A Major Qualifying Project Report Submitted to The
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Systematic Screening for Potential Therapeutic Targets in Osteosarcoma Through a Kinome-Wide CRISPR-Cas9 Library
Cancer Biol Med 2020. doi: 10.20892/j.issn.2095-3941.2020.0162 ORIGINAL ARTICLE Systematic screening for potential therapeutic targets in osteosarcoma through a kinome-wide CRISPR-Cas9 library Yuanzhong Wu*, Liwen Zhou*, Zifeng Wang, Xin Wang, Ruhua Zhang, Lisi Zheng, Tiebang Kang Sun Yat-sen University Cancer Center, State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Guangzhou 510060, China ABSTRACT Objective: Osteosarcoma is the most common primary malignant bone tumor. However, the survival of patients with osteosarcoma has remained unchanged during the past 30 years, owing to a lack of efficient therapeutic targets. Methods: We constructed a kinome-targeting CRISPR-Cas9 library containing 507 kinases and 100 nontargeting controls and screened the potential kinase targets in osteosarcoma. The CRISPR screening sequencing data were analyzed with the Model-based Analysis of Genome-wide CRISPR/Cas9 Knockout (MAGeCK) Python package. The functional data were applied in the 143B cell line through lenti-CRISPR-mediated gene knockout. The clinical significance of kinases in the survival of patients with osteosarcoma was analyzed in the R2: Genomics Analysis and Visualization Platform. Results: We identified 53 potential kinase targets in osteosarcoma. Among these targets, we analyzed 3 kinases, TRRAP, PKMYT1, and TP53RK, to validate their oncogenic functions in osteosarcoma. PKMYT1 and TP53RK showed higher expression in osteosarcoma than in normal bone tissue, whereas TRRAP showed no significant difference. High expression of all 3 kinases was associated with relatively poor prognosis in patients with osteosarcoma. Conclusions: Our results not only offer potential therapeutic kinase targets in osteosarcoma but also provide a paradigm for functional genetic screening by using a CRISPR-Cas9 library, including target design, library construction, screening workflow, data analysis, and functional validation. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

The Title of the Dissertation
UNIVERSITY OF CALIFORNIA SAN DIEGO Novel network-based integrated analyses of multi-omics data reveal new insights into CD8+ T cell differentiation and mouse embryogenesis A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Bioinformatics and Systems Biology by Kai Zhang Committee in charge: Professor Wei Wang, Chair Professor Pavel Arkadjevich Pevzner, Co-Chair Professor Vineet Bafna Professor Cornelis Murre Professor Bing Ren 2018 Copyright Kai Zhang, 2018 All rights reserved. The dissertation of Kai Zhang is approved, and it is accept- able in quality and form for publication on microfilm and electronically: Co-Chair Chair University of California San Diego 2018 iii EPIGRAPH The only true wisdom is in knowing you know nothing. —Socrates iv TABLE OF CONTENTS Signature Page ....................................... iii Epigraph ........................................... iv Table of Contents ...................................... v List of Figures ........................................ viii List of Tables ........................................ ix Acknowledgements ..................................... x Vita ............................................. xi Abstract of the Dissertation ................................. xii Chapter 1 General introduction ............................ 1 1.1 The applications of graph theory in bioinformatics ......... 1 1.2 Leveraging graphs to conduct integrated analyses .......... 4 1.3 References .............................. 6 Chapter 2 Systematic -

Plasma Membrane Ca2+–Atpase in Rat and Human Odontoblasts Mediates Dentin Mineralization
biomolecules Article Plasma Membrane Ca2+–ATPase in Rat and Human Odontoblasts Mediates Dentin Mineralization Maki Kimura 1,†, Hiroyuki Mochizuki 1,†, Ryouichi Satou 2, Miyu Iwasaki 2, Eitoyo Kokubu 3, Kyosuke Kono 1, Sachie Nomura 1, Takeshi Sakurai 1, Hidetaka Kuroda 1,4,† and Yoshiyuki Shibukawa 1,*,† 1 Department of Physiology, Tokyo Dental College, 2-9-18, Kanda-Misaki-cho, Chiyoda-ku, Tokyo 101-0061, Japan; [email protected] (M.K.); [email protected] (H.M.); [email protected] (K.K.); [email protected] (S.N.); [email protected] (T.S.); [email protected] (H.K.) 2 Department of Epidemiology and Public Health, Tokyo Dental College, Chiyodaku, Tokyo 101-0061, Japan; [email protected] (R.S.); [email protected] (M.I.) 3 Department of Microbiology, Tokyo Dental College, Chiyodaku, Tokyo 101-0061, Japan; [email protected] 4 Department of Dental Anesthesiology, Kanagawa Dental University, 1-23, Ogawacho, Kanagawa, Yokosuka-shi 238-8570, Japan * Correspondence: [email protected] † These authors contributed equally to this study. Abstract: Intracellular Ca2+ signaling engendered by Ca2+ influx and mobilization in odontoblasts is critical for dentinogenesis induced by multiple stimuli at the dentin surface. Increased Ca2+ is exported by the Na+–Ca2+ exchanger (NCX) and plasma membrane Ca2+–ATPase (PMCA) to Citation: Kimura, M.; Mochizuki, H.; maintain Ca2+ homeostasis. We previously demonstrated a functional coupling between Ca2+ Satou, R.; Iwasaki, M.; Kokubu, E.; extrusion by NCX and its influx through transient receptor potential channels in odontoblasts. Kono, K.; Nomura, S.; Sakurai, T.; Although the presence of PMCA in odontoblasts has been previously described, steady-state levels of Kuroda, H.; Shibukawa, Y. -

The Role of the Mtor Pathway in Developmental Reprogramming Of
THE ROLE OF THE MTOR PATHWAY IN DEVELOPMENTAL REPROGRAMMING OF HEPATIC LIPID METABOLISM AND THE HEPATIC TRANSCRIPTOME AFTER EXPOSURE TO 2,2',4,4'- TETRABROMODIPHENYL ETHER (BDE-47) An Honors Thesis Presented By JOSEPH PAUL MCGAUNN Approved as to style and content by: ________________________________________________________** Alexander Suvorov 05/18/20 10:40 ** Chair ________________________________________________________** Laura V Danai 05/18/20 10:51 ** Committee Member ________________________________________________________** Scott C Garman 05/18/20 10:57 ** Honors Program Director ABSTRACT An emerging hypothesis links the epidemic of metabolic diseases, such as non-alcoholic fatty liver disease (NAFLD) and diabetes with chemical exposures during development. Evidence from our lab and others suggests that developmental exposure to environmentally prevalent flame-retardant BDE47 may permanently reprogram hepatic lipid metabolism, resulting in an NAFLD-like phenotype. Additionally, we have demonstrated that BDE-47 alters the activity of both mTOR complexes (mTORC1 and 2) in hepatocytes. The mTOR pathway integrates environmental information from different signaling pathways, and regulates key cellular functions such as lipid metabolism, innate immunity, and ribosome biogenesis. Thus, we hypothesized that the developmental effects of BDE-47 on liver lipid metabolism are mTOR-dependent. To assess this, we generated mice with liver-specific deletions of mTORC1 or mTORC2 and exposed these mice and their respective controls perinatally to -

Product Data Sheet
Product Data Sheet ExProfileTM Human AMPK Signaling Related Gene qPCR Array For focused group profiling of human AMPK signaling genes expression Cat. No. QG004-A (4 x 96-well plate, Format A) Cat. No. QG004-B (4 x 96-well plate, Format B) Cat. No. QG004-C (4 x 96-well plate, Format C) Cat. No. QG004-D (4 x 96-well plate, Format D) Cat. No. QG004-E (4 x 96-well plate, Format E) Plates available individually or as a set of 6. Each set contains 336 unique gene primer pairs deposited in one 96-well plate. Introduction The ExProfile human AMPK signaling related gene qPCR array profiles the expression of 336 human genes related to AMPK-mediated signal transduction. These genes are carefully chosen for their close pathway correlation based on a thorough literature search of peer-reviewed publications, mainly including genes that encode AMP-activated protein kinase complex,its regulators and targets involved in many important biological processes, such as glucose uptake, β-oxidation of fatty acids and modulation of insulin secretion. This array allows researchers to study the pathway-related genes to gain understanding of their roles in the different biological processes. QG004 plate 01: 84 unique gene PCR primer pairs QG004 plate 02: 84 unique gene PCR primer pairs QG004 plate 03: 84 unique gene PCR primer pairs QG004 plate 04: 84 unique gene PCR primer pairs Shipping and storage condition Shipped at room temperate Stable for at least 6 months when stored at -20°C Array format GeneCopoeia provides five qPCR array formats (A, B, C, D, and E) suitable for use with the following real- time cyclers. -

Paraganglioma (PGL) Tumors in Patients with Succinate Dehydrogenase-Related PCC–PGL Syndromes: a Clinicopathological and Molecular Analysis
T G Papathomas and others Non-PCC/PGL tumors in the SDH 170:1 1–12 Clinical Study deficiency Non-pheochromocytoma (PCC)/paraganglioma (PGL) tumors in patients with succinate dehydrogenase-related PCC–PGL syndromes: a clinicopathological and molecular analysis Thomas G Papathomas1, Jose Gaal1, Eleonora P M Corssmit2, Lindsey Oudijk1, Esther Korpershoek1, Ketil Heimdal3, Jean-Pierre Bayley4, Hans Morreau5, Marieke van Dooren6, Konstantinos Papaspyrou7, Thomas Schreiner8, Torsten Hansen9, Per Arne Andresen10, David F Restuccia1, Ingrid van Kessel6, Geert J L H van Leenders1, Johan M Kros1, Leendert H J Looijenga1, Leo J Hofland11, Wolf Mann7, Francien H van Nederveen12, Ozgur Mete13,14, Sylvia L Asa13,14, Ronald R de Krijger1,15 and Winand N M Dinjens1 1Department of Pathology, Josephine Nefkens Institute, Erasmus MC, University Medical Center, PO Box 2040, 3000 CA Rotterdam, The Netherlands, 2Department of Endocrinology, Leiden University Medical Center, Leiden,The Netherlands, 3Section for Clinical Genetics, Department of Medical Genetics, Oslo University Hospital, Oslo, Norway, 4Department of Human and Clinical Genetics, Leiden University Medical Center, Leiden, The Netherlands, 5Department of Pathology, Leiden University Medical Center, Leiden, The Netherlands, 6Department of Clinical Genetics, Erasmus MC, University Medical Center, Rotterdam, The Netherlands, 7Department of Otorhinolaryngology, Head and Neck Surgery, University Medical Center of the Johannes Gutenberg University Mainz, Mainz, Germany, 8Section for Specialized Endocrinology, -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Related Malignant Phenotypes in the Nf1-Deficient MPNST
Published OnlineFirst February 19, 2013; DOI: 10.1158/1541-7786.MCR-12-0593 Molecular Cancer Genomics Research RAS/MEK–Independent Gene Expression Reveals BMP2- Related Malignant Phenotypes in the Nf1-Deficient MPNST Daochun Sun1, Ramsi Haddad2,3, Janice M. Kraniak2, Steven D. Horne1, and Michael A. Tainsky1,2 Abstract Malignant peripheral nerve sheath tumor (MPNST) is a type of soft tissue sarcoma that occurs in carriers of germline mutations in Nf1 gene as well as sporadically. Neurofibromin, encoded by the Nf1 gene, functions as a GTPase-activating protein (GAP) whose mutation leads to activation of wt-RAS and mitogen-activated protein kinase (MAPK) signaling in neurofibromatosis type I (NF1) patients' tumors. However, therapeutic targeting of RAS and MAPK have had limited success in this disease. In this study, we modulated NRAS, mitogen-activated protein/extracellular signal–regulated kinase (MEK)1/2, and neurofibromin levels in MPNST cells and determined gene expression changes to evaluate the regulation of signaling pathways in MPNST cells. Gene expression changes due to neurofibromin modulation but independent of NRAS and MEK1/2 regulation in MPNST cells indicated bone morphogenetic protein 2 (Bmp2) signaling as a key pathway. The BMP2-SMAD1/5/8 pathway was activated in NF1-associated MPNST cells and inhibition of BMP2 signaling by LDN-193189 or short hairpin RNA (shRNA) to BMP2 decreased the motility and invasion of NF1-associated MPNST cells. The pathway-specific gene changes provide a greater understanding of the complex role of neurofibromin in MPNST pathology and novel targets for drug discovery. Mol Cancer Res; 11(6); 616–27. -

To Study Mutant P53 Gain of Function, Various Tumor-Derived P53 Mutants
Differential effects of mutant TAp63γ on transactivation of p53 and/or p63 responsive genes and their effects on global gene expression. A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science By Shama K Khokhar M.Sc., Bilaspur University, 2004 B.Sc., Bhopal University, 2002 2007 1 COPYRIGHT SHAMA K KHOKHAR 2007 2 WRIGHT STATE UNIVERSITY SCHOOL OF GRADUATE STUDIES Date of Defense: 12-03-07 I HEREBY RECOMMEND THAT THE THESIS PREPARED UNDER MY SUPERVISION BY SHAMA KHAN KHOKHAR ENTITLED Differential effects of mutant TAp63γ on transactivation of p53 and/or p63 responsive genes and their effects on global gene expression BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Science Madhavi P. Kadakia, Ph.D. Thesis Director Daniel Organisciak , Ph.D. Department Chair Committee on Final Examination Madhavi P. Kadakia, Ph.D. Steven J. Berberich, Ph.D. Michael Leffak, Ph.D. Joseph F. Thomas, Jr., Ph.D. Dean, School of Graduate Studies 3 Abstract Khokhar, Shama K. M.S., Department of Biochemistry and Molecular Biology, Wright State University, 2007 Differential effect of TAp63γ mutants on transactivation of p53 and/or p63 responsive genes and their effects on global gene expression. p63, a member of the p53 gene family, known to play a role in development, has more recently also been implicated in cancer progression. Mice lacking p63 exhibit severe developmental defects such as limb truncations, abnormal skin, and absence of hair follicles, teeth, and mammary glands. Germline missense mutations of p63 have been shown to be responsible for several human developmental syndromes including SHFM, EEC and ADULT syndromes and are associated with anomalies in the development of organs of epithelial origin. -
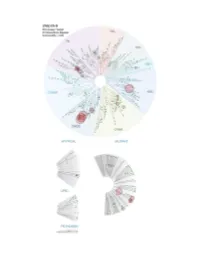
Profiling Data
Compound Name DiscoveRx Gene Symbol Entrez Gene Percent Compound Symbol Control Concentration (nM) JNK-IN-8 AAK1 AAK1 69 1000 JNK-IN-8 ABL1(E255K)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317I)-nonphosphorylated ABL1 87 1000 JNK-IN-8 ABL1(F317I)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317L)-nonphosphorylated ABL1 65 1000 JNK-IN-8 ABL1(F317L)-phosphorylated ABL1 61 1000 JNK-IN-8 ABL1(H396P)-nonphosphorylated ABL1 42 1000 JNK-IN-8 ABL1(H396P)-phosphorylated ABL1 60 1000 JNK-IN-8 ABL1(M351T)-phosphorylated ABL1 81 1000 JNK-IN-8 ABL1(Q252H)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(Q252H)-phosphorylated ABL1 56 1000 JNK-IN-8 ABL1(T315I)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(T315I)-phosphorylated ABL1 92 1000 JNK-IN-8 ABL1(Y253F)-phosphorylated ABL1 71 1000 JNK-IN-8 ABL1-nonphosphorylated ABL1 97 1000 JNK-IN-8 ABL1-phosphorylated ABL1 100 1000 JNK-IN-8 ABL2 ABL2 97 1000 JNK-IN-8 ACVR1 ACVR1 100 1000 JNK-IN-8 ACVR1B ACVR1B 88 1000 JNK-IN-8 ACVR2A ACVR2A 100 1000 JNK-IN-8 ACVR2B ACVR2B 100 1000 JNK-IN-8 ACVRL1 ACVRL1 96 1000 JNK-IN-8 ADCK3 CABC1 100 1000 JNK-IN-8 ADCK4 ADCK4 93 1000 JNK-IN-8 AKT1 AKT1 100 1000 JNK-IN-8 AKT2 AKT2 100 1000 JNK-IN-8 AKT3 AKT3 100 1000 JNK-IN-8 ALK ALK 85 1000 JNK-IN-8 AMPK-alpha1 PRKAA1 100 1000 JNK-IN-8 AMPK-alpha2 PRKAA2 84 1000 JNK-IN-8 ANKK1 ANKK1 75 1000 JNK-IN-8 ARK5 NUAK1 100 1000 JNK-IN-8 ASK1 MAP3K5 100 1000 JNK-IN-8 ASK2 MAP3K6 93 1000 JNK-IN-8 AURKA AURKA 100 1000 JNK-IN-8 AURKA AURKA 84 1000 JNK-IN-8 AURKB AURKB 83 1000 JNK-IN-8 AURKB AURKB 96 1000 JNK-IN-8 AURKC AURKC 95 1000 JNK-IN-8 -

TWIST1 and TWIST2 Regulate Glycogen Storage and Inflammatory
J M MUDRY and others TWIST regulation of metabolism 224:3 303–313 Research in muscle TWIST1 and TWIST2 regulate glycogen storage and inflammatory genes in skeletal muscle Correspondence 1 1 2 1,2 Jonathan M Mudry , Julie Massart , Ferenc L M Szekeres and Anna Krook should be addressed to A Krook 1Section for Integrative Physiology, Department of Molecular Medicine and Surgery, and 2Section for Integrative Email Physiology, Department of Physiology and Pharmacology, Karolinska Institutet, SE-171 77 Stockholm, Sweden [email protected] Abstract TWIST proteins are important for development of embryonic skeletal muscle and play a role Key Words in the metabolism of tumor and white adipose tissue. The impact of TWIST on metabolism " TWIST in skeletal muscle is incompletely studied. Our aim was to assess the impact of TWIST1 " metabolism and TWIST2 overexpression on glucose and lipid metabolism. In intact mouse muscle, " glycogen overexpression of Twist reduced total glycogen content without altering glucose uptake. " skeletal muscle Expression of TWIST1 or TWIST2 reduced Pdk4 mRNA, while increasing mRNA levels of Il6, Tnfa, and Il1b. Phosphorylation of AKT was increased and protein abundance of acetyl CoA carboxylase (ACC) was decreased in skeletal muscle overexpressing TWIST1 or TWIST2. Glycogen synthesis and fatty acid oxidation remained stable in C2C12 cells overexpressing TWIST1 or TWIST2. Finally, skeletal muscle mRNA levels remain unaltered in ob/ob mice, type 2 diabetic patients, or in healthy subjects before and after 3 months of exercise training. Journal of Endocrinology Collectively, our results indicate that TWIST1 and TWIST2 are expressed in skeletal muscle. Overexpression of these proteins impacts proteins in metabolic pathways and mRNA level of cytokines.