Market-Structure Surveillance Through Text Mining
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

North America Sales History and Forecast
North America sales history and forecast 1998 1999 2000 2001 2002 2003 2004 2005 2006 U.S. car 131,559 153,658 162,703 172,505 166,848 170,794 172,594 195,026 211,172 Canada car 7,701 8,922 9,182 9,900 10,903 10,895 10,872 13,956 13,423 Mexico car 1,944 2,442 3,995 5,219 4,573 4,990 6,468 7,680 8,189 North America car 141,204 165,022 175,880 187,624 182,324 186,679 189,934 216,662 232,784 U.S. truck – 1,312 26,720 40,622 34,021 37,789 68,611 66,613 67,151 Canada. truck – 89 1,840 2,802 3,072 2,857 5,102 5,142 4,909 Mexico truck 115 233 213 897 982 989 928 890 983 North America truck 115 1,634 28,773 44,321 38,075 41,635 74,641 72,645 73,043 BMW 141,319 166,656 204,653 231,945 220,399 228,314 264,575 289,307 305,827 U.S. car 739,217 – – – – – – – – Canada car 86,148 – – – – – – – – Mexico car 47,176 – – – – – – – – North America car 872,541 – – – – – – – – U.S. truck 1,770,794 – – – – – – – – Canada truck 183,048 – – – – – – – – Mexico truck 45,123 – – – – – – – – North America truck 1,998,965 – – – – – – – – CHRYSLER CORP. 2,871,506 – – – – – – – – U.S. car – 889,506 894,219 863,043 739,430 744,526 751,850 775,084 796,545 Canada car – 92,064 89,163 76,691 83,291 80,243 79,625 84,883 88,430 Mexico car 52,058 65,957 86,948 78,504 86,942 87,746 91,957 97,751 North America car – 1,033,628 1,049,339 1,026,682 901,225 911,711 919,221 951,924 982,726 U.S. -

Brochure: Jaguar X150.II XK (February 2009)
THE XK COLLECTION The new XK combines Jaguar’s legendary performance, with advanced technologies and sporting luxury to create a grand tourer with the heart and soul o f a s p o r t s c a r. DESIGN 4 PERFORMANCE 18 CRAFTSMANSHIP 24 TECHNOLOGY 30 THE XK COLLECTION 40 SPECIFICATION 56 DESIGN Some cars are built. Some are engineered. A Jaguar is created. A rare blend of art and performance, science and beauty. A new Jaguar is one of the most technologically advanced and luxurious cars ever made. Even standing still, the new XK looks fast. Coupe or Convertible, ultra-effi cient new 5.0 Litre V8 or thrilling new 375kW supercharged, its sweeping, athletic lines and muscular rear haunches exude immense visual energy. Fast has never looked this seductive. Visual energy is created by an aluminium skin stretched taut over the light, yet strong and immensely rigid body structure that gives the new XK its remarkable agility. It’s the energy that comes from the XK’s purity of design, with sculpted surfaces created to cut the air with aerodynamic effi ciency, delivering the visual promise of breathtaking performance and driving excitement. It’s the purity that comes from the XK’s exquisite, precision detailing. Complex mesh surfacing for the front grille openings. Bold, technically- advanced headlamps. Elegant and distinctive side power vents. The sculpted nose now features a dramatic new front bumper design with chrome detailed air intakes, heightening the look of power and performance. This is the beauty of a car that so effortlessly fulfi ls the dual roles of sophisticated, luxurious Grand Tourer and exhilarating, dynamic sports car. -

2002 LEXUS SC 430 Following the Disappointing Results Obtained with the Previous Generation of the SC, Lexus Is Back with a Hard
2002 LEXUS SC 430 Following the disappointing results obtained with the previous generation of the SC, Lexus is back with a hardtop convertible, the SC 430. The rigid aluminium roof folds down into the trunk. With the top up, the SC looks just like a coupe. Inside Despite the car’s low stance, it’s easy to enter and exit the front. The seats are extremely comfortable, with good side and lower-back support. The driving position is excellent, but the front of your leg can rub on the emergency brake pedal when you use the footrest. It’s also easy to step on the emergency brake pedal on the way in,. The rear seat is so unusable and hard to reach that you can’t help wondering why Lexus even bothered. The seatbacks are much too upright, and there’s no semblance of comfort even with the front seats moved up to free a bit of legroom The designers would have been better off simply converting the space into a storage area. Rumour has it, however, that the rear seats are there for insurance purposes, a four-seater, even a make-believe one, being cheaper to insure than a two-seater. The trunk will no doubt give new meaning to the notion of “travelling light”. Cargo capacity is almost non-existent. The only place where there’s room for one or maybe two suitcases is behind the front seats. Convenience and safety The cabin is very well finished in top-quality materials. However, we could hear creaking sounds, both with the top up and down. -

Lexus SC430 Cover
2004 Lexus Owner’s Manual Supplement SC 430 ● Owner Amenities ● Warranty Information ● Maintenance Information 00505-L2004-SC 07/03 W ELCOME TO THE L EXUS F AMILY From everyone in the Lexus organization, thank you Thank you again for choosing Lexus, and please for purchasing one of our vehicles. Your Lexus is the accept our best wishes for years of safe and pleasurable culmination of more than 50 years of research and driving. For the latest information about our vehicles development by Toyota Motor Corporation, and is and our company, please visit our Web site at designed to deliver uncompromising luxury and www.lexus.com. To access your dealership’s Web site, performance. log on to www.lexusdealer.com. We are committed to This booklet has been developed to help you obtain providing you with an ownership experience that is the highest level of satisfaction from your Lexus. second to none, and we look forward to serving you in Please take some time to review it carefully. In the years ahead. Welcome to the Lexus family! addition to important information about warranty coverages and maintenance requirements, you’ll find details on a host of amenities available exclusively to Lexus owners. Yukitoshi Funo President and Chief Executive Officer Toyota Motor Sales, U.S.A., Inc. 1 T ABLE OF C ONTENTS OWNER AMENITIES Complimentary Services First Two Maintenance Services . 4 Loaner Vehicle. 4 Travel Protection. 4 Roadside Assistance . 5 Other Benefits and Assistance Quality Control . 7 Vehicle Service History . 7 Vehicle Service Agreements . 7 Additional Keys. 8 Body Repairs . 8 WARRANTY INFORMATION Introduction If You Need Assistance . -

Results for Round 5
Round 5 Results Castle Airport, 5/5/2007 89 entries Indexed Ranking # Driver Car Hometown Sponsor Index 1st 2nd 3rd 4th 5th Time OA Ind Modified 1 Barry Spencer 11 Europa Fremont La Mexicana EM/0.879 43.724 53.326 49.872 49.89(1 49.743 58.991 3 8 2 Bob Weisickle 88 Austin Healy 100-8 Granite Bay Auburn Tire EM/0.879 43.914 53.506 50.454 50.398 51.198(1 49.959 4 10 B Prepared - Index: 0.866 1 Tom Smiley 37 CORVETTE Granite Bay 44.241 55.13 62.43(1 53.778(1 52.457(1 51.087 9 13 2 Rory Marin 2 Corvette Oakley Maier Racing, Hi-Tech Trans 44.546 56.485 51.623 51.439 63.985(2 51.544 13 17 3 Speedy Knudsen 70 Corvette Napa Jensen's Ornamental, L'J's and Sign Max of Napa 44.693 55.702 53.356 52.843 51.608 51.709 14 21 4 Jim Neighbor 20 Corvette Walnut Creek Prudential Calif Realty 48.977 56.688 56.556(1 65.057(2 60.144 DNR 48 60 C Prepared - Index: 0.864 1 Guy Ankeny 52 Camaro Simi Valley Ankeny Racing Ent. 42.712 DNF 52.104 DNF 50.429 49.435 1 1 2 Mike Maier 36 G T 350 Livermore Maier Racing & K N Filters 43.27 68.425(2 50.369 50.605 50.916 50.081 5 3 3 Joel Villarreal 139 CAMARO San Lorenzo Maier Racing, K & N Filters and La Mexicana 43.313 50.131 50.809 50.908(1 50.168 DNR 6 4 4 Jesus Villarreal 139 Camaro Z28 San Lorenzo K&N Filters, Maier Racing,La Mexicana 43.978 52.273 51.016 50.9 51.566(1 52.368(2 8 12 5 Frank Stagnaro 136 GT 350 Petaluma Maier Racing 44.37 52.177 52.471 51.828 51.354 52.882 12 14 6 Mike DeJesus 66 Mustang Hayward 44.974 54.108(1 52.053 52.117(1 52.231(1 52.21(1 16 22 7 Garrett Ankeny 152 Camaro Simi Valley Ankeny Racing Ent. -

BT45-JAG Bluetooth Kit for Jaguar with CD Changer
Courtesy of: DiscountCarStereo.com Serving the internet community since 1995 BT45-JAG QUICK START BLUETOOTH INSTALLATION GUIDE FOR SELECT JAGUAR XK AND XJ WITH CD CHANGER 1998-03 XJ (X308) and 1997*-06 XK (X100) PRODUCT SAFETY & DISCLAIMER READ ALL INSTRUCTIONS CAREFULLY BEFORE INSTALLING, FAILURE TO DO SO MAY CAUSE Audio module installation PERSONAL INJURY OR DAMAGE TO PRODUCT AND/OR PROPERTY 1. Remove carpet trim piece around audio rack (See Fig. 1). If vehicle does not have GPS, use empty slot to access changer plug, however vehicles with • This installation guide is provided as a GENERAL installation guide, some vehicles vary and may require additional steps. We do not accept responsibility for third party labor charges Navigation or convertibles, may require lowering audio rack by removing or modifications. Exercise due-diligence when installing this product. (4) 8mm and leaning rack forward to reveal wiring. • We do not accept any responsibility for vehicle damage or personal injury resulting from the installation of this product. • Careless installation and operation can result in equipment damage. Requirements CD changer and factory phone plug Introduction Safety comes first when you’re on the road, so having an intuitive and easy to Fig. 1 use Bluetooth kit is essential to reducing driver distraction. The BT45-JAG kit is 2. Locate short CD pigtail. Connects CD changer to radio (Standard systems) compatible with virtually all Bluetooth phones, and sounds great whether you are or to amplifier (Premium system). using it for mobile conversations or music streaming. The system will mute This is the cable required to complete install (See Fig. -

Energy & Climate Change
2 0 0 7 T OYO TA N A ER energy & climate change Toyota strives to improve fuel economy through fuel-efficient engine and vehicle design, but also considers additional methods to enhance fuel efficiency. Toyota recommends SAE 0W-20 viscosity grade engine oil for an increasing number of models as one way to improve fuel efficiency. “Toyota recognizes that climate change is occurring and … is committed to continued action Accent to address climate change and Photo promote greater energy diversity …” – Toyota Testimony Before the U.S. House Subcommittee on Energy and Air Quality EEnernerGG Y Y && CC L LIIMAMAtete CCHHAANNGGEE > TOYO T A ’ S A PP R OA ch T O E ner G Y A N D C L I MA te C H A N G E > Vehic L E F U E L E fficienc Y > Vehic L E F U E L S Di V er S it Y > A DVA nce D Vehic L E T echn OLOG ie S > A DVA nce D T R A N SPO rt A ti O N S OLU ti O N S > E ner G Y A N D Greenh OUS E G AS E S in O U R O P er A ti O nS TOYOTA IS COMMitteD to continued action to address to provide energy from renewable sources. Fuel providers will climate change and promote energy diversity. Action on both need to make new fuels available and provide the necessary issues must, by definition, be broad in scope and involve a distribution infrastructure. -

Injury, Collision, & Theft Losses
Injury, Collision, &Theft Losses By make and model, 2000-02 models September 2003 HIGHWAY LOSS DATA INSTITUTE 1005 North Glebe Road, Arlington, VA 22201 703/247-1600 Fax 703/247-1595 www.highwaysafety.org The Highway Loss Data Institute is a nonprofit public service organization. COMPARISON WITH DEATH RATES It is closely associated with and funded through the Insurance Institute for Highway Safety, which is wholly supported by auto insurers. HLDI gathers, Collisions that result in serious and fatal occupant injuries are relatively processes, and publishes data on the ways losses vary among different rare, so they have only a small influence on the insurance injury results kinds of vehicles. reported in this publication. The results shown here are dominated by the relatively frequent low to moderate severity collisions and associated injuries. A separate report (go to highwaysafety.org/sr_ddr/sr3507.htm), GUIDE TO THIS REPORT published periodically by the Insurance Institute for Highway Safety, is based on fatal crashes. It summarizes driver deaths per million registered vehicle The table inside summarizes the recent insurance injury, collision, and years by make and model. Vehicles with high death rates often have high theft losses of passenger cars, pickup trucks, and utility vehicles. Results frequencies of insurance claims for occupant injuries. For example, small two- are based on the loss experience of 2000-02 models from their first sales and four-door cars typically have high death rates and higher-than-average through May 2003. For vehicles that were newly introduced or redesigned insurance injury claims experience. during these years, the results shown in this publication are based only on the most recent model years for which the vehicle designs were However, there are exceptions. -

High-Theft” Motor Vehicles Pursuant to M.G.L
COMMONWEALTH OF MASSACHUSETTS Office of Consumer Affairs and Business Regulation DIVISION OF INSURANCE One South Station • Boston, MA 02110-2208 (617) 521-7794 • http://www.mass.gov/doi DEVAL L. PATRICK GREGORY BIALECKI GOVERNOR SECRETARY OF HOUSING AND ECONOMIC DEVELOPMENT TIMOTHY P. MURRAY LIEUTENANT GOVERNOR BARBARA ANTHONY UNDERSECRETARY OF CONSUMER AFFAIRS AND BUSINESS REGULATION NONNIE S. BURNES COMMISSIONER OF INSURANCE Property & Casualty Insurance Filing Guidance Notice 2009 - B TO: Insurance Companies Soliciting, Negotiating, Selling or Servicing Commercial or Private Passenger Automobile Insurance Policies in Massachusetts FROM: Kevin P. Beagan, Deputy Commissioner and Director of the State Rating Bureau DATE: June 11, 2009 RE: Designation of “High-Theft” Motor Vehicles Pursuant to M.G.L. c. 175, § 113H Effective August 1, 2009 ______________________________________________________________________________ This Filing Guidance Notice notifies all insurance companies soliciting, negotiating, selling or servicing private passenger motor vehicle insurance policies regarding in Massachusetts that the Commissioner of Insurance, pursuant to her authority under M.G.L. c. 175, § 113H, has additionally designated certain 2010 model year motor vehicles as “high-theft vehicles”. The list of all such designated vehicles for model years 2010 and prior, which is effective August 1, 2009, is attached to this Guidance. Any questions regarding this Filing Guidance Notice should be directed to Kevin P. Beagan, Deputy Commissioner and Director -

ADR6200 BT Carkit Matrix 1026
ADR6200VW - Bluetooth Car Kit Support for Verizon Wireless Subscribers OEM LOGO Notes: "Do not Remove" 1. If you do not see a specific auto manufacture listed for the desired VZW handset, please check with that auto manufacturer for compatibility information. 2. Information regarding Bluetooth(R) capabilities for the cars listed below has been provided by the handset manufacturer, and has not been independently verified by Verizon Wireless. Device Model # Functionality Identify HW/SW Release Car Model (List all Car Manufacturer BT Car Kit OEM BT RX / TX Batt RSSI Roaming Caller Voice Comments HW: Enter HW version models tested) SEND / END Rings PB Transfer Stereo Audio SW: Enter SW version Connection Audio Meter Meter Status ID Recog Embedded OEM Bluetooth Car Kits 2009 Honda Accord, ADR6200VW; ROM: 1.04.605.1 Honda JCI YY Y YYYYYNYY Honda Pilot and CRV 2009 Acura TSX, RL,TL ADR6200VW; ROM: 1.04.605.1 Acura JCI YY Y YYYYYNYY and MDX 2004 Toyota LandCruiser 2005 Toyota LandCruiser 2006 Toyota ADR6200VW; ROM: 1.04.605.1 Toyota LandCruiser Denso YY Y YYYYYNY Y 2004 Toyota Prius 2005 Toyota Prius 2007 Toyota Camry 2006 Sienna 2006 4-Runner 2004 Lexus LS 430 2006 Lexus LS 430 2004 Lexus LX 470 2006 Lexus LX 470 2005 Lexus GX 470 2006 Lexus RX 330 2005 Lexus LS 430 2006 Lexus RX 400h ADR6200VW; ROM: 1.04.605.1 Lexus Denso YY Y YYYYYNY Y 2005 Lexus LX 470 2006 Lexus SC 430 2005 Lexus RX 300 2005 Lexus SC 430 2006 Lexus GS 300 2006 Lexus GS 430 2006 Lexus GX 470 ADR6200VW; ROM: 1.04.605.1 Scion 2010 Scion SC Denso Y Y Y Y Y Y Y Y N Y Y ADR6200VW; -
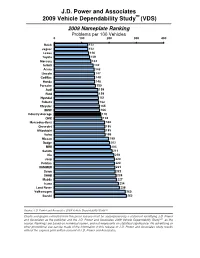
J.D. Power and Associates 2009 Vehicle Dependability Study (VDS)
J.D. Power and Associates 2009 Vehicle Dependability Study SM (VDS) 2009 Nameplate Ranking Problems per 100 Vehicles 0 100 200 300 400 Buick 122 Jaguar 122 Lexus 126 Toyota 129 Mercury 134 Infiniti 142 Acura 146 Lincoln 147 Cadillac 148 Honda 148 Porsche 150 Audi 159 Ford 159 Hyundai 161 Subaru 162 Chrysler 165 BMW 166 Industry Average 170 GMC 174 Mercedes-Benz 184 Chevrolet 185 Mitsubishi 185 Volvo 186 Nissan 199 Dodge 202 MINI 205 Saturn 211 Kia 218 Jeep 220 Pontiac 220 HUMMER 221 Scion 222 SAAB 226 Mazda 227 Isuzu 234 Land Rover 238 Volkswagen 260 Suzuki 263 Source: J.D. Power and Associates 2009 Vehicle Dependability Study SM Charts and graphs extracted from this press release must be accompanied by a statement identifying J.D. Power and Associates as the publisher and the J.D. Power and Associates 2009 Vehicle Dependability Study SM as the source. Rankings are based on numerical scores, and not necessarily on statistical significance. No advertising or other promotional use can be made of the information in this release or J.D. Power and Associates study results without the express prior written consent of J.D. Power and Associates. J.D. Power and Associates 2009 Vehicle Dependability Study SM (VDS) Top Three Models per Segment Car Segments Sub-Compact Car Compact Premium Sporty Car Highest Ranked: Scion xA Highest Ranked: Nissan 350Z Suzuki Aerio Mercedes-Benz SLK-Class Chevrolet Aveo Acura RSX Compact Car Entry Premium Vehicle Highest Ranked: Toyota Prius Highest Ranked: Lincoln Zephyr Toyota Matrix Cadillac CTS Pontiac Vibe Infiniti -

Jaguar XK 2012 Guide
Electrical Guide XK VIN: B44940 > BY APPOINTMENT TO BY APPOINTMENT TO HER MAJESTY QUEEN ELIZABETH II HIS ROYAL HIGHNESS THE PRINCE OF WALES MANUFACTURERS OF DAIMLER AND JAGUAR CARS MANUFACTURERS OF DAIMLER AND JAGUAR CARS JAGUAR CARS LIMITED COVENTRY JAGUAR CARS LIMITED COVENTRY Electrical Guide XK VIN: B44940 > Published by Technical Communications, Jaguar Cars Limited Publication Part Number JLR 16 02 21_1E Preface Preface Jaguar XK (B44940 >) While every effort is made to ensure accuracy, design changes to the vehicle may be made in the period between the completion of this publication and the introduction of vehicles. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form: electronic, mechanical, including photocopying, recording or other means without prior written permission from the Service Division of Jaguar Cars Limited. Paper copies of this document are uncontrolled, always refer to the electronic source material for the latest information. © 2011 Jaguar Cars Limited DATE OF ISSUE: 07/2011 Jaguar XK (B44940 >) Table of Contents Table of Contents Table of Contents . 1 Table of Contents: Figures . 2 Abbreviations and Acronyms . 6 Using this Publication . 7 Symbols and Codes . 8 DATE OF ISSUE: 07/2011 1 Table of Contents: Figures Table of Contents: Figures Jaguar XK (B44940 >) FIGURES Fig. Description Variant 01 Power Distribution Fig. 01.1 . Power Distribution Box: Part 1. All Fig. 01.2 . Power Distribution Box: Part 2. All Fig. 01.3 . Power Distribution Box: Part 3. All Fig. 01.4 . Central Junction Box: Part 1 . All Fig. 01.5 . Central Junction Box: Part 2 .