File Naming Convention for Time Sequence Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Integrated Voice Evacuation System Vx-3000 Series
SETTING SOFTWARE INSTRUCTIONS For Authorized Advanced End User INTEGRATED VOICE EVACUATION SYSTEM VX-3000 SERIES Tip In this manual, the VX-3004F/3008F/3016F Voice Evacuation Frames are collectively referred to as "VX-3000F." Thank you for purchasing TOA’s Integrated Voice Evacuation System. Please carefully follow the instructions in this manual to ensure long, trouble-free use of your equipment. TABLE OF CONTENTS 1. SOFTWARE OUTLINE ................................................................................... 3 2. NOTES ON PERFORMING SETTINGS .............................................. 3 2.1. System Requirements .......................................................................................... 3 2.2. Notes .................................................................................................................... 3 3. SOFTWARE SETUP ........................................................................................ 4 3.1. Setting Software Installation ................................................................................. 4 3.2. Uninstallation ....................................................................................................... 6 4. STARTING THE VX-3000 SETTING SOFTWARE ....................... 7 5. SETTING ITEMS ................................................................................................ 8 5.1. Setting Item Button Configuration ........................................................................ 8 5.2. Menu Bar ............................................................................................................. -

Wikipedia: Design of the FAT File System
Design of the FAT file system A FAT file system is a specific type of computer file system architecture and FAT a family of industry-standard file systems utilizing it. Developer(s) Microsoft, SCP, IBM, [3] The FAT file system is a legacy file system which is simple and robust. It Compaq, Digital offers good performance even in very light-weight implementations, but Research, Novell, cannot deliver the same performance, reliability and scalability as some Caldera modern file systems. It is, however, supported for compatibility reasons by Full name File Allocation Table: nearly all currently developed operating systems for personal computers and FAT12 (12- many home computers, mobile devices and embedded systems, and thus is a bit version), well suited format for data exchange between computers and devices of almost FAT16 (16- any type and age from 1981 through the present. bit versions), Originally designed in 1977 for use on floppy disks, FAT was soon adapted and FAT32 (32-bit version used almost universally on hard disks throughout the DOS and Windows 9x with 28 bits used), eras for two decades. Today, FAT file systems are still commonly found on exFAT (64- floppy disks, USB sticks, flash and other solid-state memory cards and bit versions) modules, and many portable and embedded devices. DCF implements FAT as Introduced 1977 (Standalone the standard file system for digital cameras since 1998.[4] FAT is also utilized Disk BASIC-80) for the EFI system partition (partition type 0xEF) in the boot stage of EFI- FAT12: August 1980 compliant computers. (SCP QDOS) FAT16: August 1984 For floppy disks, FAT has been standardized as ECMA-107[5] and (IBM PC DOS 3.0) ISO/IEC 9293:1994[6] (superseding ISO 9293:1987[7]). -

List of MS-DOS Commands - Wikipedia, the Free Encyclopedia Page 1 of 25
List of MS-DOS commands - Wikipedia, the free encyclopedia Page 1 of 25 List of MS-DOS commands From Wikipedia, the free encyclopedia In the personal computer operating systems MS -DOS and PC DOS, a number of standard system commands were provided for common Contents tasks such as listing files on a disk or moving files. Some commands were built-in to the command interpreter, others existed as transient ■ 1 Resident and transient commands commands loaded into memory when required. ■ 2 Command line arguments Over the several generations of MS-DOS, ■ 3 Windows command prompt commands were added for the additional ■ 4 Commands functions of the operating system. In the current ■ 4.1 @ Microsoft Windows operating system a text- ■ 4.2 : mode command prompt window can still be ■ 4.3 ; used. Some DOS commands carry out functions ■ 4.4 /* equivalent to those in a UNIX system but ■ 4.5 ( ) always with differences in details of the ■ 4.6 append function. ■ 4.7 assign ■ 4.8 attrib ■ 4.9 backup and restore Resident and transient ■ 4.10 BASIC and BASICA commands ■ 4.11 call ■ 4.12 cd or chdir ■ 4.13 chcp The command interpreter for MS-DOS runs ■ 4.14 chkdsk when no application programs are running. ■ 4.15 choice When an application exits, if the command ■ 4.16 cls interpreter in memory was overwritten, MS- ■ 4.17 copy DOS will re-load it from disk. The command ■ 4.18 ctty interpreter is usually stored in a file called ■ 4.19 defrag "COMMAND.COM". Some commands are ■ 4.20 del or erase internal and built-into COMMAND.COM, ■ 4.21 deltree others are stored on disk in the same way as ■ 4.22 dir application programs. -

Secrets of Powershell Remoting
Secrets of PowerShell Remoting The DevOps Collective, Inc. This book is for sale at http://leanpub.com/secretsofpowershellremoting This version was published on 2018-10-28 This is a Leanpub book. Leanpub empowers authors and publishers with the Lean Publishing process. Lean Publishing is the act of publishing an in-progress ebook using lightweight tools and many iterations to get reader feedback, pivot until you have the right book and build traction once you do. © 2016 - 2018 The DevOps Collective, Inc. Also By The DevOps Collective, Inc. Creating HTML Reports in Windows PowerShell A Unix Person’s Guide to PowerShell The Big Book of PowerShell Error Handling DevOps: The Ops Perspective Ditch Excel: Making Historical and Trend Reports in PowerShell The Big Book of PowerShell Gotchas The Monad Manifesto, Annotated Why PowerShell? Windows PowerShell Networking Guide The PowerShell + DevOps Global Summit Manual for Summiteers Why PowerShell? (Spanish) Secrets of PowerShell Remoting (Spanish) DevOps: The Ops Perspective (Spanish) The Monad Manifesto: Annotated (Spanish) Creating HTML Reports in PowerShell (Spanish) The Big Book of PowerShell Gotchas (Spanish) The Big Book of PowerShell Error Handling (Spanish) DevOps: WTF? PowerShell.org: History of a Community Contents Secrets of PowerShell Remoting ..................................... 1 Remoting Basics ................................................ 3 What is Remoting? ............................................ 3 Examining Remoting Architecture .................................. 3 Enabling -

Luno Tools Run Command Documentation Page 1/6
Luno Tools Run Command documentation Page 1/6 Luno Tools Run Command Description Run Command aims to be a user-friendly way to run command line applications, command line system calls and single line shell scripts. Setup 1. Build a working command outside Switch It is important to start with a command which achieves your task and which needs to work outside Switch. On Mac, this means you build and test the command in the Terminal App. On Windows, you build the command in “Command Prompt” (Cmd.exe) or “Windows Powershell”. By example, we can build a command which retrieves the permissions of one file and stores it in another file. On mac we can achieve this using the following command: ls -l /path/to/inputfile.txt > /path/to/outputfolder/filename.txt And on Windows Command Prompt using this command : icacls -l C:\path\to\inputfile.txt > C:\path\to\outputfolder\filename.txt If you have issues with your command at this stage (you don’t achieve the output you want, you have errors, …), then the issue is not related to the “Run Command” app itself. The people with the most knowledge about your issue are the people who are expert at the command line application, command line system call or shell script you are trying to use. Usually, there are help pages, support forums, support people specific for these applications who can help you. Alternatively, you can also ask help on the Enfocus forums. 2. Handle spaces correctly When working with these kinds of commands a space is used to separate different parts of the command, by example a space is placed between the command name and the path to the inputfile. -

Chronosync Manual for Macos
ChronoSync Manual for macOS Econ Technologies, Inc. P.O. Box 195780 Winter Springs, FL 32719 www.econtechnologies.com copyright 2002-2018 If you can’t find the information you’re looking for in this manual, you should also refer to ChronoSync’s Help, located within the application, and our website in the Guides, Tech Notes, and Documentation sections. TABLE OF CONTENTS CHAPTER ONE.................................................................................................................. 8 Introduction .................................................................................................................................................. 8 Welcome to ChronoSync ........................................................................................................................... 9 CHAPTER TWO ............................................................................................................... 10 Basic Overview .......................................................................................................................................... 10 ChronoSync Documents .......................................................................................................................... 11 Synchronizer Tasks ............................................................................................................................. 11 Task Container .................................................................................................................................... 11 ChronoSync Organizer -

Macintosh Library Modules Release 2.4.1
Macintosh Library Modules Release 2.4.1 Guido van Rossum Fred L. Drake, Jr., editor 30 March 2005 Python Software Foundation Email: [email protected] Copyright c 2001-2004 Python Software Foundation. All rights reserved. Copyright c 2000 BeOpen.com. All rights reserved. Copyright c 1995-2000 Corporation for National Research Initiatives. All rights reserved. Copyright c 1991-1995 Stichting Mathematisch Centrum. All rights reserved. See the end of this document for complete license and permissions information. Abstract This library reference manual documents Python’s extensions for the Macintosh. It should be used in conjunction with the Python Library Reference, which documents the standard library and built-in types. This manual assumes basic knowledge about the Python language. For an informal introduction to Python, see the Python Tutorial; the Python Reference Manual remains the highest authority on syntactic and semantic questions. Finally, the manual entitled Extending and Embedding the Python Interpreter describes how to add new extensions to Python and how to embed it in other applications. CONTENTS 1 Using Python on a Macintosh 1 1.1 Getting and Installing MacPython .................................. 1 1.2 The IDE ............................................... 2 1.3 The Package Manager ........................................ 3 2 MacPython Modules 5 2.1 macpath — MacOS path manipulation functions ......................... 5 2.2 macfs — Various file system services ............................... 5 2.3 ic — Access to Internet Config ................................... 8 2.4 MacOS — Access to Mac OS interpreter features .......................... 9 2.5 macostools — Convenience routines for file manipulation ................... 10 2.6 findertools — The finder’s Apple Events interface ...................... 10 2.7 EasyDialogs — Basic Macintosh dialogs ............................ 11 2.8 FrameWork — Interactive application framework ........................ -
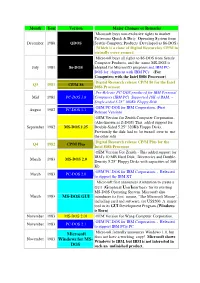
Microsoft Windows for MS
Month Year Version Major Changes or Remarks Microsoft buys non-exclusive rights to market Pattersons Quick & Dirty Operating System from December 1980 QDOS Seattle Computer Products (Developed as 86-DOS) (Which is a clone of Digital Researches C P/M in virtually every respect) Microsoft buys all rights to 86-DOS from Seattle Computer Products, and the name MS-DOS is July 1981 86-DOS adopted for Microsoft's purposes and IBM PC- DOS for shipment with IBM PCs (For Computers with the Intel 8086 Processor) Digital Research release CP/M 86 for the Intel Q3 1981 CP/M 86 8086 Processer Pre-Release PC-DOS produced for IBM Personal Mid 1981 PC-DOS 1.0 Computers (IBM PC) Supported 16K of RAM, ~ Single-sided 5.25" 160Kb Floppy Disk OEM PC-DOS for IBM Corporation. (First August 1982 PC-DOS 1.1 Release Version) OEM Version for Zenith Computer Corporation.. (Also known as Z-DOS) This added support for September 1982 MS-DOS 1.25 Double-Sided 5.25" 320Kb Floppy Disks. Previously the disk had to be turned over to use the other side Digital Research release CP/M Plus for the Q4 1982 CP/M Plus Intel 8086 Processer OEM Version For Zenith - This added support for IBM's 10 MB Hard Disk, Directories and Double- March 1983 MS-DOS 2.0 Density 5.25" Floppy Disks with capacities of 360 Kb OEM PC-DOS for IBM Corporation. - Released March 1983 PC-DOS 2.0 to support the IBM XT Microsoft first announces it intention to create a GUI (Graphical User Interface) for its existing MS-DOS Operating System. -

Drive Investigation
Mag. iur. Dr. techn. Michael Sonntag Drive investigation Institute for Information Processing and Microprocessor Technology (FIM) Johannes Kepler University Linz, Austria E-Mail: [email protected] http://www.fim.uni-linz.ac.at/staff/sonntag.htm © Michael Sonntag 2011 Agenda Install the software: ImDisk Cygwin Scenario Optional (can be run from CD): WinHex, HxD Search for deleted files and reconstruct them WinHex: Deleted file (FAT) Reconstruct: If possible Discovering hidden files: Wrong extension Cygwin: "file" command Windows ADS LADS – Find the picture hidden in an ADS Timestamps WinHex: Analyze timestamps and convert them Running time of your Windows computer Analyze the event log Michael Sonntag Drive investigation 2 Images Source of images: http://dftt.sourceforge.net/ 6-undel-fat.zip » FAT image 8-jpeg-search.zip » NTFS image 5-fat-daylight.zip » FAT image Requirements: Operating System: Windows (XP, Vista; NT, 2K, 7: ???) Harddisk space: » Scenarios: 17 MB » Cygwin: A lot; approx. 700 MB! » Other software: A few MB Michael Sonntag Drive investigation 3 Software installation ImDisk: Mounting a disk image as a drive under Windows Requires Administrator access and a reboot Procedure: » Install software » Set service start to “Automatic” » Reboot the computer Install "Winhex" Not really needed; can be run directly from CD! » Copy to harddisk for faster start if desired Install "HxD" Not really needed; can be run directly from CD! Michael Sonntag Drive investigation 4 Software installation Install "Cygwin" Linux-like environment (and programs) under windows Procedure: » Execute "setup.exe" and choose to install from local path – Select the subdirectory starting with "ftp…" in it as install source » E.g.: “E:\Software\Source” – No spaces in the path of destination directory E.g. -

File Allocation Table - Wikipedia, the Free Encyclopedia Page 1 of 22
File Allocation Table - Wikipedia, the free encyclopedia Page 1 of 22 File Allocation Table From Wikipedia, the free encyclopedia File Allocation Table (FAT) is a file system developed by Microsoft for MS-DOS and is the primary file system for consumer versions of Microsoft Windows up to and including Windows Me. FAT as it applies to flexible/floppy and optical disc cartridges (FAT12 and FAT16 without long filename support) has been standardized as ECMA-107 and ISO/IEC 9293. The file system is partially patented. The FAT file system is relatively uncomplicated, and is supported by virtually all existing operating systems for personal computers. This ubiquity makes it an ideal format for floppy disks and solid-state memory cards, and a convenient way of sharing data between disparate operating systems installed on the same computer (a dual boot environment). The most common implementations have a serious drawback in that when files are deleted and new files written to the media, directory fragments tend to become scattered over the entire disk, making reading and writing a slow process. Defragmentation is one solution to this, but is often a lengthy process in itself and has to be performed regularly to keep the FAT file system clean. Defragmentation should not be performed on solid-state memory cards since they wear down eventually. Contents 1 History 1.1 FAT12 1.2 Directories 1.3 Initial FAT16 1.4 Extended partition and logical drives 1.5 Final FAT16 1.6 Long File Names (VFAT, LFNs) 1.7 FAT32 1.8 Fragmentation 1.9 Third party -

Azure RTOS Filex User Guide
Azure RTOS FileX User Guide Published: February 2020 For the latest information, please see azure.com/rtos This document is provided “as-is.” Information and views expressed in this document, including URL and other Internet Web site references, may change without notice. This document does not provide you with any legal rights to any intellectual property in any Microsoft product. You may copy and use this document for your internal, reference purposes. © 2020 Microsoft. All rights reserved. Microsoft Azure RTOS, Azure RTOS FileX, Azure RTOS GUIX, Azure RTOS GUIX Studio, Azure RTOS NetX, Azure RTOS NetX Duo, Azure RTOS ThreadX, Azure RTOS TraceX, Azure RTOS Trace, event-chaining, picokernel, and preemption-threshold are trademarks of the Microsoft group of companies. All other trademarks are property of their respective owners. Safety Certifications IEC 61508 up to SIL 4 IEC 62304 up to SW safety Class C ISO 26262 ASIL D EN 50128 SW-SIL 4 UL/IEC 60730, UL/IEC 60335, UL 1998 MISRA-C:2004 Compliant MISRA C:2012 Compliant Part Number: 000-1001 Revision 6.0 Contents About This Guide 7 • Organization 7 • Guide Conventions 8 • FileX Data Types 9 • Customer Support Center 10 Chapter 1: Introduction to FileX 13 • FileX Unique Features 14 • Safety Certifications 15 • Powerful Services of FileX 17 • Easy-to-use API 18 • exFAT Support 18 • Fault Tolerant Support 19 • Callback Functions 21 • Easy Integration 21 Chapter 2: Installation and Use of FileX 23 • Host Considerations 24 • Target Considerations 25 • Product Distribution 25 • FileX Installation -

FAT32 File Structure Prof
FAT32 File Structure Prof. James L. Frankel Harvard University Version of 9:45 PM 24-Mar-2021 Copyright © 2021 James L. Frankel. All rights reserved. FAT32 Source Documentation • The reference document you should use is the Microsoft Extensible Firmware Initiative FAT32 File System Specification • On class web site under The NXP/Freescale ARM -> microSDHC Card • It is available on the class web site at https://cscie92.dce.harvard.edu/spring2021/Microsoft%20Extensible%20Firmware%20Initiative%20FAT32%2 0File%20System%20Specification,%20Version%201.03,%2020001206.pdf under Online Papers Used in Class • Important correction to this document concerns the DIR_CrtTimeTenth field in the FAT 32 Byte Directory Entry Structure • The name and description of this field is incorrect • Instead of DIR_CrtTimeTenth, we will use the name DIR_CrtTimeHundth • Here is the correct description of this field (to update the text on page 23): • Hundredths of a second time at file creation time. This field contains a count of hundredths of a second. Because the seconds portion of the DIR_CrtTime field denotes a creation time with a granularity of 2 seconds, this field contains a number of hundredths of a second (0 to 199, inclusively) that denotes a number of seconds from 0 to 1.99, inclusively, that may increment the number of seconds in addition to supplying the number of hundredths of a second. • There is also a typo on page 25 where a field is referred to as DIR_CrtTimeMil (which does not exist), and, as corrected here, should be DIR_CrtTimeHundth 2 SD Documentation • Documentation for the SD controller in the K70 • K70 Sub-Family Reference Manual, Rev.