. 2, April 2014 A Low Complexity Topological Sorting Algorithm for Directed Acyclic Graph Renkun Liu then return error (graph has at Abstract—In a Directed Acyclic Graph (DAG), vertex A and least one cycle) vertex B are connected by a directed edge AB which shows that else return L (a topologically A comes before B in the ordering. In this way, we can find a sorted order) sorting algorithm totally different from Kahn or DFS algorithms, the directed edge already tells us the order of the Because we need to check every vertex and every edge for nodes, so that it can simply be sorted by re-ordering the nodes the “start nodes”, then sorting will check everything over according to the edges from a Direction Matrix. No vertex is again, so the complexity is O(E+V). specifically chosen, which makes the complexity to be O*E. An alternative algorithm for topological sorting is based on Then we can get an algorithm that has much lower complexity than Kahn and DFS. At last, the implement of the algorithm by Depth-First Search (DFS) [2]. For this algorithm, edges point matlab script will be shown in the appendix part. in the opposite direction as the previous algorithm. The algorithm loops through each node of the graph, in an Index Terms—DAG, algorithm, complexity, matlab. arbitrary order, initiating a depth-first search that terminates when it hits any node that has already been visited since the beginning of the topological sort: I. -

CS302 Final Exam, December 5, 2016 - James S
CS302 Final Exam, December 5, 2016 - James S. Plank Question 1 For each of the following algorithms/activities, tell me its running time with big-O notation. Use the answer sheet, and simply circle the correct running time. If n is unspecified, assume the following: If a vector or string is involved, assume that n is the number of elements. If a graph is involved, assume that n is the number of nodes. If the number of edges is not specified, then assume that the graph has O(n2) edges. A: Sorting a vector of uniformly distributed random numbers with bucket sort. B: In a graph with exactly one cycle, determining if a given node is on the cycle, or not on the cycle. C: Determining the connected components of an undirected graph. D: Sorting a vector of uniformly distributed random numbers with insertion sort. E: Finding a minimum spanning tree of a graph using Prim's algorithm. F: Sorting a vector of uniformly distributed random numbers with quicksort (average case). G: Calculating Fib(n) using dynamic programming. H: Performing a topological sort on a directed acyclic graph. I: Finding a minimum spanning tree of a graph using Kruskal's algorithm. J: Finding the minimum cut of a graph, after you have found the network flow. K: Finding the first augmenting path in the Edmonds Karp implementation of network flow. L: Processing the residual graph in the Ford Fulkerson algorithm, once you have found an augmenting path. Question 2 Please answer the following statements as true or false. A: Kruskal's algorithm requires a starting node. -

On the Parameterized Complexity of Polytree Learning
On the Parameterized Complexity of Polytree Learning Niels Grüttemeier , Christian Komusiewicz and Nils Morawietz∗ Philipps-Universität Marburg, Marburg, Germany {niegru, komusiewicz, morawietz}@informatik.uni-marburg.de Abstract In light of the hardness of handling general Bayesian networks, the learning and inference prob- A Bayesian network is a directed acyclic graph that lems for Bayesian networks fulfilling some spe- represents statistical dependencies between vari- cific structural constraints have been studied exten- ables of a joint probability distribution. A funda- sively [Pearl, 1989; Korhonen and Parviainen, 2013; mental task in data science is to learn a Bayesian Korhonen and Parviainen, 2015; network from observed data. POLYTREE LEARN- Grüttemeier and Komusiewicz, 2020a; ING is the problem of learning an optimal Bayesian Ramaswamy and Szeider, 2021]. network that fulfills the additional property that its underlying undirected graph is a forest. In One of the earliest special cases that has received atten- this work, we revisit the complexity of POLYTREE tion are tree networks, also called branchings. A tree is a LEARNING. We show that POLYTREE LEARN- Bayesian network where every vertex has at most one par- ING can be solved in 3n · |I|O(1) time where n is ent. In other words, every connected component is a di- the number of variables and |I| is the total in- rected in-tree. Learning and inference can be performed in stance size. Moreover, we consider the influence polynomial time on trees [Chow and Liu, 1968; Pearl, 1989]. of the number of variables d that might receive a Trees are, however, very limited in their modeling power nonempty parent set in the final DAG on the com- since every variable may depend only on at most one other plexity of POLYTREE LEARNING.