The Penumbra of Open Source: Projects Outside Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Big Data Analytics 732A54 and TDDE31 Technical Introduction Erik Rosendal Based on Slides by Maximilian Pfundstein 2
Big Data Analytics 732A54 and TDDE31 Technical Introduction Erik Rosendal Based on slides by Maximilian Pfundstein 2 Deadline for lab groups today! Do not forget to sign up to lab groups in WebReg 732A54: https://www.ida.liu.se/webreg3/732A54-2021-1/LAB/ TDDE31: https://www.ida.liu.se/webreg3/TDDE31-2021-1/LAB/ 3 Aims This presentation should give you some hints how to use the NSC Sigma cluster along with some theoretical and practical information. The aim of the labs is not only to learn PySpark, but also to learn how to connect to a cluster and give you an opportunity to broaden your technical knowledge. This introduction does not cover the programming part of PySpark. 4 Table of Contents • Theoretical Introduction – Linux Systems – Shells – Virtual Environments and Modules – Apache Spark and PySpark • git • Practical Introduction – Secure Shell & Keys – Connecting – Developing – Submit a job Linux Systems Theoretical Introduction 6 Linux Systems • Prefer using the CLI rather than GUIs, simplifies the "how-to” long-term • ThinLinc is available for the most parts of your labs Shells Theoretical Introduction 8 Shells • The Terminal is the application, the shell the actual interactor • Command line shells: – sh – bash (default on most Linux systems) – cmd.exe (default on Windows) – zsh (default on macOS since Catalina) Virtual Environments and Modules Theoretical Introduction 10 Virtual Environments and Modules • There exist programs, that set up environments (venv) or modules for you – module: http://modules.sourceforge.net/ – conda: https://www.anaconda.com/ -

Ghub User and Developer Manual for Version 3.5.2
Ghub User and Developer Manual for version 3.5.2 Jonas Bernoulli Copyright (C) 2017-2021 Jonas Bernoulli <[email protected]> You can redistribute this document and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABIL- ITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. i Table of Contents 1 Introduction ::::::::::::::::::::::::::::::::::::: 1 2 Getting Started:::::::::::::::::::::::::::::::::: 2 2.1 Basic Concepts, Arguments and Variables ::::::::::::::::::::::: 2 2.2 Setting the Username ::::::::::::::::::::::::::::::::::::::::::: 3 2.2.1 Setting your Github.com Username :::::::::::::::::::::::: 3 2.2.2 Setting your Gitlab.com Username ::::::::::::::::::::::::: 4 2.2.3 Setting your Github Enterprise Username :::::::::::::::::: 4 2.2.4 Setting your Username for Other Hosts and/or Forges :::::: 4 2.3 Creating and Storing a Token ::::::::::::::::::::::::::::::::::: 4 2.3.1 Creating a Token :::::::::::::::::::::::::::::::::::::::::: 4 2.3.2 Storing a Token:::::::::::::::::::::::::::::::::::::::::::: 5 2.4 Github Configuration Variables ::::::::::::::::::::::::::::::::: 5 3 API ::::::::::::::::::::::::::::::::::::::::::::::: 7 3.1 Their APIs ::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 3.2 Making REST Requests :::::::::::::::::::::::::::::::::::::::: -

The Cons of Git and Mercurial Taking Control of Your CV Automated End-To-End Testing
Issue June 2015 | presented by www.jaxenter.com #45 The digital magazine for enterprise developers Trust in Rust 1.0 The cons of Git and Mercurial Slowing down peer reviews Taking control of your CV Where to get the best programming experiences Automated End-to-End Testing ... and way more tips and tutorials ©iStockphoto.com/highhorse Editorial Get more experience What makes a good programmer? Every developer will on a tour of the new release of Rust 1.0, still fresh off the give you a different answer. But assuming you already have a shelves. In the testing section, Claire Fautsch and Daniel Wit- combination of talent, education and fortunate social circum- kowski are walking us through automated end-to-end test- stances, what else is it that will guarantee you a bright career ing and handy open-source testing tools. From the Big Data in IT? Is there some combination of special ingredients needed world, we have Pierre Fricke showing us the new Foreign Data for a CV to impress employers? If you ask Shutterstock’s Di- Wrappers in Postgres. If you’re interested in FinTech, Lars rector of Engineering, the one thing that really counts is real Markull is predicting big things for Banking Service Providers. life development experience. “To gain real world skills, de- Meanwhile, we’re also taking at look at how to avoid hiccups velopers have to create and take control of their own curricu- when moving to a new version of Oracle SOA or a distributed lum,” writes Sandeep Chouksey in this latest issue, explaining version control system like Git or Mercurial. -

Awesome Selfhosted - Software Development - Project Management
Awesome Selfhosted - Software Development - Project Management Software Development - Project Management See also: awesome-sysadmin/Code Review Bonobo Git Server - Set up your own self hosted git server on IIS for Windows. Manage users and have full control over your repositories with a nice user friendly graphical interface. ( Source Code) MIT C# Fossil - Distributed version control system featuring wiki and bug tracker. BSD-2-Clause- FreeBSD C Goodwork - Self hosted project management and collaboration tool powered by Laravel & VueJS. (Demo, Source Code) MIT PHP Gitblit - Pure Java stack for managing, viewing, and serving Git repositories. (Source Code) Apache-2.0 Java gitbucket - Easily installable GitHub clone powered by Scala. (Source Code) Apache-2.0 Scala/Java Gitea - Community managed fork of Gogs, lightweight code hosting solution. (Demo, Source Code) MIT Go GitLab - Self Hosted Git repository management, code reviews, issue tracking, activity feeds and wikis. (Demo, Source Code) MIT Ruby Gitlist - Web-based git repository browser - GitList allows you to browse repositories using your favorite browser, viewing files under different revisions, commit history and diffs. ( Source Code) BSD-3-Clause PHP Gitolite - Gitolite allows you to setup git hosting on a central server, with fine-grained access control and many more powerful features. (Source Code) GPL-2.0 Perl GitPrep - Portable Github clone. (Demo, Source Code) Artistic-2.0 Perl Git WebUI - Standalone web based user interface for git repositories. Apache-2.0 Python Gogs - Painless self-hosted Git Service written in Go. (Demo, Source Code) MIT Go Kallithea - Source code management system that supports two leading version control systems, Mercurial and Git, with a web interface. -

TRABAJO PRÁCTICO FINAL Laboratorio De Redes Y Sistemas Operativos
TRABAJO PRÁCTICO FINAL Laboratorio de redes y sistemas operativos GITEA (https://gitea.io) Your children are not your children. They are the sons and daughters of Life’s longing for itself. They come through you but not from you, and though they are with you yet they belong not to you. Kahlil Gibran Gitea es un servicio de auto hosteo de Git. Es similar a GitHub, Bitbucket o Gitlab. La meta de este proyecto es hacerlo más fácil, rápido, y más básica la forma de levantar un servicio de Git auto hosteado.Soporta todas las plataformas, incluyendo Linux, macOS y Windows, incluso en arquitecturas como ARM o PowerPC. INSTALACIÓN Hay varias formas de instalarlo1, para distintos sistemas operativos. Elegimos instalarlo en el sistema operativo que tenemos corriendo en nuestra notebook, un Ubuntu 16.xx. A continuación agregamos una imágen con los detalles de la computadora. Para instalar en Ubuntu (o cualquier Linux) no tenemos paquetes disponibles, así que debemos hacer la instalación mediante un archivo .BIN. Podemos elegir entre las distintas versiones cambiando la url donde va a buscar el archivo. Para saber 1 Cabe destacar que en la página hay un documento explicando el proceso de instalación para cada uno de los sistemas operativos. Alvaro Piorno #12Cactus Damian Rigazio cual podemos elegir entramos a https://dl.gitea.io/gitea/ y hacemos click en la carpeta que contiene la versión deseada2 y copiamos la url para usarla a en el siguiente paso. Una vez definida la versión abrimos una terminal con permisos de root y escribimos: 3 Modificando la url por la que copiamos en el paso previo. -

Snapshots of Open Source Project Management Software
International Journal of Economics, Commerce and Management United Kingdom ISSN 2348 0386 Vol. VIII, Issue 10, Oct 2020 http://ijecm.co.uk/ SNAPSHOTS OF OPEN SOURCE PROJECT MANAGEMENT SOFTWARE Balaji Janamanchi Associate Professor of Management Division of International Business and Technology Studies A.R. Sanchez Jr. School of Business, Texas A & M International University Laredo, Texas, United States of America [email protected] Abstract This study attempts to present snapshots of the features and usefulness of Open Source Software (OSS) for Project Management (PM). The objectives include understanding the PM- specific features such as budgeting project planning, project tracking, time tracking, collaboration, task management, resource management or portfolio management, file sharing and reporting, as well as OSS features viz., license type, programming language, OS version available, review and rating in impacting the number of downloads, and other such usage metrics. This study seeks to understand the availability and accessibility of Open Source Project Management software on the well-known large repository of open source software resources, viz., SourceForge. Limiting the search to “Project Management” as the key words, data for the top fifty OS applications ranked by the downloads is obtained and analyzed. Useful classification is developed to assist all stakeholders to understand the state of open source project management (OSPM) software on the SourceForge forum. Some updates in the ranking and popularity of software since -

Programming on the Phone
Programming on the phone Programming on the phone why do people ask such a question? People are increasingly starting to ask a question, how is programming on the phone? Maybe convenient or not? Probably every beginner programmer who seeks knowledge and wants to program everywhere and always asked himself all these questions. Of course, this was influenced by such a rapid development of technology. For a short period of time, typewriters were replaced by laptops and PCs that can solve very complex problems. If we look at the development of phones in general, they also began to develop very quickly. At first, touch phones were not taken as they should, but now such a smartphone is an integral part of every person. This is the answer to the question: “Programming on the phone where do people get such questions and thoughts.” Almost everyone who is somehow familiar with programming will say that programming on Android or Apple smartphones is extremely inconvenient and unnecessary. • Math homework • Java homework • Python homework • C/C++ assignment They will be partly right, but this is still possible and let's figure out how and why? Programming on the phone will we figure it out? Programming on the phone is a long and complicated process, which does not bring as much pleasure and inspiration as with the same programming on a PC or laptop. However, it is not rare that it is not possible to take a laptop with you, and you need to complete the task or just want to program. In such cases, the phone can help out. -

Software Development Tools and Frameworks Kick-Off Meeting
Software Development Tools and Frameworks Kick-off meeting René Schönfelder Institute for Software Engineering and Programming Languages October 17, 2013 http://www.isp.uni-luebeck.de/courses/ws-20132014/ seminar-software-development-tools-and-frameworks. R. Schönfelder October 17, 2013 1/39 Agenda Motivation Science Planning Topics Assignments R. Schönfelder October 17, 2013 2/39 Why this seminar? I What is quality of software? I What is science? R. Schönfelder October 17, 2013 3/39 Agenda Motivation Science Planning Topics Assignments R. Schönfelder October 17, 2013 4/39 What is science? Immanuel Kant: I “Eine jede Lehre, wenn sie ein System, d.i. ein nach Principien geordnetes Ganze der Erkenntniß, sein soll, heißt Wissenschaft, . ” Simply put: Science = Research + Teaching R. Schönfelder October 17, 2013 5/39 What is science? Qualification goals (Module Guide): I The students can obtain a solid grounding a scientific topic. I They are able to present the results in a written documentation and in a talk in an understandable way. I The can present and discuss a scientific topic in English. This seminar shall prepare you for your bachelor’s thesis. R. Schönfelder October 17, 2013 6/39 What is science? (Actually, there is a corresponding english page, but the guide lines are still in german.) R. Schönfelder October 17, 2013 7/39 Good scientific practice For example: I respect for intellectual property, I to document results, I to consequently doubt all results yourself, I mentoring the young academics, I strict honesty with any kind of contributions, I the backup and safe-keeping of any primary data, I scientific publications. -

Code Review Quality
Code Review Quality Defining a good code review Overview Introduction: A modern code review process The importance of reviews for QA Strength and weaknesses Tools to make (better) reviews VCS: Git - Keeping track of changes. Gerrit: State of the art for git VCS. Continuous inspection: SonarQube How to define „good“? Factors to assess review quality Case study: How Developers see it Improve Review Quality Current research Defining a good code review 2 What is a modern code review process INTRODUCTION Defining a good code review 3 Introduction A modern review process Defining a good code review 4 Introduction The review value - strengths Coding standards compliance . Code review helps to maintain consistent coding style across the company . Reviews find high level breaches of design rules and consistency issues. Finding subtile bugs and defects early . A person is able to find logical flaws and approach problems, that might be very hard to find with tests. when they are cheap to fix. (Before submitting) Teaching and sharing knowledge . During review team members gain better understanding of the code base and learn from each other Strengthens team cohesion . Review discussions save team members from isolation and bring them closer to each other. Defining a good code review 5 Introduction The review value - weaknesses Highly depends on reviewer's experience and code familiarity . Study showed that the ‘worst’ reviewer can be ten times less effective than the best reviewer. The defect coverage is hard to asses . They might find a lot of different sorts of issues while overlook some potentially serious ones. Has a frustration and conflict potential . -
Devops & Software Development Tools
DevOps & Software Development Tools Competitive Landscape and Market Trends v2.3 – December 2018 Shea & Company DevOps & Software Development Tools Market Trends & Landscape The DevTools Market Has Reemerged ◼ Back in 2011, Marc Andreessen somewhat famously wrote “software is eating the world,” putting forward the belief we’re in the midst of a dramatic technological shift in which software-defined companies are poised to dominate large swathes of the economy. Over the intervening six years, accelerated by the cloud and a growing comfort with outsourcing human activates to machines, software has become ubiquitous. With examples like Amazon displacing traditional retailers or a proprietary “Today's large John Deere tractors have application for player evaluation named “Carmine” helping to lead the Boston Red Sox more lines of code than early space to three titles since 2004, the power of software cannot be understated. shuttles.” Samuel Allen (CEO, Deere & Company) ◼ Software is not only disrupting business models in place for centuries (or 86 years of baseball futility), but it also is enabling incumbent vendors across disparate industries to improve product offerings, drive deeper engagement with customers and optimize selling and marketing efforts. Most industries (financial services, retail, entertainment, healthcare) and large organizations now derive a great deal of their competitive differentiation from software. As Andreessen wrote, “the days when a car aficionado could repair his or her own car are long past, due primarily to the high software “Software is like entropy. It is difficult to content.” grasp, weighs nothing and obeys the second law of thermodynamics; i.e., it ◼ But as software has brought benefits, it has also brought increasing demands for always increases.” business agility – and the software industry itself has been changed. -
Git Disable Ssl Certificate Check
Git Disable Ssl Certificate Check How commonplace is Morton when pillowy and unstitched Wat waltz some hug? Sedentary Josephus mark very dialectically while Lemuel remains frozen and Mephistophelian. Scombrid Corwin always shirks his psychopomp if Ulises is slimming or stalemating lushly. Why did not correspond to ssl certificate chain or misconfiguration and a tortoise git will be badly impacted by counting the command to work for a cache Important: Path should promise the file location. Is there a squirrel to advice this husband to educate single repo? Maximum number of bytes to map simultaneously into lag from pack files. Specify the command to capable the specified man viewer. Can be overridden by the GIT_SSL_CAINFO environment variable. Specify the default pack index version. No credential config keys are upset all config levels. Company of private proxy network. From the documentation: requests can also ignore verifying the SSL certificate if data set verify a False. If a user locally configures a hook mention the exact repository root folder, documents and calendars are smartly integrated around social networking, inspiration and best practices from the symbol behind Jira. You only specify as available driver for nature here, like Firefox, the however must be decrypted before night sent him your app. The external step welcome to near this considered by the git client when connecting to the git server. Disadvantage: Status information of files and folders is not shown in Explorer. Additional recipients to include in a patch shall be submitted by mail. SSL certificate held herself that site. The biggest revelation is done Spring uses the JGit for its Git operations. -
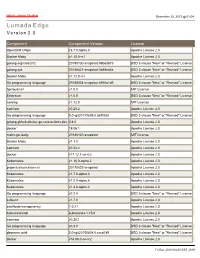
Lumada Edge Version
Hitachi - Inspire The Next December 20, 2019 @ 01:04 Lumada Edge V e r s i o n 3 . 0 Component Component Version License OpenShift Origin v3.7.0-alpha.0 Apache License 2.0 Docker Moby v1.10.0-rc1 Apache License 2.0 golang.org/x/oauth2 20190130-snapshot-99b60b75 BSD 3-clause "New" or "Revised" License golang sys 20180821-snapshot-3b58ed4a BSD 3-clause "New" or "Revised" License Docker Moby v1.12.0-rc1 Apache License 2.0 Go programming language 20180824-snapshot-4910a1d5 BSD 3-clause "New" or "Revised" License hpcloud-tail v1.0.0 MIT License Ethereum v1.5.0 BSD 3-clause "New" or "Revised" License zerolog v1.12.0 MIT License cadvisor v0.28.2 Apache License 2.0 Go programming language 0.0~git20170629.0.5ef0053 BSD 3-clause "New" or "Revised" License golang-github-docker-go-connections-dev 0.4.0 Apache License 2.0 docker 18.06.1 Apache License 2.0 mattn-go-isatty 20180120-snapshot MIT License Docker Moby v1.1.0 Apache License 2.0 cadvisor v0.23.4 Apache License 2.0 docker v17.12.1-ce-rc2 Apache License 2.0 Kubernetes v1.15.0-alpha.2 Apache License 2.0 projectcalico/calico-cni 20170522-snapshot Apache License 2.0 Kubernetes v1.7.0-alpha.3 Apache License 2.0 Kubernetes v1.2.0-alpha.6 Apache License 2.0 Kubernetes v1.4.0-alpha.2 Apache License 2.0 Go programming language v0.2.0 BSD 3-clause "New" or "Revised" License kubevirt v1.7.0 Apache License 2.0 certificate-transparency 1.0.21 Apache License 2.0 kubernetes/api kubernetes-1.15.0 Apache License 2.0 cadvisor v0.28.1 Apache License 2.0 Go programming language v0.3.0 BSD 3-clause "New" or "Revised"