Automatic Organization of Digital Music Documents – Sheet Music and Audio
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Timeline of the Evolutionary History of Life
Timeline of the evolutionary history of life This timeline of the evolutionary history of life represents the current scientific theory Life timeline Ice Ages outlining the major events during the 0 — Primates Quater nary Flowers ←Earliest apes development of life on planet Earth. In P Birds h Mammals – Plants Dinosaurs biology, evolution is any change across Karo o a n ← Andean Tetrapoda successive generations in the heritable -50 0 — e Arthropods Molluscs r ←Cambrian explosion characteristics of biological populations. o ← Cryoge nian Ediacara biota – z ← Evolutionary processes give rise to diversity o Earliest animals ←Earliest plants at every level of biological organization, i Multicellular -1000 — c from kingdoms to species, and individual life ←Sexual reproduction organisms and molecules, such as DNA and – P proteins. The similarities between all present r -1500 — o day organisms indicate the presence of a t – e common ancestor from which all known r Eukaryotes o species, living and extinct, have diverged -2000 — z o through the process of evolution. More than i Huron ian – c 99 percent of all species, amounting to over ←Oxygen crisis [1] five billion species, that ever lived on -2500 — ←Atmospheric oxygen Earth are estimated to be extinct.[2][3] Estimates on the number of Earth's current – Photosynthesis Pong ola species range from 10 million to 14 -3000 — A million,[4] of which about 1.2 million have r c been documented and over 86 percent have – h [5] e not yet been described. However, a May a -3500 — n ←Earliest oxygen 2016 -

Integrative and Comparative Biology Integrative and Comparative Biology, Volume 58, Number 4, Pp
Integrative and Comparative Biology Integrative and Comparative Biology, volume 58, number 4, pp. 605–622 doi:10.1093/icb/icy088 Society for Integrative and Comparative Biology SYMPOSIUM INTRODUCTION The Temporal and Environmental Context of Early Animal Evolution: Considering All the Ingredients of an “Explosion” Downloaded from https://academic.oup.com/icb/article-abstract/58/4/605/5056706 by Stanford Medical Center user on 15 October 2018 Erik A. Sperling1 and Richard G. Stockey Department of Geological Sciences, Stanford University, 450 Serra Mall, Building 320, Stanford, CA 94305, USA From the symposium “From Small and Squishy to Big and Armored: Genomic, Ecological and Paleontological Insights into the Early Evolution of Animals” presented at the annual meeting of the Society for Integrative and Comparative Biology, January 3–7, 2018 at San Francisco, California. 1E-mail: [email protected] Synopsis Animals originated and evolved during a unique time in Earth history—the Neoproterozoic Era. This paper aims to discuss (1) when landmark events in early animal evolution occurred, and (2) the environmental context of these evolutionary milestones, and how such factors may have affected ecosystems and body plans. With respect to timing, molecular clock studies—utilizing a diversity of methodologies—agree that animal multicellularity had arisen by 800 million years ago (Ma) (Tonian period), the bilaterian body plan by 650 Ma (Cryogenian), and divergences between sister phyla occurred 560–540 Ma (late Ediacaran). Most purported Tonian and Cryogenian animal body fossils are unlikely to be correctly identified, but independent support for the presence of pre-Ediacaran animals is recorded by organic geochemical biomarkers produced by demosponges. -

Vr 1724 (05/2019)
Supported Employment Manual Oregon Vocational Rehabilitation Revised: 5/30/19 500 Summer ST NE, E87 Salem, OR 97301-1120 [email protected] Contents Scope of Vocational Rehabilitation Services ........................................... 3 Collaboration with other agencies .............................................................................. 3 1. The Team .......................................................................................................... 3 2. The team is a source of valuable information about the participant .................... 3 3. Information that the team may bring to meetings ............................................... 3 Supported Employment Procedures .......................................................................... 4 1. Application to VR and referrals .......................................................................... 4 2. Eligibility ............................................................................................................. 4 3. Plan development (pre-plan decisions and activities) ......................................... 5 4. The Individualized plan for employment (IPE) .................................................... 7 5. Monitoring and managing progress of the IPE ................................................... 9 6. Closure ............................................................................................................ 11 7. Appeal rights ................................................................................................... -

R1707007 Rule 21 Working Group Three Final Report
BEFORE THE PUBLIC UTILITIES COMMISSION OF THE STATE OF CALIFORNIA Order Instituting Rulemaking to Consider Streamlining Interconnection of Distributed Rulemaking 17-07-007 Energy Resources and Improvements to Rule 21. (Filed July 13, 2017) WORKING GROUP THREE FINAL REPORT JONATHAN J. NEWLANDER Attorney for SAN DIEGO GAS & ELECTRIC COMPANY 8330 Century Park Court, CP32D San Diego, CA 92123 Phone: (858) 654-1652 E-mail: [email protected] ON BEHALF OF ITSELF AND: KEITH T. SAMPSON ALEXA MULLARKY Attorney for: Attorney for PACIFIC GAS AND ELECTRIC SOUTHERN CALIFORNIA EDISON COMPANY COMPANY 77 Beale Street 2244 Walnut Grove Avenue San Francisco, California 94105 Post Office Box 800 Telephone: (415) 973-5443 Rosemead, California 91770 Facsimile: (415) 973-0516 Telephone: (626) 302-1577 E-mail: [email protected] E-mail: [email protected] June 14, 2019 BEFORE THE PUBLIC UTILITIES COMMISSION OF THE STATE OF CALIFORNIA Order Instituting Rulemaking to Consider Streamlining Interconnection of Distributed Rulemaking 17-07-007 Energy Resources and Improvements to Rule 21. (Filed July 13, 2017) WORKING GROUP THREE FINAL REPORT Pursuant to the Scoping Memo of Assigned Commissioner and Administrative Law Judge, dated October 2, 2017, as modified by the Assigned Commissioner’s Amended Scoping Memo and Joint Administrative Law Judge Ruling, dated November 16, 2018, San Diego Gas & Electric Company (U 902-E), on behalf of itself and Pacific Gas and Electric Company (U 39-E) and Southern California Edison Company (U 338-E), hereby submits -

Concept Progress a Science Fiction Metaphysics
CONCEPT PROGRESS A SCIENCE FICTION METAPHYSICS LEO INDMAN Copyright © 2017 by Leo Indman All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the author except for the use of brief quotations in a book review. This is a work of fiction. Names, characters, businesses, places, events and incidents are either the products of the author’s imagination or used in a fictitious manner. Any resemblance to actual persons, living or dead, or actual events is purely coincidental. Although every precaution has been taken to verify the accuracy of the information contained herein, the author assumes no responsibility for any errors or omissions. No liability is assumed for damages that may result from the use of information contained within. The views expressed in this book are solely those of the author. The author is not responsible for websites (or their content) that are not owned by the author. The author is grateful to: NASA, for its stellar imagery: www.nasa.gov Wikipedia, for its vast knowledge and reference: www.wikipedia.org Cover and interior design by the author ePublished in the United States of America Available on Apple iBooks: www.apple.com/ibooks/ ISBN: 978-0-9988289-0-9 Concept Progress: A Science Fiction Metaphysics / Leo Indman First Edition www.conceptprogress.com ii For Marianna, Ariella, and Eli iii CONCEPT PROGRESS iv Table of Contents Copyright Dedication Introduction Chapter One Concept Sound Chapter One | Science, Philosophy, and -

And Neoarchean Tectonic Evolution of the Northwestern
Meso – and Neoarchean tectonic evolution of the northwestern Superior Province: Insights from a U-Pb geochronology, Nd isotope, and geochemistry study of the Island Lake greenstone belt, Northeastern Manitoba by Jennifer E. Parks A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Doctor of Philosophy in Earth Sciences Waterloo, Ontario, Canada, 2011 ©Jennifer E. Parks 2011 Author’s Declaration I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I understand that my thesis may be made electronically available to the public. ii Abstract What tectonic processes were operating in the Archean, and whether they were similar to the “modern-style” plate tectonics seen operating today, is a fundamental question about Archean geology. The Superior Province is the largest piece of preserved Archean crust on Earth. As such it provides an excellent opportunity to study Archean tectonic processes. Much work has been completed in the southern part of the Superior Province. A well-documented series of discrete, southward younging orogenies related to a series of northward dipping subduction zones, has been proposed for amalgamating this part of the Superior Province. The tectonic evolution in the northwestern Superior Province is much less constrained, and it is unclear if it is related to the series of subduction zones in the southern part of the Superior Province, or if it is related to an entirely different process. Such ideas need to be tested in order to develop a concise model for the Meso – and Neoarchean tectonic evolution of the northwestern Superior Province. -

Proceedings of the Second Annual IOOS Development Workshop
2ND IOOS IMPLEMENTATION CONFERENCE ARLINGTON, VIRGINIA MAY 3-4, 2005 PROCEEDINGS SECOND IOOS IMPLEMENTATION CONFERENCE: MULTI-HAZARD FORECASTING The National Office for Integrated and Sustained Ocean Observations Ocean.US Publication No. 10 1 Executive Summary 4 1. Introduction 6 1.1 Goal and Rationale 6 © K 1.2 Objectives 7 ri st in e 1.2.1 Forecasting of Natural Hazards 7 S t u m 1.2.2 Mitigating and Managing the Effects of Natural Hazards 8 p 1.2.3 Data Management and Communications 8 1.2.4 Using IOOS Data and Information for Education, Capacity Building, and Outreach 8 1.3 Participants 9 1.4 Procedure 9 1.5 Conference Evaluation 9 2. Summary of the Consensus Recommendations by the Conferees (Days 1 and 2) 10 2.1 Coastal Inundation 10 2.1.1 Observations 10 © K 2.1.2 Modeling 10 r is t in e 2.1.3 Products 10 S t u m 2.2 DMAC 11 p 2.2.1 DMAC Interoperability Framework (Standards Oversight Process) 11 2.2.2 DMAC Interoperability Infrastructure 11 2.2.3 DMAC Test Beds 12 2.2.4 Regional Development 12 2.3 Education 12 2.3.1 National Coordinating Office for Education 12 2.3.2 Governance of IOOS Education 13 2.3.3 IOOS Education Planning 13 2.3.3.1 Education Strategy and Implementation Planning 14 2.3.3.2 Key Educational Messages and Themes 14 © 2.3.3.3 Audience Research and Pilot Projects 14 K ri st 2.3.4 Learning Material Design 15 in e S 2.3.5 Formalize Interagency Collaboration Beyond IOOS 15 t u m p 3. -

An Historical Overview by Michael Moynahan
Since 1899: A Tradition of Quality Education Building an Education Tradition in Shasta County Insights to the History of the Shasta Union High School District as seen through the eyes of the Superintendents by Michael Moynahan Cover,Content and SUHSD Logo designed by Nancy L. Williams (ret. SUHSD 5/2008) © Michael Moynahan 2009 ° Published by the SUHSD Building an Education Tradition Insights to the History of the Shasta Union High School District as seen through the eyes of the Superintendents by Michael Moynahan Since 1899 Since Redding in the Late 1800's Table of Contents iv • Acknowledgements vii • Introduction 1 • History in the Making: A Tradition Begins 3 • A Brief History of the Shasta Union High School District 11 • Modern Era Architects of Education: The Superintendents 13 • Chapter 1 - The Richard Haake Epoch 29 • Chapter 2 - The Time of Joseph Appel 41 • Chapter 3 - The Donald Demsher Age 53 • Chapter 4 - The Rob Slaby Period 63 • Chapter 5 - The Michael Stuart Era 87 • Chapter 6 - The Jim Cloney Commencement 95 • Reflections 97 • Shining Stars: Notable Graduates 107 • Conclusion 111 • Appendix 112 • Principals/Superintendents 113 • Trustees of the Governing Board of the SUHSD 114 • Works Cited 121 • Index 129 • About the Author Building an Education Tradition in Shasta County iii >> Teamwork “Real generosity toward the future lies in giving all to 1908 Girls' Basketball Team the present."” — Albert Camus Acknowledgements When I began this project in July of 2006, I had no idea the amount of research and time it would entail before it was completed. However, the real eye-opener for me was the energy and passion that would be generated by the people who helped me to complete this work. -

Final Report
BEFORE THE PUBLIC UTILITIES COMMISSION OF THE STATE OF CALIFORNIA FILED 06/14/19 04:59 PM Order Instituting Rulemaking to Consider Streamlining Interconnection of Distributed Rulemaking 17-07-007 Energy Resources and Improvements to Rule 21. (Filed July 13, 2017) WORKING GROUP THREE FINAL REPORT JONATHAN J. NEWLANDER Attorney for SAN DIEGO GAS & ELECTRIC COMPANY 8330 Century Park Court, CP32D San Diego, CA 92123 Phone: (858) 654-1652 E-mail: [email protected] ON BEHALF OF ITSELF AND: KEITH T. SAMPSON ALEXA MULLARKY Attorney for: Attorney for PACIFIC GAS AND ELECTRIC SOUTHERN CALIFORNIA EDISON COMPANY COMPANY 77 Beale Street 2244 Walnut Grove Avenue San Francisco, California 94105 Post Office Box 800 Telephone: (415) 973-5443 Rosemead, California 91770 Facsimile: (415) 973-0516 Telephone: (626) 302-1577 E-mail: [email protected] E-mail: [email protected] June 14, 2019 1 / 141 BEFORE THE PUBLIC UTILITIES COMMISSION OF THE STATE OF CALIFORNIA Order Instituting Rulemaking to Consider Streamlining Interconnection of Distributed Rulemaking 17-07-007 Energy Resources and Improvements to Rule 21. (Filed July 13, 2017) WORKING GROUP THREE FINAL REPORT Pursuant to the Scoping Memo of Assigned Commissioner and Administrative Law Judge, dated October 2, 2017, as modified by the Assigned Commissioner’s Amended Scoping Memo and Joint Administrative Law Judge Ruling, dated November 16, 2018, San Diego Gas & Electric Company (U 902-E), on behalf of itself and Pacific Gas and Electric Company (U 39-E) and Southern California Edison Company (U 338-E), hereby submits the Working Group Three Final Report. Respectfully submitted, /s/ Jonathan J. -
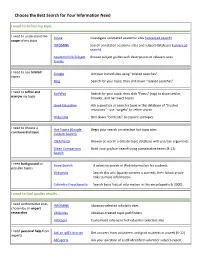
Choose the Best Search for Your Information Need
Choose the Best Search for Your Information Need I need to define my topic... I need to understand the Intute Investigate annotated academic sites (advanced search) scope of my topic INFOMINE Search annotated academic sites and subject databases (advanced search) AcademicInfo Subject Browse subject guides with descriptions of relevant sites Guides I need to see related Google Uncover buried sites using "related searches" topics Bing Search for your topic, then drill down "related searches" I need to refine and SurfWax Search for your topic, then click "Focus" (top) to show similar, narrow my topic broader, and narrower topics iSeek Education Ask a question or search a topic in this database of "trusted resources" - use "targets" to refine search Wikipedia Drill down “Contents” to explore subtopics I need to choose a Hot Topics (Google Begin your search on selective hot topic sites controversial issue Custom Search) IDEA Portal Browse or search a debate topic database with pro/con arguments Glean Comparison Build your pro/con search using comparative terms (K-12) Search I need background on SweetSearch A selective search of Web information for students possible topics Wikipedia Search this wiki (quality content is starred), then follow article links to more information Columbia Encyclopedia Search basic factual information in this encyclopedia (c 2000) I need to find quality results... I need authoritative sites INFOMINE Librarian-selected scholarly sites chosen by an expert researcher LibGuides Librarian-created topic pathfinders Infotopia -
Numbers in India's Periphery Ankush Agrawal , Vikas Kumar Frontmatter More Information
Cambridge University Press 978-1-108-48672-9 — Numbers in India's Periphery Ankush Agrawal , Vikas Kumar Frontmatter More Information Numbers in India’s Periphery Over the past two centuries, the deep and multifaceted relation between statistics and statecraft has emerged as a defining feature of modern states across the world. Governments increasingly depend upon statistics for planning and evaluation of interventions as well as self-representation. Numbers in India’s Periphery examines systematic and deliberate errors in government statistics. Using field interviews, archival sources and secondary data, the book explores the shifting relations between various kinds of government statistics and charts their political career in Nagaland, a state located in India’s landlocked ethno-geographic periphery stretching from Mizoram to Jammu and Kashmir. This book examines the area (1951–2018), population (1951–2011) and National Sample Survey statistics (1973–2014) of Nagaland, treating them as part of a larger family of mutually constitutive statistics embedded in a shared context. It shows that Nagaland’s government statistics suffer from sustained and large errors and examines the impact of inadequacies in the data generating processes on statistics of interest to policymakers. It argues that statistics are shaped by a combination of factors, including discontent with colonial borders, competition over resource-rich territories, political unrest, competition for government spending and contests over the delimitation of administrative units and electoral constituencies in the context of weak institutions and dominance of the state in the economy. It also engages with the shared experience of other states of India, including Assam, Jammu and Kashmir and Manipur, and other countries in Africa and Asia and non-governmental statistics such as church membership data. -
Catalogue & Index
Catalogue & Index Periodical of the Chartered Institute of Library and Information Professionals (CILIP) Cataloguing & Indexing Group Issue 158 Editorial Contents 2 - 3 Retrospective Welcome to Issue 158 field (that could be used records and 25% of new authority control, of Catalogue & Index. for added entries for additions come from H K Williams This issue covers the series) redundant in outside the US. main topics of authority favour of using the 490 4 - 5 Series authority control and indexing. and 8XX fields, Colin Keeping with the control and MARC21, With the onslaught of Duncan, Inverclyde international flavour, Colin Duncan digital information, the Libraries discusses the Jennine Knight of the 6 - 9 Wikipedia and need for a controlled implication and includes University of West Indies cataloguing, semantic value of citing some information on highlights both the Kathleen Menzies people and places ever other library services strengths and weaknesses of pre and increases. This issue and how they will deal 10 - 11 Cooperative name post coordinate demonstrates how our with the change. authority data – the LC/ indexing. profession is, and can NACO Authority File, be, at the forefront. Kathleen Hugh Taylor Menzies, Researcher at Information 12 - 16 Pre and post professionals are the Centre for coordinate indexing: practitioners of a Digital strengths and weaknesses, tradition that spans Library Jennine Knight hundreds of years but is Research at Strathclyde 17 - 20 Spelling it all out: ever more prescient in this time and age. University