Challenges in Automated Classification Using Library Classification Schemes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Library N Info SCI Ebooks
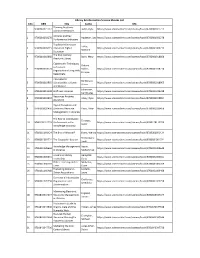
Library & Information Science Ebooks List S.No ISBN Title Author URL Planning Academic 1 9780081021712 Bailin, Kylie https://www.sciencedirect.com/science/book/9780081021712 Library Orientations Libraries and Key 2 9780081002278 Appleton, Leo https://www.sciencedirect.com/science/book/9780081002278 Performance Indicators Teaching Information Lokse, 3 9780081009215 Literacy in Higher https://www.sciencedirect.com/science/book/9780081009215 Mariann Education The 21st Century 4 9780081018668 Bolin, Mary https://www.sciencedirect.com/science/book/9780081018668 Academic Library Cybermetric Techniques Orduna- to Evaluate 5 9780081018774 Malea, https://www.sciencedirect.com/science/book/9780081018774 Organizations Using Web- Enrique Based Data International Bordonaro, 6 9780081018965 Librarianship at Home https://www.sciencedirect.com/science/book/9780081018965 Karen and Abroad Johanssen, 7 9780081019238 Staff-Less Libraries https://www.sciencedirect.com/science/book/9780081019238 Carl Gustav Resources Anytime, 8 9780081019894 Litsey, Ryan https://www.sciencedirect.com/science/book/9780081019894 Anywhere Digital Disruption and 9 9780081020456 Electronic Resource Patra, Nihar https://www.sciencedirect.com/science/book/9780081020456 Management in Libraries The Role of Information Tarango, 10 9780128112229 Professionals in the https://www.sciencedirect.com/science/book/9780128112229 Javier Knowledge Economy 11 9780081001424 The End of Wisdom? Evans, Wendy https://www.sciencedirect.com/science/book/9780081001424 Frederiksen, 12 9780081001721 The -

Catalogue and Index
ISSN 2399-9667 Catalogue and Index Periodical of the Cataloguing and Indexing Group, a Special Interest Group of CILIP, the Library and Information Association Editorial September 2017, Issue 188 Contents 3-10 Deborah Lee & Classification is the theme of this bumper issue of Catalogue and Index. Anastasia Kerameos There was a tremendous response to the call for papers, illustrating the importance and interest in classification to the U.K. cataloguing and 11-16 John Akeroyd & metadata community. The classification discussed in this issue comes in many flavours, including the usage of classification schemes, digital tools Aida Slavic for classification, the theory of classification, reclassification, and much 17-20 Vanda Broughton more besides. 21-26 Sean Goddard & The issue starts by exploring the usage of classification schemes. Deborah Lee and Anastasia Kerameos outline the results of a survey Tim Haillay into U.K. classification practices, linked to the recent CILIP CIG workshop “Thinking about classification”. John Ackeroyd and Aida Slavic 27-29 Jane Del-Pizzo discuss how UDC is used, including survey results relating to the U.K. 30-33 Marcin Trzmielewski, and the use of UDC in repositories and as part of catalogue records. Vanda Broughton discusses classification theory and how classification Claudio Gnoli, Marco (and classification schemes) are still a critical part of organizing Lardera, Gaia Heidi information. Pallestrini & Matea Sipic Reclassification is another significant part of cataloguing and 34-37 Nicky Ransom classification life, and this issue is a rich source of information about 38-42 Penny Doulgeris various reclassification projects. Sean Goddard and Tim Haillay describe a reclassification project at the University of Sussex, specifically 43-45 Mary Mitchell focussed on language and literature. -

Theory and Practice. Drexel Univ., Philadelphia, Pa. Graduate
DOCUMENT RESUME F 680 IR 002 925 AUTHOR Painter, Ann F., Ed. TITLE Classification: Theory and Practice. INSTITUTION Drexel Univ., Philadelphia, Pa. Graduate Schoolof Library Science. PUB DATE Oct 74 NOTE 125p. JOURNAL CIT Drexel Library Quarterly; v10 n4 Oct 74 EDRS PRICE MF-$0.76 HC-$5.70 Plus Postage DESCRIPTORS *Classification; Cluster Grouping; Futures (of Society); Information Retrieval; *Library Automation; *Library Science; Library Technical Processes IDENTIFIERS Dewey Decimal Classification; Library of Congress Classification; Universal Decimal Classification ABSTRACT In response to recent trends towards automated bibliographic control, this issue of "Drexel LibraryQuarterly" discusses present day bibliographic classificationschemes and offers some insight into the future. Thisvolume contains essays which: (1) define "classification";(2) provide historical ,background; (3) examine the Dewey Decimal System, the Library of Congress Classification, and the Universal Decimal Classification;(4) discuss research and development of automated systems; and(5) make predictions for the future. (EMH) *********************************************************************** Documents acquired by ERIC include manyinformal unpublished * materials not available from other sources.ERIC makes every effort * * to obtain the best copy available.Nevertheless, items of marginal * * reproducibility are often encounteredand this affects the quality * * of the microfiche and hardcopyreproductions ERIC makes available * * via the ERIC Document ReproductionService -

Reconsidering Library of Congress Classification in US Law Libraries
LAW LIBRARY JOURNAL Vol. 106:1 [2014-5] It’s All Enumerative: Reconsidering Library of Congress Classification in U.S. Law Libraries* Kristen M. Hallows** Ms. Hallows investigates the widespread use of the Library of Congress Classification system in U.S. law libraries and the difficulties it can present in some circumstances. To address these problems, she proposes that smaller law libraries that do not par- ticipate in a bibliographic utility may benefit from an in-house classification scheme. Introduction ¶1 At its most basic level, the human impulse to classify emerges from our strong desire to know what to expect. New things that resemble familiar things need little or no further examination. Quite simply, “we know what to expect of a dog or a banana, since they are similar to dogs and bananas we already know.”1 ¶2 Classification also provides a means of organization. One of the most fun- damental concepts learned in a library and information science program is that we organize to retrieve; therefore, classification is not only helpful but also necessary if we are to benefit from the information we acquire and produce. Further, we may also classify to facilitate browsing and therefore discovery—even in an online envi- ronment such as the library catalog,2 though physical collections are the focus of this article. ¶3 In an increasingly digital world, classification may seem like a quaint notion from the past. In a database, it is unnecessary to store records using any particular system, as long as those records relevant to a search are displayed or sorted in a useful way. -

The Effects of Classification Systems on Management and Access in Selected Elementary School Libraries" (1986)
Old Dominion University ODU Digital Commons Theses and Dissertations in Urban Services - Urban College of Education & Professional Studies Education (Darden) Summer 1986 The ffecE ts of Classification Systems on Management and Access in Selected Elementary School Libraries Ellen L. Miller Old Dominion University Follow this and additional works at: https://digitalcommons.odu.edu/ urbanservices_education_etds Recommended Citation Miller, Ellen L.. "The Effects of Classification Systems on Management and Access in Selected Elementary School Libraries" (1986). Doctor of Philosophy (PhD), dissertation, , Old Dominion University, DOI: 10.25777/2ewx-2p03 https://digitalcommons.odu.edu/urbanservices_education_etds/3 This Dissertation is brought to you for free and open access by the College of Education & Professional Studies (Darden) at ODU Digital Commons. It has been accepted for inclusion in Theses and Dissertations in Urban Services - Urban Education by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. THE EFFECTS OF CLASSIFICATION SYSTEMS ON MANAGEMENT AND ACCESS IN SELECTED ELEMENTARY SCHOOL LIBRARIES by Ellen L. Miller B.S. January 1973, Old Dominion University M.S. August 1976, Old Dominion University A Dissertation Submitted to the Faculty of Old Dominion University in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY URBAN SERVICES OLD DOMINION UNIVERSITY August, 1986 Executive Director ther Chairperson Concentration Director Dean of the Darde Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. ABSTRACT THE EFFECTS OF CLASSIFICATION SYSTEMS ON MANAGEMENT AND ACCESS IN SELECTED ELEMENTARY SCHOOL LIBRARIES Ellen Lowe Miller Old Dominion University, 1986 Director: Dr. Katherine T. Bucher Without an adequate access and delivery system for "easy" books, young children are locked out of the vast literary resources of elementary school libraries. -

A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel University of Pennsylvania, [email protected]
University of Pennsylvania ScholarlyCommons Departmental Papers (ASC) Annenberg School for Communication 2018 A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/asc_papers Part of the Communication Commons Recommended Citation Lingel, J. (2018). A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility. Public Culture, 30 (2), 305-327. https://doi.org/10.1215/08992363-4310942 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/asc_papers/707 For more information, please contact [email protected]. A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Disciplines Communication | Social and Behavioral Sciences This journal article is available at ScholarlyCommons: https://repository.upenn.edu/asc_papers/707 A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel There is a mismatch between what libraries do and how they are perceived, between how they are used by local patrons and how they are used as punch lines in conversations about civic resources and technological change. In the United States, public libraries have been woven into the social and spatial fabric of neighborhood life, whether urban, suburban, or rural, and they enjoy immense popularity: According to a 2014 study from the Pew Research Center (2014), 54 percent of people in the United States use a public library each year, 72 percent of people live in a household with a regular library user, and libraries are viewed as important community resources by 91 percent of people. As library historian Wayne Wiegand (2011) has repeatedly pointed out, there are more public libraries in the United States than there are McDonald’s. -

Libraries in Secondary Schools
Australian Council for Educational Research (ACER) ACEReSearch Information Management Cunningham Library 1945 Libraries in secondary schools: a report on the libraries of secondary schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian Institute of Librarians (Victorian Branch) Frank G. Kirby Follow this and additional works at: https://research.acer.edu.au/information_management Part of the Educational Assessment, Evaluation, and Research Commons, Library and Information Science Commons, and the Secondary Education Commons Recommended Citation Kirby, Frank G. (1945). Libraries in secondary schools: a report on the libraries of secondary schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian Institute of Librarians (Victorian Branch) This Book is brought to you by the Cunningham Library at ACEReSearch. It has been accepted for inclusion in Information Management by an authorized administrator of ACEReSearch. For more information, please contact [email protected]. LIBRARIES IN SECONDARY SCHOOLS A Report on the Libraries of Secondary Schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian lnstitutp of Librarians ( Victorian Branch) by FRANK G. KIRBY, M.A. (Librarian, Scotch College, Melbourne; Member of the A.l.L.; formerly of the Public Library. of Victoria.) MELBOURNE UNIVERSITY PRESS 1945 Publication of this Report was made possible by a grant from the Australian Council for Educational Research From, the collection of Emeritus Professor Bill Connell was a leader in building educational studies in Australian universities during the twentieth century. Margaret Connell worked closely with Bill on a wide range of educational projects over a period of sixty years. -

A Study of Web-Based Library Classification Schemes
Vol. 5(10), pp. 386-393, November, 2013 DOI: 10.5897/IJLIS2013.0336 International Journal of Library and Information ISSN 2141–2537 ©2013 Academic Journals Science http://www.academicjournals.org/IJLIS Full Length Research Paper A study of web-based library classification schemes Pranali B. Gedam1* and Ashwini Paradkar2 1Manoharbhai Patel College of Arts, Commerce and Science, Sakoli Dist- Bhandara, India. 2St. Francis De Sales College, Nagpur, Maharashtra 440006, India. Accepted 29 March, 2013 The study deals with web-based library classification schemes. In the emerging digital paradigm, the library classification schemes sparked dynamically print into web in the beginning of 21st century. Web- based library classification schemes are completely different from traditional classification schemes. The study discusses three web-based schemes viz WebDewey 2.0, UDC (universal decimal classification) online and classification web. WebDewey 2.0 is a Web-based product of DDC 23rd ed., UDC online is of UDC and classification web of LCC (Library of Congress Classification). These are constantly updated, revised and up-to date web-based library classification schemes. This study is significant in that it provided a description of current trends of library classification schemes. Investigative method is used to identify web-based library classification schemes. The databases have been accessed through trial accounts of their official websites. This study mainly compares the aspects of WebDewey 2.0, UDC online, and classification web. It concludes that DDC (Dewey Decimal Classification) is the most updated library classification scheme in the world. Key words: Web-based library classification schemes, WebDewey 2.0, Universal Decimal Classification online, classification web. -

Library Classification Systems and Organization of Islamic Knowledge Current Global Scenario and Optimal Solution
LRTS 56(3) 171 Library Classification Systems and Organization of Islamic Knowledge Current Global Scenario and Optimal Solution Haroon Idrees Standard library classification systems like Dewey Decimal Classification (DDC), U.S. Library of Congress Classification (LCC), and Universal Decimal Classification (UDC) are internationally known and widely used by librar- ies as the tools for organizing information. Charles Ammi Cutter’s Expansive Classification (EC), James Duff Brown’s Subject Classification (SC), Henry E. Bliss’ Bibliographic Classification (BC), and S. R. Ranganathan’s Colon Classification (CC) also are standard classification systems, but they are less commonly used compared to aforementioned three systems. All these systems are easy to use and convenient for most general collection libraries. However, these systems are not adequate for some special collections. Libraries with rich collec- tions on Islam also face problems while using these systems, although such librar- ies often use expansions in the original systems for their collections. This paper examines this problem and presents a potential optimal solution. The author collected data, using a semistructured interview technique, from a representative sample of thirty libraries in eight countries with strong collections in Islam. These data were analyzed employing qualitative methods. ewey Decimal Classification (DDC), Charles Ammi Cutter’s Expansive Haroon Idrees (h.haroonidrees@gmail .com) is Senior Librarian, Islamic Research D Classification (EC), James Duff Brown’s Subject Classification (SC), U.S. Institute, International Islamic University, Library of Congress Classification (LCC), Universal Decimal Classification Islamabad, Pakistan, and a PhD candi- (UDC), Henry E. Bliss’s Bibliographic Classification (BC), and S. R. Rangana- date at the Berlin School of Library and Information Science, Humboldt Universi- than’s Colon Classification (CC) are internationally known standard classification ty of Berlin. -

LIBRARIES Learn Dewey Decimal Classification.Pdf
LIBRARY EDUCATION SERIES Learn DEWEY DECIMAL CLASSIFICATION (Edition 22) FIRST NORTH AMERICAN EDITION by Mary Mortimer TOTALRECALL PUBLICATIONS, INC. TotalRecall Publications, Inc. Learn Dewey Decimal Classification (Edition 21) first published in the United States of America by Scarecrow Press, Inc. 2000 First North American edition of Learn Dewey Decimal Classification (Edition 22) DocMatrix Pty Ltd 2007 Based on previous Australasian editions DocMatrix Pty Ltd 1997, 1998, 2004, 2007. All rights reserved. Published simultaneously by TotalRecall Publications, Inc. in the United States of America, Canada, England and other countries around the world except the Pacific Rim. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means electronic or mechanical or by photocopying, recording, or otherwise without the prior permission of the publisher. The views expressed in this book are solely those of the author, and do not represent the views of any other party or parties. ISBN 978- 1-59095-804-9 REPRINTED UNDER SPECIAL ARRANGEMENT WITH PUBLISHER BY TOTALRECALL PUBLICATIONS, Inc. 1103 Middlecreek, Friendswood, Texas, 77546 Telephone (281) 992-3131 Fax (281) 482-5390 Email [email protected] Some or all of this publication is subject to an exclusive publishing license in Australia, New Zealand, Papua New Guinea and Hong Kong. The holder of that license reserves all its rights. Importing this publication into any of those countries may infringe those exclusive rights, placing the importer at risk of an infringement claim. Importers are recommended to seek independent legal advice to determine if importation of publications into those countries, including by way of international sale, infringe those rights. -

The Development of Classification at the Library of Congress
I LL I N I S UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN PRODUCTION NOTE University of Illinois at Urbana-Champaign Library Large-scale Digitization Project, 2007. University of Illinois Graduate School of Library and Information Science 41:',X1 -,-A 4"ER PA !!9 =01.1ISSN 0272 1769 Number 164 August 1984 The Development of Classification at the Library of Congress by Francis Miksa The Development of Classification at the Library of Congress by Francis Miksa ©1984 The Board of Trustees of The University of Illinois Contents Introduction .......................... ....... ...... ......... 3 Early Growth of the Collections ................................. 3 Subject Access During the Early Years ........................ ..... 5 A.R. Spofford and the Growth of the Library of Congress ........... 9 Spofford and Subject Access ..................................... 10 From Spofford to John Russell Young ......................... 15 Trends in Classification .............................. ... ........ 16 A Tentative Beginning, 1897-98 ................................ 18 Years of Decision, 1899-1901 ................ .................. 21 Classification Development, 1901-11: General Features ............. 23 Classification Development, 1901-11: Collocation Patterns.......... 25 Likenesses with Other Schemes ......................... ...... 25 A Unique Departure ....................................... 26 A Fundamental Tension .................................... 27 Common Arrangement Patterns ......................... ...... 28 Adaptation for Particular -

Conceptualizing a Future for Library Classification
Wisdom in Education Volume 5 Issue 2 Article 3 11-1-2015 Conceptualizing a Future for Library Classification Risa M. Lumley California State University, San Bernardino Palm Desert, [email protected] Follow this and additional works at: https://scholarworks.lib.csusb.edu/wie Part of the Higher Education Commons, and the Social and Philosophical Foundations of Education Commons Recommended Citation Lumley, Risa M. (2015) "Conceptualizing a Future for Library Classification," Wisdom in Education: Vol. 5 : Iss. 2 , Article 3. Available at: https://scholarworks.lib.csusb.edu/wie/vol5/iss2/3 This Article is brought to you for free and open access by CSUSB ScholarWorks. It has been accepted for inclusion in Wisdom in Education by an authorized editor of CSUSB ScholarWorks. For more information, please contact [email protected]. Conceptualizing a Future for Library Classification Abstract This paper traces the roots of the positivist epistemology of librarianship; its ideals of neutrality and access as they intersect in the classification and assignment of library subject headings; and the notion of the author as it relates to the creation of library authority files. By legitimizing their own professional neutrality, librarians have wielded tremendous power over what libraries collect as well as how those works are represented, but have done so with little self-reflection. The act of classifying works and assigning subject headings is not a neutral process. It is time for librarians to use new tools such as the RDA standards to hold academic libraries accountable for assessing their collections to ensure they represent the diversity of voices that comprise the full record and collective history of our culture.