Patterns of Sequence Conservation in Presynaptic Neural Genes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Analysis of Retinopathy in Type 1 Diabetes
Genetic Analysis of Retinopathy in Type 1 Diabetes by Sayed Mohsen Hosseini A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Institute of Medical Science University of Toronto © Copyright by S. Mohsen Hosseini 2014 Genetic Analysis of Retinopathy in Type 1 Diabetes Sayed Mohsen Hosseini Doctor of Philosophy Institute of Medical Science University of Toronto 2014 Abstract Diabetic retinopathy (DR) is a leading cause of blindness worldwide. Several lines of evidence suggest a genetic contribution to the risk of DR; however, no genetic variant has shown convincing association with DR in genome-wide association studies (GWAS). To identify common polymorphisms associated with DR, meta-GWAS were performed in three type 1 diabetes cohorts of White subjects: Diabetes Complications and Control Trial (DCCT, n=1304), Wisconsin Epidemiologic Study of Diabetic Retinopathy (WESDR, n=603) and Renin-Angiotensin System Study (RASS, n=239). Severe (SDR) and mild (MDR) retinopathy outcomes were defined based on repeated fundus photographs in each study graded for retinopathy severity on the Early Treatment Diabetic Retinopathy Study (ETDRS) scale. Multivariable models accounted for glycemia (measured by A1C), diabetes duration and other relevant covariates in the association analyses of additive genotypes with SDR and MDR. Fixed-effects meta- analysis was used to combine the results of GWAS performed separately in WESDR, ii RASS and subgroups of DCCT, defined by cohort and treatment group. Top association signals were prioritized for replication, based on previous supporting knowledge from the literature, followed by replication in three independent white T1D studies: Genesis-GeneDiab (n=502), Steno (n=936) and FinnDiane (n=2194). -

Propranolol-Mediated Attenuation of MMP-9 Excretion in Infants with Hemangiomas
Supplementary Online Content Thaivalappil S, Bauman N, Saieg A, Movius E, Brown KJ, Preciado D. Propranolol-mediated attenuation of MMP-9 excretion in infants with hemangiomas. JAMA Otolaryngol Head Neck Surg. doi:10.1001/jamaoto.2013.4773 eTable. List of All of the Proteins Identified by Proteomics This supplementary material has been provided by the authors to give readers additional information about their work. © 2013 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 10/01/2021 eTable. List of All of the Proteins Identified by Proteomics Protein Name Prop 12 mo/4 Pred 12 mo/4 Δ Prop to Pred mo mo Myeloperoxidase OS=Homo sapiens GN=MPO 26.00 143.00 ‐117.00 Lactotransferrin OS=Homo sapiens GN=LTF 114.00 205.50 ‐91.50 Matrix metalloproteinase‐9 OS=Homo sapiens GN=MMP9 5.00 36.00 ‐31.00 Neutrophil elastase OS=Homo sapiens GN=ELANE 24.00 48.00 ‐24.00 Bleomycin hydrolase OS=Homo sapiens GN=BLMH 3.00 25.00 ‐22.00 CAP7_HUMAN Azurocidin OS=Homo sapiens GN=AZU1 PE=1 SV=3 4.00 26.00 ‐22.00 S10A8_HUMAN Protein S100‐A8 OS=Homo sapiens GN=S100A8 PE=1 14.67 30.50 ‐15.83 SV=1 IL1F9_HUMAN Interleukin‐1 family member 9 OS=Homo sapiens 1.00 15.00 ‐14.00 GN=IL1F9 PE=1 SV=1 MUC5B_HUMAN Mucin‐5B OS=Homo sapiens GN=MUC5B PE=1 SV=3 2.00 14.00 ‐12.00 MUC4_HUMAN Mucin‐4 OS=Homo sapiens GN=MUC4 PE=1 SV=3 1.00 12.00 ‐11.00 HRG_HUMAN Histidine‐rich glycoprotein OS=Homo sapiens GN=HRG 1.00 12.00 ‐11.00 PE=1 SV=1 TKT_HUMAN Transketolase OS=Homo sapiens GN=TKT PE=1 SV=3 17.00 28.00 ‐11.00 CATG_HUMAN Cathepsin G OS=Homo -
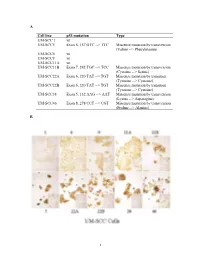
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Transcriptomic Analysis of the Aquaporin (AQP) Gene Family
Pancreatology 19 (2019) 436e442 Contents lists available at ScienceDirect Pancreatology journal homepage: www.elsevier.com/locate/pan Transcriptomic analysis of the Aquaporin (AQP) gene family interactome identifies a molecular panel of four prognostic markers in patients with pancreatic ductal adenocarcinoma Dimitrios E. Magouliotis a, b, Vasiliki S. Tasiopoulou c, Konstantinos Dimas d, * Nikos Sakellaridis d, Konstantina A. Svokos e, Alexis A. Svokos f, Dimitris Zacharoulis b, a Division of Surgery and Interventional Science, Faculty of Medical Sciences, UCL, London, UK b Department of Surgery, University of Thessaly, Biopolis, Larissa, Greece c Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece d Department of Pharmacology, Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece e The Warren Alpert Medical School of Brown University, Providence, RI, USA f Riverside Regional Medical Center, Newport News, VA, USA article info abstract Article history: Background: This study aimed to assess the differential gene expression of aquaporin (AQP) gene family Received 14 October 2018 interactome in pancreatic ductal adenocarcinoma (PDAC) using data mining techniques to identify novel Received in revised form candidate genes intervening in the pathogenicity of PDAC. 29 January 2019 Method: Transcriptome data mining techniques were used in order to construct the interactome of the Accepted 9 February 2019 AQP gene family and to determine which genes members are differentially expressed in PDAC as Available online 11 February 2019 compared to controls. The same techniques were used in order to evaluate the potential prognostic role of the differentially expressed genes. Keywords: PDAC Results: Transcriptome microarray data of four GEO datasets were incorporated, including 142 primary Aquaporin tumor samples and 104 normal pancreatic tissue samples. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Steroid-Dependent Regulation of the Oviduct: a Cross-Species Transcriptomal Analysis
University of Kentucky UKnowledge Theses and Dissertations--Animal and Food Sciences Animal and Food Sciences 2015 Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis Katheryn L. Cerny University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Cerny, Katheryn L., "Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis" (2015). Theses and Dissertations--Animal and Food Sciences. 49. https://uknowledge.uky.edu/animalsci_etds/49 This Doctoral Dissertation is brought to you for free and open access by the Animal and Food Sciences at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Animal and Food Sciences by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -

Transcriptomic Analysis of Native Versus Cultured Human and Mouse Dorsal Root Ganglia Focused on Pharmacological Targets Short
bioRxiv preprint doi: https://doi.org/10.1101/766865; this version posted September 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Transcriptomic analysis of native versus cultured human and mouse dorsal root ganglia focused on pharmacological targets Short title: Comparative transcriptomics of acutely dissected versus cultured DRGs Andi Wangzhou1, Lisa A. McIlvried2, Candler Paige1, Paulino Barragan-Iglesias1, Carolyn A. Guzman1, Gregory Dussor1, Pradipta R. Ray1,#, Robert W. Gereau IV2, # and Theodore J. Price1, # 1The University of Texas at Dallas, School of Behavioral and Brain Sciences and Center for Advanced Pain Studies, 800 W Campbell Rd. Richardson, TX, 75080, USA 2Washington University Pain Center and Department of Anesthesiology, Washington University School of Medicine # corresponding authors [email protected], [email protected] and [email protected] Funding: NIH grants T32DA007261 (LM); NS065926 and NS102161 (TJP); NS106953 and NS042595 (RWG). The authors declare no conflicts of interest Author Contributions Conceived of the Project: PRR, RWG IV and TJP Performed Experiments: AW, LAM, CP, PB-I Supervised Experiments: GD, RWG IV, TJP Analyzed Data: AW, LAM, CP, CAG, PRR Supervised Bioinformatics Analysis: PRR Drew Figures: AW, PRR Wrote and Edited Manuscript: AW, LAM, CP, GD, PRR, RWG IV, TJP All authors approved the final version of the manuscript. 1 bioRxiv preprint doi: https://doi.org/10.1101/766865; this version posted September 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

EFA6A, an Exchange Factor for Arf6, Regulates Early Steps in Ciliogenesis
EFA6A, an exchange factor for Arf6, regulates early steps in ciliogenesis Mariagrazia Partisani, Carole Baron, Rania Ghossoub, Racha Fayad, Sophie Pagnotta, Sophie Abélanet, Eric Macia, Frédéric Brau, Sandra Lacas-Gervais, Alexandre Benmerah, et al. To cite this version: Mariagrazia Partisani, Carole Baron, Rania Ghossoub, Racha Fayad, Sophie Pagnotta, et al.. EFA6A, an exchange factor for Arf6, regulates early steps in ciliogenesis. Journal of Cell Science, Company of Biologists, 2021, 134 (2), pp.jcs249565. 10.1242/jcs.249565. hal-03120586 HAL Id: hal-03120586 https://hal.archives-ouvertes.fr/hal-03120586 Submitted on 19 Apr 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. © 2021. Published by The Company of Biologists Ltd | Journal of Cell Science (2021) 134, jcs249565. doi:10.1242/jcs.249565 RESEARCH ARTICLE EFA6A, an exchange factor for Arf6, regulates early steps in ciliogenesis Mariagrazia Partisani1, Carole L. Baron1, Rania Ghossoub2, Racha Fayad1, Sophie Pagnotta3, Sophie Abélanet1, Eric Macia1,Frédéric Brau1, Sandra Lacas-Gervais3, Alexandre Benmerah4,Frédéric Luton1 and Michel Franco1,* ABSTRACT localized to the PC and which play an important role in its assembly Ciliogenesis is a coordinated process initiated by the recruitment and and/or function. -

1 UST College of Science Department of Biological Sciences
UST College of Science Department of Biological Sciences 1 Pharmacogenomics of Myofascial Pain Syndrome An Undergraduate Thesis Submitted to the Department of Biological Sciences College of Science University of Santo Tomas In Partial Fulfillment of the Requirements for the Degree of Bachelor of Science in Biology Jose Marie V. Lazaga Marc Llandro C. Fernandez May 2021 UST College of Science Department of Biological Sciences 2 PANEL APPROVAL SHEET This undergraduate research manuscript entitled: Pharmacogenomics of Myofascial Pain Syndrome prepared and submitted by Jose Marie V. Lazaga and Marc Llandro C. Fernandez, was checked and has complied with the revisions and suggestions requested by panel members after thorough evaluation. This final version of the manuscript is hereby approved and accepted for submission in partial fulfillment of the requirements for the degree of Bachelor of Science in Biology. Noted by: Asst. Prof. Marilyn G. Rimando, PhD Research adviser, Bio/MicroSem 602-603 Approved by: Bio/MicroSem 603 panel member Bio/MicroSem 603 panel member Date: Date: UST College of Science Department of Biological Sciences 3 DECLARATION OF ORIGINALITY We hereby affirm that this submission is our own work and that, to the best of our knowledge and belief, it contains no material previously published or written by another person nor material to which a substantial extent has been accepted for award of any other degree or diploma of a university or other institute of higher learning, except where due acknowledgement is made in the text. We also declare that the intellectual content of this undergraduate research is the product of our work, even though we may have received assistance from others on style, presentation, and language expression. -

Supplemental Information IRF4 Transcription Factor-Dependent Cd11b+ Dendritic Cells in Human and Mouse Control Mucosal IL-17 C
Immunity, Volume 38 Supplemental Information IRF4 Transcription Factor-Dependent CD11b+ Dendritic Cells in Human and Mouse Control Mucosal IL-17 Cytokine Responses Andreas Schlitzer, Naomi McGovern, Pearline Teo, Teresa Zelante, Koji Atarashi, Donovan Low, Adrian W.S. Ho, Peter See, Amanda Shin, Pavandip Singh Wasan, Guillaume Hoeffel, Benoit Malleret, Alexander Heiseke, Samantha Chew, Laura Jardine, Harriet A. Purvis, Catharien M.U. Hilkens, John Tam, Michael Poidinger, E. Richard Stanley, Anne B. K rug, Laurent Renia, Baalasubramanian Sivasankar, Lai Guan Ng, Matthew Collin, Paola Ricciardi-Castagnoli, Kenya Honda, Muzlifah Haniffa, and Florent Ginhoux Supplemental Inventory 1. Supplemental Figures and Tables Figure S1, Related to Figure 1 Figure S2, Related to Figure 2 and 3 Figure S3, Related to Figure 4 Figure S4, Related to Figure 5 Figure S5, Related to Figure 5 Figure S6, Related to Figure 7 Table S1, Related to Figure 3 Table S2, Related to Figure 6 Table S3, Related to Figure 6 2. Supplemental Experimental Procedures 3. Supplemental References Supplementary figure 1 Sorting strategy for mouse lung and small intestinal DC A Sorting strategy, Lung Singlets Dapi-CD45+ 250K 250K 250K 105 200K 200K 200K 104 A I - 150K 150K 150K C P C C 3 10 S A S S 100K 100K S 100K D S S 102 50K 50K 50K 0 0 0 0 0 50K 100K 150K 200K 250K 0 50K 100K 150K 200K 250K 0 103 104 105 0 103 104 105 FSC FSC-W CD45 GR1 Auto Fluor.- MHCII+ GR1- SSClow CD11c+ CD11b+ 250K 105 105 105 200K 4 104 10 104 150K I 3 I 3 4 3 0 10 3 C 2 H 10 10 100K 1 S D C D S C M 2 C 10 50K 0 0 0 0 0 102 103 104 105 0 103 104 105 0 103 104 105 0 103 104 105 Auto fluor. -

Redefining the Specificity of Phosphoinositide-Binding by Human
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Redefining the specificity of phosphoinositide-binding by human PH domain-containing proteins Nilmani Singh1†, Adriana Reyes-Ordoñez1†, Michael A. Compagnone1, Jesus F. Moreno Castillo1, Benjamin J. Leslie2, Taekjip Ha2,3,4,5, Jie Chen1* 1Department of Cell & Developmental Biology, University of Illinois at Urbana-Champaign, Urbana, IL 61801; 2Department of Biophysics and Biophysical Chemistry, Johns Hopkins University School of Medicine, Baltimore, MD 21205; 3Department of Biophysics, Johns Hopkins University, Baltimore, MD 21218; 4Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD 21205; 5Howard Hughes Medical Institute, Baltimore, MD 21205, USA †These authors contributed equally to this work. *Correspondence: [email protected]. bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. ABSTRACT Pleckstrin homology (PH) domains are presumed to bind phosphoinositides (PIPs), but specific interaction with and regulation by PIPs for most PH domain-containing proteins are unclear. Here we employed a single-molecule pulldown assay to study interactions of lipid vesicles with full-length proteins in mammalian whole cell lysates. -

A Human Population-Based Organotypic in Vitro Model for Cardiotoxicity Screening1
ALTEX preprint published July 8, 2018 doi:10.14573/altex.1805301 Research Article A human population-based organotypic in vitro model for cardiotoxicity screening1 Fabian A. Grimm1, Alexander Blanchette1, John S. House2, Kyle Ferguson1, Nan-Hung Hsieh1, Chimeddulam Dalaijamts1, Alec A. Wright1, Blake Anson5, Fred A. Wright3,4, Weihsueh A. Chiu1, Ivan Rusyn1 1Department of Veterinary Integrative Biosciences, Texas A&M University, College Station, TX, USA; 2Bioinformatics Research Center, 3Department of Biological Sciences, and 4Department of Statistics, North Carolina State University, Raleigh, NC, USA; 5Cellular Dynamics International, Madison, WI, USA Abstract Assessing inter-individual variability in responses to xenobiotics remains a substantial challenge, both in drug development with respect to pharmaceuticals and in public health with respect to environmental chemicals. Although approaches exist to characterize pharmacokinetic variability, there are no methods to routinely address pharmacodynamic variability. In this study, we aimed to demonstrate the feasibility of characterizing inter-individual variability in a human in vitro model. Specifically, we hypothesized that genetic variability across a population of iPSC- derived cardiomyocytes translates into reproducible variability in both baseline phenotypes and drug responses. We measured baseline and drug-related effects in iPSC-derived cardiomyocytes from 27 healthy donors on kinetic Ca2+ flux and high-content live cell imaging. Cells were treated in concentration-response with cardiotoxic drugs: isoproterenol (β- adrenergic receptor agonist/positive inotrope), propranolol (β-adrenergic receptor antagonist/negative inotrope), and cisapride (hERG channel inhibitor/QT prolongation). Cells from four of the 27 donors were further evaluated in terms of baseline and treatment-related gene expression. Reproducibility of phenotypic responses was evaluated across batches and time.