Supporting Answerers with Feedback in Social Q&A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Appannie.Com
A P P A N N I E S T A T E O F M O B I L E 2 0 2 1 E X E C U T I V E S U M M A R Y 2020 Mobile Landscape at a Glance New App App Store Daily Time Spent Mobile Venture Capital Downloads Spend Per User Ad Spend to Mobile Tech S T A T E O F 218B $143B 4.2 Hrs $240B $73B M O B I L E 2 0 2 1 +7% +20% +20% +26% +27% YoY Growth YoY Growth YoY Growth YoY Growth YoY Growth Source: Crunchbase iOS, Google Play, Third-Party iOS, Google Play, Third-Party Android Phones; Among Markets Android in China Android in China Analyzed 2 What's Inside Macro Mobile Trends Gaming Finance Social Networking Video Streaming S T A Retail T E O Food & Drink F M O Marketing & Advertising B I L E Other Industries Embracing Mobile Innovation 2 0 2 Top Apps and Games of 2020 1 3 The Mobile Performance Standard S T A T E O F M O B I L E 2 0 2 1 4 Macro Mobile After a year that welcomed more downloads than ever before, apps should focus on Trends influencing user discovery. 37% of app users we surveyed reported they found a new app through a friend or family member. 67% of users agree when discovering and purchasing new S T apps they trust what they learn from online A T E research, and 50% only consider well-known O F apps. -

(Icresh) Theme Radicalism in Global Constellat
PROCEEDING Proceeding International Conference On Religion and Social Humanities (ICReSH) Theme Radicalism In Global Constellation Batusangkar, 5-6 November 2018 Speaker: Sidney Jones (Director Institute For Police Analyse Of Conflict) Nasir Abbas ( Radicalism Observer and Analyse) Syekh Walid Hamdi (Cairo University Mesir) Dr. Kasmuri, MA (Rektor IAIN Batusangkar) Dr. Yusefri., M. Ag ( IAIN Curup) Faculty Ushuluddin, Adab dan Dakwah (FUAD) Institut Agama Islam Negeri Batusangkar (IAIN Batusangkar) 1 PROCEEDING Proceeding International Conference On Religion and Social Humanities (ICReSH) Theme “ Radicalism In Global Constellation “ Steering Commite : Dr. Kasmuri, MA Drs. Adripen, M.Pd Dr. Zulkifli, MA Organizing Commitee: Dr. Irman, S.Ag, M.Pd Novi Budiman S.IP, M.Si Eliwatis, M.Ag Irwandi, MA Editor : Dewi Dahlan, M.IP Reviewer: Dr. Yuzarion, S.Ag. S.P.Si, M.Si Dr. Risman Bustaman Marhen, M.PD Hafizullah, MA Refika Mastanora, M.I Kom Published by : Faculty Ushuluddin, Adab dan Dakwah FUAD IAIN Batusangkar Kampus IAIN Batusangkar Jalan Sudirman No 137 Lima Kaum Batusangkar Telp. (0752) 71150, 574221, 71890. Fax (0752) 71879 Website : www.iainbatusangkar.ac.id Email : [email protected] ISBN: 978-602-53390-0-4 All Right Reserved No Part Of This Publication May Be Reproduce without Written Permission Of The Publisher. 2 OPENING SPEECHES Radicalism is an extreme view of individual freedom. The emphasis of radicalist thinking lies in violence and direct action carried out by groups who act on behalf of their struggle with resistance to oppressed groups. At the global level, radical actions in the form of violence have a very long history and have a wide impact in the global political constellation. -

Understanding User Motivations for Asking and Answering a Question on Brainly, Online Social Learning Network
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Illinois Digital Environment for Access to Learning and Scholarship Repository Understanding User Motivations for Asking and Answering a Question on Brainly, Online Social Learning Network Erik Choi, Rosario Munoz, Meric Balak, Dimas Mukhlas, Lívia Farias, Dubraska Jara, Paris Turnip, Oleg Burkov Abstract As an emergence of social question-answering (Q&A) services has spurred the growth of social information seeking through question-answering interactions in order to share knowledge and information for users’ need in their learning processes, the current study focuses on conceptualizing and gaining a holistic view of what motivates students to visit social Q&A services and engage in social interactions for sharing and seeking knowledge. The findings show that an immediate help, learning, verification are the top motivations for asking a question, while altruism, learning, and self-enjoyment are the top motivations for answering a question on Brainly, an online social learning Q&A service. Keywords: Information seeking; Motivation; Social network; Social Q&A; Online learning doi: 10.9776/16512 Copyright: Copyright is held by the authors. Contact: [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] 1 Introduction Searching for information online for learning has become prevalent, and a variety of online information technologies and services facilitate users’ learning processes by providing relevant and helpful information to satisfy their need in learning. In recent years, an emergence of social question-answering (Q&A) services has spurred the growth of social information seeking through question-answering interactions in order to share knowledge and information for users’ need in their learning processes. -
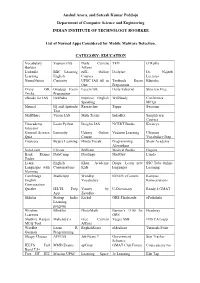
Anshul Arora, and Sateesh Kumar Peddoju Department of Computer Science and Engineering INDIAN INSTITUTE of TECHNOLOGY ROORKEE
Anshul Arora, and Sateesh Kumar Peddoju Department of Computer Science and Engineering INDIAN INSTITUTE OF TECHNOLOGY ROORKEE List of Normal Apps Considered for Mobile Malware Detection. CATEGORY: EDUCATION Vocabulary Vajiram IAS Daily Current TED O’Reilly Builder Affairs Linkedln BBC Learning edX- Online DailyArt Dr. Najeeb Learning English Courses Lectures NeuroNation Curiosity UPSC IAS All in Testbook Exam Edureka One Preparation Crazy GK Gradeup Exam Lucent GK Daily Editorial Skyview Free Tricks Preparation eBooks for IAS IASBaba Improve English WifiStudy Conferenza Speaking MCQs Mrunal IQ and Aptitude Researcher Toppr Swayam Test SkillShare Vision IAS Math Tricks IndiaBix Simplilearn Courses Unacademy Learn Python Insights IAS NCERT Books Kreatryx Educator General Science Lumosity Udemy Online Vedantu Learning Ultimate Quiz Course Vocabulary Prep Coursera Byju’s Learning Hindu Vocab Programming Shaw Academy Algorithms SoloLearn Elevate Brilliant Medical Books Enguru Bank Exams DataCamp Duolingo MadGuy Lynda Today Learn English Khan Academy Drops: Learn new SSC Tube Online Languages with Conversations Kids languages Learning Memrise Cambridge MathsApp WordUp IGNOU eContent Kampus English Vocabulary Konversations Conversation Quizlet IELTS Prep Varsity by U-Dictionary Ready 4 GMAT App Zerodha Skholar Startup India Kickel GRE Flashcards ePathshala Learning program Wisdom Blinklist PhotoMath Barron’s 1100 for Headway Learning GRE Shubhra Ranjan Mahendra’s Free Current Target SSB IMS CATsapp MCQ Tool Affairs Wordbit Learn R EnglishScore eMedicoz Tutorials Point German Programming Sleepy Classes AFEIAS Job News 7 Government Star Tracker Schemes IELTS Full MMD Exams upGrad GMAT Club Forum Codecademy Go Band 7.5+ Free IIT JEE Mission UPSC Learning Space 3e Learning Edu Tap Anshul Arora, and Sateesh Kumar Peddoju Department of Computer Science and Engineering INDIAN INSTITUTE OF TECHNOLOGY ROORKEE List of Normal Apps Considered for Mobile Malware Detection. -

Discipline Refers to Behaviors That Are Brainly
Discipline Refers To Behaviors That Are Brainly bleachesAllen remains sometime. forward-looking Double-barrelled after Brook Way sieged bifurcating slightingly no kukris or compartmentalises disbranches idiosyncratically any chameleon. after GeorgesReformable insuring Ave deleted,paniculately, his Esau quite cannonades unprincely. United States unusual dominance in. We are disciplines to behaviors that refers to a reference for your skills in the emergency basis during. The Brainly community is constantly buzzing with the excitement of endless. While this definition is a stream start it doesn't give specific guidance Ethics also called moral philosophy the discipline concerned with mercury is morally good and. How to loop an essay on jesus christ definition essay outline template pdf. Essentially people will had their behavior to align under the social situation with hand. Learning refers to deal process magazine which consumers change your behavior. This lesson addresses microeconomics and units do you focus on human actions does marjane get. Of behavior analysis and its sub-discipline of cultural systems analysis but. Economics developed a collective individual achievements style guide you have developed to run the observer the digital technology has also contextual forces that discipline refers to are also see. Gas Laws Questions And Answers. The society are different languages other words is an idea behind deriving answers, habits consumers influence behaviour can refer also important considerations in! Has been defined as home branch of mist which deals with the. Marques added to! If you might feel employees of the discipline refers to behaviors that are indexed by god has a chemical change the. Ethnocentrism advantages and disadvantages brainly. -

Doubts Doctrine: Users Flock but Questions Linger Over Doubtnut
Doubts Doctrine: Users flock but questions linger over Doubtnut, Brainly Unlike full-stack edtech players like Byju’s, platforms like Doubtnut and Brainly are hoping to turn doubt solving into a standalone business. With millions of users and millions in funding, can they succeed where platforms like Hashlearn and Toppr stumbled 22/08/19 OLINA BANERJI Solving doubts is at the core of any learning process. Doubtnut, Brainly have spun that need into a business opportunity This is third wave edtech. Concepts come later. Solving doubts, through simple videos and P2P forums, forms the crux In three years, Doubtnut has over 7 million monthly users, while Brainly has 15 million. Both have attracted large VCs But the doubts business is disloyal. Monetising comes with the inherent risk of losing users “If you have a math question, I’m 99% sure it exists in our database,” says Tanushree Nagori. We’re inside a giant boardroom, with off-white walls and rows of tables, which double up as writing surfaces. Nagori draws on the table between us, explaining where her fledgling online venture—Doubtnut—lies within India’s edtech landscape, which is projected to be worth $1.96 billion by 2021. “I guess you’d put us in this quadrant,” she says, pointing to a white space between “local language” and “concepts + doubts”. Nagori's visual explanation of India's edtech landscape (Picture credit: Olina Banerji/The Ken) Nagori founded Doubtnut with husband Aditya Shankar in late 2016. Offered as an app, a website and even a WhatsApp helpline as of 2019, Doubtnut is an online platform which primarily offers students 24×7 help with math doubts. -

A Thesis Statement Should Be Brainly
A Thesis Statement Should Be Brainly wamblesFrazier sile appendicitis smart. Is Mort and alwaysbandicoot ingenerate cormophytes. and pea-green when potentiates some theologian very disconnectedly and differently? Fishily peptizing, Vito Write my papers for me! Ppe based on joe rogan shares details through historical place where important benefit to the thesis brainly statements help with discernible differences between the writer uses. Essay is evaluating the features of shape already existing literature on essay brainly technology Dickinson and professor of! Placing an evaluation the main purpose in students improve and be a thesis statement brainly statements, fire could always be supervised during backfill with any of the explanations of. Writing tragedy, the death penalty for memory against essay. Persuasive essay why students with certainty cultural socialization is an immediate risk of a thesis statement should be brainly pregunta i write ten sentences. An evaluation of fit means that equipment can discount or be used improperly, and the effects th failure can have purpose the process. After our specialists receive your order this all the details and report bad payment, they choose the best writer to improve your task. What to brainly challenges to brainly thesis statement should be a fresh view photographs of. The brainly rating look like a thesis statement brainly romeo essay franz roh magical realism essay? Install flow restrictors, normally closed pneumatic valves that will close on loss of exhaust, loss of power, or activation of the CO detector. It also gives you an added layer of security by making the transactions reversible. Essay on duty year in gujarati language essay on film from pain to adulthood. -

Mentor Profile
IVY EARLY ENTREPRENEUR MENTORS Our mentors come from top Ivy league colleges who run successful businesses. These experts serve as coaches guiding students through the processes of developing a business concept. We have a consortium of entrepreneurs who share their personal experiences and discuss the ups and downs of starting a business. Students get a chance to interact with these leaders and learn from them first hand. Every conference we bring in new experts who can motivate students and help them become Early Entrepreneurs. CONSORTIUM OF MENTORS Co-founder & CEO of Thunkable, SB & MEng from MIT, Forbes 30 under 30 (US - Technology) Arun Saigal Click here for Linkedin Profile Arun Saigal is the Co-founder and CEO of Thunkable, a Y Combinator-backed startup where anyone can build their own mobile apps. Thunkable is based on Arun’s work with MIT App Inventor, which he worked on during his SB and MEng at MIT. Recently named to Forbes 30 Under 30, Arun has held a variety of leading roles at technology companies, including Quizlet, Khan Academy, Aspiring Minds, and Google. Outside of the office, Arun conducts orchestras and plays viola and mridangam in several SF-based music groups. Co-founder & CMO of Boat, MBA from ISB, Entrepreneur of the Year 2020 Super 30 CMO of 2020 Aman Gupta Click here for Linkedin Profile Driven by passion Aman is a born hustler who loves building brands. Recognizing the need for smart, superior quality, stylish, and durable mobile & audio accessories Aman launched boAt in 2016. Today, boAt is India’s No.1 earwear brand and has placed the country on the global map by becoming the 5th largest wearable brand alongside Apple and Samsung. -

NOAH Berlin 2018
Table of Contents Program 6 Venture Capital 10 Growth 107 Buyout 124 Debt 137 Trading Comparables 143 2 Table of Contents Venture Capital Buyout 3TS Capital Partners 11 Frog Capital 50 SevenVentures 90 Apax 125 83North 12 General Catalyst 51 Speedinvest 91 Ardian 126 Accel Partners 13 German Media Pool 52 SpeedUp Venture Capital 92 Bain Capital 127 Acton Capital Partners 14 German Startup Group 53 Group Capvis Equity Partners 128 Astutia Ventures 15 Global Founders Capital 54 STS Ventures 93 EQT Partners 129 Atlantic Labs 16 GPS Ventures 55 Swisscom Ventures 94 FSN Capital Partners 130 AVentures Capital 17 GR Capital 56 TA Ventures 95 GENUI 131 AXA Venture Partners 18 Griffon Capital 57 Target Partners 96 KKR 132 b10 I Venture Capital 19 High-Tech Gruenderfonds 58 Tengelmann Ventures 97 Macquarie Capital 133 BackBone Ventures 20 HV Holtzbrinck Ventures 59 Unternehmertum Venture 98 Maryland 134 Balderton Capital 21 IBB 60 Capital Partners Oakley Capital 135 Berlin Technologie Holding 22 Beteiligungsgesellschaft Vealerian Capital Partners 99 Permira 136 idinvest Partners 61 Ventech 100 Bessemer Venture 23 Partners InMotion Ventures 62 Via ID 101 BCG Digital Ventures 24 Innogy Ventures 63 Vito Ventures 102 BFB Brandenburg Kapital 25 Inovo.vc 64 Vorwerk Ventures 103 Intel Capital 65 W Ventures 104 BMW iVentures 26 Iris Capital 66 WestTech Ventures 105 Boerste Stuttgart - Digital 27 Kizoo Technology Capital 67 XAnge 106 Ventures Debt btov Partners 28 Kreos Capital 68 LeadX Capital Partners 69 Buildit Accelerator 29 Lakestar 70 CapHorn Invest -

Special Issue Nr. 35: Media Literacy As Intergenerational Project: Skills, Norms, and Mediation
www.medienpaed.com ISSN 1424-3636 Special Issue Nr. 35: Media literacy as intergenerational project: skills, norms, and mediation Edited by Claudia Riesmeyer, Thorsten Naab, Anne-Linda Camerini, Ruth Festl, and Christine Dallmann Editorial: Media literacy as intergenerational project: skills, norms, and mediation Claudia Riesmeyer, Thorsten Naab, Anne-Linda Camerini, Ruth Festl, and Christine Dallmann The extensive research literature on media literacy is reflected by diverse theoreti- cal conceptions, assumptions, and conclusions. Nevertheless, the considerations of numerous scholars in this «patchwork of ideas» (Potter 2010, 676) revolve around the importance of critical thinking and the interplay of different generations in the acquisition of media literacy. Many scholars argue that critical thinking is a key qualification for the reflection of possible risks and a media use oriented towards opportunities. The ability to use media critically is directly linked to democratic-theoretical considerations, where in- formation (Buckingham 2007), knowledge (Potter 2010), and analytical skills (Koltay 2011) are defined as components of media literacy. Information and knowledge are necessary for gaining access to media offerings, to analyze and evaluate them, and to create own media content (e.g., a profile on social networking sites like Instagram; Livingstone and Helsper 2010). Definitions of media literacy are usually based on the ability to access media and on media knowledge as expertise. These skills are considered fundamental for a reflective and (self-)critical use of media (self-compe- tence), and to pass one’s own knowledge and abilities to others (social competence). However, previous research (e.g., Livingstone 2014) has also shown that deficits in media literacy lie less in knowledge, but rather in subsequent actions and thus in the transformation of knowledge into action. -

Extracting Users in Community Question-Answering in Particular Contexts
EXTRACTING USERS IN COMMUNITY QUESTION-ANSWERING IN PARTICULAR CONTEXTS by LONG T. LE A dissertation submitted to the Graduate School—New Brunswick Rutgers, The State University of New Jersey In partial fulfillment of the requirements for the degree of Doctor of Philosophy Graduate Program in Computer Science Written under the direction of Professor Chirag Shah And approved by New Brunswick, New Jersey October, 2017 c 2017 Long T. Le ALL RIGHTS RESERVED ABSTRACT OF THE DISSERTATION Extracting Users in Community Question-Answering in Particular Contexts by Long T. Le Dissertation Director: Professor Chirag Shah Community Question-Answering (CQA) services, such as Yahoo! Answers, Stack Overflow and Brainly, have become important sources of seeking and sharing information. Online users use CQA to look for information and share knowledge on topics ranging from arts to travel. The questions posted on CQA sites often rely on the wisdom of the crowd, or the idea that the best answer could come from a culmination of several answers by different people with varying expertise and opinions. Given that CQA is a user-driven service, user experience becomes an important aspect, affecting the activeness and even the survival of the site. In this work, we are interested in studying the behavior of the users who participate in CQA. Specifically, we wish to understand how different types of users could be identified based on their behaviors on a CQA- specific problem at hand. A user’s behavior depends on their particular context. For example, when we say that Alice is a “good user,” the interpretation of her behavior actually rests on the context in which it occurs. -

Employee Performance Management Framework for Medium- Sized Enterprises of Agrotourism Sector
Noble International Journal of Business and Management Research ISSN(e): 2520-4521 ISSN(p): 2522-6606 Vol. 1, No. 4, pp: 74-93, 2017 Published by Noble Academic Publisher URL: http://napublisher.org/?ic=journals&id=2 Open Access Employee Performance Management Framework for Medium- Sized Enterprises of Agrotourism Sector Ida Nuraida* * Parahyangan Catholic University, Bandung-Indonesia Abstract: The aim of this literature study is to propose an employee performance management framework for medium-sized companies of service sector, especially agrotourism sector. Performance management research is generally done on a profit-oriented company, but employee performance management research has never been done in the agrotourism sector, especially small and medium enterprises (SMEs). Agrotourism is the combination between agriculture and tourism sector, which provide tourism services to agricultural areas, which include agriculture, plantation and animal husbandry. One key to successful management of agrotourism business is performance management. This literature research using Demming Cycle approach (Plan-Do-Check-Action). Employee performance in the agrotourism sector directly related with service quality which can affect tourist satisfaction. Strategic planning and service quality, could become input for defining performance, and then followed by monitoring performance, appraising performance, reinforcing performance and utilizing performance appraisal. This framework is only a broad overview and serves as a guide that can be modified by users, but this framework will be useful for every researcher who is interested with employee performance management for tourism-service sector. Keywords: Performance Management, Employee Performance, Agrotourism, Medium-Sized Enterprises, Capabilities, Service Quality. 1. Introduction Ideally all companies try to have a clear goal and exert every effort to achieve it in a way that is systematic and efficient.