Merkle Trees and Directed Acyclic Graphs (DAG) As We've Discussed, the Decentralized Web Depends on Linked Data Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Angela: a Sparse, Distributed, and Highly Concurrent Merkle Tree
Angela: A Sparse, Distributed, and Highly Concurrent Merkle Tree Janakirama Kalidhindi, Alex Kazorian, Aneesh Khera, Cibi Pari Abstract— Merkle trees allow for efficient and authen- with high query throughput. Any concurrency overhead ticated verification of data contents through hierarchical should not destroy the system’s performance when the cryptographic hashes. Because the contents of parent scale of the merkle tree is very large. nodes in the trees are the hashes of the children nodes, Outside of Key Transparency, this problem is gen- concurrency in merkle trees is a hard problem. The eralizable to other applications that have the need current standard for merkle tree updates is a naive locking of the entire tree as shown in Google’s merkle tree for efficient, authenticated data structures, such as the implementation, Trillian. We present Angela, a concur- Global Data Plane file system. rent and distributed sparse merkle tree implementation. As a result of these needs, we have developed a novel Angela is distributed using Ray onto Amazon EC2 algorithm for updating a batch of updates to a merkle clusters and uses Amazon Aurora to store and retrieve tree concurrently. Run locally on a MacBook Pro with state. Angela is motivated by Google Key Transparency a 2.2GHz Intel Core i7, 16GB of RAM, and an Intel and inspired by it’s underlying merkle tree, Trillian. Iris Pro1536 MB, we achieved a 2x speedup over the Like Trillian, Angela assumes that a large number of naive algorithm mentioned earlier. We expanded this its 2256 leaves are empty and publishes a new root after algorithm into a distributed merkle tree implementation, some amount of time. -
Bayes Nets Conclusion Inference
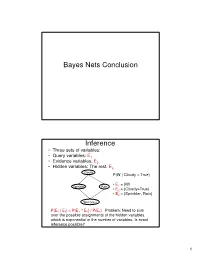
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -

Enabling Authentication of Sliding Window Queries on Streams
ProofInfused Streams: Enabling Authentication of Sliding Window Queries On Streams Feifei Li† Ke Yi‡ Marios Hadjieleftheriou‡ George Kollios† †Computer Science Department Boston University ‡AT&T Labs Inc. lifeifei, gkollios @cs.bu.edu yike, marioh @research.att.com { } { } ABSTRACT As computer systems are essential components of many crit- ical commercial services, the need for secure online transac- . tions is now becoming evident. The demand for such appli- cations, as the market grows, exceeds the capacity of individ- 0110..011 ual businesses to provide fast and reliable services, making Provider Servers outsourcing technologies a key player in alleviating issues Clients of scale. Consider a stock broker that needs to provide a real-time stock trading monitoring service to clients. Since Figure 1: The outsourced stream model. the cost of multicasting this information to a large audi- ence might become prohibitive, the broker could outsource providers, who would be in turn responsible for forwarding the stock feed to third-party providers, who are in turn re- the appropriate sub-feed to clients (see Figure 1). Evidently, sponsible for forwarding the appropriate sub-feed to clients. especially in critical applications, the integrity of the third- Evidently, in critical applications the integrity of the third- party should not be taken for granted, as the latter might party should not be taken for granted. In this work we study have malicious intent or might be temporarily compromised a variety of authentication algorithms for selection and ag- by other malicious entities. Deceiving clients can be at- gregation queries over sliding windows. Our algorithms en- tempted for gaining business advantage over the original able the end-users to prove that the results provided by the service provider, for competition purposes against impor- third-party are correct, i.e., equal to the results that would tant clients, or for easing the workload on the third-party have been computed by the original provider. -

Providing Authentication and Integrity in Outsourced Databases Using Merkle Hash Tree’S
Providing Authentication and Integrity in Outsourced Databases using Merkle Hash Tree's Einar Mykletun Maithili Narasimha University of California Irvine University of California Irvine [email protected] [email protected] Gene Tsudik University of California Irvine [email protected] 1 Introduction In this paper we intend to describe and summarize results relating to the use of authenticated data structures, specifically Merkle Hash Tree's, in the context of the Outsourced Database Model (ODB). In ODB, organizations outsource their data management needs to an external untrusted service provider. The service provider hosts clients' databases and offers seamless mechanisms to create, store, update and access (query) their databases. Due to the service provider being untrusted, it becomes imperative to provide means to ensure authenticity and integrity in the query replies returned by the provider to clients. It is therefore the goal of this paper to outline an applicable data structure that can support authenticated query replies from the service provider to the clients (who issue the queries). Merkle Hash Tree's (introduced in section 3) is such a data structure. 1.1 Outsourced Database Model (ODB) The outsourced database model (ODB) is an example of the well-known Client-Server model. In ODB, the Database Service Provider (also referred to as the Server) has the infrastructure required to host outsourced databases and provides efficient mechanisms for clients to create, store, update and query the database. The owner of the data is identified as the entity who has to access to add, remove, and modify tuples in the database. The owner and the client may or may not be the same entity. -

Applications of DFS
(b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges 1 / 7 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 1 / 7 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 1 / 7 4. Connected components of a undirected graph (see Homework 6) 5. -

The SCADS Toolkit Nick Lanham, Jesse Trutna
The SCADS Toolkit Nick Lanham, Jesse Trutna (it’s catching…) SCADS Overview SCADS is a scalable, non-relational datastore for highly concurrent, interactive workloads. Scale Independence - as new users join No changes to application Cost per user doesn’t increase Request latency doesn’t change Key Innovations 1. Performance safe query language 2. Declarative performance/consistency tradeoffs 3. Automatic scale up and down using machine learning Toolkit Motivation Investigated other open-source distributed key-value stores Cassandra, Hypertable, CouchDB Monolithic, opaque point solutions Make many decisions about how to architect the system a -prori Want set of components to rapidly explore the space of systems’ design Extensible components communicate over established APIs Understand the implications and performance bottlenecks of different designs SCADS Components Component Responsibilities Storage Layer Persist and serve data for a specified key responsibility Copy and sync data between storage nodes Data Placement Layer Assign node key responsibilities Manage replication and partition factors Provide clients with key to node mapping Provides mechanism for machine learning policies Client Library Hides client interaction with distributed storage system Provides higher-level constructs like indexes and query language Storage Layer Key-value store that supports range queries built on BDB API Record get(NameSpace ns, RecordKey key) list<Record> get_set (NameSpace ns, RecordSet rs ) bool put(NameSpace ns, Record rec) i32 count_set(NameSpace ns, RecordSet rs) bool set_responsibility_policy(NameSpace ns,RecordSet policy) RecordSet get_responsibility_policy(NameSpace ns) bool sync_set(NameSpace ns, RecordSet rs, Host h, ConflictPolicy policy) bool copy_set(NameSpace ns, RecordSet rs, Host h) bool remove_set(NameSpace ns, RecordSet rs) Storage Layer Storage Layer Storage Layer: Synchronize Replicas may diverge during network partitions (in order to preserve availability). -

Authentication of Moving Range Queries
Authentication of Moving Range Queries Duncan Yung Eric Lo Man Lung Yiu ∗ Department of Computing Hong Kong Polytechnic University {cskwyung, ericlo, csmlyiu}@comp.polyu.edu.hk ABSTRACT the user leaves the safe region, Thus, safe region is a powerful op- A moving range query continuously reports the query result (e.g., timization for significantly reducing the communication frequency restaurants) that are within radius r from a moving query point between the user and the service provider. (e.g., moving tourist). To minimize the communication cost with The query results and safe regions returned by LBS, however, the mobile clients, a service provider that evaluates moving range may not always be accurate. For instance, a hacker may infiltrate queries also returns a safe region that bounds the validity of query the LBS’s servers [25] so that results of queries all include a partic- results. However, an untrustworthy service provider may report in- ular location (e.g., the White House). Furthermore, the LBS may be correct safe regions to mobile clients. In this paper, we present effi- self-compromised and thus ranks sponsored facilities higher than cient techniques for authenticating the safe regions of moving range actual query result. The LBS may also return an overly large safe queries. We theoretically proved that our methods for authenticat- region to the clients for the sake of saving computing resources and ing moving range queries can minimize the data sent between the communication bandwidth [22, 16, 30]. On the other hand, the LBS service provider and the mobile clients. Extensive experiments are may opt to return overly small safe regions so that the clients have carried out using both real and synthetic datasets and results show to request new safe regions more frequently, if the LBS charges fee that our methods incur small communication costs and overhead. -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R. -

Executing Large Scale Processes in a Blockchain
The current issue and full text archive of this journal is available on Emerald Insight at: www.emeraldinsight.com/2514-4774.htm JCMS 2,2 Executing large-scale processes in a blockchain Mahalingam Ramkumar Department of Computer Science and Engineering, Mississippi State University, 106 Starkville, Mississippi, USA Received 16 May 2018 Revised 16 May 2018 Abstract Accepted 1 September 2018 Purpose – The purpose of this paper is to examine the blockchain as a trusted computing platform. Understanding the strengths and limitations of this platform is essential to execute large-scale real-world applications in blockchains. Design/methodology/approach – This paper proposes several modifications to conventional blockchain networks to improve the scale and scope of applications. Findings – Simple modifications to cryptographic protocols for constructing blockchain ledgers, and digital signatures for authentication of transactions, are sufficient to realize a scalable blockchain platform. Originality/value – The original contributions of this paper are concrete steps to overcome limitations of current blockchain networks. Keywords Cryptography, Blockchain, Scalability, Transactions, Blockchain networks Paper type Research paper 1. Introduction A blockchain broadcast network (Bozic et al., 2016; Croman et al., 2016; Nakamoto, 2008; Wood, 2014) is a mechanism for creating a distributed, tamper-proof, append-only ledger. Every participant in the broadcast network maintains a copy, or some representation, of the ledger. Ledger entries are made by consensus on the states of a process “executed” on the blockchain. As an example, in the Bitcoin (Nakamoto, 2008) process: (1) Bitcoin transactions transfer Bitcoins from a wallet to one or more other wallets. (2) Bitcoins created by “mining” are added to the miner’s wallet. -

IB Case Study Vocabulary a Local Economy Driven by Blockchain (2020) Websites
IB Case Study Vocabulary A local economy driven by blockchain (2020) Websites Merkle Tree: https://blockonomi.com/merkle-tree/ Blockchain: https://unwttng.com/what-is-a-blockchain Mining: https://www.buybitcoinworldwide.com/mining/ Attacks on Cryptocurrencies: https://blockgeeks.com/guides/hypothetical-attacks-on-cryptocurrencies/ Bitcoin Transaction Life Cycle: https://ducmanhphan.github.io/2018-12-18-Transaction-pool-in- blockchain/#transaction-pool 51 % attack - a potential attack on a blockchain network, where a single entity or organization can control the majority of the hash rate, potentially causing a network disruption. In such a scenario, the attacker would have enough mining power to intentionally exclude or modify the ordering of transactions. Block - records, which together form a blockchain. ... Blocks hold all the records of valid cryptocurrency transactions. They are hashed and encoded into a hash tree or Merkle tree. In the world of cryptocurrencies, blocks are like ledger pages while the whole record-keeping book is the blockchain. A block is a file that stores unalterable data related to the network. Blockchain - a data structure that holds transactional records and while ensuring security, transparency, and decentralization. You can also think of it as a chain or records stored in the forms of blocks which are controlled by no single authority. Block header – main way of identifying a block in a blockchain is via its block header hash. The block hash is responsible for block identification within a blockchain. In short, each block on the blockchain is identified by its block header hash. Each block is uniquely identified by a hash number that is obtained by double hashing the block header with the SHA256 algorithm. -

Lowest Common Ancestors in Trees and Directed Acyclic Graphs1
Lowest Common Ancestors in Trees and Directed Acyclic Graphs1 Michael A. Bender2 3 Martín Farach-Colton4 Giridhar Pemmasani2 Steven Skiena2 5 Pavel Sumazin6 Version: We study the problem of finding lowest common ancestors (LCA) in trees and directed acyclic graphs (DAGs). Specifically, we extend the LCA problem to DAGs and study the LCA variants that arise in this general setting. We begin with a clear exposition of Berkman and Vishkin’s simple optimal algorithm for LCA in trees. The ideas presented are not novel theoretical contributions, but they lay the foundation for our work on LCA problems in DAGs. We present an algorithm that finds all-pairs-representative : LCA in DAGs in O~(n2 688 ) operations, provide a transitive-closure lower bound for the all-pairs-representative-LCA problem, and develop an LCA-existence algorithm that preprocesses the DAG in transitive-closure time. We also present a suboptimal but practical O(n3) algorithm for all-pairs-representative LCA in DAGs that uses ideas from the optimal algorithms in trees and DAGs. Our results reveal a close relationship between the LCA, all-pairs-shortest-path, and transitive-closure problems. We conclude the paper with a short experimental study of LCA algorithms in trees and DAGs. Our experiments and source code demonstrate the elegance of the preprocessing-query algorithms for LCA in trees. We show that for most trees the suboptimal Θ(n log n)-preprocessing Θ(1)-query algorithm should be preferred, and demonstrate that our proposed O(n3) algorithm for all- pairs-representative LCA in DAGs performs well in both low and high density DAGs.