Self-Organizing Map and Social Networks: Unfolding Online Social Popularity a Bottom-Up Sociological Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Creating & Connecting: Research and Guidelines on Online Social
CREATING & CONNECTING//Research and Guidelines on Online Social — and Educational — Networking NATIONAL SCHOOL BOARDS ASSOCIATION CONTENTS Creating & Connecting//The Positives . Page 1 Online social networking Creating & Connecting//The Gaps . Page 4 is now so deeply embedded in the lifestyles of tweens and teens that Creating & Connecting//Expectations it rivals television for their atten- and Interests . Page 7 tion, according to a new study Striking a Balance//Guidance and Recommendations from Grunwald Associates LLC for School Board Members . Page 8 conducted in cooperation with the National School Boards Association. Nine- to 17-year-olds report spending almost as much time About the Study using social networking services This study was made possible with generous support and Web sites as they spend from Microsoft, News Corporation and Verizon. watching television. Among teens, The study was comprised of three surveys: an that amounts to about 9 hours a online survey of 1,277 nine- to 17-year-old students, an online survey of 1,039 parents and telephone inter- week on social networking activi- views with 250 school district leaders who make deci- ties, compared to about 10 hours sions on Internet policy. Grunwald Associates LLC, an a week watching TV. independent research and consulting firm that has conducted highly respected surveys on educator and Students are hardly passive family technology use since 1995, formulated and couch potatoes online. Beyond directed the study. Hypothesis Group managed the basic communications, many stu- field research. Tom de Boor and Li Kramer Halpern of dents engage in highly creative Grunwald Associates LLC provided guidance through- out the study and led the analysis. -

Social Networks for Main Street
Ulster County Main Streets: A Regional Approach Ulster County Planning Department, 244 Fair Street, Kingston NY 12401 Why do we take a regional approach to Main Streets? There are many different approaches to supporting these centers in our local economy. The goal of the Ulster County Main Streets approach is to develop a program that is based on our region‘s specific needs and support appropriate responses and strategies that are built and sustained from within our communities. It is also founded upon the idea that communities are stronger when they work together, share knowledge, leverage their resources, and think regionally to support their ―competitive advantage.‖ What is the Main Streets Strategic Toolbox? Any successful planning effort requires solid information as a basis for decision-making. The Toolbox includes resources to help your community create a strong, sustainable strategy for Main Street revitalization. For a full list of topics in the toolbox, please contact our staff at 845-340-3338 or visit our website at www.ulstercountyny.gov/planning. Social Networks for Main Street The web has become more than a warehouse of information. Social networking (or ―Web 2.0‖) is an interactive information-sharing platform that allows internet users add content and interact with others. Businesses are using Web 2.0 to increase customer loyalty and market visibility. This offers tremendous potential for Main Street businesses. Consumers are online. For them, this is ―word of mouth‖ via the web. Some examples: Main Street Webpage: “Come see and shop New Paltz Main Street.” Consumer on Facebook: “Have you been to New Paltz?” Response: “Yeah, great!”“ Twitter Tweet: Just got back from New Paltz. -

Twitter, Myspace and Facebook Demystified - by Ted Janusz
Twitter, MySpace and Facebook Demystified - by Ted Janusz Q: I hear people talking about Web sites like Twitter, MySpace and Facebook. What are they? And, even more importantly, should I be using them to promote oral implantology? First, you are not alone. A recent survey showed that 70 percent of American adults did not know enough about Twitter to even have an opinion. Tools like Twitter, Facebook and MySpace are components of something else you may have heard people talking about: Web 2.0 , a popular term for Internet applications in which the users are actively engaged in creating and distributing Web content. Web 1.0 probably consisted of the Web sites you saw back in the late 90s, which were nothing more than fancy electronic brochures. Web 1.5 would have been something like Amazon or eBay, sites on which one could buy, sell and leave reviews. What Web 3.0 will look like is anybody's guess! Let's look specifically at the three applications that you mentioned. Tweet, Tweet Twitter - "Twitter is like text messaging, only you can also do it from the Web," says Dan Tynan, the author of the Tynan on Technology blog. "Instead of sending a message to just one person, you can send it to thousands of people at once. You can choose to follow anyone's update (called "tweets") simply by clicking the Follow button on their profile, or vice-versa. The only rule is that each tweet can be no longer than 140 characters." Former CEO of Twitter Jack Dorsey once accepted an award for Twitter by saying, "We'd like to thank you in 140 characters or less. -

Analysis of Topological Characteristics of Huge Online Social Networking Services Yong-Yeol Ahn, Seungyeop Han, Haewoon Kwak, Young-Ho Eom, Sue Moon, Hawoong Jeong
1 Analysis of Topological Characteristics of Huge Online Social Networking Services Yong-Yeol Ahn, Seungyeop Han, Haewoon Kwak, Young-Ho Eom, Sue Moon, Hawoong Jeong Abstract— Social networking services are a fast-growing busi- the statistics severely and it is imperative to use large data sets ness in the Internet. However, it is unknown if online relationships in network structure analysis. and their growth patterns are the same as in real-life social It is only very recently that we have seen research results networks. In this paper, we compare the structures of three online social networking services: Cyworld, MySpace, and orkut, from large networks. Novel network structures from human each with more than 10 million users, respectively. We have societies and communication systems have been unveiled; just access to complete data of Cyworld’s ilchon (friend) relationships to name a few are the Internet and WWW [3] and the patents, and analyze its degree distribution, clustering property, degree Autonomous Systems (AS), and affiliation networks [4]. Even correlation, and evolution over time. We also use Cyworld data in the short history of the Internet, SNSs are a fairly new to evaluate the validity of snowball sampling method, which we use to crawl and obtain partial network topologies of MySpace phenomenon and their network structures are not yet studied and orkut. Cyworld, the oldest of the three, demonstrates a carefully. The social networks of SNSs are believed to reflect changing scaling behavior over time in degree distribution. The the real-life social relationships of people more accurately than latest Cyworld data’s degree distribution exhibits a multi-scaling any other online networks. -

Obtaining and Using Evidence from Social Networking Sites
U.S. Department of Justice Criminal Division Washington, D.C. 20530 CRM-200900732F MAR 3 2010 Mr. James Tucker Mr. Shane Witnov Electronic Frontier Foundation 454 Shotwell Street San Francisco, CA 94110 Dear Messrs Tucker and Witnov: This is an interim response to your request dated October 6, 2009 for access to records concerning "use of social networking websites (including, but not limited to Facebook, MySpace, Twitter, Flickr and other online social media) for investigative (criminal or otherwise) or data gathering purposes created since January 2003, including, but not limited to: 1) documents that contain information on the use of "fake identities" to "trick" users "into accepting a [government] official as friend" or otherwise provide information to he government as described in the Boston Globe article quoted above; 2) guides, manuals, policy statements, memoranda, presentations, or other materials explaining how government agents should collect information on social networking websites: 3) guides, manuals, policy statements, memoranda, presentations, or other materials, detailing how or when government agents may collect information through social networking websites; 4) guides, manuals, policy statements, memoranda, presentations and other materials detailing what procedures government agents must follow to collect information through social- networking websites; 5) guides, manuals, policy statements, memorandum, presentations, agreements (both formal and informal) with social-networking companies, or other materials relating to privileged user access by the Criminal Division to the social networking websites; 6) guides, manuals, memoranda, presentations or other materials for using any visualization programs, data analysis programs or tools used to analyze data gathered from social networks; 7) contracts, requests for proposals, or purchase orders for any visualization programs, data analysis programs or tools used to analyze data gathered from social networks. -
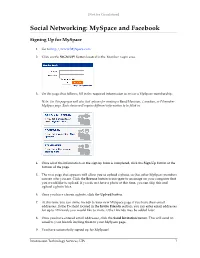
Social Networking: Myspace and Facebook
[Not for Circulation] Social Networking: MySpace and Facebook Signing Up for MySpace 1. Go to http://www.MySpace.com. 2. Click on the SIGN UP! Button located in the Member Login area. 3. On the page that follows, fill in the required information to create a MySpace membership. Note: On this page you will also find options for creating a Band/Musician, Comedian, or Filmmaker MySpace page. Each choice will require different information to be filled in. 4. Once all of the information on the sign up form is completed, click the Sign Up button at the bottom of the page. 5. The next page that appears will allow you to upload a photo, so that other MySpace members can see who you are. Click the Browse button to navigate to an image on your computer that you would like to upload. If you do not have a photo at this time, you can skip this and upload a photo later. 6. Once you have chosen a photo, click the Upload button. 7. At this time you can invite friends to your new MySpace page if you have their email addresses. In the To: field located in the Invite Friends section, you can enter email addresses for up to 10 friends you would like to invite. Other friends may be added later. 8. Once you have entered email addresses, click the Send Invitation button. This will send an email to your friends inviting them to your MySpace page. 9. You have successfully signed up for MySpace! Information Technology Services, UIS 1 [Not for Circulation] Signing Up for Facebook 1. -

Opportunities and Challenges for Standardization in Mobile Social Networks
Opportunities and Challenges for Standardization in Mobile Social Networks Laurent-Walter Goix, Telecom Italia [email protected] Bryan Sullivan, AT&T [email protected] Abstract This paper describes the opportunities and challenges related to the standardization of interoperable “Mobile Social Networks”. Challenges addressed include the effect of social networks on resource usage, the need for social network federation, and the needs for a standards context. The concept of Mobile Federated Social Networks as defined in the OMA SNEW specification is introduced as an approach to some of these challenges. Further specific needs and opportunities in standards and developer support for mobile social apps are described, including potentially further work in support of regulatory requirements. Finally, we conclude that a common standard is needed for making mobile social networks interoperable, while addressing privacy concerns from users & institutions as well as the differentiations of service providers. 1 INTRODUCTION Online Social Networks (OSN) are dominated by Walled Gardens that have attracted users by offering new paradigms of communication / content exchange that better fit their modern lifestyle. Issues are emerging related to data ownership, privacy and identity management and some institutions such as the European Commission have started to provide measures for controlling this. The impressive access to OSN from ever smarter mobile devices, as well as the growth of mobile- specific SN services (e.g. WhatsApp) have further stimulated the mobile industry that is already starving for new attractive services (RCS 1). In this context OMA 2 as mobile industry forum has recently promoted the SNEW specifications that can leverage network services such as user identity and native interoperability of mobile networks (the approach promoted by “federated social networks”). -

Myspace and Facebook: Applying the Uses and Gratifications Theory to Exploring Friend-Networking Sites
CYBERPSYCHOLOGY & BEHAVIOR Volume 11, Number 2, 2008 © Mary Ann Liebert, Inc. DOI: 10.1089/cpb.2007.0056 MySpace and Facebook: Applying the Uses and Gratifications Theory to Exploring Friend-Networking Sites JOHN RAACKE, Ph.D. and JENNIFER BONDS-RAACKE, Ph.D. ABSTRACT The increased use of the Internet as a new tool in communication has changed the way peo- ple interact. This fact is even more evident in the recent development and use of friend-net- working sites. However, no research has evaluated these sites and their impact on college stu- dents. Therefore, the present study was conducted to evaluate: (a) why people use these friend-networking sites, (b) what the characteristics are of the typical college user, and (c) what uses and gratifications are met by using these sites. Results indicated that the vast ma- jority of college students are using these friend-networking sites for a significant portion of their day for reasons such as making new friends and locating old friends. Additionally, both men and women of traditional college age are equally engaging in this form of online com- munication with this result holding true for nearly all ethnic groups. Finally, results showed that many uses and gratifications are met by users (e.g., “keeping in touch with friends”). Re- sults are discussed in light of the impact that friend-networking sites have on communica- tion and social needs of college students. INTRODUCTION women are more likely to engage in online com- munication to maintain personal connections with LTHOUGH THE INTERNET originated in the United family, friends, and coworkers, whereas men use AStates, its use has spread quickly throughout online communication for pursuing sexual interests the world. -

11 Sites and Apps Kids Are Heading to After Facebook Remember
11 Sites and Apps Kids Are Heading to After Facebook Remember MySpace? Not so long ago, practically every teen in the world was on it –- and then many left for Facebook. Now, as Facebook's popularity among teens is starting to wane, you might be wondering what the new "it" social network is. But the days of a one-stop shop for all social networking needs are over. Instead, teens are dividing their attention between an array of apps. You don't need to know the ins and outs of every app and site that's "hot" right now (and frankly, if you did, they wouldn't be trendy anymore). But knowing the basics -- what they are, why they're popular, and the problems that can crop up when they're not used responsibly. 11 Social Media Tools Parents Need to Know About Now Twitter Instagram Snapchat Tumblr Google+ Vine Wanelo Kik Messenger Ooovoo Pheed Ask.fm 1. Twitter is a microblogging site that allows users to post brief, 140-character messages -- called "tweets" -- and follow other users' activities. Why it's popular Teens like using it to share quick tidbits about their lives with friends. What parents need to know Public tweets are the norm for teens. Though you can choose to keep your tweets private, most teens report having public accounts. Updates appear immediately. Even though you can remove tweets, your followers can still read what you wrote until it's gone. This can get kids in trouble if they say something in the heat of the moment. -

Cachet: a Decentralized Architecture for Privacy Preserving Social Networking with Caching
Cachet: A Decentralized Architecture for Privacy Preserving Social Networking with Caching Shirin Nilizadeh Sonia Jahid Prateek Mittal Indiana University University of Illinois at University of California, Bloomington Urbana-Champaign Berkeley [email protected] [email protected] [email protected] Nikita Borisov Apu Kapadia University of Illinois at Indiana University Urbana-Champaign Bloomington [email protected] [email protected] ABSTRACT and (b) use of social contacts for object caching results in Online social networks (OSNs) such as Facebook and significant performance improvements. Google+ have transformed the way our society communi- cates. However, this success has come at the cost of user Categories and Subject Descriptors privacy; in today's OSNs, users are not in control of their C.2.4 [Computer-Communication Networks]: Dis- own data, and depend on OSN operators to enforce access tributed Systems|Distributed Applications; K.6.m control policies. A multitude of privacy breaches has spurred [Management of Computing and Information research into privacy-preserving alternatives for social net- Systems]: Miscellaneous|Security working, exploring a number of techniques for storing, dis- seminating, and controlling access to data in a decentral- ized fashion. In this paper, we argue that a combination General Terms of techniques is necessary to efficiently support the complex Algorithms, Security functionality requirements of OSNs. We propose Cachet, an architecture that provides strong Keywords security and privacy guarantees while preserving the main functionality of online social networks. In particular, Cachet privacy, peer-to-peer systems, social networking, caching protects the confidentiality, integrity and availability of user content, as well as the privacy of user relationships. -

Chazen Society Fellow Interest Paper Orkut V. Facebook: the Battle for Brazil
Chazen Society Fellow Interest Paper Orkut v. Facebook: The Battle for Brazil LAUREN FRASCA MBA ’10 When it comes to stereotypes about Brazilians – that they are a fun-loving people who love to dance samba, wear tiny bathing suits, and raise their pro soccer players to the levels of demi-gods – only one, the idea that they hold human connection in high esteem, seems to be born out by concrete data. Brazilians are among the savviest social networkers in the world, by almost all engagement measures. Nearly 80 percent of Internet users in Brazil (a group itself expected to grow by almost 50 percent over the next three years1) are engaged in social networking – a global high. And these users are highly active, logging an average of 6.3 hours on social networks and 1,220 page views per month per Internet user – a rate second only to Russia, and almost double the worldwide average of 3.7 hours.2 It is precisely this broad, highly engaged audience that makes Brazil the hotly contested ground it is today, with the dominant social networking Web site, Google’s Orkut, facing stiff competition from Facebook, the leading aggregate Web site worldwide. Social Network Services Though social networking Web sites would appear to be tools born of the 21st century, they have existed since even the earliest days of Internet-enabled home computing. Starting with bulletin board services in the early 1980s (accessed over a phone line with a modem), users and creators of these Web sites grew increasingly sophisticated, launching communities such as The WELL (1985), Geocities (1994), and Tripod (1995). -

2010 Nonprofit Social Network Benchmark Report
April 2010 Nonprofit Social Network Benchmark Report www.nonprofitsocialnetworksurvey.com www.nten.org www.commonknow.com www.theport.com Introduction NTEN, Common Knowledge, and ThePort Network offer this second annual installment of the Nonprofit Social Networking Benchmark Report. This report’s objective is to provide nonprofits with insights and trends surrounding social networking technology as part of nonprofit organizations’ marketing, communications, fundraising, and program house social network services. Social networking community built on Between February 3 and March 15, 2010, a nonprofit’s own 1,173 nonprofit professionals responded to website. Term derived a survey about their organization’s use of from direct mail online social networks. house lists. Two groups of questions were posed to survey participants: commercial 1. Tells us about your use of commercial social network social networks such as Facebook, Twitter, An online community LinkedIn, and others. owned and operated by a corporation. 2. Tell us about your work building and Popular examples using social networks on your own include Facebook and websites, called house social networks . MySpace. Survey respondents represented small, medium and large nonprofits and all nonprofit segments: Arts & Culture, Association, Education, Environment & Animals, Health & Healthcare, Human Services, International, Public & Societal Benefit, Religious and others (See Appendix A for more details). www.nonprofitsocialnetworksurvey.com 1 Executive Summary Commercial Social Networks Nonprofits continued to increase their use of commercial social networks over 2009 and early 2010 with Facebook and Twitter proving to be the preferred networks. LinkedIn and YouTube held steady, but MySpace lost significant ground. The following are the key excerpts from this section: • Facebook is still used by more nonprofits than any other commercial social network with 86% of nonprofits indicating that they have a presence on this network.