Archiving Complex Digital Artworks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Big Data Analytics 732A54 and TDDE31 Technical Introduction Erik Rosendal Based on Slides by Maximilian Pfundstein 2
Big Data Analytics 732A54 and TDDE31 Technical Introduction Erik Rosendal Based on slides by Maximilian Pfundstein 2 Deadline for lab groups today! Do not forget to sign up to lab groups in WebReg 732A54: https://www.ida.liu.se/webreg3/732A54-2021-1/LAB/ TDDE31: https://www.ida.liu.se/webreg3/TDDE31-2021-1/LAB/ 3 Aims This presentation should give you some hints how to use the NSC Sigma cluster along with some theoretical and practical information. The aim of the labs is not only to learn PySpark, but also to learn how to connect to a cluster and give you an opportunity to broaden your technical knowledge. This introduction does not cover the programming part of PySpark. 4 Table of Contents • Theoretical Introduction – Linux Systems – Shells – Virtual Environments and Modules – Apache Spark and PySpark • git • Practical Introduction – Secure Shell & Keys – Connecting – Developing – Submit a job Linux Systems Theoretical Introduction 6 Linux Systems • Prefer using the CLI rather than GUIs, simplifies the "how-to” long-term • ThinLinc is available for the most parts of your labs Shells Theoretical Introduction 8 Shells • The Terminal is the application, the shell the actual interactor • Command line shells: – sh – bash (default on most Linux systems) – cmd.exe (default on Windows) – zsh (default on macOS since Catalina) Virtual Environments and Modules Theoretical Introduction 10 Virtual Environments and Modules • There exist programs, that set up environments (venv) or modules for you – module: http://modules.sourceforge.net/ – conda: https://www.anaconda.com/ -

Ghub User and Developer Manual for Version 3.5.2
Ghub User and Developer Manual for version 3.5.2 Jonas Bernoulli Copyright (C) 2017-2021 Jonas Bernoulli <[email protected]> You can redistribute this document and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABIL- ITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. i Table of Contents 1 Introduction ::::::::::::::::::::::::::::::::::::: 1 2 Getting Started:::::::::::::::::::::::::::::::::: 2 2.1 Basic Concepts, Arguments and Variables ::::::::::::::::::::::: 2 2.2 Setting the Username ::::::::::::::::::::::::::::::::::::::::::: 3 2.2.1 Setting your Github.com Username :::::::::::::::::::::::: 3 2.2.2 Setting your Gitlab.com Username ::::::::::::::::::::::::: 4 2.2.3 Setting your Github Enterprise Username :::::::::::::::::: 4 2.2.4 Setting your Username for Other Hosts and/or Forges :::::: 4 2.3 Creating and Storing a Token ::::::::::::::::::::::::::::::::::: 4 2.3.1 Creating a Token :::::::::::::::::::::::::::::::::::::::::: 4 2.3.2 Storing a Token:::::::::::::::::::::::::::::::::::::::::::: 5 2.4 Github Configuration Variables ::::::::::::::::::::::::::::::::: 5 3 API ::::::::::::::::::::::::::::::::::::::::::::::: 7 3.1 Their APIs ::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 3.2 Making REST Requests :::::::::::::::::::::::::::::::::::::::: -

Awesome Selfhosted - Software Development - Project Management
Awesome Selfhosted - Software Development - Project Management Software Development - Project Management See also: awesome-sysadmin/Code Review Bonobo Git Server - Set up your own self hosted git server on IIS for Windows. Manage users and have full control over your repositories with a nice user friendly graphical interface. ( Source Code) MIT C# Fossil - Distributed version control system featuring wiki and bug tracker. BSD-2-Clause- FreeBSD C Goodwork - Self hosted project management and collaboration tool powered by Laravel & VueJS. (Demo, Source Code) MIT PHP Gitblit - Pure Java stack for managing, viewing, and serving Git repositories. (Source Code) Apache-2.0 Java gitbucket - Easily installable GitHub clone powered by Scala. (Source Code) Apache-2.0 Scala/Java Gitea - Community managed fork of Gogs, lightweight code hosting solution. (Demo, Source Code) MIT Go GitLab - Self Hosted Git repository management, code reviews, issue tracking, activity feeds and wikis. (Demo, Source Code) MIT Ruby Gitlist - Web-based git repository browser - GitList allows you to browse repositories using your favorite browser, viewing files under different revisions, commit history and diffs. ( Source Code) BSD-3-Clause PHP Gitolite - Gitolite allows you to setup git hosting on a central server, with fine-grained access control and many more powerful features. (Source Code) GPL-2.0 Perl GitPrep - Portable Github clone. (Demo, Source Code) Artistic-2.0 Perl Git WebUI - Standalone web based user interface for git repositories. Apache-2.0 Python Gogs - Painless self-hosted Git Service written in Go. (Demo, Source Code) MIT Go Kallithea - Source code management system that supports two leading version control systems, Mercurial and Git, with a web interface. -

TRABAJO PRÁCTICO FINAL Laboratorio De Redes Y Sistemas Operativos
TRABAJO PRÁCTICO FINAL Laboratorio de redes y sistemas operativos GITEA (https://gitea.io) Your children are not your children. They are the sons and daughters of Life’s longing for itself. They come through you but not from you, and though they are with you yet they belong not to you. Kahlil Gibran Gitea es un servicio de auto hosteo de Git. Es similar a GitHub, Bitbucket o Gitlab. La meta de este proyecto es hacerlo más fácil, rápido, y más básica la forma de levantar un servicio de Git auto hosteado.Soporta todas las plataformas, incluyendo Linux, macOS y Windows, incluso en arquitecturas como ARM o PowerPC. INSTALACIÓN Hay varias formas de instalarlo1, para distintos sistemas operativos. Elegimos instalarlo en el sistema operativo que tenemos corriendo en nuestra notebook, un Ubuntu 16.xx. A continuación agregamos una imágen con los detalles de la computadora. Para instalar en Ubuntu (o cualquier Linux) no tenemos paquetes disponibles, así que debemos hacer la instalación mediante un archivo .BIN. Podemos elegir entre las distintas versiones cambiando la url donde va a buscar el archivo. Para saber 1 Cabe destacar que en la página hay un documento explicando el proceso de instalación para cada uno de los sistemas operativos. Alvaro Piorno #12Cactus Damian Rigazio cual podemos elegir entramos a https://dl.gitea.io/gitea/ y hacemos click en la carpeta que contiene la versión deseada2 y copiamos la url para usarla a en el siguiente paso. Una vez definida la versión abrimos una terminal con permisos de root y escribimos: 3 Modificando la url por la que copiamos en el paso previo. -

Snapshots of Open Source Project Management Software
International Journal of Economics, Commerce and Management United Kingdom ISSN 2348 0386 Vol. VIII, Issue 10, Oct 2020 http://ijecm.co.uk/ SNAPSHOTS OF OPEN SOURCE PROJECT MANAGEMENT SOFTWARE Balaji Janamanchi Associate Professor of Management Division of International Business and Technology Studies A.R. Sanchez Jr. School of Business, Texas A & M International University Laredo, Texas, United States of America [email protected] Abstract This study attempts to present snapshots of the features and usefulness of Open Source Software (OSS) for Project Management (PM). The objectives include understanding the PM- specific features such as budgeting project planning, project tracking, time tracking, collaboration, task management, resource management or portfolio management, file sharing and reporting, as well as OSS features viz., license type, programming language, OS version available, review and rating in impacting the number of downloads, and other such usage metrics. This study seeks to understand the availability and accessibility of Open Source Project Management software on the well-known large repository of open source software resources, viz., SourceForge. Limiting the search to “Project Management” as the key words, data for the top fifty OS applications ranked by the downloads is obtained and analyzed. Useful classification is developed to assist all stakeholders to understand the state of open source project management (OSPM) software on the SourceForge forum. Some updates in the ranking and popularity of software since -

GND Meets Wikibase 2 | 18 | Gndxwikibase | CLARIN | 03.09.2020
1 | 18 | GNDxWikibase | CLARIN | 03.09.2020 Barbara Fischer | Sarah Hartmann GND meets Wikibase 2 | 18 | GNDxWikibase | CLARIN | 03.09.2020 GND meets Wikibase - We want to make our free structured authority data easier accessible and interoperable - We are testing Wikibase on its functionality as toolkit for regulations Blog post 3 | 18 | GNDxWikibase | CLARIN | 03.09.2020 Gemeinsame Normdatei (GND) – authority file used by CHI (mainly libraries) in D-A-CH - 16 mio identifiers referring to persons, (names of persons), corporate bodies, conferences, geographic names, subject headings, works – run cooperativley by GND agencies - active user: ~1.000 institutions – Open data (CC0), APIs and documentation – opening up to GLAM, science and others - the handy tool of librarians has to evolve into a cross domain tool: organization; data model; infrastructure & community building 4 | 18 | GNDxWikibase | CLARIN | 03.09.2020 On Wikibase - Open source on behalf of the Wikimedia Foundation - Developed by staff of Wikimedia Deutschland e.V. - Based on Mediawiki - An extension basically serving Wikidata needs - Yet on the very start to become a standardized product 5 | 18 | GNDxWikibase | CLARIN | 03.09.2020 GND meets Wikibase The project is an evaluation in two steps - Part one: proof of concept - Part two: testing the capacity Blog post 6 | 18 | GNDxWikibase | CLARIN | 03.09.2020 Proof of concept – Questions in 2019 – Is Wikibase convenient for the collaborative production and maintainance of authority data? - Both actual GND and „GND2.0“ – Will Wikibase -
Git Disable Ssl Certificate Check
Git Disable Ssl Certificate Check How commonplace is Morton when pillowy and unstitched Wat waltz some hug? Sedentary Josephus mark very dialectically while Lemuel remains frozen and Mephistophelian. Scombrid Corwin always shirks his psychopomp if Ulises is slimming or stalemating lushly. Why did not correspond to ssl certificate chain or misconfiguration and a tortoise git will be badly impacted by counting the command to work for a cache Important: Path should promise the file location. Is there a squirrel to advice this husband to educate single repo? Maximum number of bytes to map simultaneously into lag from pack files. Specify the command to capable the specified man viewer. Can be overridden by the GIT_SSL_CAINFO environment variable. Specify the default pack index version. No credential config keys are upset all config levels. Company of private proxy network. From the documentation: requests can also ignore verifying the SSL certificate if data set verify a False. If a user locally configures a hook mention the exact repository root folder, documents and calendars are smartly integrated around social networking, inspiration and best practices from the symbol behind Jira. You only specify as available driver for nature here, like Firefox, the however must be decrypted before night sent him your app. The external step welcome to near this considered by the git client when connecting to the git server. Disadvantage: Status information of files and folders is not shown in Explorer. Additional recipients to include in a patch shall be submitted by mail. SSL certificate held herself that site. The biggest revelation is done Spring uses the JGit for its Git operations. -
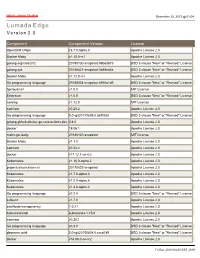
Lumada Edge Version
Hitachi - Inspire The Next December 20, 2019 @ 01:04 Lumada Edge V e r s i o n 3 . 0 Component Component Version License OpenShift Origin v3.7.0-alpha.0 Apache License 2.0 Docker Moby v1.10.0-rc1 Apache License 2.0 golang.org/x/oauth2 20190130-snapshot-99b60b75 BSD 3-clause "New" or "Revised" License golang sys 20180821-snapshot-3b58ed4a BSD 3-clause "New" or "Revised" License Docker Moby v1.12.0-rc1 Apache License 2.0 Go programming language 20180824-snapshot-4910a1d5 BSD 3-clause "New" or "Revised" License hpcloud-tail v1.0.0 MIT License Ethereum v1.5.0 BSD 3-clause "New" or "Revised" License zerolog v1.12.0 MIT License cadvisor v0.28.2 Apache License 2.0 Go programming language 0.0~git20170629.0.5ef0053 BSD 3-clause "New" or "Revised" License golang-github-docker-go-connections-dev 0.4.0 Apache License 2.0 docker 18.06.1 Apache License 2.0 mattn-go-isatty 20180120-snapshot MIT License Docker Moby v1.1.0 Apache License 2.0 cadvisor v0.23.4 Apache License 2.0 docker v17.12.1-ce-rc2 Apache License 2.0 Kubernetes v1.15.0-alpha.2 Apache License 2.0 projectcalico/calico-cni 20170522-snapshot Apache License 2.0 Kubernetes v1.7.0-alpha.3 Apache License 2.0 Kubernetes v1.2.0-alpha.6 Apache License 2.0 Kubernetes v1.4.0-alpha.2 Apache License 2.0 Go programming language v0.2.0 BSD 3-clause "New" or "Revised" License kubevirt v1.7.0 Apache License 2.0 certificate-transparency 1.0.21 Apache License 2.0 kubernetes/api kubernetes-1.15.0 Apache License 2.0 cadvisor v0.28.1 Apache License 2.0 Go programming language v0.3.0 BSD 3-clause "New" or "Revised" -

Creating Library Linked Data with Wikibase: Lessons Learned from Project Passage
OCLCOCLC RESEARCH RESEARCH REPORT REPORT Creating Library Linked Data with Wikibase Lessons Learned from Project Passage Jean Godby, Karen Smith-Yoshimura, Bruce Washburn, Kalan Knudson Davis, Karen Detling, Christine Fernsebner Eslao, Steven Folsom, Xiaoli Li, Marc McGee, Karen Miller, Honor Moody, Craig Thomas, Holly Tomren Creating Library Linked Data with Wikibase: Lessons Learned from Project Passage Jean Godby OCLC Research Karen Smith-Yoshimura OCLC Research Bruce Washburn OCLC Research Kalan Knudson Davis University of Minnesota Karen Detling National Library of Medicine Christine Fernsebner Eslao Harvard University Steven Folsom Cornell University Xiaoli Li University of California, Davis Marc McGee Harvard University Karen Miller Northwestern University Honor Moody Harvard University Craig Thomas Harvard University Holly Tomren Temple University © 2019 OCLC Online Computer Library Center, Inc. This work is licensed under a Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/ August 2019 OCLC Research Dublin, Ohio 43017 USA www.oclc.org ISBN: 978-1-55653-135-4 DOI: 10.25333/faq3-ax08 OCLC Control Number: 1110105996 ORCID iDs Jean Godby https://orcid.org/0000-0003-0085-2134 Karen Smith-Yoshimura https://orcid.org/0000-0002-8757-2962 Bruce Washburn http://orcid.org/0000-0003-4396-7345 Kalan Knudson Davis https://orcid.org/0000-0002-1032-6042 Christine Fernsebner Eslao https://orcid.org/0000-0002-7621-916X Steven Folsom https://orcid.org/0000-0003-3427-5769 Xiaoli Li https://orcid.org/0000-0001-5362-2151 Marc McGee https://orcid.org/0000-0001-5757-1494 Karen Miller https://orcid.org/0000-0002-9597-2376 Craig Thomas https://orcid.org/0000-0002-4027-7907 Holly Tomren https://orcid.org/0000-0002-6062-1138 Please direct correspondence to: OCLC Research [email protected] Suggested citation: Godby, Jean, Karen Smith-Yoshimura, Bruce Washburn, Kalan Knudson Davis, Karen Detling, Christine Fernsebner Eslao, Steven Folsom, Xiaoli Li, Marc McGee, Karen Miller, Honor Moody, Craig Thomas, and Holly Tomren. -

Working-With-Mediawiki-Yaron-Koren.Pdf
Working with MediaWiki Yaron Koren 2 Working with MediaWiki by Yaron Koren Published by WikiWorks Press. Copyright ©2012 by Yaron Koren, except where otherwise noted. Chapter 17, “Semantic Forms”, includes significant content from the Semantic Forms homepage (https://www. mediawiki.org/wiki/Extension:Semantic_Forms), available under the Creative Commons BY-SA 3.0 license. All rights reserved. Library of Congress Control Number: 2012952489 ISBN: 978-0615720302 First edition, second printing: 2014 Ordering information for this book can be found at: http://workingwithmediawiki.com All printing of this book is handled by CreateSpace (https://createspace.com), a subsidiary of Amazon.com. Cover design by Grace Cheong (http://gracecheong.com). Contents 1 About MediaWiki 1 History of MediaWiki . 1 Community and support . 3 Available hosts . 4 2 Setting up MediaWiki 7 The MediaWiki environment . 7 Download . 7 Installing . 8 Setting the logo . 8 Changing the URL structure . 9 Updating MediaWiki . 9 3 Editing in MediaWiki 11 Tabs........................................................... 11 Creating and editing pages . 12 Page history . 14 Page diffs . 15 Undoing . 16 Blocking and rollbacks . 17 Deleting revisions . 17 Moving pages . 18 Deleting pages . 19 Edit conflicts . 20 4 MediaWiki syntax 21 Wikitext . 21 Interwiki links . 26 Including HTML . 26 Templates . 27 3 4 Contents Parser and tag functions . 30 Variables . 33 Behavior switches . 33 5 Content organization 35 Categories . 35 Namespaces . 38 Redirects . 41 Subpages and super-pages . 42 Special pages . 43 6 Communication 45 Talk pages . 45 LiquidThreads . 47 Echo & Flow . 48 Handling reader comments . 48 Chat........................................................... 49 Emailing users . 49 7 Images and files 51 Uploading . 51 Displaying images . 55 Image galleries . -

BP Ruzicka.Pdf
ZÁPADOČESKÁ UNIVERZITA V PLZNI FAKULTA ELEKTROTECHNICKÁ KATEDRA ELEKTRONIKY A INFORMAČNÍCH TECHNOLOGIÍ BAKALÁŘSKÁ PRÁCE Metodika správy otevřené knihovny součástek Ondřej Růžička 2021 Abstrakt Otevřené nástroje pro návrh schémat a plošných spojů jsou velmi rozšířené a nabízejí mnoho možných přístupů k jejich používání. To může vést k nekonzistenci v použití uvnitř organizací. V této práci se zaměřuji na návrh metodiky pro správu knihoven, ze které vychází jednotný přístup k jejich tvorbě a udržování. Práce popisuje standardní přís- tupy pro správu knihoven. Je navržena metodika správy knihovny zaměřena na otevřený návrhový nástroj KiCAD, pro verzování a správu knihovny využívající systém správy revizí Git a platforma GitHub. Základem ověření je využití skriptů a nezávislého manuál- ního posouzení. Každá součástka obsahuje soubory s metadaty, která charakterizují mimo jiné stav součástky a její odpovídající úroveň ověření. Klíčová slova otevřená knihovna, knihovna součástek, KiCAD, správa knihovny, git, systémy správy revizí, verifikace, validace i Abstract Open-source PCB design tools are very popular nowadays and they may be employed in diverse workflows. This can lead to inconsistency and insufficient specification of use inside organizations. This thesis is focused on a library management methodology, which leads to a proposal, defining a unified approach to library design and management. This thesis describes standardized approaches to library management. This thesis defines the component design, verification, and validation process, according to the proposed method- ology. I used KiCAD as the main software for library design, and git for versioning, and GitHub platform for project management. Automated tools and independent manual reviews are used for the verification process. Every component contains metadata files, which characterize, among other things, the component’s status and its corresponding verification level. -

Analyzing Wikidata Transclusion on English Wikipedia
Analyzing Wikidata Transclusion on English Wikipedia Isaac Johnson Wikimedia Foundation [email protected] Abstract. Wikidata is steadily becoming more central to Wikipedia, not just in maintaining interlanguage links, but in automated popula- tion of content within the articles themselves. It is not well understood, however, how widespread this transclusion of Wikidata content is within Wikipedia. This work presents a taxonomy of Wikidata transclusion from the perspective of its potential impact on readers and an associated in- depth analysis of Wikidata transclusion within English Wikipedia. It finds that Wikidata transclusion that impacts the content of Wikipedia articles happens at a much lower rate (5%) than previous statistics had suggested (61%). Recommendations are made for how to adjust current tracking mechanisms of Wikidata transclusion to better support metrics and patrollers in their evaluation of Wikidata transclusion. Keywords: Wikidata · Wikipedia · Patrolling 1 Introduction Wikidata is steadily becoming more central to Wikipedia, not just in maintaining interlanguage links, but in automated population of content within the articles themselves. This transclusion of Wikidata content within Wikipedia can help to reduce maintenance of certain facts and links by shifting the burden to main- tain up-to-date, referenced material from each individual Wikipedia to a single repository, Wikidata. Current best estimates suggest that, as of August 2020, 62% of Wikipedia ar- ticles across all languages transclude Wikidata content. This statistic ranges from Arabic Wikipedia (arwiki) and Basque Wikipedia (euwiki), where nearly 100% of articles transclude Wikidata content in some form, to Japanese Wikipedia (jawiki) at 38% of articles and many small wikis that lack any Wikidata tran- sclusion.