Computational Composition Strategies in Audiovisual Laptop Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Apparent Entropy of Cellular Automata
Apparent Entropy of Cellular Automata Bruno Martin Laboratoire d’Informatique et du Parallelisme,´ Ecole´ Normale Superieure´ de Lyon, 46, allee´ d’Italie, 69364 Lyon Cedex 07, France We introduce the notion of apparent entropy on cellular automata that points out how complex some configurations of the space-time diagram may appear to the human eye. We then study, theoretically, if possible, but mainly experimentally through natural examples, the relations between this notion, Wolfram’s intuition, and almost everywhere sensitivity to initial conditions. Introduction A radius-r one-dimensional cellular automaton (CA) is an infinite se- quence of identical finite-state machines (indexed by Ÿ) called cells. Each finite-state machine is in a state and these states change simultane- ously according to a local transition function: the following state of the machine is related to its own state as well as the states of its 2r neigh- bors. A configuration of an automaton is the function which associates to each cell a state. We can thus define a global transition function from the set of all the configurations to itself which associates the following configuration after one step of computation. Recently, a lot of articles proposed classifications of CAs [5, 8, 13] but the canonical reference is still Wolfram’s empirical classification [14] which has resisted numerous attempts of formalization. Among the lat- est attempts, some are based on the mathematical definitions of chaos for dynamical systems adapted to CAs thanks to Besicovitch topol- ogy [2, 6] and [11] introduces the almost everywhere sensitivity to initial conditions for this topology and compares this notion with information propagation formalization. -

Flocking: a Framework for Declarative Music-Making on the Web
Proceedings ICMC|SMC|2014 14-20 September 2014, Athens, Greece Flocking: A Framework for Declarative Music-Making on the Web Colin Clark Adam Tindale OCAD University OCAD University [email protected] [email protected] ABSTRACT JavaScript. As artists and musicians increasingly use net- worked devices, sensors, and collaboration in their work, Flocking 1 is a framework for audio synthesis and mu- these limitations take an increasing toll on the complexity sic composition written in JavaScript. It takes a unique and scalability of creative coding. approach to solving several of the common architectural Flocking is an open source JavaScript framework that problems faced by computer music environments, empha- aims to address some of these concerns by connecting mu- sizing a declarative style that is closely aligned with the sicians and artists with the cross-platform, distributed de- principles of the web. livery model of the web, and with the larger pool of li- Flocking’s goal is to enable the growth of an ecosys- braries, user interface components, and tutorials that are tem of tools that can easily parse and understand the logic available to the web development community. Further, and semantics of digital instruments by representing the it emphasizes an approach to interoperability in which basic building blocks of synthesis declaratively. This is declarative instruments and compositions can be broadly particularly useful for supporting generative composition shared, manipulated, and extended across traditional tech- (where programs generate new instruments and scores al- nical subcultural boundaries. gorithmically), graphical tools (for programmers and non- programmers alike to collaborate), and new modes of so- cial programming that allow musicians to easily adapt, ex- 1.1 Interoperability in Context tend, and rework existing instruments without having to A primary motivating concern for Flocking is that the “fork” their code. -
![Arxiv:1607.02291V3 [Cs.FL] 8 May 2018](https://docslib.b-cdn.net/cover/3689/arxiv-1607-02291v3-cs-fl-8-may-2018-1473689.webp)
Arxiv:1607.02291V3 [Cs.FL] 8 May 2018
Noname manuscript No. (will be inserted by the editor) A Survey of Cellular Automata: Types, Dynamics, Non-uniformity and Applications (Draft version) Kamalika Bhattacharjee · Nazma Naskar · Souvik Roy · Sukanta Das Received: date / Accepted: date Abstract Cellular automata (CAs) are dynamical systems which exhibit complex global be- havior from simple local interaction and computation. Since the inception of cellular au- tomaton (CA) by von Neumann in 1950s, it has attracted the attention of several researchers over various backgrounds and fields for modelling different physical, natural as well as real- life phenomena. Classically, CAs are uniform. However, non-uniformity has also been in- troduced in update pattern, lattice structure, neighborhood dependency and local rule. In this survey, we tour to the various types of CAs introduced till date, the different characteriza- tion tools, the global behaviors of CAs, like universality, reversibility, dynamics etc. Special attention is given to non-uniformity in CAs and especially to non-uniform elementary CAs, which have been very useful in solving several real-life problems. Keywords Cellular Automata (CAs) · Types · Characterization tools · Dynamics · Non-uniformity · Technology Mathematics Subject Classification (2010) 68Q80 · 37B15 1 Introduction From the end of the first half of 20th century, a new approach has started to come in scien- tific studies, which after questioning the so called Cartesian analytical approach, says that interconnections among the elements of a system, be it physical, biological, artificial or any other, greatly effect the behavior of the system. In fact, according to this approach, knowing the parts of a system, one can not properly understand the system as a whole. -

The Early History of Music Programming and Digital Synthesis, Session 20
Chapter 20. Meeting 20, Languages: The Early History of Music Programming and Digital Synthesis 20.1. Announcements • Music Technology Case Study Final Draft due Tuesday, 24 November 20.2. Quiz • 10 Minutes 20.3. The Early Computer: History • 1942 to 1946: Atanasoff-Berry Computer, the Colossus, the Harvard Mark I, and the Electrical Numerical Integrator And Calculator (ENIAC) • 1942: Atanasoff-Berry Computer 467 Courtesy of University Archives, Library, Iowa State University of Science and Technology. Used with permission. • 1946: ENIAC unveiled at University of Pennsylvania 468 Source: US Army • Diverse and incomplete computers © Wikimedia Foundation. License CC BY-SA. This content is excluded from our Creative Commons license. For more information, see http://ocw.mit.edu/fairuse. 20.4. The Early Computer: Interface • Punchcards • 1960s: card printed for Bell Labs, for the GE 600 469 Courtesy of Douglas W. Jones. Used with permission. • Fortran cards Courtesy of Douglas W. Jones. Used with permission. 20.5. The Jacquard Loom • 1801: Joseph Jacquard invents a way of storing and recalling loom operations 470 Photo courtesy of Douglas W. Jones at the University of Iowa. 471 Photo by George H. Williams, from Wikipedia (public domain). • Multiple cards could be strung together • Based on technologies of numerous inventors from the 1700s, including the automata of Jacques Vaucanson (Riskin 2003) 20.6. Computer Languages: Then and Now • Low-level languages are closer to machine representation; high-level languages are closer to human abstractions • Low Level • Machine code: direct binary instruction • Assembly: mnemonics to machine codes • High-Level: FORTRAN • 1954: John Backus at IBM design FORmula TRANslator System • 1958: Fortran II 472 • 1977: ANSI Fortran • High-Level: C • 1972: Dennis Ritchie at Bell Laboratories • Based on B • Very High-Level: Lisp, Perl, Python, Ruby • 1958: Lisp by John McCarthy • 1987: Perl by Larry Wall • 1990: Python by Guido van Rossum • 1995: Ruby by Yukihiro “Matz” Matsumoto 20.7. -

Abstract Collection of the 2017 International Symposium on Nonlinear Theory and Its Applications (NOLTA2017)
Abstract Collection of the 2017 International Symposium on Nonlinear Theory and its Applications (NOLTA2017) Cancun International Convention Center, Cancun,´ Mexico December 4–7, 2017. Abstract Collection of NOLTA2017 ⃝C IEICE Japan 2017 Typesetting: Data conversion by the authors. Final processing by T. Tsubone and W. Kurebayashi with LATEX. Printed in Japan 2 Contents Welcome Message from the General Chairs . 6 Technical Program Chair’s Message . 7 Organizing Committee . 8 Technical Program Committee . 9 Advisory Committee . 10 NOLTA Steering Committee . 11 Special Session Organizers . 12 Symposium Information . 14 Symposium Venue . 14 Social Events . 14 Session at a Glance . 16 Abstracts 19 A0L-A Plenary Talk 1 . 19 A1L-A Theory and Learning Applications of Koopman Operator Formalism . 19 A1L-B Systems Theory and its Applications . 20 A1L-C Complex systems, complex networks and bigdata analyses . 21 A1L-D Advanced Theory and Applications Related to Communication Quality . 23 A1L-E Neuromorphic Systems and Electronic Devices 1 . 24 A2L-A Network Function for Physically and Logically Coupled System . 25 A2L-B Circuits and Systems / Analog and digital devices . 26 A2L-C Neural Networks / Biological Engineering . 27 A2L-D Complex Communication Sciences 1 . 28 A2L-E Neuromorphic Systems and Electronic Devices 2 . 29 A3L-A Radio and Optical Wireless Communications 1 . 30 A3L-B Complex Networks and Systems / Image and Signal Processing . 32 A3L-C Laser Dynamics and Complex Photonics 1 . 34 A3L-D-1 Complex Communication Sciences 2 . 35 A3L-D-2 Complex Networks and Systems / Image and Signal Processing . 36 A3L-E-1 Neuromorphic Systems and Electronic Devices 3 . 37 A3L-E-2 Machine Learning / Evolutionary computations . -

Lecture P4: Cellular Automata Arrays Allow Manipulation of Potentially Huge Amounts of Data
Array Review Lecture P4: Cellular Automata Arrays allow manipulation of potentially huge amounts of data. ■ All elements of the same type. – double, int ■ N-element array has elements indexed 0 through N-1. ■ Fast access to arbitrary element. – a[i] ■ Waste of space if array is "sparse." Reaction diffusion textures. Andy Witkin and Michael Kass Princeton University • COS 126 • General Computer Science • Fall 2002 • http://www.Princeton.EDU/~cs126 2 Cellular Automata Applications of Cellular Automata Cellular automata. (singular = cellular automaton) Modern applications. ■ Computer simulations that try to emulate laws of nature. ■ Simulations of biology, chemistry, physics. ■ Simple rules can generate complex patterns. – ferromagnetism according to Ising mode – forest fire propagation – nonlinear chemical reaction-diffusion systems – turbulent flow John von Neumann. (Princeton IAS, 1950s) – biological pigmentation patterns ■ Wanted to create and simulate artificial – breaking of materials life on a machine. – growth of crystals ■ Self-replication. – growth of plants and animals ■ ■ "As simple as possible, but no simpler." Image processing. ■ Computer graphics. ■ Design of massively parallel hardware. ■ Art. 3 4 How Did the Zebra Get Its Stripes? One Dimensional Cellular Automata 1-D cellular automata. ■ Sequence of cells. ■ Each cell is either black (alive) or white (dead). ■ In each time step, update status of each cell, depending on color of nearby cells from previous time step. Example rule. Make cell black at time t if at least one of its proper neighbors was black at time t-1. time 0 time 1 time 2 Synthetic zebra. Greg Turk 5 6 Cellular Automata: Designing the Code Cellular Automata: The Code How to store the row of cells. -
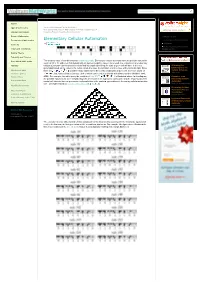
Elementary Cellular Automaton Calculus and Analysis Interactive Entries > Interactive Demonstrations >
Search MathWorld Algebra Applied Mathematics Discrete Mathematics > Cellular Automata > Recreational Mathematics > Mathematical Art > Mathematical Images > elementary cellular automaton Calculus and Analysis Interactive Entries > Interactive Demonstrations > Discrete Mathematics THINGS TO TRY: Foundations of Mathematics Elementary Cellular Automaton elementary cellular automaton 39th prime Geometry do the algebraic units contain History and Terminology Sqrt[2]+Sqrt[3]? Number Theory Probability and Statistics Recreational Mathematics The simplest class of one-dimensional cellular automata. Elementary cellular automata have two possible values for each cell (0 or 1), and rules that depend only on nearest neighbor values. As a result, the evolution of an elementary Topology cellular automaton can completely be described by a table specifying the state a given cell will have in the next A Strategy for generation based on the value of the cell to its left, the value the cell itself, and the value of the cell to its right. Since Exploring k=2, r=2 Alphabetical Index there are possible binary states for the three cells neighboring a given cell, there are a total of Cellular Automata John Kiehl Interactive Entries elementary cellular automata, each of which can be indexed with an 8-bit binary number (Wolfram 1983, Random Entry 2002). For example, the table giving the evolution of rule 30 ( ) is illustrated above. In this diagram, Dynamics of an the possible values of the three neighboring cells are shown in the top row of each panel, and the resulting value the Elementary Cellular New in MathWorld central cell takes in the next generation is shown below in the center. generations of elementary cellular automaton Automaton rule are implemented as CellularAutomaton[r, 1 , 0 , n]. -

Global Properties of Cellular Automata
Global properties of cellular automata Edward Jack Powley Submitted for the qualification of PhD University of York Department of Computer Science October 2009 Abstract A cellular automaton (CA) is a discrete dynamical system, composed of a large number of simple, identical, uniformly interconnected components. CAs were introduced by John von Neumann in the 1950s, and have since been studied extensively both as models of real-world systems and in their own right as abstract mathematical and computational systems. CAs can exhibit emergent behaviour of varying types, including universal computation. As is often the case with emergent behaviour, predicting the behaviour from the specification of the system is a nontrivial task. This thesis explores some properties of CAs, and studies the correlations between these properties and the qualitative behaviour of the CA. The properties studied in this thesis are properties of the global state space of the CA as a dynamical system. These include degree of symmetry, numbers of preimages (convergence of trajectories), and distances between successive states on trajectories. While we do not obtain a complete classifi- cation of CAs according to their qualitative behaviour, we argue that these types of global properties are a better indicator than other, more local, properties. 3 Contents Chapter 1. Introduction 11 Part 1. Literature review 15 Chapter 2. Cellular automata 17 2.1. Definition and dynamics 17 2.2. Example: Conway's Game of Life 19 2.3. 1-dimensional CAs and elementary CAs 21 2.4. Essentially different rules 23 2.5. Classification 26 2.6. Speed of propagation 29 2.7. -

5 Cellular Automata Models
5 Cellular automata models Cellular automata (CA) models epitomize the idea that simple rules can generate complex patterns. A CA consists of an array of cells each with an integer 'state'. On each time step a local update rule is applied to the cells. The update rule defines how the a particular cell will update its state as a funcion of its neighbours state. The CA is run over time and the evolution of the state is observed. 5.1 Elementary cellular automata The elementary one dimensional CA is defined by how three cells influence a single cell. For example, The rules can be expressed in binary form where a 0 represents that a par- ticular configuration gives a white output and a 1 denotes a black output. For example, the above rule in binary is 00011110. Converting this binary number to base-10, we call this rule 30. We thus have a set of different rules for elementary cellular automata from 0 up to 255. 21 Although the rule itself is simple, the output of rule 30 is somewhat compli- cated. 22 23 Elementary CA simulators are easily found on the internet. In the lecture, I will demonstrate one of these written in NetLogo (http://ccl.northwestern.edu/netlogo/). We will look at rules 254, 250, 150, 90, 110, 30 and 193 in this simulator. Some of these rules produce simple repetitive patterns, others produce pe- riodic patterns, while some produce complicated patterns. Rule 30 is of special interest because it is chaotic. This rule is used as the random number generator used for large integers in Mathematica. -

Cellular Automata Can Reduce Memory Requirements of Collective-State Computing Denis Kleyko, E
1 Cellular Automata Can Reduce Memory Requirements of Collective-State Computing Denis Kleyko, E. Paxon Frady, and Friedrich T. Sommer Abstract—Various non-classical approaches of distributed in- include reservoir computing (RC) [2], [3], [4], [5] for buffering formation processing, such as neural networks, computation with spatio-temporal inputs, and attractor networks for associative Ising models, reservoir computing, vector symbolic architectures, memory [6] and optimization [7]. In addition, many other and others, employ the principle of collective-state computing. In this type of computing, the variables relevant in a computation models can be regarded as collective-state computing, such as are superimposed into a single high-dimensional state vector, the random projection [8], compressed sensing [9], [10], randomly collective-state. The variable encoding uses a fixed set of random connected feedforward neural networks [11], [12], and vector patterns, which has to be stored and kept available during symbolic architectures (VSAs) [13], [14], [15]. Interestingly, the computation. Here we show that an elementary cellular these diverse computational models share a fundamental com- automaton with rule 90 (CA90) enables space-time tradeoff for collective-state computing models that use random dense binary monality – they all include an initialization phase in which representations, i.e., memory requirements can be traded off with high-dimensional i.i.d. random vectors or matrices are gener- computation running CA90. We investigate the randomization ated that have to be memorized. behavior of CA90, in particular, the relation between the length of In different models, these memorized random vectors serve the randomization period and the size of the grid, and how CA90 a similar purpose: to represent inputs and variables that need to preserves similarity in the presence of the initialization noise. -

Real-Time Multimedia Composition Using
Real-time Multimedia Composition using Lua W esley Smith Graham W akefield Media Arts and Technology Program Media Arts and Technology Program University of California Santa Barbara University of California Santa Barbara [email protected] [email protected] ABSTRACT 1.2 Lua In this paper, a new interface for programming multimedia compositions in Max/MSP/Jitter using the Lua scripting Lua is a powerful, efficient scripting language based on language is presented. Lua is extensible and efficient making associative tables and functional programming techniques. it an ideal choice for designing a programmatic interface for Lua is ideally suited for real-time multimedia processing multimedia compositions. First, we discuss the distinctions because of its flexible semantics and fast performance; it is of graphical and textual interfaces for composition and the frequently used for game logic programming (e.g. World of requirements for a productive compositional workflow, and Warcraft [24]) and application extension (e.g. Adobe then we describe domain specific implementations of Lua Lightroom) [11]. bindings as Max externals for graphics and audio in that order. 1.3 jit.gl.lua and lua~ Categories and Subject Descriptors H.5.1 [Information Interfaces and Presentation] Multimedia The jit.gl.lua (for OpenGL graphics) and Lua~ (for audio DSP) Information Systems - animations; H.5.5 [Information extensions allow a new range of expressive control in which Interfaces and Presentation] Sound and Music Computing - arbitrary, dynamic data structures and behaviors can be methodologies & techniques, modeling, signal synthesis and generated, whilst interfacing with the convenient graphical processing; I.3.7 [Computer Graphics] Three-Dimensional interface and libraries of Max/MSP/Jitter. -

SAOL: the MPEG-4 Structured Audio Orchestra Language
Eric D. Scheirer and Barry L. Vercoe Machine Listening Group SAOL: The MPEG-4 E15-401D MIT Media Laboratory Cambridge, Massachusetts 02139-4307, USA Structured Audio [email protected] [email protected] Orchestra Language Since the beginning of the computer music era, The Motion Pictures Experts Group (MPEG), tools have been created that allow the description part of the International Standardization Organiza- of music and other organized sound as concise net- tion (ISO) finished the MPEG-4 standard, formally works of interacting oscillators and envelope func- ISO 14496, in October 1998; MPEG-4 will be des- tions. Originated by Max Mathews with his series ignated as an international standard and published of “Music N” languages (Mathews 1969), this unit in 1999. The work plan and technology of MPEG-4 generator paradigm for the creation of musical represent a departure from the previous MPEG-1 sound has proven highly effective for the creative (ISO 11172) and MPEG-2 (ISO 13818) standards. description of sound and widely useful for musi- While MPEG-4 contains capabilities similar to cians. Languages such as Csound (Vercoe 1995), MPEG-1 and MPEG-2 for the coding and compres- Nyquist (Dannenberg 1997a), CLM (Schottstaedt sion of audiovisual data, it additionally specifies 1994), and SuperCollider (McCartney 1996b) are methods for the compressed transmission of syn- widely used in academic and production studios thetic sound and computer graphics, and for the today. juxtaposition of synthetic and “natural” (com- As well as being an effective tool for marshalling pressed audio/video) material. a composer’s creative resources, these languages Within the MPEG-4 standard, there is a set of represent an unusual form of digital audio com- tools of particular interest to computer musicians pression (Vercoe, Gardner, and Scheirer 1998).